Zynq开发实践(FPGA之spi实现)
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing @163.com】
虽然串口用的地方比较多,实现起来也比较简单。但是串口本身速度比较慢,不利于高速数据通信。而且单个串口没有办法和很多芯片设备通信。所以,人们在串口的基础之上添加clk、cs信号,这样就形成了基本的spi总线协议。它也是mcu/soc和fpga通信的重要方式之一。
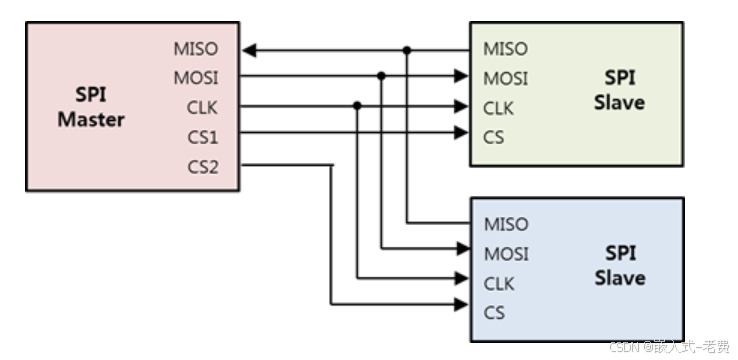
1、spi和串口的区别
相比较串口,spi多了cs和clk。正因为有了cs,这样fpga就可以通过它来区分不同的spi接口芯片。此时clk、rx、tx就可以完全复用。此外有了clk之后,数据的收发都可以借助于clk的边沿来进行处理,处理的效率高了很多,甚至可以达到20~50M,快一点的话100M也是可以的,这不是串口可以比拟的。
2、spi和iic的区别
现在spi和iic比较,iic的收发是同一根pin,iic也有clk信号,但是没有cs信号。这导致iic上的芯片都会接收总线上的数据,但是如果发现设备数据不是自己的,会直接扔掉。
3、spi和iic应用范围非常广
不仅spi norflash、spi nandflash,还是spi网络芯片、spi adc、spi dac,spi和iic的应用范围都是非常广的。spi一般用于中高速芯片,iic和uart则用于低速芯片。所以说,如果掌握好了spi、iic、uart之后,基本上mcu能做的事情,都可以用fpga来完成。像rgb、mcu、vga这样mcu做不来的视频接口,也可以用fpga来完成。甚至于很多sdio接口的外设,都是可以转换成spi访问,tf卡就是一个典型的案例。
spi本身只是一个总线,所以我们实际对芯片操作的时候,还需要了解操作的方式,比如怎么发命令,怎么发命令和地址,怎么读数据。就拿spi nanflash来说,要做好这个工作需要分成这三步,
实现基本的spi协议;
实现访问spi nandflash需要的各个命令;
根据需求访问spi nandflash,做好读、写和状态的校验。4、spi master和spi slave
一般把主动发起命令的设备称之为master,被动接收命令的设备称之为slave。当然fpga和spi nandflash通信时,此时fpga就是master,nandflash就是slave。如果此时mcu/soc和fpga通信,这种情况下mcu/soc就是master,fpga就是slave。
如果有同学不知道如何用spi写slave,那么可以找一个spi nandflash的芯片手册,把自己当成一个spi nand,去适配master就可以了。
5、spi的四种模式
根据时钟极性cpol和时钟相位cpha,就可以把spi分成四种工作模式。其中cpol,就是空闲状态的时候,spi处于高电平还是低电平。而cpha,则告诉我们采样的时候,应该是第一个边沿采样,还是第二个边沿采样。实际应用的时候,我们记住0-0就可以,即空闲状态是0,第一个边沿触发的时候采样。
6、发送和采样数据
spi的发送和采样都是基于clock进行的。如果spi时钟不是很快,那么可以通过计数分频的办法去解决。首先我们谈一下发送。假设spi的工作模式是0-0,即空闲为0,上升沿采样。这种情况下,只需要一个周期发送一个bit数据即可,每半个周期时钟反转一下,也就是上升沿的时候提示对方接收数据,因此数据肯定是提前准备好的。
采样的时候一般是反过来的。以spi nandflash为例。fpga发送完命令之后,一般就可以开始准备采样数据了。采样的时候,其实和发送也是一样的,在上升沿的时候开始采样,因为对方数据发送一般是下降沿开始发送。所以在一个周期内spi clock做两次翻转就可以了。
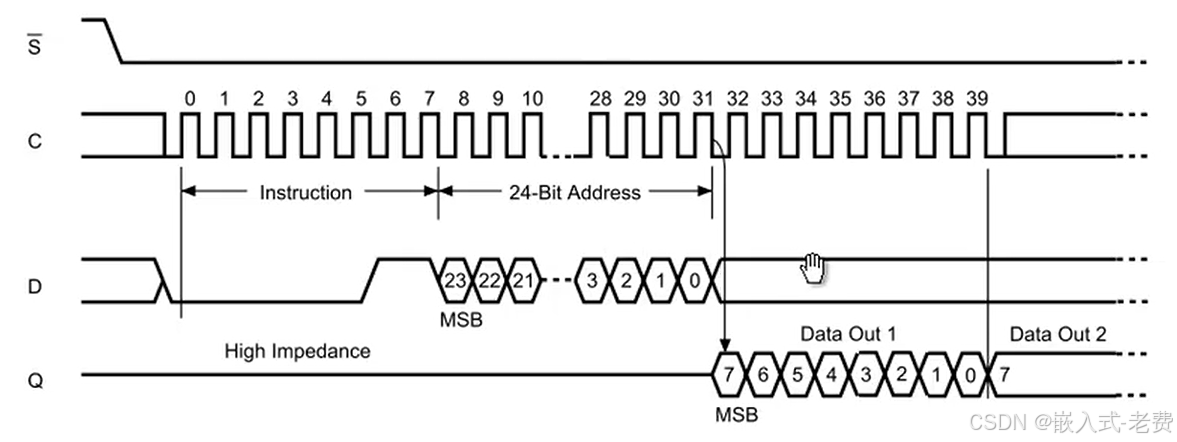
7、spi协议的实现
所以这里spi的实现主要集中在底层领域,涉及到spi clock、cs、mosi、miso,可以好好看一下,
module spi_top(input clk,input rst,input rw,input rw_valid,input[7:0] w_data,output[7:0] r_data,output status,// about signaloutput cs,output reg tx,output reg spi_clk,input rx);reg[3:0] state;
reg[3:0] next_state;
reg[15:0] counter;
reg[3:0] num;reg rw_reg;
reg[7:0] w_data_reg;
reg[7:0] r_data_reg;localparam TIMER_INTERVAL = 16'd20;localparam IDLE = 4'h0;
localparam SPI_CLK = 4'h1;
localparam SPI_CHK = 4'h2;
localparam LAST_CLK = 4'h3;
localparam SPI_END = 4'h4;// about state machinealways@(posedge clk or negedge rst)if(!rst)state <= IDLE;else state <= next_state;always@(*)case(state)IDLE: beginif(rw_valid)next_state = SPI_CLK;elsenext_state = IDLE;endSPI_CLK: beginif(counter == TIMER_INTERVAL)next_state = SPI_CHK;elsenext_state = SPI_CLK;endSPI_CHK: beginif(num == 4'hf)next_state = LAST_CLK;elsenext_state = SPI_CLK;endLAST_CLK: beginif(counter == TIMER_INTERVAL)next_state = SPI_END;elsenext_state = LAST_CLK;endSPI_END:next_state = IDLE;default:next_state = IDLE;endcase// about cs, sometime can be used for multiple devicesassign cs = (state != IDLE) ? 0 : 1;// save rw dataalways@(posedge clk or negedge rst)if(!rst) beginrw_reg <= 0;w_data_reg <= 8'h0;endelse if(state == IDLE && rw_valid) beginrw_reg <= rw;w_data_reg <= w_data;end// about frequency divisonalways@(posedge clk or negedge rst)if(!rst)counter <= 16'h0;else if(state == SPI_CLK || state == LAST_CLK)counter <= counter + 1;elsecounter <= 16'h0;// about clk numberalways@(posedge clk or negedge rst)if(!rst)num <= 4'h0;else if(state == SPI_CHK)num <= num + 1;else if(state == IDLE)num <= 4'h0;//
// about spi clk
// this is very import, useful for low speed communication
//always@(posedge clk or negedge rst)if(!rst)spi_clk <= 0;else if(state == SPI_CLK && counter == TIMER_INTERVAL)spi_clk <= ~spi_clk;else if(state == IDLE)spi_clk <= 0;// about tx signalalways@(posedge clk or negedge rst)if(!rst)tx <= 0;else if(state == SPI_CLK && rw_reg)tx <= w_data_reg[0];else if(state == SPI_CHK && num <= 13 && rw_reg) // fix bug about num 2025.9.9tx <= w_data_reg[(num >> 1) +1];else if(state == IDLE)tx <= 0;// about rx signalalways@(posedge clk or negedge rst)if(!rst)r_data_reg <= 8'h0;else if(state == SPI_CHK && !num[0] && !rw_reg)r_data_reg[num >> 1] <= rx;else if(state == IDLE)r_data_reg <= 8'h0;assign r_data = r_data_reg;
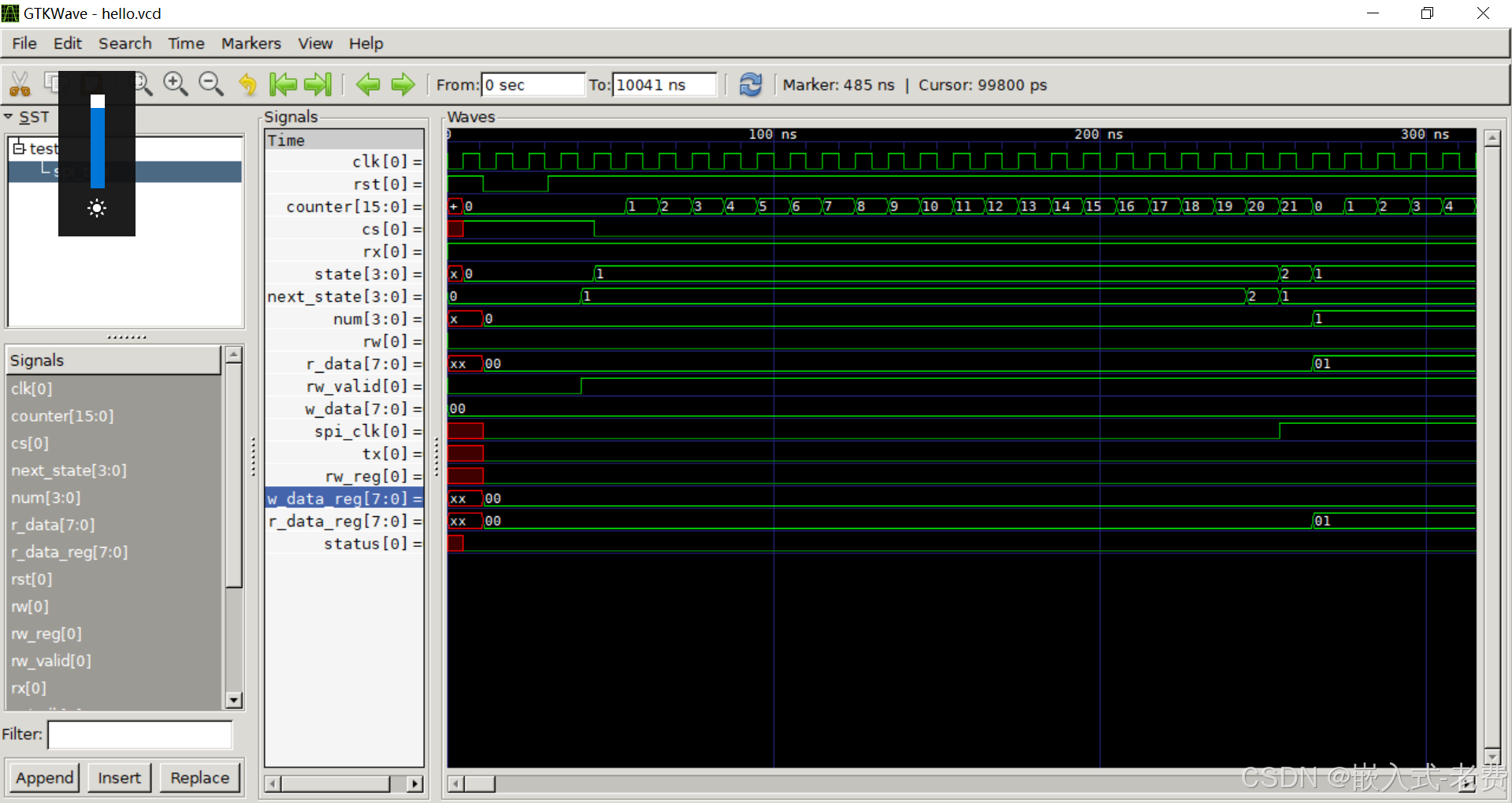
assign status = (state == SPI_END);endmodule实际跑起来,添加上testbench之后,仿真截图是这样的,