计算机视觉cv2入门之实时人脸检测
前边我们已经讲解了HaarCascade级联分类器以及针对实时视频流文件的操作方法,这里我们通过实时人脸检测这一案例来学习和实操一下。

大致思路
- 使用cv2.VideoCaPture打开摄像头捕获人脸图片
- 根据人脸种类以及指定图片数量来构建一个自己的人脸图片数据集
- 使用CNN或 Anyway 卷积模型训练人脸图片数据集。
- 使用cv2.VideoCaPture打开摄像头,HaarCascade级联分类器对每一帧画面检测人脸,并将检测到的人脸图像传入训练好的模型,模型返回预测结果,并标注在视频中。
人脸图片数据集的构建
经典的人脸图片数据集有很多,但是都比较大,下载费时且模型训练时间长,并且由于是要实时检测,用别人的图片没什么卵用,因此这里我决定自行采集人脸图片来构建一个小型数据集。人脸图片的获取方法比较简单,就是使用cv2.VideoCapture函数打开摄像头来进行采集。这里我把我的方法分享给大家。
采集人脸图片
import cv2
import os
from tkinter import messagebox
DATASET_DIR='facePhotos'#保存所有待采集脸的图片的文件夹的路径
faces=[]#每一张图片对应的种类
face_kinds=1#人脸种类
photo_num=5#要采集的图片数量
avg=photo_num//face_kinds#平均每个人脸需要采集的照片数量
for kind in range(face_kinds):faces.extend([kind]*avg)
os.makedirs(DATASET_DIR, exist_ok=True)#exist_ok=True可以避免二次采集时重建新文件夹def capture_faces(face:str,count:int):'''Args:face:每次采集的人脸类别,要标记在视频中,防止忘记采集的手势是多少导致实际类别与真实采集结果不一致从而成为噪声!\ncount:用来命名每次保存的图片,这里直接用图片的数量来命名\n'''cv2.namedWindow('Data Collection',cv2.WND_PROP_FULLSCREEN)cv2.setWindowProperty('Data Collection', cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN)cap=cv2.VideoCapture(0)while True:ret,frame=cap.read()if not ret: breakroi=frame[50:300,200:400]#roi区域,可以自行修改cv2.rectangle(frame,(200,50),(400,300),(0,0,255),2)#roi区域处绘制方框cv2.putText(frame,text=f'Photo Num:No{count+1} Face Type:{face}',org=(100,400),fontFace=3,fontScale=1,thickness=3,color=(0,255,0))cv2.imshow(f'Data Collection',frame)key=cv2.waitKey(1)if key==27:#按下ESC保存并退出img_path=f'{DATASET_DIR}/{count}.jpg'roi=cv2.cvtColor(roi,cv2.COLOR_BGR2GRAY)cv2.imwrite(img_path,roi)break cap.release()cv2.destroyAllWindows()
messagebox.showinfo(title='提示',message=f'开始采集面部照片(按ESC保存并退出),注意文字提示')
for i in range(len(faces)):capture_faces(faces[i],i)运行上述代码后,便可以开始采集手势图片了,这里我使用上述代码总共采集了200张图片用于后续CNN模型的训练。
采集中效果:

说明
采集时,将右手放置在视频中的绿色框内,尽可能的放置在中央,Face Type后的数字表示当前的人脸类型。如果采集时出现错误,那么只需要删除掉原来的图片,自行指定新的类别(face)以及原来图片的编号,调用一次capture_faces函数重新采集即可。

采集结果(5个人脸,100张图片,当然数量越多越好)
数据预处理
这里的数据预处理主要就是将我们的图像数据划分训练集与测试集后转换为tensor类型的DataLoder。
#数据预处理
import os
from torch.utils.data import Dataset, DataLoader
import torch
from torchvision import transforms
import os
class FaceDataset(Dataset):def __init__(self, data_dir,face_kinds,photo_num,transform=None):self.data_dir = data_dirself.transform = transformself.image_paths = []self.labels=[]avg=photo_num//face_kindsfor kind in range(face_kinds):self.labels.extend([kind]*avg)# 读取数据集for img_name in os.listdir(data_dir):if img_name.endswith('.jpg'):self.image_paths.append(os.path.join(data_dir, img_name))
def process_data(data_dir,face_kinds,photo_num,batch_size=4):#数据预处理transform = transforms.Compose([transforms.ToPILImage(),transforms.Resize((64, 64)),transforms.ToTensor(),transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])])dataset=FaceDataset(data_dir,face_kinds,photo_num,transform=transform)train_size=int(0.8*len(dataset))test_size=len(dataset) - train_sizetrain_dataset, test_dataset = torch.utils.data.random_split(dataset, [train_size, test_size])train_loader=DataLoader(train_dataset, batch_size=batch_size, shuffle=True)test_loader=DataLoader(test_dataset, batch_size=batch_size, shuffle=False)return train_loader, test_loaderCNN模型训练
考虑到我的数据集比较少且该分类问题比较简单,所以这里我的模型也没有太复杂只是使用了2层卷积操作。倘若你的数据集比较大,分类种类比较多,可以尝试使用一些其他的卷积模型,比如mobilenet,resnet等。
#CNN模型
import torch
import torch.nn as nn
import torch.optim as optim
class FaceCNN(nn.Module):def __init__(self, num_classes=5):super(FaceCNN, self).__init__()self.conv1=nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1)self.relu=nn.ReLU()self.bn1=nn.BatchNorm2d(16)self.maxpool=nn.MaxPool2d(kernel_size=2, stride=2)self.conv2=nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1)self.bn2=nn.BatchNorm2d(32)self.fc1=nn.Linear(32*16*16, 128)self.fc2=nn.Linear(128, num_classes)def forward(self, x):x=self.conv1(x)x=self.bn1(x)x=self.relu(x)x=self.maxpool(x)x=self.conv2(x)x=self.bn2(x)x=self.relu(x)x=self.maxpool(x)x=x.view(x.size(0),-1)x=self.fc1(x)x=self.relu(x)x=self.fc2(x)return xdef train_model(train_loader, test_loader, num_epochs=50):device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')model=FaceCNN(num_classes=5).to(device)criterion=nn.CrossEntropyLoss()optimizer=optim.Adam(model.parameters(),lr=0.001)for epoch in range(num_epochs):model.train()running_loss=0.0correct=0total=0for images, labels in train_loader:images=images.to(device)labels=labels.to(device)optimizer.zero_grad()outputs=model(images)loss=criterion(outputs, labels)loss.backward()optimizer.step()running_loss+=loss.item()_, predicted=torch.max(outputs.data, 1)total+=labels.size(0)correct+=(predicted==labels).sum().item()train_loss = running_loss / len(train_loader)train_acc = 100 * correct / total# 测试集评估model.eval()test_correct = 0test_total = 0with torch.no_grad():for images, labels in test_loader:images=images.to(device)labels=labels.to(device)outputs=model(images)_, predicted=torch.max(outputs.data, 1)test_total+=labels.size(0)test_correct+=(predicted==labels).sum().item()test_acc=100*test_correct/test_totalprint(f'Epoch [{epoch+1}/{num_epochs}], 'f'Train Loss: {train_loss:.4f}, 'f'Train Acc: {train_acc:.2f}%, 'f'Test Acc: {test_acc:.2f}%')#保存模型torch.save(model.state_dict(), 'face_cnn.pth')print('训练完成,模型已保存为 face_cnn.pth')return model实时预测
实时预测的思路是:打开摄像头,使用HaarCascade检测并获取实时视频流中的每一帧图片,将图片传入到训练好的模型中预测并将结果标注在视频流文件的每一帧上。
HaarCascade分类器
Haar CascadeXML特征分类器,是一种基于机器学习的方法,它利用了积分图像(或总面积)的概念有效地提取特征(例如,边缘、线条等)的数值。“级联分类器”即意味着不是一次就为图像中的许多特征应用数百个分类器,而是一对一地应用分类器。
利用OpenCV自带的xml文件,可以实时检测摄像头中人脸Haar特征或LBP特征,它们描述不同的局部信息。
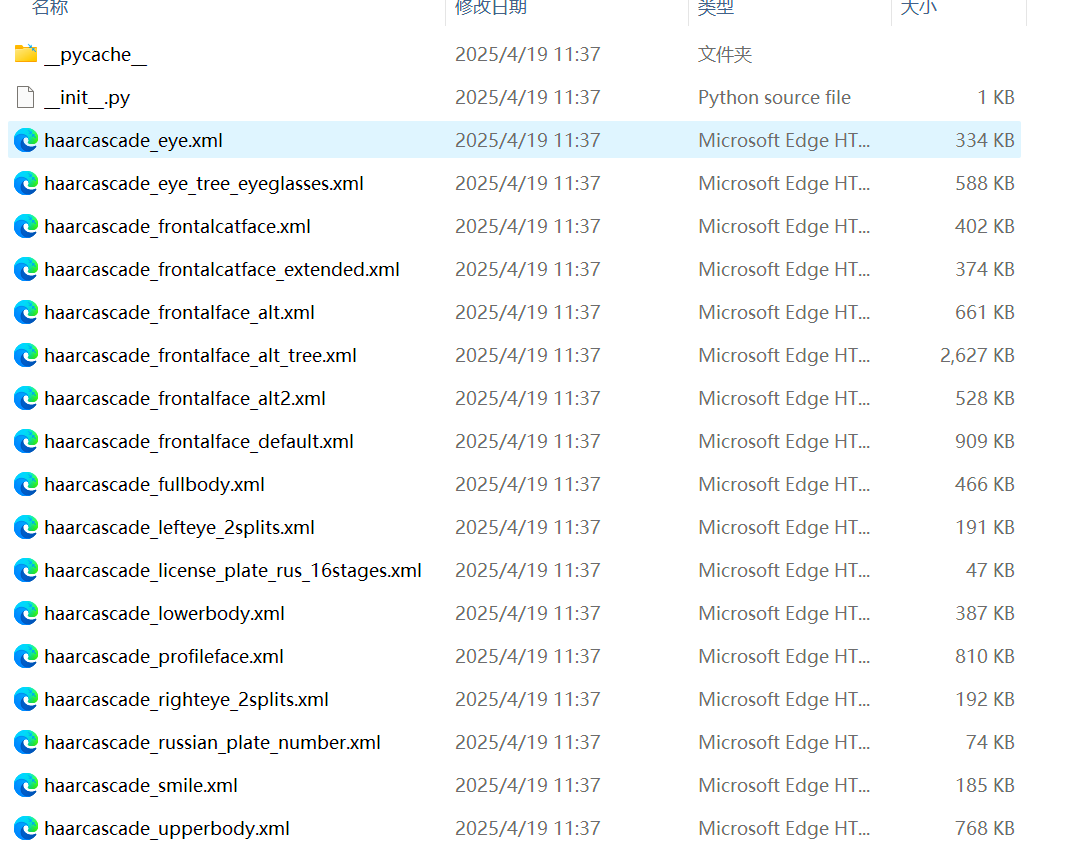
opencv自带的级联特征分类器都位于cv2/data这个文件夹下,检测的对象和内容都包含在名称里。
导入并初始化分类器
为了更方便的获取路径来导入,我们可以使用os.path和cv2.__file__属性来获取:
#HaarCascade初始化
import cv2
import os
haarcascade=os.path.dirname(cv2.__file__)
face_cascade=os.path.join(haarcascade,r"data\haarcascade_frontalface_default.xml")
face_detector=cv2.CascadeClassifier(face_cascade)detectMutiScale函数
在进行检测时,我们主要用的detectMutiScale这个函数,使用前需要先定义分类器
#检测人脸
'''
detecMultiScale()函数参数详解:
image: 8-bit灰度图像
scaleFactor: float=1.1 图像金字塔缩放比例(每次缩小倍数),值越小检测越精细但速度越慢。
minNeighbors:int=3 候选矩形需有的最少相邻矩形数,值越大误检越少但可能漏检。
minSize:tuple 目标最小尺寸(如 (30, 30))主要用来忽略更小的区域以加速检测。
maxSize:tuple 目标最大尺寸(如 (100, 100))主要用来忽略更大的区域。
'''import cv2
import os
haarcascade=os.path.dirname(cv2.__file__)
face_cascade=os.path.join(haarcascade,r"data\haarcascade_frontalface_default.xml")
face_detector=cv2.CascadeClassifier(face_cascade)src_image=cv2.imread('face.png')
gray_image=cv2.cvtColor(src_image.cv2.COLOR_BGR2GRAY)
faces=face_detector.detectMultiScale(image=gray_image,scaleFactor=1.15,minNeighbors=5)
mark_image=src_image.copy()
mark_image_gray=gray_image.copy()
for x,y,w,h in faces:cv2.rectangle(mark_image,(x,y),(x+w,y+h),(0,255,0),3)cv2.rectangle(mark_image_gray,(x,y),(x+w,y+h),0,3)
plt.subplot(1,2,1),plt.imshow(mark_image),plt.text(x=x,y=y,s='人脸')
plt.subplot(1,2,2),plt.imshow(mark_image_gray,cmap='gray'),plt.text(x=x,y=y,s='人脸')detecMultiScale函数参数详解:
| 参数 | 类型 | 默认值 | 说明 |
|---|---|---|---|
image | 8-bit 灰度图像 | 无 | 输入的单通道灰度图像,需先通过 cv2.cvtColor() 转换。 |
scaleFactor | float | 1.1 | 图像金字塔缩放比例(每次缩小倍数),值越小检测越精细但速度越慢。 |
minNeighbors | int | 3 | 候选矩形需有的最少相邻矩形数,值越大误检越少但可能漏检。 |
minSize | tuple (w, h) | None | 目标最小尺寸(如 (30, 30),用来忽略更小的区域以加速检测。 |
maxSize | tuple (w, h) | None | 目标最大尺寸(如 (100, 100),用来忽略更大的区域。 |
这里的这个minNeighbors参数与KNN中的K值有一些相似之处:
- 两者都通过“邻居数量”过滤噪声或不确定性。
- 值越大,结果越保守(漏检增多或分类边界更平滑);值越小,结果越敏感(误检增多或过拟合风险)。
detectMultiscale函数最终的返回值为list([x,y,w,h])即测到的目标矩形列表(左上角坐标 + 宽高)
如果有需要的话,我们还可以使用cv2.rectangle将检测到的目标在原始图像中绘制出来。
完整代码
代码共计包含两部分,一部分为人脸图片数据采集,另一部分为数据预处理-训练-实时预测
数据集采集:
采集人脸图片的代码
import cv2
import os
from tkinter import messagebox
DATASET_DIR='facePhotos'#保存所有待采集脸的图片的文件夹的路径
faces=[]#每一张图片对应的种类
face_kinds=1#人脸种类
photo_num=5#要采集的图片数量
avg=photo_num//face_kinds#平均每个人脸需要采集的照片数量
for kind in range(face_kinds):faces.extend([kind]*avg)
os.makedirs(DATASET_DIR, exist_ok=True)#exist_ok=True可以避免二次采集时重建新文件夹def capture_faces(face:str,count:int):'''Args:face:每次采集的人脸类别,要标记在视频中,防止忘记采集的手势是多少导致实际类别与真实采集结果不一致从而成为噪声!\ncount:用来命名每次保存的图片,这里直接用图片的数量来命名\n'''cv2.namedWindow('Data Collection',cv2.WND_PROP_FULLSCREEN)cv2.setWindowProperty('Data Collection', cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN)cap=cv2.VideoCapture(0)while True:ret,frame=cap.read()if not ret: breakroi=frame[50:300,200:400]#roi区域,可以自行修改cv2.rectangle(frame,(200,50),(400,300),(0,0,255),2)#roi区域处绘制方框cv2.putText(frame,text=f'Photo Num:No{count+1} Face Type:{face}',org=(100,400),fontFace=3,fontScale=1,thickness=3,color=(0,255,0))cv2.imshow(f'Data Collection',frame)key=cv2.waitKey(1)if key==27:#按下ESC保存并退出img_path=f'{DATASET_DIR}/{count}.jpg'roi=cv2.cvtColor(roi,cv2.COLOR_BGR2GRAY)cv2.imwrite(img_path,roi)break cap.release()cv2.destroyAllWindows()
messagebox.showinfo(title='提示',message=f'开始采集面部照片(按ESC保存并退出),注意文字提示')
for i in range(len(faces)):capture_faces(faces[i],i)训练并预测:
这里还使用了语音播报来播放,使用时要注意win32com.client下的语音播报API会阻塞主线程,也就是无法直接与cv2.VideoCapture函数同时使用,需要单开一个线程来解决这个问题。
#数据预处理
import os
from torch.utils.data import Dataset, DataLoader
import torch
import cv2
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms
#实时预测
import sys
import threading
import win32com.client
import queue
import cv2
import osclass FaceDataset(Dataset):def __init__(self, data_dir,face_kinds,photo_num,transform=None):self.data_dir = data_dirself.transform = transformself.image_paths = []self.labels=[]avg=photo_num//face_kindsfor kind in range(face_kinds):self.labels.extend([kind]*avg)# 读取数据集for img_name in os.listdir(data_dir):if img_name.endswith('.jpg'):self.image_paths.append(os.path.join(data_dir, img_name))def __len__(self):return len(self.image_paths)def __getitem__(self, idx):img_path=self.image_paths[idx]image=cv2.imread(img_path)image=cv2.cvtColor(image, cv2.COLOR_BGR2RGB) # 转换为RGBlabel=self.labels[idx]if self.transform:image=self.transform(image)return image, labeldef process_data(data_dir,face_kinds,photo_num,batch_size=4):# 数据预处理transform = transforms.Compose([transforms.ToPILImage(),transforms.Resize((64, 64)),transforms.ToTensor(),transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])])dataset=FaceDataset(data_dir,face_kinds,photo_num,transform=transform)train_size=int(0.8*len(dataset))test_size=len(dataset) - train_sizetrain_dataset, test_dataset = torch.utils.data.random_split(dataset, [train_size, test_size])train_loader=DataLoader(train_dataset, batch_size=batch_size, shuffle=True)test_loader=DataLoader(test_dataset, batch_size=batch_size, shuffle=False)return train_loader, test_loaderclass FaceCNN(nn.Module):def __init__(self, num_classes=5):super(FaceCNN, self).__init__()self.conv1=nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1)self.relu=nn.ReLU()self.bn1=nn.BatchNorm2d(16)self.maxpool=nn.MaxPool2d(kernel_size=2, stride=2)self.conv2=nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1)self.bn2=nn.BatchNorm2d(32)self.fc1=nn.Linear(32*16*16, 128)self.fc2=nn.Linear(128, num_classes)def forward(self, x):x=self.conv1(x)x=self.bn1(x)x=self.relu(x)x=self.maxpool(x)x=self.conv2(x)x=self.bn2(x)x=self.relu(x)x=self.maxpool(x)x=x.view(x.size(0),-1)x=self.fc1(x)x=self.relu(x)x=self.fc2(x)return xdef train_model(train_loader, test_loader, num_epochs=50):device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')model=FaceCNN(num_classes=5).to(device)criterion=nn.CrossEntropyLoss()optimizer=optim.Adam(model.parameters(),lr=0.001)for epoch in range(num_epochs):model.train()running_loss=0.0correct=0total=0for images, labels in train_loader:images=images.to(device)labels=labels.to(device)optimizer.zero_grad()outputs=model(images)loss=criterion(outputs, labels)loss.backward()optimizer.step()running_loss+=loss.item()_, predicted=torch.max(outputs.data, 1)total+=labels.size(0)correct+=(predicted==labels).sum().item()train_loss = running_loss / len(train_loader)train_acc = 100 * correct / total# 测试集评估model.eval()test_correct = 0test_total = 0with torch.no_grad():for images, labels in test_loader:images=images.to(device)labels=labels.to(device)outputs=model(images)_, predicted=torch.max(outputs.data, 1)test_total+=labels.size(0)test_correct+=(predicted==labels).sum().item()test_acc=100*test_correct/test_totalprint(f'Epoch [{epoch+1}/{num_epochs}], 'f'Train Loss: {train_loss:.4f}, 'f'Train Acc: {train_acc:.2f}%, 'f'Test Acc: {test_acc:.2f}%')#保存模型torch.save(model.state_dict(), 'face_cnn.pth')print('训练完成,模型已保存为 face_cnn.pth')return modeldef speech_worker():while not stop_event.set():try:text=speech_queue.get(timeout=0.1)speaker.Speak(text)except queue.Empty:continuedef clear_queue():with speech_queue.mutex:speech_queue.queue.clear() def realtime_prediction(model_path='face_cnn.pth'):speech_thread=threading.Thread(target=speech_worker)speech_thread.start()device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')#加载模型model=FaceCNN(num_classes=5).to(device)model.load_state_dict(torch.load(model_path))model.eval()#预处理transform=transforms.Compose([transforms.ToPILImage(),transforms.Resize((64, 64)),transforms.ToTensor(),transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])])cap=cv2.VideoCapture(0)cv2.namedWindow('Face Recognition', cv2.WND_PROP_FULLSCREEN)cv2.setWindowProperty('Face Recognition', cv2.WND_PROP_FULLSCREEN, cv2.WINDOW_FULLSCREEN)with torch.no_grad():while True:ret, frame=cap.read()if not ret: break # roi=frame[50:300,200:400]#roi区域,可以自行修改# cv2.rectangle(frame,(200,50),(400,300),(0,0,255),2)#roi区域处绘制方框try:gray_frame=cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)face=face_detector.detectMultiScale(image=gray_frame,scaleFactor=1.15,minNeighbors=6)for x,y,w,h in face:cv2.rectangle(frame,(x-10,y-80),(x+w+10,y+h+80),(0,255,0),3)roi=frame[y-80:y+h+80,x-10:x+w+10]#roi区域,可以自行修改roi=cv2.resize(roi,dsize=(400,450))input_tensor=transform(roi).unsqueeze(0).to(device)output=model(input_tensor)_, pred=torch.max(output, 1)probabilities=torch.nn.functional.softmax(output[0], dim=0) confidence, pred=torch.max(probabilities, 0)confidence=confidence.item()*100 #转换为百分比confidence=round(confidence,2)cv2.putText(frame, f'Prediction:You are {english_map_dict.get(pred.item())}', (50, 40), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2)cv2.putText(frame,f'confidence:{confidence}',(70,70),cv2.FONT_HERSHEY_SIMPLEX,0.5, (0, 0, 255), 2)if confidence>60:clear_queue()speech_queue.put(f'你是{map_dict.get(pred.item())}')except Exception as e:print(f"预测错误: {e}")cv2.imshow('Face Recognition', frame)if cv2.waitKey(1)==27: breakcap.release()cv2.destroyAllWindows()clear_queue()stop_event.set()speech_thread.join()sys.exit()if __name__=='__main__':speaker=win32com.client.Dispatch('SAPI.SpVoice')DATASET_DIR='FacePhotos'face_kinds=5photo_num=100haarcascade=os.path.dirname(cv2.__file__)face_cascade=os.path.join(haarcascade,r"data\haarcascade_frontalface_default.xml")face_detector=cv2.CascadeClassifier(face_cascade)speech_queue=queue.Queue()stop_event=threading.Event()map_dict={0:'Hu',1:'Li',2:'LiN',3:'Xie',4:'Li'}english_map_dict={0:'Hu',1:'Li',2:'Lin',3:'Xie',4:Jie'}train_loader,test_loader=process_data(data_dir=DATASET_DIR,face_kinds=face_kinds,photo_num=photo_num)model=train_model(train_loader,test_loader, num_epochs=50)realtime_prediction()最终效果:

当人脸出现在屏幕中时,HarrCascade分类器会自动查找并标注人脸所处区域,获得的人脸照片传入到训练好的模型后会实时返回并标注在屏幕上。
总结

以上便是计算机视觉cv2入门之实时人脸检测的所有内容,如果你感到本文对你有用,还劳驾各位一键三连支持一下博主。