交换排序——冒泡排序与快速排序
笔者把源码放在github上了:z-yi-han/Fundamentals-of-Data-Struct: 这是新人用来记录自己的数据结构学习的过程
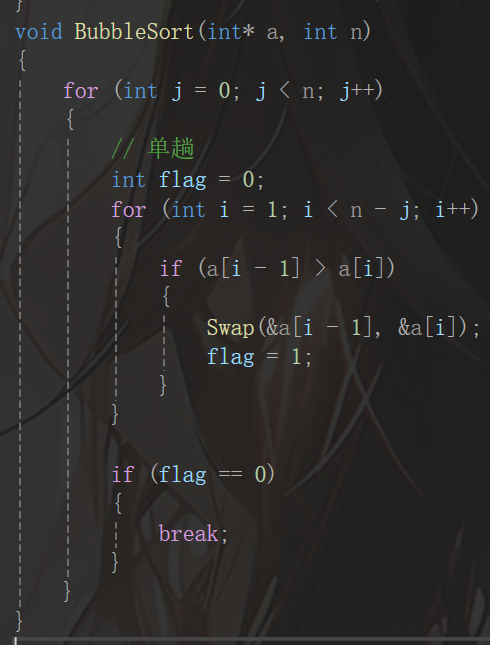
今天,笔者带领大家学习交换排序,交换排序有两种,一种是冒泡排序,一种是快速排序。首先笔者带着大家快速过一遍冒泡排序:就是遍历整个数组然后让较大的数放在后面,从而实现冒泡的效果,由于读者都比较熟悉,笔者不再过多赘述,直接看一看代码即可:
下面是快速排序,也是本文的重点,快速排序是一个实现起来很麻烦的排序。首先,我们先知道什么是快速排序:快排是一种效率较高的交换排序,定义是选定一个key,然后左边找大,右边找小,从而实现升序排序的目的:
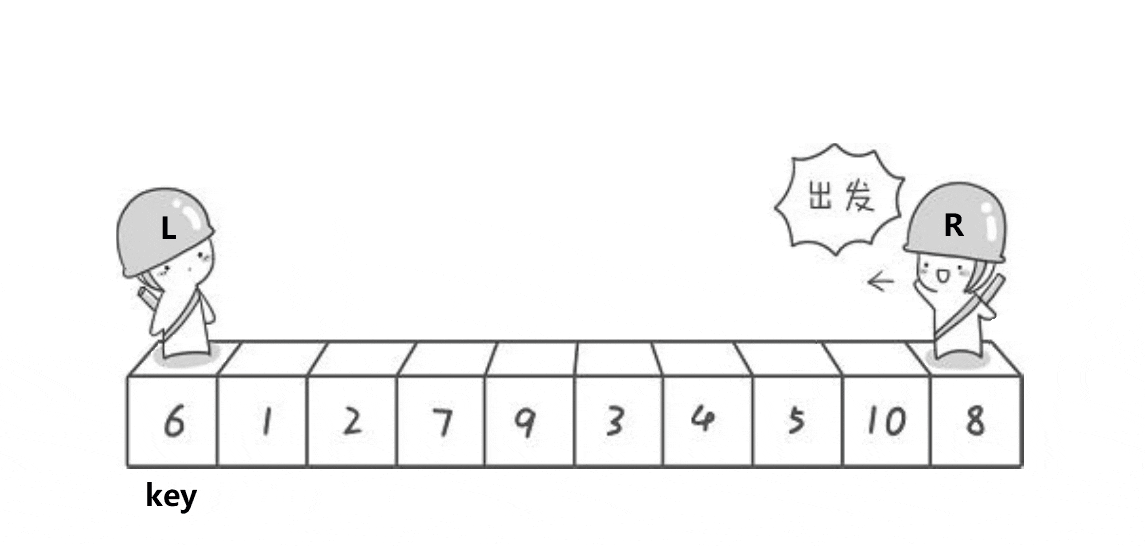
就是这样开始即可,然后左找大,右找小,先让R(right)出发,然后每个值和key对比,如果这个值比key小,那就停止,然后L(left)开动,和key继续比较,直到对应的值大于key时,停,此时right小于ker,left大于key,二者交换位置,这样就会让比key小的往左,比key大的往右,然后继续走,依旧这样进行,直接二者相遇,二者一定会相遇,后面笔者会再证明,遇到之后,把key和相遇位置交换,这样就保证了升序排序。下面证明一下不管奇数偶数二者都会相遇:首先,我们要知道,这其实是一个区间问题,我们之所以不确定二者会不会遇上,就是因为觉得会有偶数情况导致碰不上,但是实际上,这种情况并不存在,看下面的逻辑:
如果 L < R:说明还能继续交换;如果 L == R:说明两边已经扫描到同一个位置了,这时停止,基准值放到这个位置上;如果 L > R:代表划分完成(这时候就是区间结束了)。 下面先把这一段的代码写完,然后再考虑整体代码:
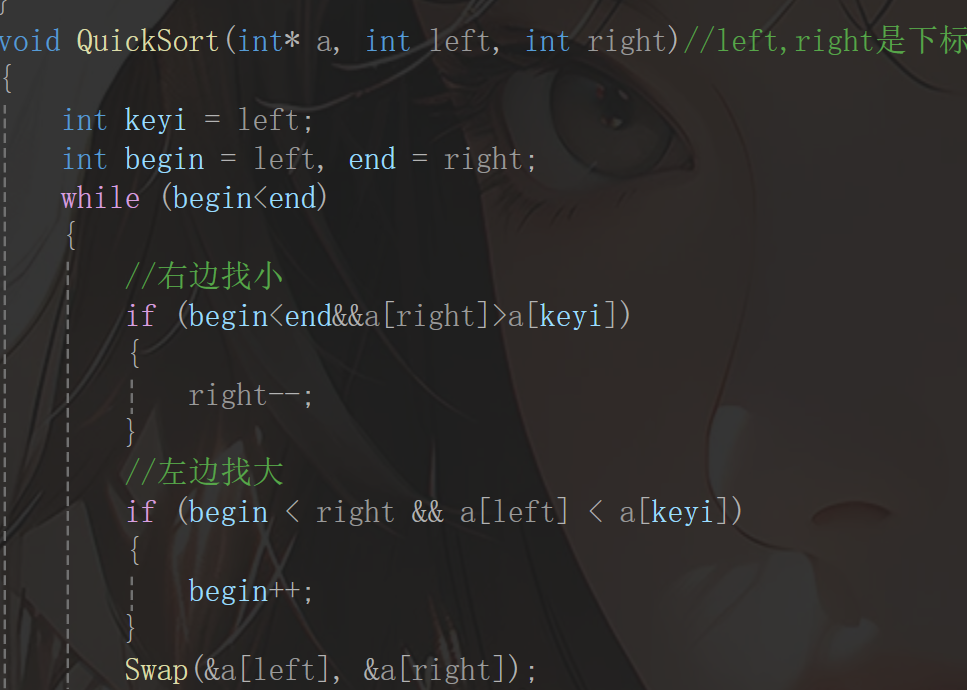
这是在进行运动,然后考虑到终点时的操作:
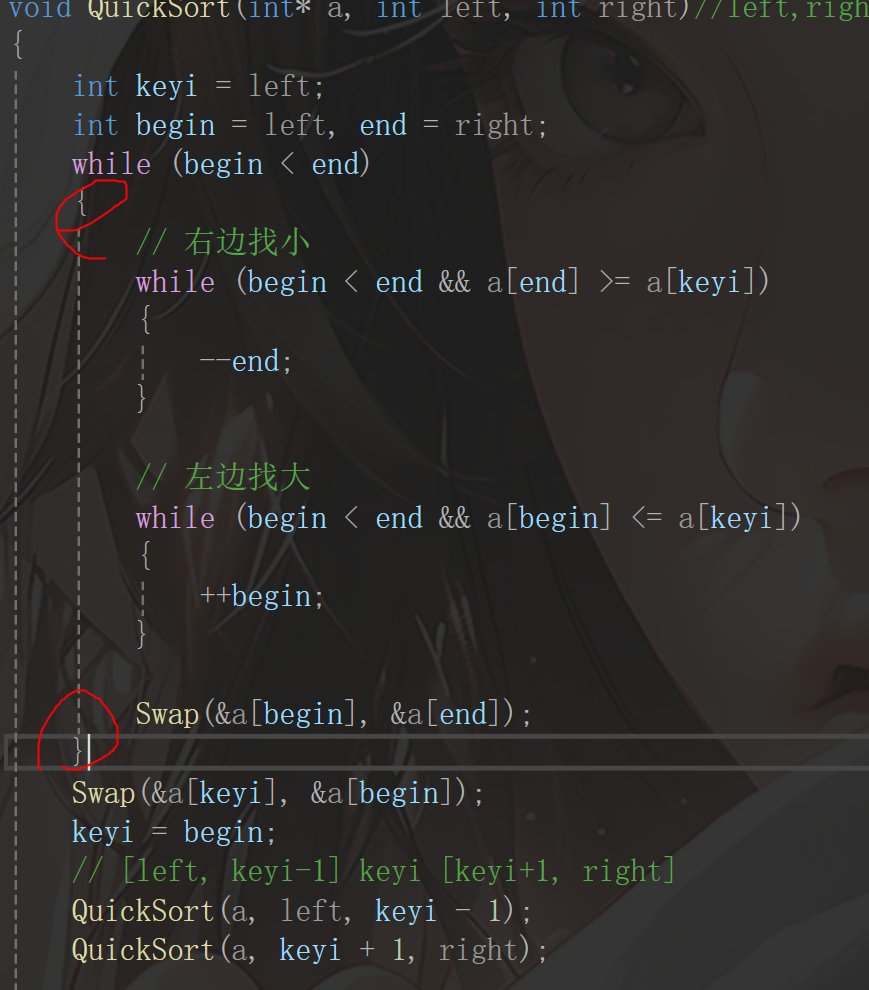
笔者带领读者慢慢捋一下代码思路,首先我们在上面进行了左找大,右找小,然后碰上之后停止了,然后因为while循环继续进行,一直到end和begin碰上了,停止,停止之后呢,需要把keyi和 相遇位置交换,也就是如图所示的Swap,不过需要注意的是,交换的是地址和数组对应的值,但是基准下标并没有变化,因为基准要进行变化,所以要赋值给keyi begin(也就是相遇的下标),下面其实就是递归了,这部分内容相信读者经过二叉树的学习之后就很容易理解了,只不过需要注意一点,那就是区间的划分,经过刚才的操作,其实keyi这个位置已经排序完成了,所以不用动了,再次划分区间的时候就是从最左边到keyi-1,keyi+1到最右边,然后再次排。序就行了,我们可以思考这个递归思想,只剩一个的时候自然递归结束。
下一篇文章笔者带大家对快速排序进行一些优化,希望读者持续关注。