MapReduce :Map阶段分区后,数据怎么找到Reducer?
MapReduce

有小伙伴反馈面试遇到的一个关于MR的细节问题:Map阶段数据分区后,每个分区的数据怎么找到Reducer?
面试官:Map 分完区,各个分区的数据怎么知道发到哪个 Reducer?
小A:发过去呗……
面试官:怎么发?发给谁?
小A:……啊吧啊吧 谁喂我花生!!!

听完回答,面试官的表情就像图上的克林一样哈哈哈哈哈
着实是一个 看似简单却极易答错的细节问题,想必大家都知道根据 key 的哈希值取模,发给对应的 Reducer。
但是面试官想深究的是:《对应》到底是谁和谁对应?
partition-0 该发给 reducer-0 还是 reducer-1? reducer-2 又该去哪找属于它的数据?
博主这里带大家从Apache Hadoop 官方文档 + GitHub 源码回顾一下具体的细节:
src/main/java/org/apache/hadoop/mapreduce/lib/partition/HashPartitioner.java
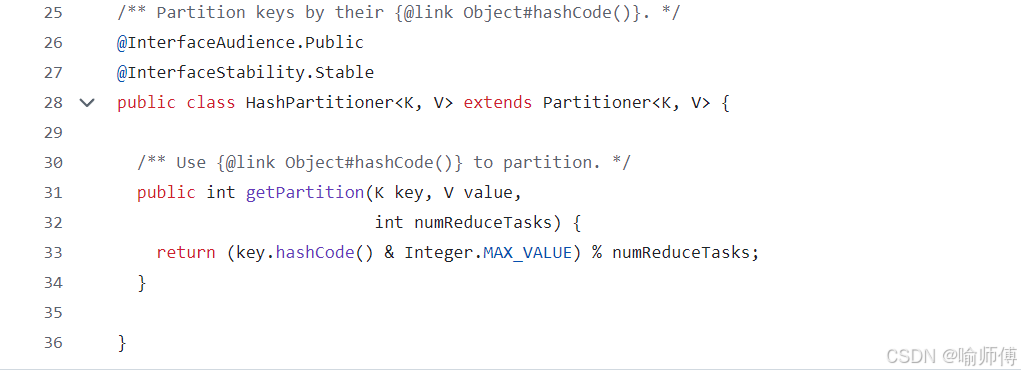
首先看一下MR默认分区器的源码是如何进行分区的:

再看一下官方文档的描述:
https://hadoop.apache.org/docs/stable/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html#Purpose
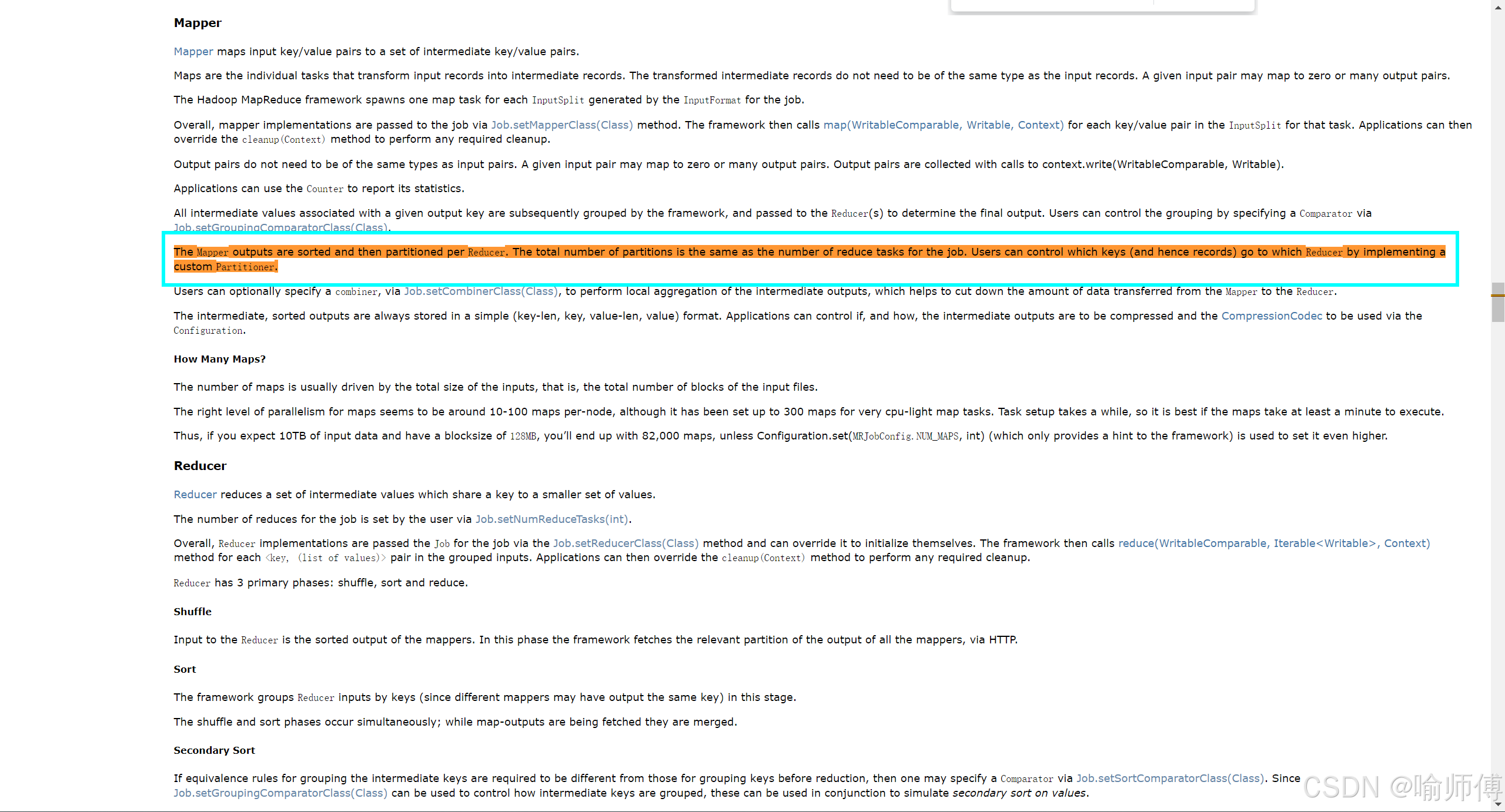
The Mapper outputs are sorted and then partitioned per Reducer.
The total number of partitions is the same as the number of reduce tasks for the job.
分区总数 = Reducer 任务数
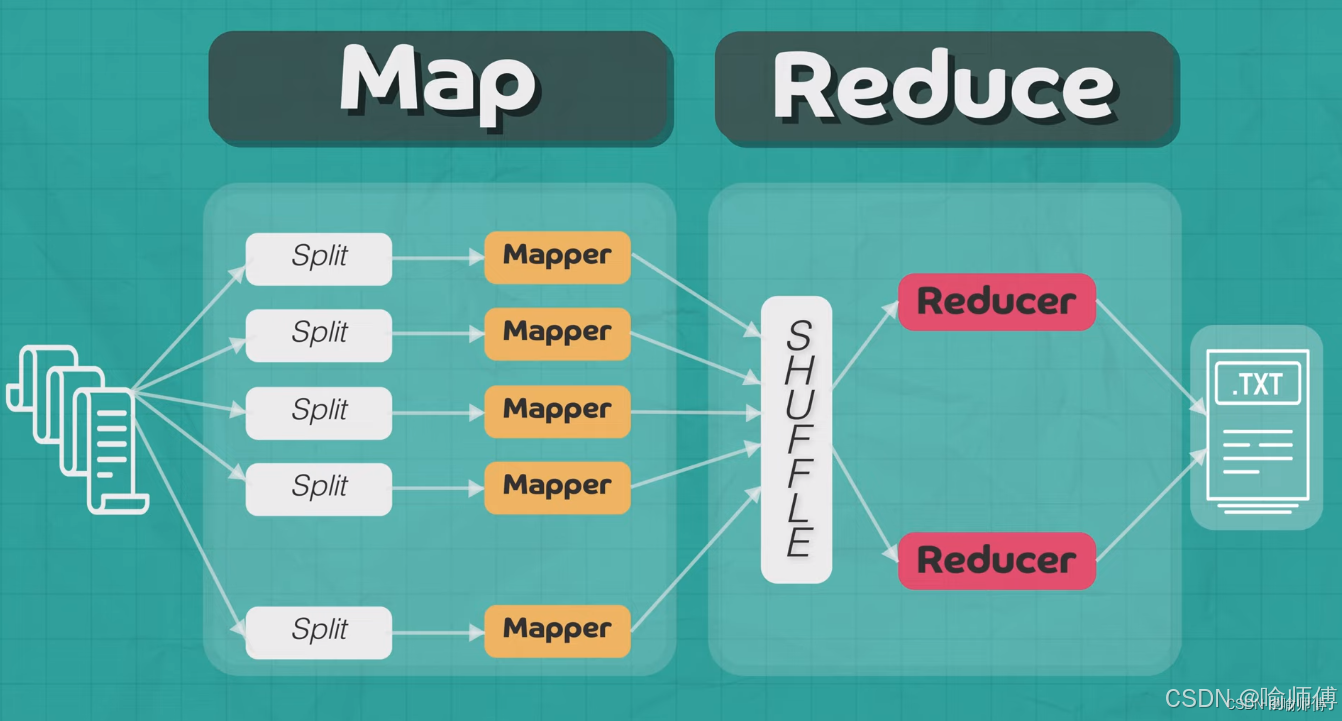
Map Output
↓
Partitioner → 分成 R 个分区(R = numReduceTasks)
↓
每个分区 → 对应一个 Reduce Task
https://hadoop.apache.org/docs/stable/api/org/apache/hadoop/mapreduce/lib/partition/HashPartitioner.html
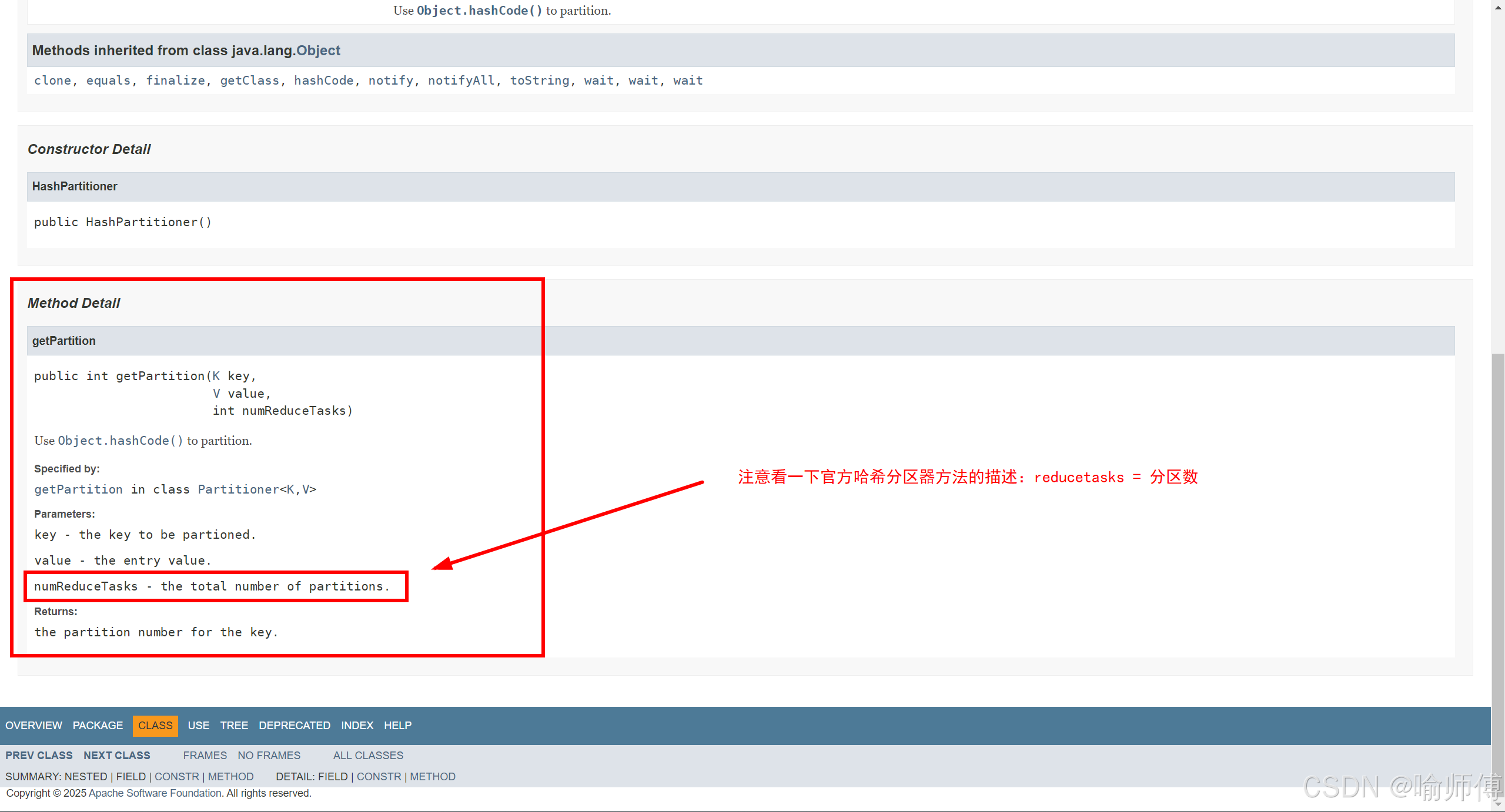
-
numPartitions = Reducer 任务数
-
% 表示取模运算,结果即为 Partition ID
-
因此,每个 key 的哈希值对 Reducer 数量取模,得到其所属分区编号
-
每个 <key, value> 被分配到一个 0 到 (numReduceTasks - 1) 的分区号
到这里大家应该可以很自信的回答面试官的问题了:

在 MapReduce 中,Map 阶段完成哈希分区后,系统是通过 ‘分区号(Partition ID)’ 和 ‘Reducer 任务编号’ 的一一对应关系’ 来确定数据发往哪个 Reducer 的。
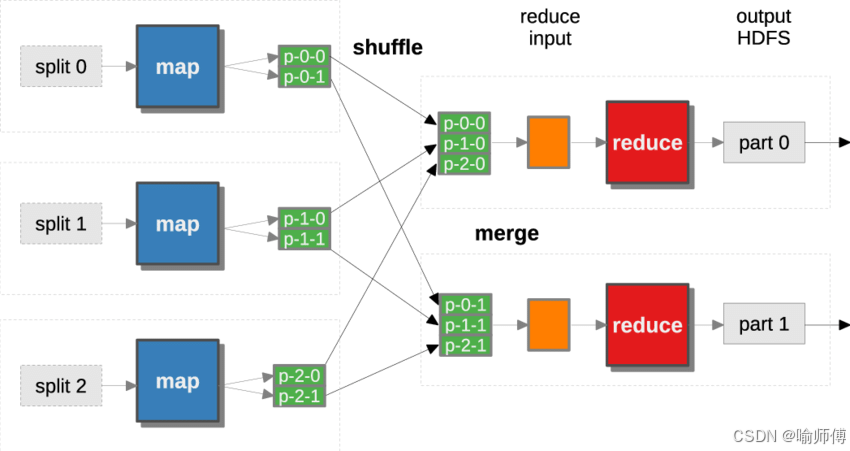
- 注意看图中数据的分布,两个reduce任务——两个分区,reduce-0 拉取 partition-0。

- Reducer-0:只接收所有 Map 的 partition 0 数据
- Reducer-1:只接收所有 Map 的 partition 1 数据
- Reducer-2:只接收所有 Map 的 partition 2 数据
tips:
谁决定数据发给哪个 Reducer? —— Map 端的 Partitioner
Reducer 怎么知道自己该收哪些数据?—— 它只拉取 partition ID = 自己编号 的数据
这里给大家拓展一下MapReduce的问题:
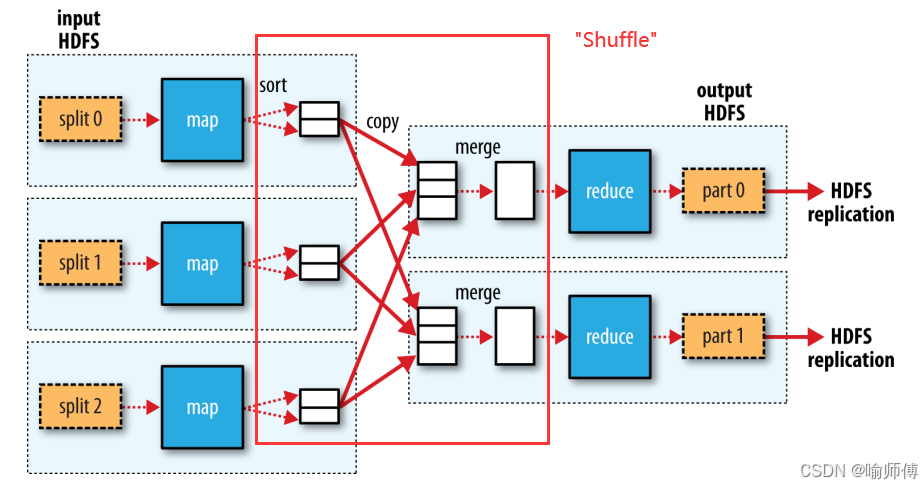
(1) Reducer 到底是“等数据上门”还是“主动出击去拉取”?
(2)MRshuffle过程通过什么网络协议进行网络传输?—— 可以引申到对计算机网络知识的考察。
能否自己去官方文档(相关书籍)或者hadoop源码中找到佐证自己想法的证据?这个过程非常有助于培养大家技术探索的能力。鼓励大家去做哈!

官方文档一句话解决这两个问题:

As described previously, each reduce fetches the output assigned to it by the Partitioner via HTTP into memory and periodically merges these outputs to disk.
(1) Reducer 到底是“等数据上门”还是“主动出击去拉取”?
- fetches(拉取):动词,主语是 reduce(即 Reducer)
- 意思是:Reducer 主动发起请求去拿数据 ,所以答案不是 Map 推送(push), 是 Reduce 拉取(pull)
Fetcher类源码地址:
https://github.com/apache/hadoop/blob/trunk/hadoop-mapreduce-project/hadoop-mapreduce-client/hadoop-mapreduce-client-core/src/main/java/org/apache/hadoop/mapreduce/task/reduce/Fetcher.java#L310
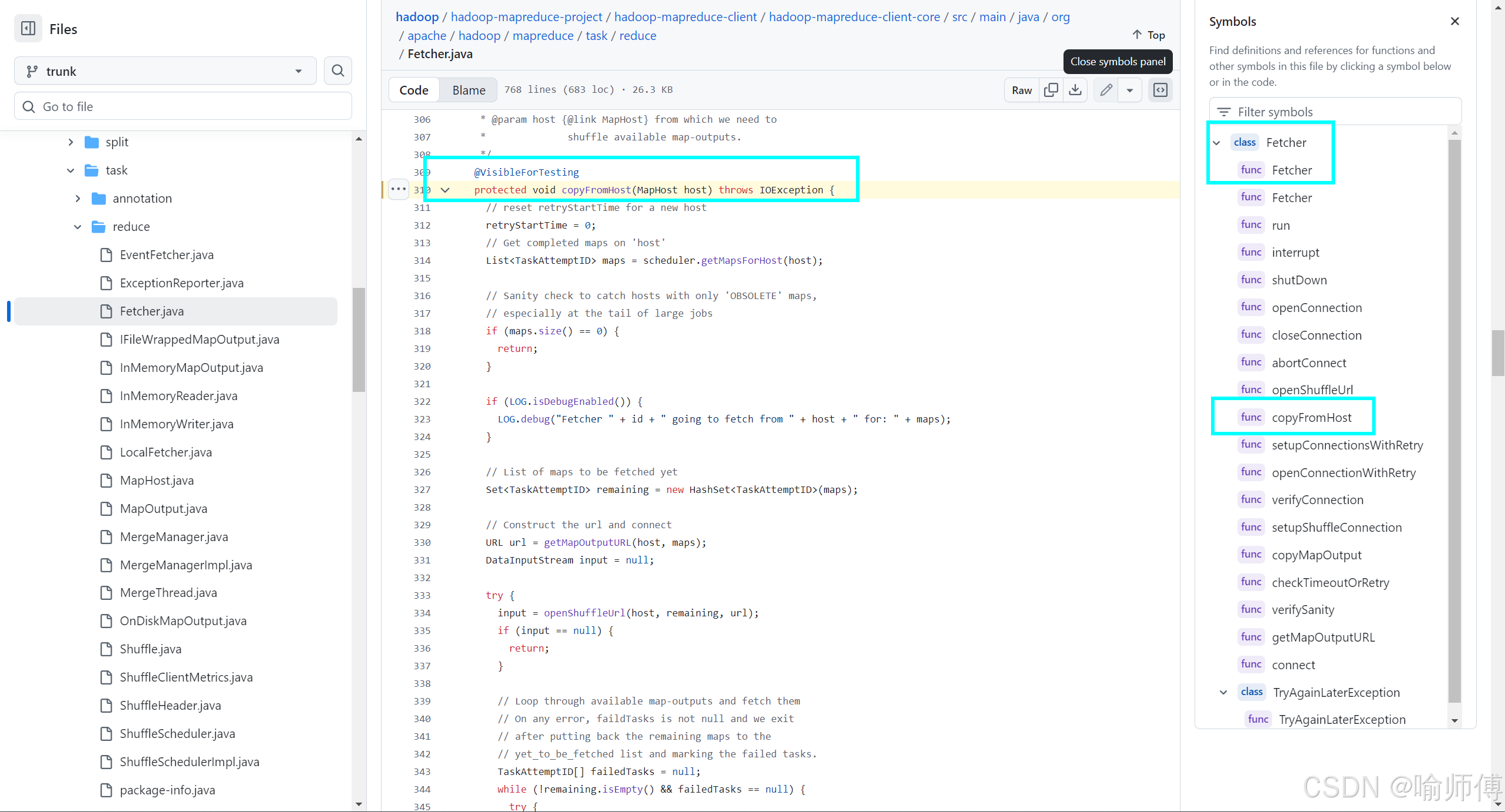
核心方法:copyFromHost(MapHost host)
- 这是整个类的核心逻辑。看名字就知道:从某个主机复制数据。
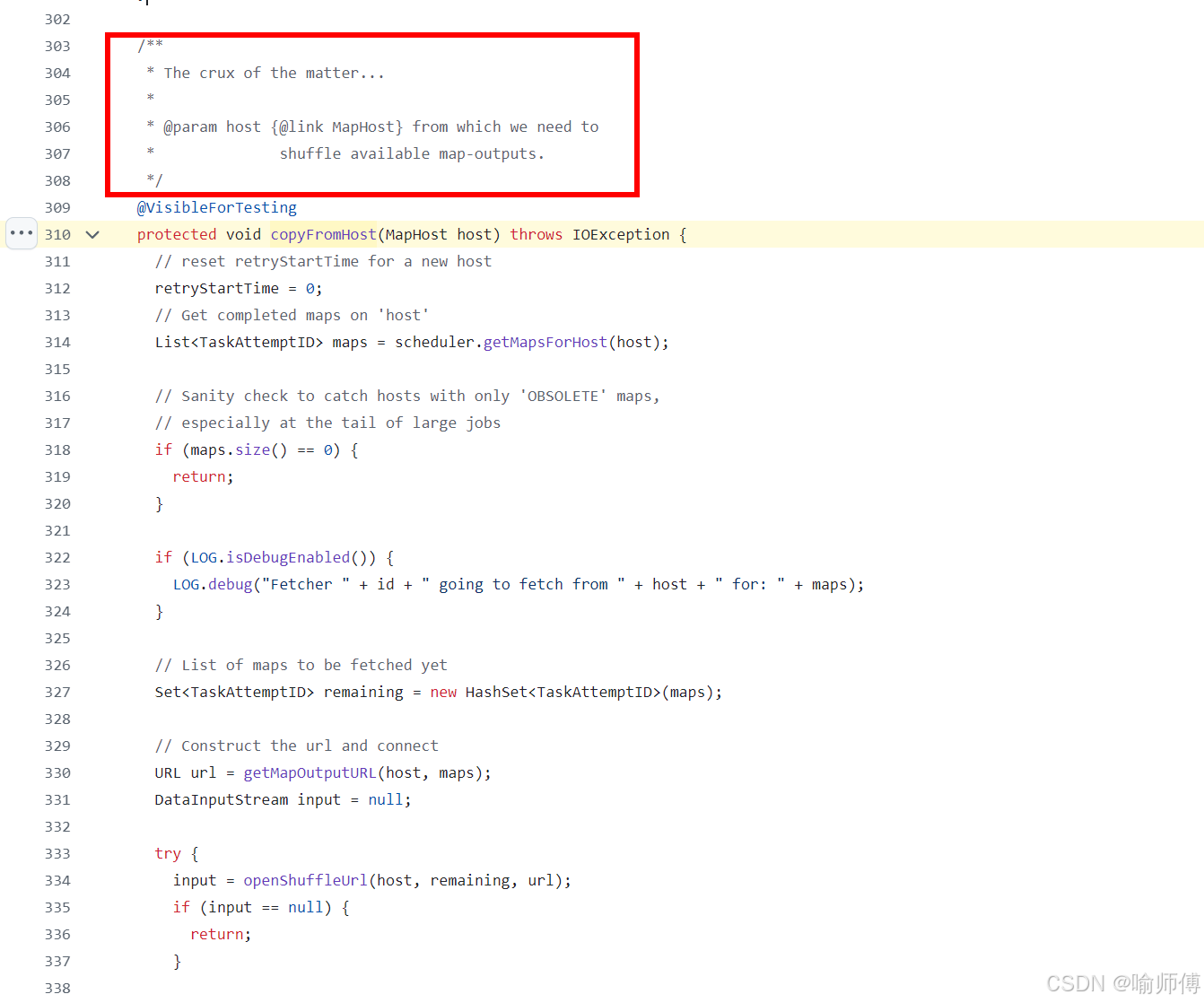
构造请求 URL:getMapOutputURL(…)
getMapOutputURL(…)方法拼接出:
http://map-node:8080/mapOutput?job=job_123&map=task_001,task_002,…的 URL。
然后通过这个 URL 向远端发起请求。
思考(面试官可能会问):你觉得为什么要这么设计?相对于map主动发送有什么好处?
我们思考一下——如果设计成 Map 主动把结果推送给 Reducer(Push 模式),会出现什么问题?
每个 Map Task 必须知道所有 Reducer 的网络位置和状态,才能把对应分区的数据发送过去,要求任务之间有复杂的协调机制(比如说ACK确认机制),系统耦合度高。
但相反pull拉取模式:
Map 任务只需将输出写入本地磁盘,并通过内置的 HTTP Server 暴露数据即可退出。它完全不需要关心 Reducer 是否存在、是否准备好、甚至是否失败——彻底实现了解耦。
(2)MRshuffle过程通过什么网络协议进行网络传输
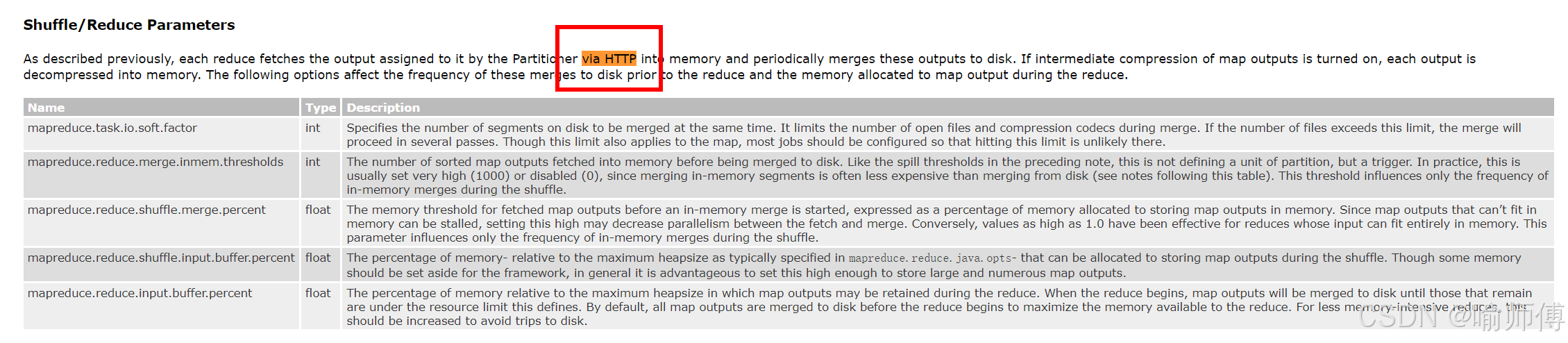
-
HTTP协议,这里是不是可以继续延伸,考察一下你对计算机网络的掌握捏?
-
通过HTTP协议,数据先拉到 内存 中(为了加速 reduce 处理) ;如果内存不够,才会 spill 到磁盘
MapReduce还是有很多细节值得大家去深挖去探索(后续会继续更新),博主在整理的过程中也学到了很多 ——常看常新!
希望大家下次再被面试官问到,直接反手掏出Hadoop源码…哈哈哈

好啦 整理不易 还希望大家多多点赞支持 您的支持就是博主更新的最大动力! 期待在这里能够遇到求知若渴的你!
