深度学习(五):过拟合、欠拟合与代价函数
深度学习模型的核心目标是 在训练数据上有效学习,同时在未知数据上保持良好的泛化能力。然而,实际训练中经常出现两类问题:
- 过拟合(Overfitting):模型过度拟合训练数据,在测试数据上表现不佳。
- 欠拟合(Underfitting):模型未能充分学习训练数据的规律,表现普遍较差。
此外,模型训练依赖于 代价函数(Cost Function),即衡量预测值与真实值之间差异的函数。代价函数不仅反映模型拟合程度,也是解决过拟合与欠拟合的重要工具。
过拟合(Overfitting)
定义
过拟合是指模型在训练集上表现很好,但在验证集和测试集上性能明显下降。其本质是 模型学习了训练数据中的噪声或偶然性规律,而非数据的本质特征。
典型特征
- 训练误差持续下降,但验证误差在达到最优点后开始上升。
- 在训练集上准确率极高,但在测试集上准确率低。
产生原因
- 模型复杂度过高(网络层数多、参数多)。
- 训练样本不足,难以支撑复杂模型。
- 数据噪声大,模型把噪声当作规律。
- 缺乏正则化手段。
常见解决方法
- 数据层面:增加训练数据量、数据增强。
- 模型层面:降低模型复杂度,减少层数或参数。
- 训练层面:
- 正则化(L1、L2、权值衰减)。
- Dropout 随机丢弃部分神经元。
- 提前停止(Early Stopping)。
- 批归一化(Batch Normalization)。
- 验证机制:交叉验证、留出验证集监控训练过程。
欠拟合(Underfitting)
定义
欠拟合是指模型在训练集和测试集上表现都不好,说明模型未能有效学习数据特征。
典型特征
- 训练误差和测试误差都较高。
- 模型在训练集上的表现已经很差,更不用说泛化能力。
产生原因
- 模型复杂度过低,无法表示数据特征。
- 特征不足或特征表达能力差。
- 学习率过高,导致训练未收敛。
- 训练次数不够,模型尚未学到有效规律。
常见解决方法
- 模型层面:提高模型复杂度(增加层数、神经元数)。
- 特征层面:提取更多有效特征,采用更强大的嵌入或预训练模型。
- 训练层面:
- 调整学习率,避免过大导致震荡。
- 延长训练时间,确保收敛。
- 使用更先进的优化算法(Adam、RMSprop)。
代价函数(Cost Function)
定义
代价函数用于衡量预测值与真实值之间的差异,是深度学习模型训练和优化的核心指标。优化目标就是 最小化代价函数。
常见代价函数
-
回归任务:
-
均方误差(MSE):
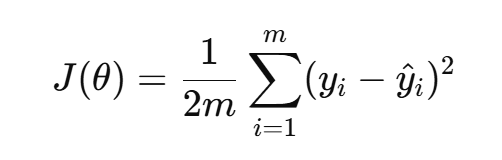
-
-
分类任务:
-
交叉熵损失(Cross-Entropy Loss):
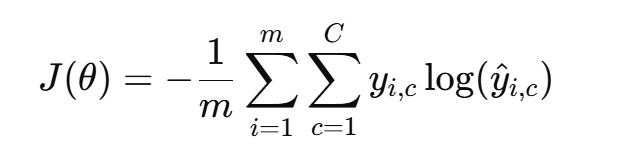
-
-
其他:
- Hinge Loss(SVM 中常用)。
- KL 散度(分布差异度量)。
代价函数与过拟合、欠拟合的关系
- 过拟合时:训练代价函数下降明显,但验证/测试代价函数先下降后上升。
- 欠拟合时:无论训练还是验证代价函数都较高,说明模型没有学到足够规律。
- 优化目标:寻找使训练误差和泛化误差都较低的参数。
引入正则化项
为了防止过拟合,代价函数中常加入正则化项:
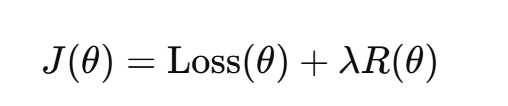
其中 R(θ) 可以是:
- L1 正则化:促进稀疏性。
- L2 正则化:抑制权重过大,提升模型稳定性。
- Dropout 等方式:在优化中隐式改变代价函数。
整体关系与训练策略
- 欠拟合 → 说明模型学习不足,需增加复杂度或延长训练。
- 过拟合 → 说明模型记忆过度,需简化模型或使用正则化。
- 代价函数 → 是监控过拟合/欠拟合的指标,通过训练误差与验证误差的走势来判断问题所在。
一个健康的训练过程表现为:
- 训练误差逐渐下降;
- 验证误差下降后趋于平稳;
- 测试误差接近验证误差,表明泛化能力良好。