小型语言模型:智能体AI的未来?
小型语言模型:智能体AI的未来?
本文解读NVIDIA研究团队论文,颠覆“越大越好”的语言模型认知,论证小型语言模型(SLMs)在智能体AI(Agentic AI)中的性能、经济性与适配性优势,结合案例与迁移算法,为Agentic系统低成本部署提供思路,回应行业对LLM依赖的惯性挑战。
论文标题:Small Language Models are the Future of Agentic AI
来源:arXiv:2506.02153 [cs.AI],链接:http://arxiv.org/abs/2506.02153
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 亚里随笔」 即刻免费解锁
文章核心
研究背景
智能体AI系统增长迅猛:2025年超半数大型IT企业部署AI智能体,2024年末该领域初创融资超20亿美元,市场规模52亿美元,预计2034年达近2000亿美元。当前Agentic系统以大型语言模型(LLMs)为核心,依赖中心化云基础设施的LLM API服务,2024年LLM API市场规模约56亿美元,配套云基础设施投资却高达570亿美元。但Agentic系统实际任务多为重复性、专业化且非对话式,通用LLM的“全能力”与系统需求错配,导致资源浪费、成本高企,为SLM应用创造空间。
研究问题
- 资源错配:Agentic系统多数子任务仅需窄域功能,却依赖通用LLM,过度消耗计算资源,不符合经济与环境可持续性。
- 部署局限:LLM依赖中心化云基础设施,存在高延迟、高维护成本问题,难以适配边缘设备,限制Agentic系统灵活性与普及性。
- 行业惯性:LLM API运营模式深度嵌入行业,前期基础设施投资与“通用优于专用”认知,阻碍SLM规模化应用。
主要贡献
- 理论定位:首次明确“SLMs是Agentic AI未来”,从性能充足性(V1)、运营适配性(V2)、经济性(V3)论证SLM优势,填补模型选型理论空白。
- 性能验证:通过Phi系列、Nemotron-H等SLM实证,证明其在常识推理、工具调用等Agentic核心任务上媲美甚至超越前代LLM,且具备推理增强潜力。
- 迁移路径:提出“LLM-to-SLM智能体转换算法”,涵盖数据采集、清洗、聚类等步骤,为系统迁移提供落地方案。
- 辩证分析:梳理行业对SLM的质疑,从架构创新、推理优化等角度反驳,提供中立参考框架。
思维导图
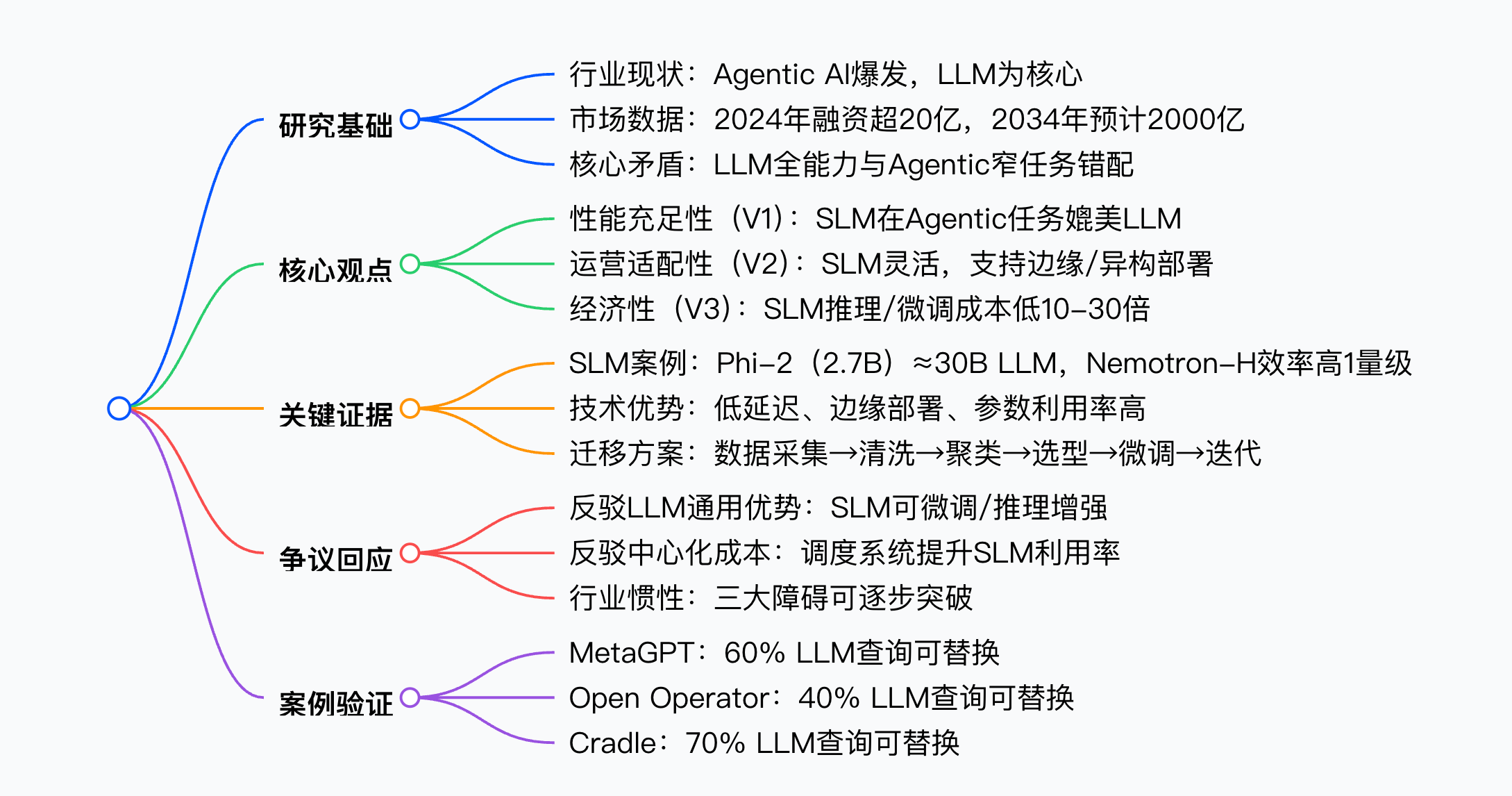
方法论精要
1. 核心定义与边界设定
- WD1(SLM):可部署于普通消费电子设备,推理延迟满足单用户Agentic请求的语言模型,2025年参数低于100亿的模型普遍符合。
- WD2(LLM):不符合SLM定义的语言模型,需依赖数据中心级基础设施。
定义以“消费级设备部署+低延迟”为锚点,避免绑定硬件依赖的参数指标,确保随技术演进仍具参考价值。
2. SLM优势论证框架
(1)性能充足性(支持V1)
- Microsoft Phi-2(2.7B)在常识推理与代码生成上媲美30B LLM,速度快15倍;Phi-3 Small(7B)对标70B同代LLM。
- NVIDIA Nemotron-H(2/4.8/9B)指令跟随与代码生成准确率媲美30B稠密LLM,推理FLOPs仅为1/10。
- Salesforce xLAM-2-8B(8B)工具调用性能超GPT-4o、Claude 3.5。
- 通过自一致性、工具增强(如Toolformer 6.7B),1-3B SLM在数学问题上可匹敌30B+ LLM。
(2)经济性(支持V3)
- 推理效率:7B SLM成本比70-175B LLM低10-30倍,NVIDIA Dynamo优化云/边缘部署。
- 微调敏捷性:SLM微调仅需数小时GPU时长,实现“隔夜迭代”,LLM需数周。
- 边缘部署:ChatRTX支持SLM在消费级GPU本地运行,实现离线推理与数据隐私控制。
- 参数利用率:SLM参数激活比例更高,无“无效参数成本”,无需跨GPU并行,维护成本低。
(3)灵活性与适配性(支持V2)
- 模块化适配:SLM可作为“专用专家模型”嵌入Agentic系统,异构架构中SLM处理常规任务,LLM按需调用。
- 快速迭代:SLM微调成本低,可快速适配新行为、格式或法规,LLM难以满足动态需求。
- 民主化潜力:SLM降低开发门槛,促进多样性,减少偏见,推动创新。
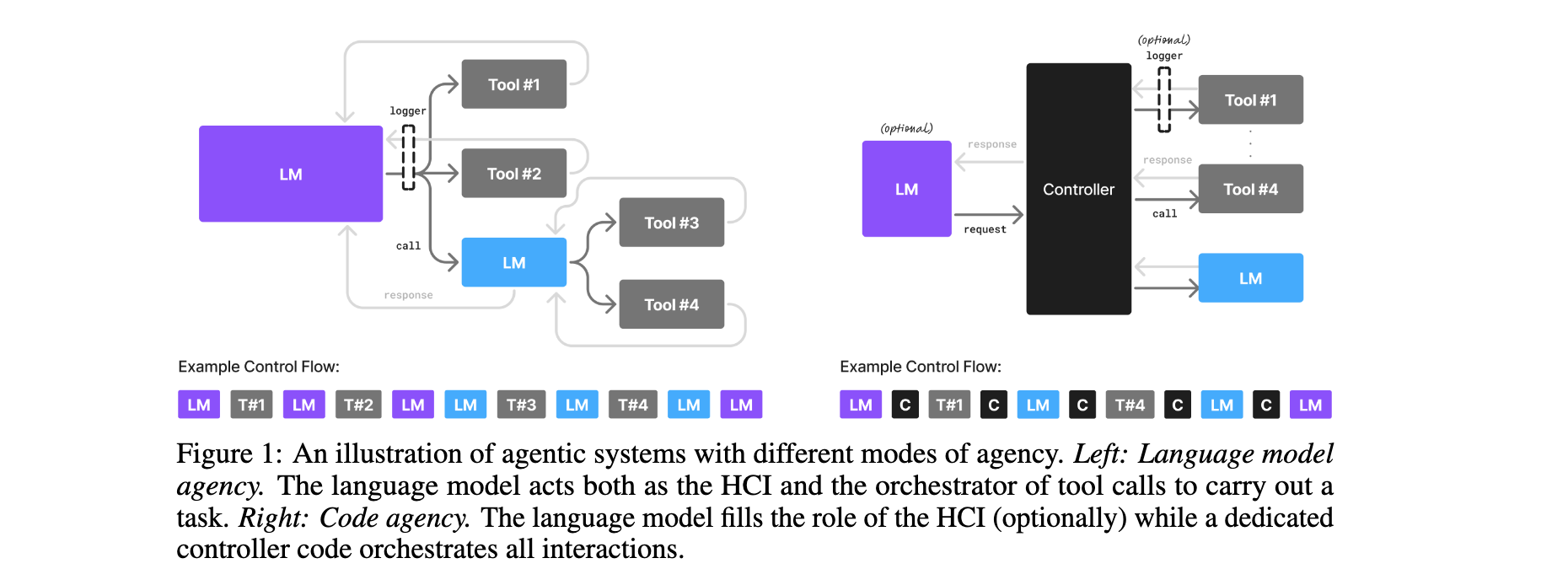
3. LLM-to-SLM智能体转换算法
S1:安全数据采集
记录非人机交互的智能体调用,含输入提示、输出响应等,采用加密日志与RBAC,匿名化数据来源。
S2:数据清洗与过滤
收集10k-100k示例后,移除敏感数据,用自动化工具处理,对特定输入重述模糊实体。
S3:任务聚类
无监督聚类识别重复任务模式,定义SLM专用任务(如意图识别、特定文档摘要)。
S4:SLM选型
基于任务需求、基准性能、许可证及部署 footprint 选择候选模型。
S5:专用SLM微调
为每个任务构建数据集,采用LoRA/QLoRA或全参数微调,必要时用知识蒸馏。
S6:迭代与优化
定期用新数据重训SLM与路由模型,形成持续优化闭环。
实验洞察
1. SLM性能验证:与LLM对比
| SLM模型 | 参数 | 核心任务 | 对比LLM | 性能 | 效率优势 |
|---|---|---|---|---|---|
| Microsoft Phi-2 | 2.7B | 常识推理、代码生成 | 30B同代LLM | 持平 | 速度快15倍 |
| NVIDIA Nemotron-H | 2/4.8/9B | 指令跟随、代码生成 | 30B稠密LLM | 持平 | 推理FLOPs低1量级 |
| NVIDIA Hymba-1.5B | 1.5B | 指令跟随 | 13B LLM | 超越 | 吞吐量高3.5倍 |
| Salesforce xLAM-2-8B | 8B | 工具调用 | GPT-4o、Claude 3.5 | SOTA,超越 | - |
| DeepMind RETRO-7.5B | 7.5B | 语言建模 | GPT-3(175B) | 持平 | 参数少25倍 |
2. 案例研究:LLM-to-SLM替换潜力
案例1:MetaGPT(多智能体软件开发)
- 用途:模拟软件公司流程,处理需求、设计、代码等任务。
- LLM调用:角色任务、结构化输出、动态规划。
- 替换潜力:60%,SLM处理常规代码、模板文档,LLM处理架构设计。
案例2:Open Operator(工作流自动化)
- 用途:实现API调用、监控等自动化任务。
- LLM调用:意图解析、流程决策、报告生成。
- 替换潜力:40%,SLM处理简单指令,LLM处理多步骤推理。
案例3:Cradle(通用计算机控制)
- 用途:通过截图与模拟交互操作GUI应用。
- LLM调用:界面理解、任务规划、错误处理。
- 替换潜力:70%,SLM处理重复交互,LLM处理动态界面适应。
3. 关键争议的实证回应
争议1:“LLM通用理解优于SLM”
- 反驳:SLM用专用架构(如Mamba-Transformer)突破参数限制;可微调适配任务;Agentic子任务无需复杂语义抽象。
争议2:“LLM中心化部署更经济”
- 反驳:Dynamo等调度系统提升SLM利用率;SLM基础设施成本持续下降,LLM成本高企。
争议3:“LLM智能体形成行业惯性”
- 反驳:SLM边缘部署突破基础设施惯性;Agentic专用基准兴起;经济优势将改变认知。
4. 核心结论与启示
SLM在Agentic AI中“性能可行、经济优势显著、技术路径清晰”,启示包括:
- 模型选型从“追大参数”转向“任务匹配”;
- SLM可降低Agentic系统成本10-30倍,加速中小企业部署;
- 短期“SLM+LLM”异构架构平衡成本与性能,长期SLM成核心;
- 需建立SLM专用基准与工具链,推动行业协作。