小目标检测:FFCA-YOLO详解
前言
FFCA-YOLO是2024年发表在 IEEE Transactions on Geoscience and Remote Sensing 上的文章,主要为了解决遥感小目标检测任务中特征表示不足、背景混淆等问题。核心的架构采用的是yolov5,提出了三个创新模块,特征增强模块(FEM)、特征融合模块(FFM)和空间上下文感知模块(SCAM)。我们这里对其模块做一个详解,以便给我们自己的改进提供思路。
原文:FFCA-YOLO for Small Object Detection in Remote Sensing Images
代码:yemu1138178251/FFCA-YOLO
特征增强模块FEM
文章里面提到FEM是采用多分支卷积结构提取多个判别性语义信息。从扩大感受野的角度出发,应用扩张卷积获得更丰富的局部上下文信息。不过,这里的图我感觉有点问题,按照代码里面所写,从上到下三个分支是进行了concat的融合,第四条分支是作为了short cut,图中更像是四条分支的融合。
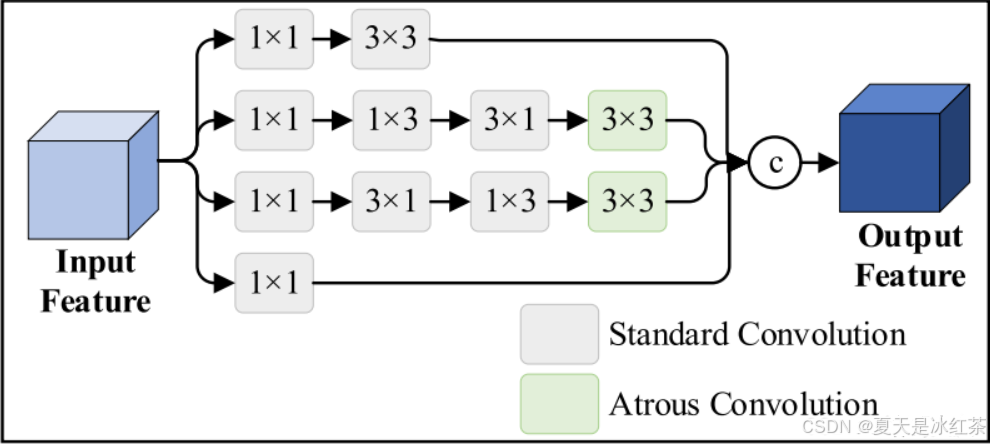
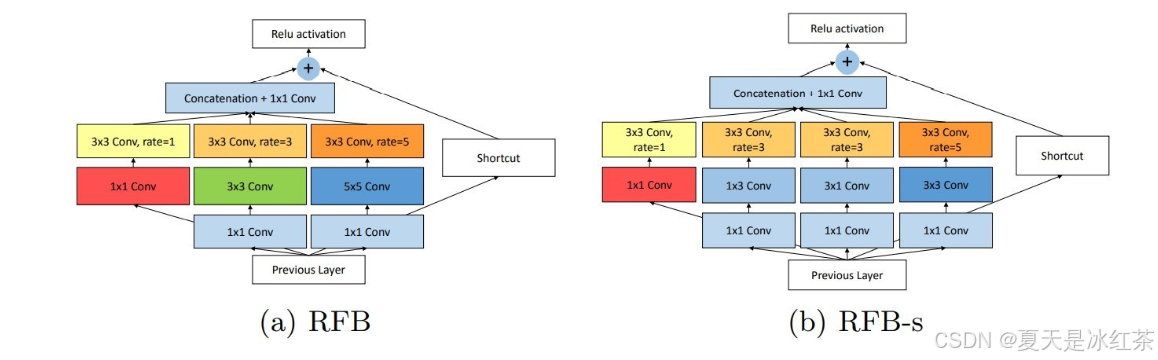
作者说这个模块的设计灵感来源于RFB-s,也就是下图的(b),而RFB这个模块的多分支的卷积主要是借鉴了Googlenet的思想,空洞卷积的设置主要是借鉴了ASPP的思想。说明经典的思想还是能做出新的工作。
因此,这两个模块的代码我们还是有必要去对比了解一下的。
FEM模块采用三条并行分支结构,分支一运用1×1卷积进行通道维度调整,再通过3×3卷积提取基础空间特征,为网络提供稳定的特征基底;分支二首先使用1×1卷积实现通道降维,接着采用水平-垂直分离卷积策略有效减少参数量,最后通过空洞卷积(dilation=5)显著扩大感受野,捕获丰富的多尺度上下文信息;分支三采用与分支二对称而互补的设计架构,通过垂直-水平分离卷积序列,为网络提供方向性互补的特征信息,进一步增强特征表达的多样性。
后面经过了特征融合后进行残差连接,但这里却是将融合后的特征只占了0.1,我看作者也没有介绍这部分的原因,可能是照搬了RFB-s后续的处理吧。
RFB-s的三个分支,构成了一个渐进式的特征金字塔,分支一捕获局部细节特征(小感受野);分支二捕获中等范围上下文(中感受野);分支三捕获全局上下文信息(大感受野)。
这种三分支处理后融合的方法算是一种常见的方法,比如去雾领域的MixDehazeNet就是三分支的不同感受野的空洞卷积通道拼接后接mlp。
那这个给了我们思路呢,比如我们可以拿上图的(a) RFB进行改进,你就可以参考这块的FEM,做一个方向性互补的特征信息,或者是保留它本身的一个空洞卷积的金字塔结构,这样就又是一个新的模块了。
import torch
import torch.nn as nnclass ConvNormAct(nn.Module):def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1,norm_layer=nn.BatchNorm2d, activation_layer=nn.ReLU, inplace=True, bias=True, apply_act=True):super(ConvNormAct, self).__init__()self.in_channels = in_channelsself.out_channels = out_channelsself.apply_act = apply_actself.conv = nn.Conv2d(self.in_channels, self.out_channels, kernel_size, stride, padding=padding,dilation=dilation, groups=groups, bias=bias)self.norm = norm_layer(out_channels) if norm_layer else Noneself.act = activation_layer(inplace) if activation_layer else Nonedef forward(self, x):x = self.conv(x)if self.norm:x = self.norm(x)if self.act and self.apply_act:x = self.act(x)return xclass FEM(nn.Module):def __init__(self, in_channels, out_channels, stride=1, scale=0.1, map_reduce=8):super(FEM, self).__init__()self.scale = scaleself.out_channels = out_channelsinter_planes = in_channels // map_reduceself.branch0 = nn.Sequential(ConvNormAct(in_channels, 2 * inter_planes, kernel_size=1, stride=stride),ConvNormAct(2 * inter_planes, 2 * inter_planes, kernel_size=3, stride=1, padding=1, apply_act=False))self.branch1 = nn.Sequential(ConvNormAct(in_channels, inter_planes, kernel_size=1, stride=1),ConvNormAct(inter_planes, (inter_planes // 2) * 3, kernel_size=(1, 3), stride=stride, padding=(0, 1)),ConvNormAct((inter_planes // 2) * 3, 2 * inter_planes, kernel_size=(3, 1), stride=stride, padding=(1, 0)),ConvNormAct(2 * inter_planes, 2 * inter_planes, kernel_size=3, stride=1, padding=5, dilation=5, apply_act=False))self.branch2 = nn.Sequential(ConvNormAct(in_channels, inter_planes, kernel_size=1, stride=1),ConvNormAct(inter_planes, (inter_planes // 2) * 3, kernel_size=(3, 1), stride=stride, padding=(1, 0)),ConvNormAct((inter_planes // 2) * 3, 2 * inter_planes, kernel_size=(1, 3), stride=stride, padding=(0, 1)),ConvNormAct(2 * inter_planes, 2 * inter_planes, kernel_size=3, stride=1, padding=5, dilation=5, apply_act=False))self.ConvLinear = ConvNormAct(6 * inter_planes, out_channels, kernel_size=1, stride=1, apply_act=False)self.shortcut = ConvNormAct(in_channels, out_channels, kernel_size=1, stride=stride, apply_act=False)self.relu = nn.ReLU(inplace=False)def forward(self, x):x0 = self.branch0(x)x1 = self.branch1(x)x2 = self.branch2(x)out = torch.cat((x0, x1, x2), 1)out = self.ConvLinear(out)short = self.shortcut(x)out = out * self.scale + shortout = self.relu(out)return outclass RFB_s(nn.Module):def __init__(self, in_channels, out_channels, stride=1, scale=0.1, visual=1):super(RFB_s, self).__init__()self.scale = scaleself.out_channels = out_channelsinter_planes = in_channels // 8self.branch0 = nn.Sequential(ConvNormAct(in_channels, 2 * inter_planes, kernel_size=1, stride=stride),ConvNormAct(2 * inter_planes, 2 * inter_planes, kernel_size=3, stride=1, padding=visual, dilation=visual,apply_act=False))self.branch1 = nn.Sequential(ConvNormAct(in_channels, inter_planes, kernel_size=1, stride=1),ConvNormAct(inter_planes, 2 * inter_planes, kernel_size=3, stride=stride, padding=1),ConvNormAct(2 * inter_planes, 2 * inter_planes, kernel_size=3, stride=1, padding=visual + 1,dilation=visual + 1, apply_act=False))self.branch2 = nn.Sequential(ConvNormAct(in_channels, inter_planes, kernel_size=1, stride=1),ConvNormAct(inter_planes, (inter_planes // 2) * 3, kernel_size=3, stride=1, padding=1),ConvNormAct((inter_planes // 2) * 3, 2 * inter_planes, kernel_size=3, stride=stride, padding=1),ConvNormAct(2 * inter_planes, 2 * inter_planes, kernel_size=3, stride=1, padding=2 * visual + 1,dilation=2 * visual + 1, apply_act=False))self.ConvLinear = ConvNormAct(6 * inter_planes, out_channels, kernel_size=1, stride=1, apply_act=False)self.shortcut = ConvNormAct(in_channels, out_channels, kernel_size=1, stride=stride, apply_act=False)self.relu = nn.ReLU(inplace=False)def forward(self, x):x0 = self.branch0(x)x1 = self.branch1(x)x2 = self.branch2(x)out = torch.cat((x0, x1, x2), 1)out = self.ConvLinear(out)short = self.shortcut(x)out = out * self.scale + shortout = self.relu(out)return outif __name__=="__main__":in_channels = 64out_channels = 128batch_size = 4height, width = 32, 32fem = FEM(in_channels=in_channels, out_channels=out_channels)rfb_s = RFB_s(in_channels=in_channels, out_channels=out_channels)x = torch.randn(batch_size, in_channels, height, width)print(f"Input: {x.shape}")output = fem(x)print(f"Output: {output.shape}")output = rfb_s(x)print(f"Output: {output.shape}")
再更,后面翻看了一下RFBNet_Pytorch,这个仓库的网络代码,发现原文的FEM里面的方向性互补的特征信息就是RFB-a的内容,那这么看来,完全就是修改了一下空洞率,然后减了一个分支。
class BasicRFB_a(nn.Module):def __init__(self, in_planes, out_planes, stride=1, scale = 0.1):super(BasicRFB_a, self).__init__()self.scale = scaleself.out_channels = out_planesinter_planes = in_planes //4self.branch0 = nn.Sequential(BasicConv(in_planes, inter_planes, kernel_size=1, stride=1),BasicConv(inter_planes, inter_planes, kernel_size=3, stride=1, padding=1,relu=False))self.branch1 = nn.Sequential(BasicConv(in_planes, inter_planes, kernel_size=1, stride=1),BasicConv(inter_planes, inter_planes, kernel_size=(3,1), stride=1, padding=(1,0)),BasicConv(inter_planes, inter_planes, kernel_size=3, stride=1, padding=3, dilation=3, relu=False))self.branch2 = nn.Sequential(BasicConv(in_planes, inter_planes, kernel_size=1, stride=1),BasicConv(inter_planes, inter_planes, kernel_size=(1,3), stride=stride, padding=(0,1)),BasicConv(inter_planes, inter_planes, kernel_size=3, stride=1, padding=3, dilation=3, relu=False))self.branch3 = nn.Sequential(BasicConv(in_planes, inter_planes//2, kernel_size=1, stride=1),BasicConv(inter_planes//2, (inter_planes//4)*3, kernel_size=(1,3), stride=1, padding=(0,1)),BasicConv((inter_planes//4)*3, inter_planes, kernel_size=(3,1), stride=stride, padding=(1,0)),BasicConv(inter_planes, inter_planes, kernel_size=3, stride=1, padding=5, dilation=5, relu=False))self.ConvLinear = BasicConv(4*inter_planes, out_planes, kernel_size=1, stride=1, relu=False)self.shortcut = BasicConv(in_planes, out_planes, kernel_size=1, stride=stride, relu=False)self.relu = nn.ReLU(inplace=False)def forward(self,x):x0 = self.branch0(x)x1 = self.branch1(x)x2 = self.branch2(x)x3 = self.branch3(x)out = torch.cat((x0,x1,x2,x3),1)out = self.ConvLinear(out)short = self.shortcut(x)out = out*self.scale + shortout = self.relu(out)return out特征融合模块FFM
高级和低级特征映射包含不同的语义信息,多尺度特征图的特征聚合可以增强小目标的语义表示。所提出的FFM采用基于BiFPN的颈部结构。与BiFPN不同,FFM改进了名为CRC的重权策略,并调整了原始的BiFPN以适应三个检测头。
其实很多的特征融合模块还不如通道拼接concat融合方法,别看有些搞得花里胡哨的,常用的方法也就是根据输入的几个特征重新计算权重后再进行通道拼接,再好一点就是利用上频域的信息,大家自己缝合模块可以试试这些方法,借鉴一下,毕竟如果直接进行concat怎么能算一个创新点呢?我觉得至少借鉴2到3个分配权重的方法,组合融合一下只要有稍稍的提升或者只要没有降点,从发论文的角度来说那就能够算是一个创新点了。
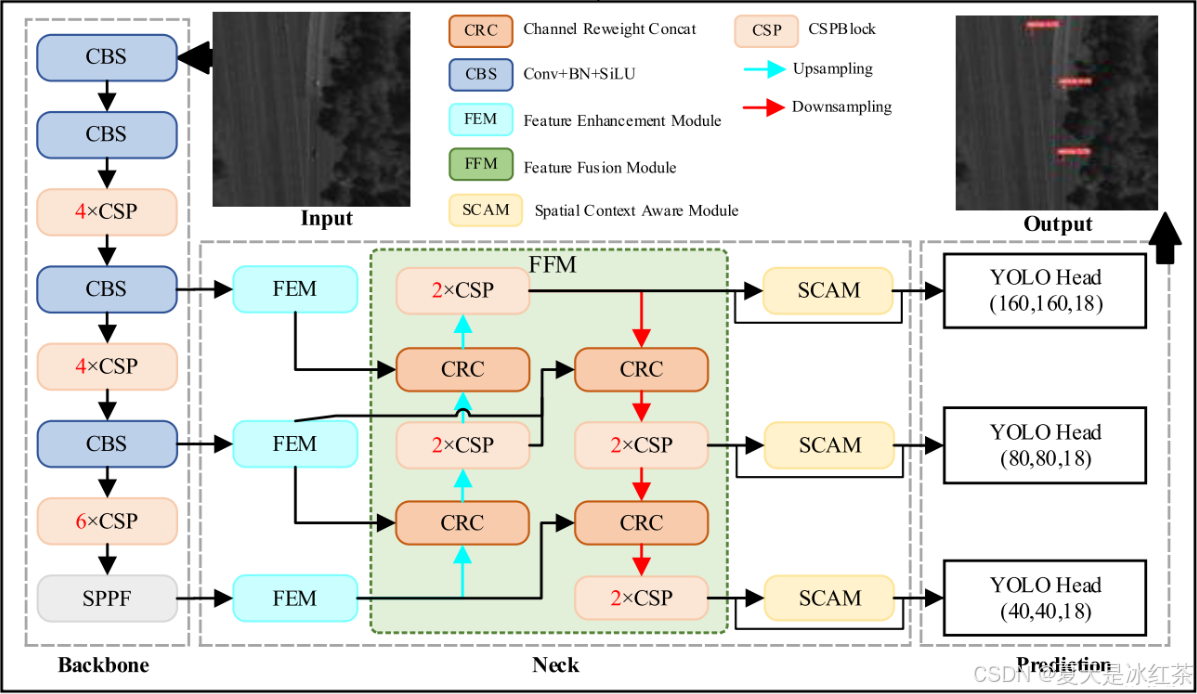
这里就是引入了可学习权重,类似注意力机制,让网络自动学不同通道的重要性。这个地方的权重应该是参考的softmax的方法,让其总和为1,这样可以保证融合过程中数值稳定,不会出现梯度爆炸,最后的就是我前面讲的通道concat的方式。
关于这里的二输入和三输入,不管有多少,就仅仅是加了一个可学习的权重,在前向传播时,每个特征图通道都会乘以对应的权重,但这种方式在很多的地方都用过了,比如SE等注意力,只不过没有额外引入全局池化或全连接层,而是直接对每个通道引入一个独立的可学习因子。
然后在写论文的时候你就可以说:
相较于传统的直接通道融合方法,我们在特征融合过程中引入了可学习的通道权重。该设计不仅能够突出关键特征、抑制冗余信息,还能通过归一化约束保持数值稳定,避免梯度异常。此外,相比于 SE 等注意力机制,我们的方法更加轻量化,无需额外的全局池化或全连接层,能够在较低计算开销下实现更加有效的特征选择。
class FFMConcat2(nn.Module):def __init__(self, dimension=1, channel_1=1, channel_2=1):super(FFMConcat2, self).__init__()self.d = dimensionself.channel_1 = channel_1self.channel_2 = channel_2self.channel_all = int(channel_1 + channel_2)self.w = nn.Parameter(torch.ones(self.channel_all, dtype=torch.float32), requires_grad=True)self.epsilon = 0.0001def forward(self, x):N1, C1, H1, W1 = x[0].size()N2, C2, H2, W2 = x[1].size()w = self.w[:(C1 + C2)]weight = w / (torch.sum(w, dim=0) + self.epsilon)x1 = (weight[:C1] * x[0].view(N1, H1, W1, C1)).view(N1, C1, H1, W1)x2 = (weight[C1:] * x[1].view(N2, H2, W2, C2)).view(N2, C2, H2, W2)return torch.cat([x1, x2], self.d)class FFMConcat3(nn.Module):def __init__(self, dimension=1, channel_1=1, channel_2=1, channel_3=1):super(FFMConcat3, self).__init__()self.d = dimensionself.channel_1 = channel_1self.channel_2 = channel_2self.channel_3 = channel_3self.channel_all = int(channel_1 + channel_2 + channel_3)self.w = nn.Parameter(torch.ones(self.channel_all, dtype=torch.float32), requires_grad=True)self.epsilon = 0.0001def forward(self, x):N1, C1, H1, W1 = x[0].size()N2, C2, H2, W2 = x[1].size()N3, C3, H3, W3 = x[2].size()w = self.w[:(C1 + C2 + C3)]weight = w / (torch.sum(w, dim=0) + self.epsilon)x1 = (weight[:C1] * x[0].view(N1, H1, W1, C1)).view(N1, C1, H1, W1)x2 = (weight[C1:(C1 + C2)] * x[1].view(N2, H2, W2, C2)).view(N2, C2, H2, W2)x3 = (weight[(C1 + C2):] * x[2].view(N3, H3, W3, C3)).view(N3, C3, H3, W3)return torch.cat([x1, x2, x3], self.d)这里我对上面的代码进行了修改,把通道数的总和直接在外部求解:
class FFMConcat(nn.Module):def __init__(self, total_channel, eps=1e-4):"""total_channel: sum of all input channelseps: A small constant to prevent division by zero."""super(FFMConcat, self).__init__()self.eps = eps# The total sum of external input channelsself.total_channel = total_channel# Learnable weights (one weight per channel)self.w = nn.Parameter(torch.ones(total_channel, dtype=torch.float32), requires_grad=True)def forward(self, x: list):"""x: list of feature maps [x1, x2, ..., xN]"""B, _, H, W = x[0].shape# Check if the total number of channels matches.channels = [xi.shape[1] for xi in x]assert sum(channels) == self.total_channel, \f"The sum of input channels {sum(channels)} does not match the defined total_channel={self.total_channel}"weight = self.w / (torch.sum(self.w, dim=0) + self.eps)outs = []start = 0for i, xi in enumerate(x):# Check if the space dimensions are consistent.assert xi.shape[2:] == (H, W), f"The size of the {i}th input space {xi.shape[2:]} does not match the first input {H, W}."ci = xi.shape[1]wi = weight[start:start + ci]# First move the channel to the end, then multiply them channel by channel, and finally move it back.xi_weighted = (wi * xi.permute(0, 2, 3, 1)).permute(0, 3, 1, 2)outs.append(xi_weighted)start += cireturn torch.cat(outs, dim=1)这属于是一个通用版本的,这样我就不用考虑太多的参数输入,后面的我们也使用这个做消融实验
空间上下文感知模块SCAM
在经过FEM与FFM之后,特征图已经考虑了局部上下文信息,并且能够很好地表示小目标特征。在此阶段对小目标和背景之间的全局关系进行建模比在主干阶段更有效。利用全局上下文信息来表示像素之间的跨空间关系,可以抑制无用背景,增强目标和背景的区分能力。
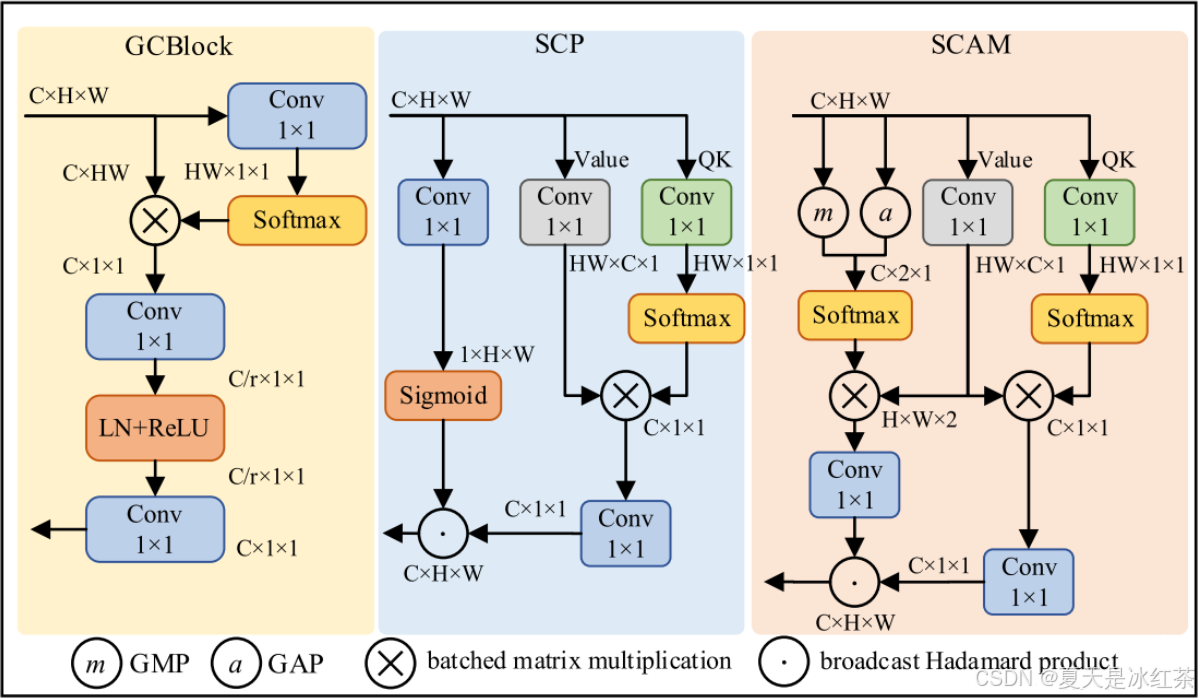
作者说是受GCNet和SCP的启发,我们从图就可以看出SCAM 模块由三个分支组成,可以看作是一种卷积版的 QKV 结构。
第一分支用于全局信息建模,GAP 可以捕捉全局的统计特征,GMP 更关注显著性区域,然后二者结合获得对整体特征分布更全面的理解;
第二分支Value 生成,使用 1×1 卷积对输入特征进行线性变换,生成特征映射,这一分支的输出就是后续用于加权的基础特征表征;
第三分支QK 生成,同样使用 1×1 卷积,来简化生成 Query (Q) 和 Key (K)。与 Transformer 中的 QK 类似,这一步主要用于构建特征间的关系矩阵。
随后,第一分支(全局信息)和第三分支(QK)分别与第二分支(Value)进行矩阵相乘,从而得到:跨通道的上下文信息,跨空间的上下文信息,最后,将这两部分结果通过 Hadamard 积(逐元素相乘) 进行融合,得到最终的 SCAM 输出。
# Conv是官方的实现,ConvWithoutBN是官方的Conv除去BN层,激活函数还是使用SiLU
class SCAM(nn.Module):def __init__(self, in_channels, reduction=1):super(SCAM, self).__init__()self.in_channels = in_channelsself.inter_channels = in_channelsself.k = Conv(in_channels, 1, 1, 1)self.v = Conv(in_channels, self.inter_channels, 1, 1)self.m = ConvWithoutBN(self.inter_channels, in_channels, 1, 1)self.m2 = Conv(2, 1, 1, 1)self.avg_pool = nn.AdaptiveAvgPool2d(1) # GAPself.max_pool = nn.AdaptiveMaxPool2d(1) # GMPdef forward(self, x):n, c, h, w = x.size(0), x.size(1), x.size(2), x.size(3)# avg max: [N, C, 1, 1]avg = self.avg_pool(x).softmax(1).view(n, 1, 1, c)max = self.max_pool(x).softmax(1).view(n, 1, 1, c)# k: [N, 1, HW, 1]k = self.k(x).view(n, 1, -1, 1).softmax(2)# v: [N, 1, C, HW]v = self.v(x).view(n, 1, c, -1)# y: [N, C, 1, 1]y = torch.matmul(v, k).view(n, c, 1, 1)# y2:[N, 1, H, W]y_avg = torch.matmul(avg, v).view(n, 1, h, w)y_max = torch.matmul(max, v).view(n, 1, h, w)# y_cat:[N, 2, H, W]y_cat = torch.cat((y_avg, y_max), 1)y = self.m(y) * self.m2(y_cat).sigmoid()return x + y如果想要在现有网络中做类似 SCAM 的改进,我们就需要想明白这些事情,它的作用一定是增强全局上下文信息(也就是Transformer的特点),通常应该放在主干特征提取之后、检测头之前,而且使用卷积有一个好处就是不会像Transformer那样改动后梯度爆炸。 论文里面你可以从方法层面、效果层面、开销层面来强调你改进的意义。
消融实验
这里我下载了最新版本的yolov5官方代码,对比了一下应该是以YOLOv5m作为基础模型进行改进优化,消融实验所用的数据集是文章中的AI-TOD——AI-TOD航空图像数据集,仓库里面的方法有点点麻烦。
先说明一下,这里仅仅将epochs改为了30,其他的超参数不变。
我们在model/yolo.py文件中进行修改,然后就是写模型的配置文件。
# 常见的卷积和残差结构类if m in {Conv,GhostConv,Bottleneck,GhostBottleneck,SPP,SPPF,DWConv,MixConv2d,Focus,CrossConv,BottleneckCSP,C3,C3TR,C3SPP,C3Ghost,nn.ConvTranspose2d,DWConvTranspose2d,C3x,# add modelFEM,}:c1, c2 = ch[f], args[0]if c2 != no: # if not outputc2 = make_divisible(c2 * gw, ch_mul)args = [c1, c2, *args[1:]]if m in {BottleneckCSP, C3, C3TR, C3Ghost, C3x}:args.insert(2, n) # number of repeatsn = 1elif m is nn.BatchNorm2d:args = [ch[f]]elif m is Concat:c2 = sum(ch[x] for x in f)# TODO: channel, gw, gdelif m in {Detect, Segment}:args.append([ch[x] for x in f])if isinstance(args[1], int): # number of anchorsargs[1] = [list(range(args[1] * 2))] * len(f)if m is Segment:args[3] = make_divisible(args[3] * gw, ch_mul)elif m is Contract:c2 = ch[f] * args[0] ** 2elif m is FFMConcat:c2 = sum(ch[x] for x in f)args = [c2]elif m in {SCAM}:c2 = ch[f]args = [c2]elif m is Expand:c2 = ch[f] // args[0] ** 2else:c2 = ch[f]
修改配置文件
# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license# Parameters
nc: 80 # number of classes
depth_multiple: 0.67 # model depth multiple
width_multiple: 0.75 # layer channel multiple
anchors: 3backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0 320*320*48[-1, 1, Conv, [128, 3, 2]], # 1 160*160*96[-1, 6, C3, [128]], # 2 160*160*96 2[-1, 1, FEM, [128]], # 3 160*160*96[-2, 1, Conv, [256, 3, 2]], # 4 80*80*192[-1, 6, C3, [256]], # 5 80*80*192 4[-1, 1, FEM, [256]], # 6 80*80*192[-2, 1, Conv, [512, 3, 2]], # 7 40*40*384[-1, 9, C3, [512]], # 8 40*40*384 6[-1, 1, SPPF, [512, 5]], # 9 40*40*384]# YOLOv5 v6.0 head
head:[# 40*40 concat 80*80[-1, 1, Conv, [256, 1, 1]], # 10 40*40*192[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 11 80*80*192[[-1, 6], 1, FFMConcat, []], # 12 80*80*384[-1, 3, C3, [256, False]], # 13 80*80*192 2# 80*80 concat 160*160[-1, 1, Conv, [128, 1, 1]], # 14 80*80*96[-1, 1, nn.Upsample, [None, 2, 'nearest']], # 15 160*160*96[[-1, 3], 1, FFMConcat, [ ]], # 16 160*160*192[-1, 3, C3, [128, False]], # 17 160*160*96 2[-1, 1, Conv, [128, 3, 2]], # 18 80*80*192[[-1, 6, 14], 1, FFMConcat, [ ]], # 19 80*80*384[-1, 3, C3, [256, False]], # 20 80*80*192 2[-1, 1, Conv, [256, 3, 2]], # 21 40*40*192[[-1, 10], 1, FFMConcat, [ ]], # 22 40*40*384[-1, 3, C3, [512, False]], # 23 40*40*384[17, 1, SCAM, [ ]], # 24[20, 1, SCAM, [ ]], # 25[23, 1, SCAM, [ ]], # 26[[24, 25, 26], 1, Detect, [nc, anchors]],]训练的时候报了一个错误:RuntimeError: adaptive_max_pool2d_backward_cuda does not have a deterministic implementation, but you set 'torch.use_deterministic_algorithms(True)'. You can turn off determinism just for this operation, or you can use the 'warn_only=True' option。
在train.py文件中找到scaler.scale(loss).backward()这一行,在其前修改。
# Backwardtorch.use_deterministic_algorithms(True, warn_only=True)scaler.scale(loss).backward()原版的YOLOv5m:
精度 (P): 0.753
召回率 (R): 0.171
mAP50 (IoU=0.5时的平均精度): 0.166
mAP50-95 (IoU=0.5到0.95的平均精度): 0.0561
改进的FFCA-YOLO:
精度 (P): 0.783
召回率 (R): 0.224
mAP50 (IoU=0.5时的平均精度): 0.224
mAP50-95 (IoU=0.5到0.95的平均精度): 0.0804
参考文章
FFCA-YOLO for Small Object Detectionin Remote Sensing Images_ffca-yolo for small object detection in remote sen-CSDN博客
顶刊【遥感目标检测】【TGRS】FFCA-YOLO遥感图像小目标检测-CSDN博客
FFCA-YOLO:突破小物体检测瓶颈,提升遥感应用中的精度与效率-CSDN博客
YOLOv11融合针对小目标FFCA-YOPLO中的FEM模块及相关改进思路_ffca模块-CSDN博客
(98 封私信) 文献阅读:FFCA-YOLO for Small Object Detection in Remote Sensing Images - 知乎
RFBnet论文及其代码详解-CSDN博客