【Redis五种数据类型】
Redis五种数据类型底层原理及应用场景
- 一、string(字符串)
- 1.常用命令
- 2.底层原理(SDS动态字符串,Long整数)
- (1).SDS的优势
- (2).三种编码方式
- 3.应用场景
- 二、list(有序可重复列表)
- 1.常用命令
- 2.底层原理
- 3.使用场景
- 三、set(无序且无重复集合)
- 1.常用命令
- 2.底层原理
- 3.应用场景
- 四、zset(有序且无重复集合)
- 1.常用命令
- 2.底层原理
- 3.应用场景
- 五、hash(哈希表)
- 1.常用命令
- 2.底层原理
- 3.应用场景
redis五种数据类型是:string(字符串),list(列表),hash(哈希表),set(无序且不重复列表),zset(有序且不重复集合)
一、string(字符串)
string数据类型是redis中最常见的一种数据类型,是二进制安全的,可以存放字符串,数值等,value存储的最大值是512M。
1.常用命令
- set < key>< value>:添加键值对
- nx:当数据库中key不存在时,可以将key-value添加到数据库(常作为分布式锁)
- xx: 当数据库key存在时,可以将key-value添加到数据库,与nx参数互斥
- ex: 设置key-value添加到数据库,并设置key的超时时间(以秒钟为单位,配合nx使用)
- px:设置key-value添加到数据库,并设置key的超时时间(以豪秒钟为单位)
- get < key>查询对应键值
- append < key>< value>:将给定的值追加到key的末尾
- strlen < key>:获取值的长度
- setnx < key>< value>:只有在key不存在时,设置key-value加入到数据库
- setex < key> < timeout>< value>:添加键值对,同时设置过期时间(以秒为单位)
- incr < key>:将key中存储的数字加1处理,只能对数字值操作。如果是空,值为1
- decr < key>:将key中存储的数字减1处理,只能对数字值操作。如果是空,值为-1
- incrby < key>< increment>:将key中存储的数字值增加指定步长的数值,如果是空,值为步长。(具有原子性)
- decrby < key>< decrement>: 将key中存储的数字值减少指定步长的数值,如果是空,值为步长。(具有原子性)
- mset < key1>< value1>[< key2>< value2>…]:同时设置1个或多个key-value值
- mget < key1>[< key2>…]:同时获取1个或多个value
- msetnx < key1>< value1>[< key2>< value2>…]:当所有给定的key都不存在时,同时设置1个或多个key-value值(具有原子性)
- getrange/substr < key>< start>< end> 将给定key,获取从start(包含)到end(包含)的值
- setrange < key>< offset>< value>:从偏移量offset开始,用value去覆盖key中存储的字符串值
- getset< key>< value>: 对给定的key设置新值,同时返回旧值。如果key不存在,则添加一个key-value值
2.底层原理(SDS动态字符串,Long整数)
string没有使用c语言原生的字符串,使用了一种动态字符串(SDS)。
struct __attribute__ ((__packed__)) sdshdr8 {uint8_t len; /* 代表字符数组长度,即字符串长度*/uint8_t alloc; /* 除去头部和空终止符申请的内存字节数 */unsigned char flags; /* 低3位标识SDS类型,高5位未使用 */char buf[]; /* 柔性数组,存放实际字符串数据*/
};
(1).SDS的优势
- 获取字符串长度时间复杂度时o(1),直接获取len属性
- 是二进制安全的,c语言中的字符串用’\0’结尾,不能存储包含’\0’的数据,如图片,音频等。SDS用len判断结束,**buf[ ]**可以存储任何数据类型,二进制安全
- c语言的字符串是不可变的,sds是可以动态扩展的。
(2).三种编码方式
String的内部存储结构⼀般是sds(Simple Dynamic String,可以动态扩展内存),但是如果⼀个String类型的value的值是数字,那么Redis内部会把它转成long类型来存储,从⽽减少内存的使用。
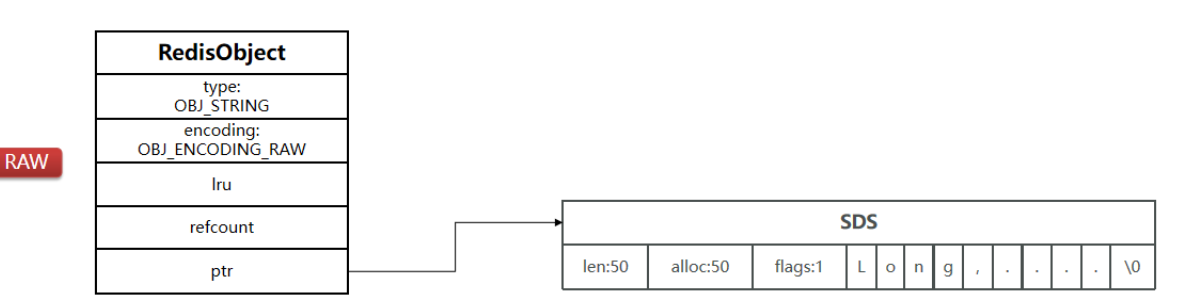
如果存储的字符串是整数值,并且大小在LONG_MAX范围内,则会采用INT编码:直接将数据保存在RedisObject的ptr指针位置(刚好8字节),不再需要SDS了。
typedef struct redisObject {unsigned type:4;/*对象类型(如 string, list, hash等)*/unsigned encoding:4; /* 对象的底层编码实现方式*/unsigned lru:LRU_BITS; /* 用于 LRU 或 LFU 的内存淘汰策略信息*/int refcount; /*引用计数,用于内存回收 */void *ptr; /*指向实际数据存储位置的指针*/
} robj;

当存储的字符串长度 ≤ 44 字节,Redis 会申请一块连续的内存空间,将 redisObject 结构体和 SDS 结构体紧挨着存放,称为embstr.
只需一次内存分配操作(分配连续空间),同样只需一次内存释放。
但是只读的。任何修改命令都会使其编码转换为 raw。

当存储的字符串其长度 > 44 字节,redis会使用raw编码方式。这是最标准的 SDS 存储方式。Redis 会创建两个独立的内存块,分别分配 redisObject 和 sdshdr 结构,然后用 ptr 指针将两者关联起来。
它具备动态扩容的能力
新长度 len < 1MB:分配 alloc = newlen * 2 + 1。
新长度 len >= 1MB:额外分配 1MB 的 free 空间(即newlen + 1MB)。
3.应用场景
单值缓存 set key value get key
对象缓存
set stu:001 value(json)
mset stu:001:name zhangsan stu:001:age 18 stu:001:gender 男
mget stu:001:name stu:001:age
分布式锁
setnx key:001 true //返回1代表加锁成功
setnx key:001 true //返回0代表加锁失败
//…业务操作
del key:001 //执行完业务释放锁
set key:001 true ex 20 nx //防止程序意外终止导致死锁
计数器
incr article:read:1001 //统计文章阅读数量
存储token
set token user(json) //分布式系统
二、list(有序可重复列表)
Redis列表是简单的字符串列表,单键多值。按照插入顺序排序。可以添加一个元素到列表的头部(左边)或者尾部(右边)
1.常用命令
- lpush < key> < value1>[< value2>…]:从左侧插入一个或多个值
- lpushx < key> < value1>[< value2>…]:将一个或多个值插入到已存在的列表头部
- lrange < key>< start>< stop>:获取列表指定范围内的元素,0左边第1位,-1右边第1 位,0 ~-1指取出所有
- rpush < key> < value1>[< value2>…]:从右侧插入一个或多个值
- rpushx < key> < value1>[< value2>…]:将一个或多个值插入到已存在的列表尾部
- lpop < key>[count]:移除并获取列表中左边第1个元素,count表明获取的总数量,返回的为移除的元素
- rpop < key>[count]:移除并获取列表中右边第1个元素,count表明获取的总数量,返回的为移除的元素
- rpoplpush < source>< destination>:移除源列表的尾部的元素(右边第一个),将该元素添加到目标列表的头部(左边第一个),并返回
- lindex < key>< index>:通过索引获取列表中的元素
- llen < key>:获取列表长度
- linsert < key> before|after < pivot>< element>:在< pivot>基准元素前或者后面插入< element >,如果key不存在,返回0。如果< pivot>不存在,返回-1,如果操作成功,返回执行后的列表长度
- lrem < key>< count>< element>:根据count的值,移除列表中与参数相等的元素
- count=0 移除表中所有与参数相等的值
- count>0 从表头开始向表尾搜索,移除与参数相等的元素,数量为count
- count<0 从表尾开始向表头搜索,移除与参数相等的元素,数量为count的绝对值
- lset < key>< index> < element>:设置给定索引位置的值
- ltrim< key>< start> < stop>:对列表进行修剪,只保留给定区间的元素,不在指定区间的被删除
- brpop < key> timeout:阻塞式移除指定key的元素,如果key中没有元素,就等待,直到有元素或超时,执行结束。
2.底层原理
list数据结构在redis3.2之前使用ziplist+linklist实现,在redis3.2之后使用quicklist实现,quicklist是用双向指针将ziplist连接起来,是ziplist和linklist混合体。
ziplist数据结构:
typedef struct {/* 使用字符串时,会同时提供其长度(slen) */unsigned char *sval; /*指向字符串内容的指针*/unsigned int slen; /*字符串的长度*//* When integer is used, 'sval' is NULL, and lval holds the value. */long long lval;/*当条目存储的是整数时,使用这个字段,此时 sval 为NULL*/
} ziplistEntry;
在 Redis 的早期版本中,当列表同时满足以下两个条件时,使用 ziplist:
- 列表对象保存的所有字符串元素长度都小于 64 字节。
- 列表对象保存的所有字符串元素个数都小于 512 字节。
特点:ziplist是一块连续的内存数组,不需要记录前后节点的指针,通过记录元素长度来获取元素,通过牺牲读取效率来换取内存空间。适合存储小对象和少量元素。
ZipList的连锁更新问题:
连锁更新是指因为一个节点的变化(插入或删除),导致后续多个节点需要被迫重新分配空间并更新其prevlen字段的连锁反应。
连锁更新在最坏情况下性能较差。但在实际应用中,它造成的性能问题并不常见,因为需要满足非常特殊的条件(一系列长度刚好在250~253字节之间的节点)。
linklist数据结构:
类似于java中的linklist底层使用双向链表
何时使用: 当不满足上述 ziplist 的条件时,编码会自动切换为 linkedlist。
特点: 标准的双端链表结构,每个节点(listNode)都包含指向前后节点的指针。插入和删除效率非常高(O(1)),但内存开销较大(每个元素都需要存储前后指针)。
quicklist(快速列表),redis3.2以后list底层使用quicklist,是用双向指针将ziplist连接起来,是ziplist和linklist混合体。
这样设计是为了在空间效率和操作效率之间取得一个完美的平衡。
- 单个 ziplist 可以保持很高的内存效率。
- 将大量 ziplist 节点用链表连接起来,避免了大型 ziplist 带来的重新分配内存的巨大开销。
typedef struct quicklist {//头节点指针quicklistNode *head;//尾节点指针quicklistNode *tail;//所有quicklistNode 中的节点数目总和,//这个值是通过累加所有节点(quicklistNode)的count字段得到的。unsigned long count; /* total count of all entries in all ziplists *///整个quicklist中节点(quicklistNode)的数量,即链表的长度。unsigned long len; /* number of quicklistNodes *///使用位域(bit field)。填充因子,用于控制每个ziplist节点的最大容量。int fill : QL_FILL_BITS; unsigned int compress : QL_COMP_BITS;unsigned int bookmark_count: QL_BM_BITS;quicklistBookmark bookmarks[];
} quicklist;
typedef struct quicklistNode {// 指向前一个 quicklistNode 的指针struct quicklistNode *prev;// 指向后一个 quicklistNode 的指针struct quicklistNode *next;// 指向实际数据容器的指针。// 在未压缩的情况下,它指向一个 ziplist(压缩列表);// 在压缩的情况下,它指向一个被 LZF 算法压缩后的数据块。unsigned char *zl;// 表示 zl 指针所指向的数据结构的大小(单位:字节)。// 如果 zl 指向的是 ziplist,那么就是该 ziplist 占用的总字节数;// 如果 zl 指向的是压缩数据,那么就是压缩后数据块的大小。unsigned int sz; // 使用位域(bit field):使用 16 个比特位来存储一个整数值。// 表示这个节点所包含的 ziplist 中实际的数据项(entry)的个数。unsigned int count : 16; // 使用位域:2 个比特位。// 表示节点的编码方式,即 zl 指针所指数据的存储形式。// RAW==1: 表示原始未压缩格式(即一个 ziplist)// LZF==2: 表示使用 LZF 算法压缩后的格式unsigned int encoding : 2; // 使用位域:2 个比特位。// 表示节点使用的数据容器类型。目前实际上只有一种主要选择。// NONE==1: 无容器(未使用)// ZIPLIST==2: 使用 ziplist 作为容器(这是默认且主要的类型) unsigned int container : 2; // 使用位域:1 个比特位。// 这是一个标志位。如果值为 1,表示这个节点当前的数据是压缩状态(LZF),// 但在下一次使用之前需要先被解压缩。// 这通常用于在需要访问节点内容时进行延迟解压缩(lazy decompression)的优化策略。unsigned int recompress : 1; // 使用位域:1 个比特位。// 这是一个标志位。用于在测试或自动调整时记录该节点是否因为太小而不适合被压缩。// 如果值为 1,表示尝试过压缩这个节点,但由于它包含的数据太少,压缩效果不好或反而增大,因此放弃压缩。unsigned int attempted_compress : 1; // 使用位域:10 个比特位。// 预留给未来使用的额外标志位。目前没有实际用途,但先预留出来,// 以便将来需要新的布尔属性时,无需扩大整个结构体的内存占用。unsigned int extra : 10;
} quicklistNode;
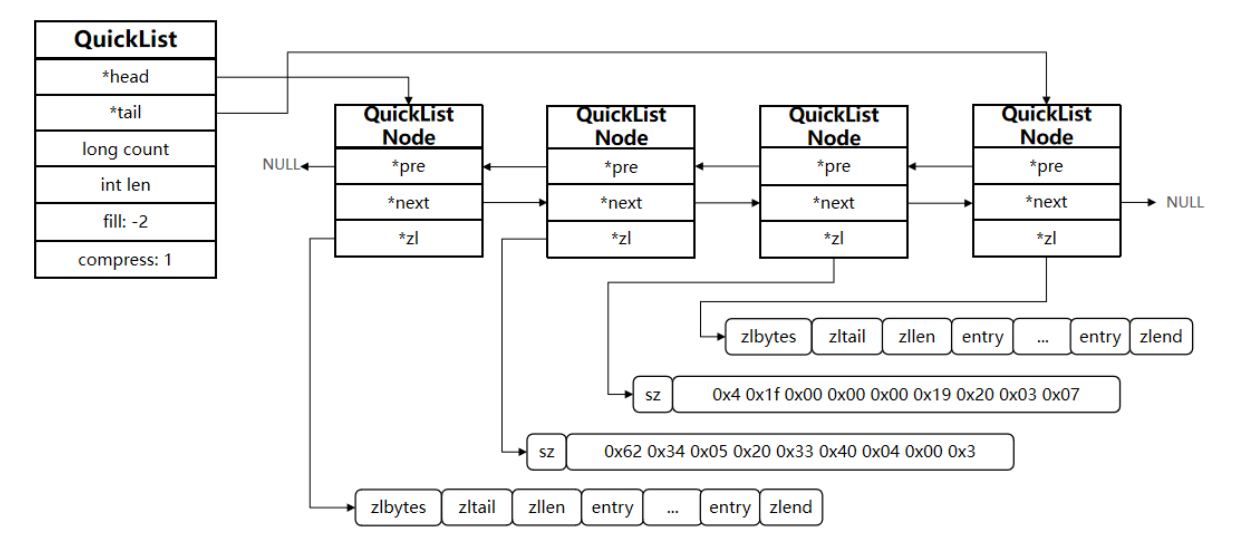
quicklist特点:
- 是一个节点为ZipList的双端链表
- 使用ziplist可以节省空间
- 可以控制了ZipList大小,解决连续内存空间申请效率问题
- 中间节点可以压缩,进一步节省了内存
3.使用场景
- 堆栈stack=lpush+lpop
- 队列queue=lpush+rpop
- 消息队列 blockingmq = lpush + brpop
- 订阅号时间线 lrange key start stop
三、set(无序且无重复集合)
set是一个无序且元素唯一的集合,类似于java中的hashset
1.常用命令
- sadd < key>< member>[< member>…]:将一个或多个成员元素加入到集合中,如果集合中已经包含成员元素,则被忽略
- smembers < key>:返回集合中的所有成员。
- sismember < key>< member>:判断给定的成员元素是否是集合中的成员,如果是返回1,否则返回0
- scard < key>:返回集合中元素个数
- srem < key>< member>[< member>…]:移除集合中一个或多个元素
- spop < key>[< count>]:移除并返回集合中的一个或count个随机元素
- srandmember < key>[< count>]:与spop相似,返回随机元素,不做移除
- smove < source> < destination> < member>:将member元素从source源移动到destination目标
- sinter < key>[< key>…]:返回给定集合的交集(共同包含)元素
- sinterstore < destination> < key1>[< key2>…]:返回给定所有集合的交集,并存储到destination目标中
- sunion < key>[< key>…]:返回给定集合的并集(所有)元素
- sunionstore < destination> < key1>[< key2>…]:返回给定所有集合的并集,并存储到destination目标中
- sdiff < key>[< key>…]:返回给定集合的差集(key1中不包含key2中的元素)
- sdiffstore < destination> < key1>[< key2>…]:返回给定所有集合的差集,并存储到destination目标中
2.底层原理
(1).intset(整数集合)
typedef struct intset {uint32_t encoding; /*编码方式,,支持存放16位,32位,64位整数*/uint32_t length;/*元素个数*/int8_t contents[];/*整数数组,保存集合数据,是一个有序的*/
} intset;
- 集合中的元素全部是整数,并且元素数量较少时(set-max-intset-entries 配置,默认 512)
- 用一个有序整数数组存储元素,查找使用二分查找,时间复杂度位o(logn)。
- 内存效率极高。
(2).hashtable (哈希表)
在redis中,是dict数据类型.
如果集合中包含非整数元素(如字符串),或者元素数量超过了阈值,会使用dict这个数据类型。
Dict由三部分组成,分别是:哈希表(DictHashTable)、哈希(DictEntry)、字典(Dict)
typedef struct dict {dictType *type;// 指向字典类型特定函数的指针void *privdata;// 指向私有数据的指针,传递给类型特定函数dictht ht[2]; // 两个哈希表,用于实现渐进式 rehashlong rehashidx; // rehash 索引,-1 表示未在进行 rehashint16_t pauserehash; // rehash 暂停标志:>0 暂停,<0 表示编码错误
} dict;
typedef struct dictht {dictEntry **table;// 哈希表数组,存储指向dictEntry的指针unsigned long size;// 哈希表大小(桶的数量)unsigned long sizemask;// 哈希表大小掩码,用于计算索引值unsigned long used;// 哈希表中已有节点的数量
} dictht;
typedef struct dictEntry {void *key; // 键指针union { // 值的联合体(多种类型),在set中为nullvoid *val;uint64_t u64;int64_t s64;double d;} v;struct dictEntry *next;// 指向下一个哈希表节点的指针(解决冲突)
} dictEntry;
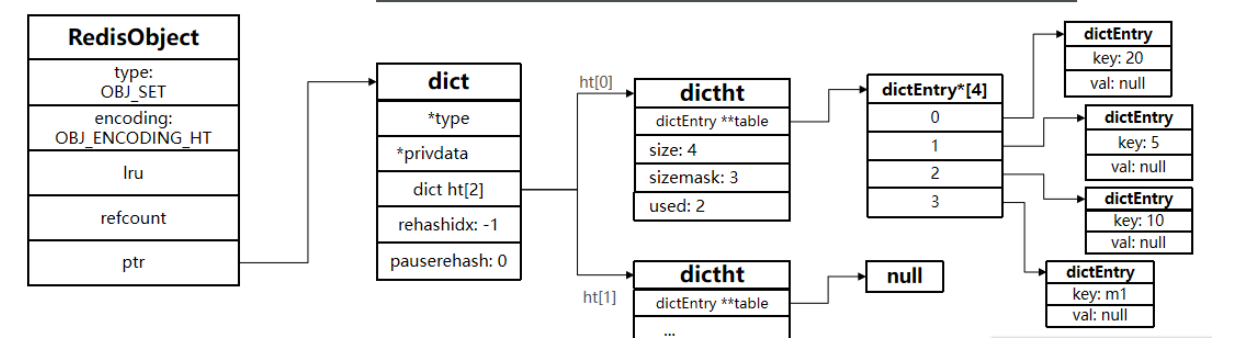
键:集合元素(字符串或整数)
值:全部设为 NULL(节省内存)
3.应用场景
- 抽奖
- sadd cj001 user:13000000000 user:13455556666 user:13566667777
- smembers cj001 //查看所有抽奖用户
- spop cj001 进行不重复抽奖
- srandmember cj001 可以重复抽奖
- 关注模型: sinter交集 sunion并集 sdiff 差集
- 微博 sadd g:list:u001 1001 sadd g:list:u002 1001 你们共同关注的 sinter交集
- QQ 你们有共同好友 sinter交集
- 快手 可能认识的人 sdiff差集
四、zset(有序且无重复集合)
Redis ZSet(Sorted Set)是一个有序的、不重复的字符串集合。每个元素都关联一个分数(score),元素按分数从小到大排序。分数相同时,按字典序排序。
1.常用命令
- zadd < key> < score>< member>[< score>< member>…]:将一个或多个元素及其分数加入到有序集合中
- zrange < key>< min>< max> [byscore|bylex] [rev] [ limit offset count] [withscores]:返回有序集合指定区间的成员,(byscore按分数区间,bylex按字典区间,rev 反向排序(分数大的写前边,小的写后边),limit分页(offset偏移量,count返回的数),withscores返回时带有对应的分数)
- zrevrange < key>< start>< stop>[ limit offset count]:返回集合反转后的成员
- zrangebyscore < key>< min>< max> [withscores] [ limit offset count]:参考zrange用法
- zrangebylex < key>< min>< max>] [ limit offset count]:通过字典区间返回有序集合的成员
- zrangebylex k2 - +:减号最小值,加号最大值
- zcard < key>:获取集合中的成员数量
- zincrby < key> < increment>< member> :为集合中指定成员分数加上增量increment
- zrem < key> < member>[< member>…]:移除集合的一个或多个成员
- zcount < key>< min>< max>:统计集合中指定区间分数(都包含)的成员数量
- zrank < key>< member>:获取集合中成员的索引位置
- zscore < key>< member>:获取集合中成员的分数值
2.底层原理
元素数量少(≤128),且所有元素大小较小(≤64字节),使用ziplist
紧凑的连续内存块,节省内存
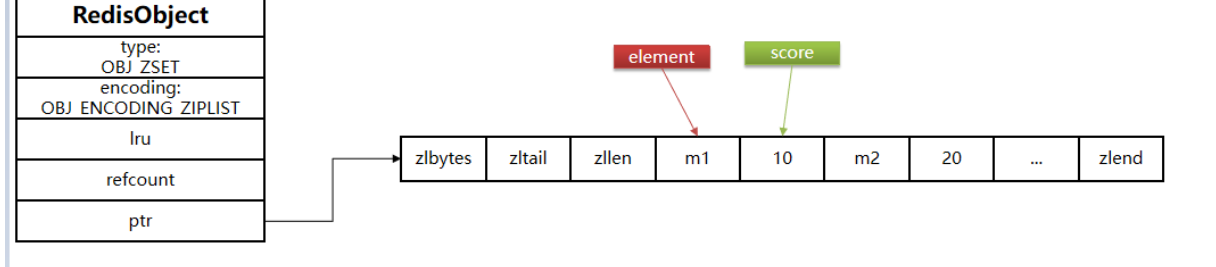
存储格式:[元素1, 分数1, 元素2, 分数2, …]
element和score是紧连在一起的连个entry,element在前,score在后
score越小越接近队首,score越大越接近队尾,按照score值升序排列
不满足 ziplist 条件时,使用dict(字典,即hash表,) + skiplist(跳表)
dict可以存储键值对,且元素唯一,skiplist可以保证元素按有序。
skiplist详解
typedef struct zskiplistNode {sds ele; // 元素值,使用SDS字符串double score; // 分数,用于排序struct zskiplistNode *backward; // 后退指针,指向前一个节点struct zskiplistLevel { // 层级数组struct zskiplistNode *forward; // 前进指针,指向下一个节点的指针unsigned long span; // 跨度,到下一个节点的距离} level[]; // 柔性数组,表示多级索引
} zskiplistNode;
typedef struct zskiplist {struct zskiplistNode *header; // 头节点指针struct zskiplistNode *tail; // 尾节点指针 unsigned long length; // 节点数量int level; // 当前最大层数
} zskiplist;
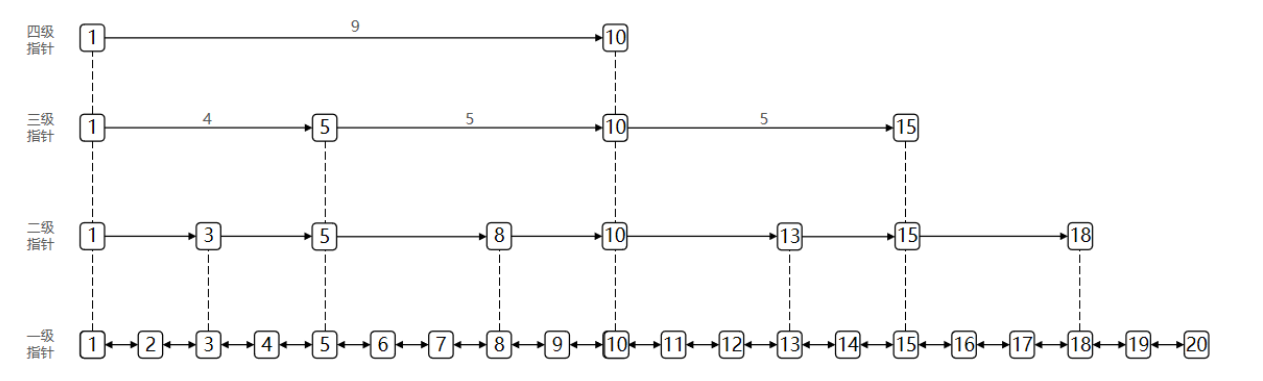
skip首先是一个链表,元素按照升序排列,节点可能包含多个指针,执行不同跨度。
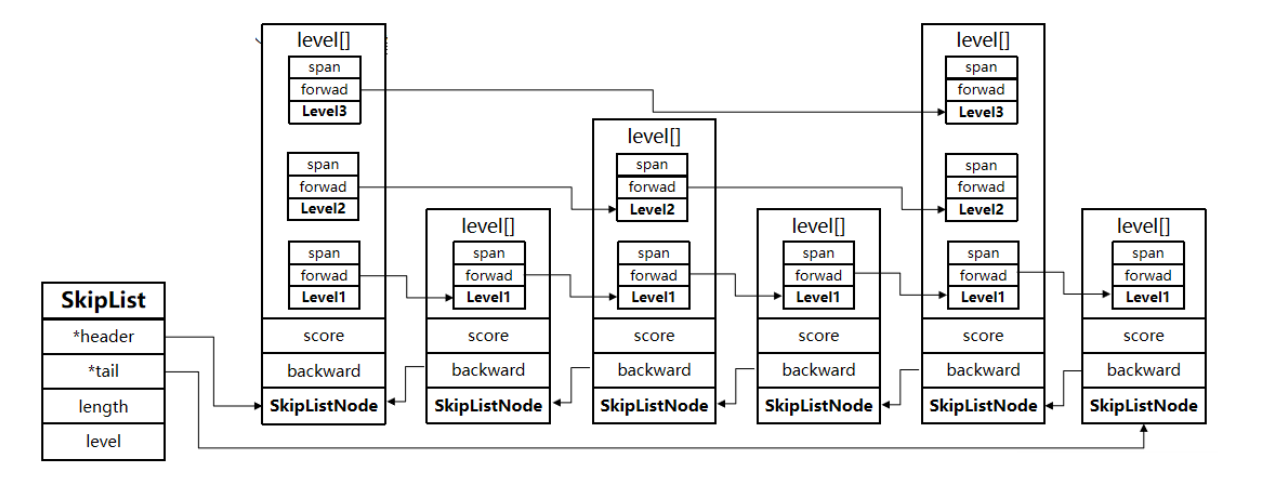
SkipList的特点:
- 是一个双向链表,每个节点都包含score和ele值
- 节点按照score值排序
- 每个节点都可以包含多层指针,层数是1到32之间的随机数
- 不同层指针到下一个节点的跨度不同,层级越高,跨度越大
- 增删改查效率与红黑树基本一致,实现却更简单0(logn),基于二分思想
当不满足上述 ziplist 的条件时,zset底层使用skiplist(调表) + dict(字典)实现
typedef struct zset {dict *dict;zskiplist *zsl;
} zset;
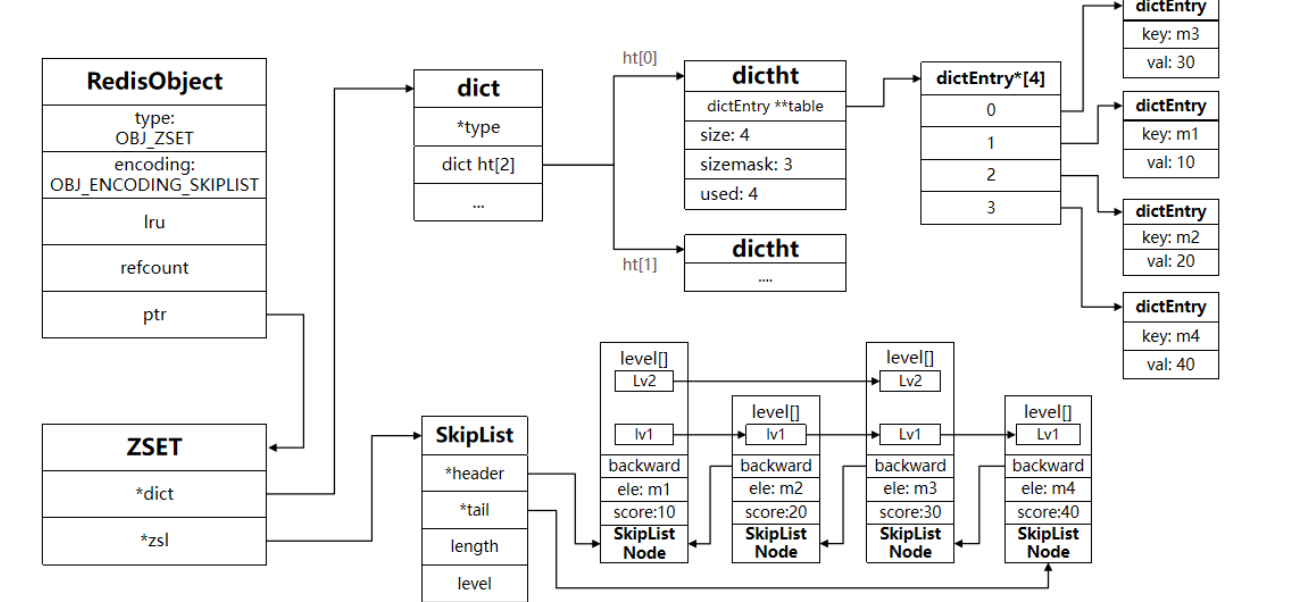
字典(dict 哈希表):来保证key的唯一性,并且根据key查找score是效率高,时间复杂度为o(1),ZSCORE 命令就是基于此实现的
跳跃表(skiplist): 核心结构,负责根据分数进行排序和范围查询。(zrange byscore)它支持平均 O(log N) 复杂度的按分数范围查找、插入和删除操作。
3.应用场景
- 按时间先后顺序排序:朋友圈点赞 zadd 1656667779666
- 获取topN: zrevrange k1 300 10 limit 0 10
- 排行榜 : 最经典的应用,如游戏积分榜、视频热度榜、销量榜。
五、hash(哈希表)
是一个string类型的键和value(对象),特别适合于存储对象,类似于java里面学习的Map<String,Object>。
1.常用命令
- hset < key>< field>< value>[< field>< value>…]:用于为哈希表中的字段赋值,如果字段在hash表中存在,则会被覆盖
- hsetnx < key>< field>< value>:只有在字段不存在时,才设置哈希表字段中的值
- hget < key>< field> 返回哈希表中指定的字段的值
- hmget < key>< field>[< field>…]:获取哈希表中所有给定的字段值
- hgetall < key>:获取在哈希表中指定key的所有字段和值
- hexists < key>< field>:判断哈希表中指定的字段是否存在,存在返回1 ,否则返回0
- hkeys < key>:获取哈希表中所有的字段
- hlen < key>:获取哈希表中的field数量
- hdel < key>< field>[< field>…]:删除一个或多个哈希表字段
- hincrby < key>< field>< increment>:为哈希表key中指定的field字段的整数值加上增加increment
- hincrbyfloat < key>< field>< increment>:为哈希表key中指定的field字段的浮点数值加上增加increment
2.底层原理
Hash与zset非常类似
- 都是键值存储
- 都需求根据键获取值
- 键必须唯一
区别:
- zset的键是member,值是score;hash的键和值都是任意值
- zset要根据score排序;hash则无需排序
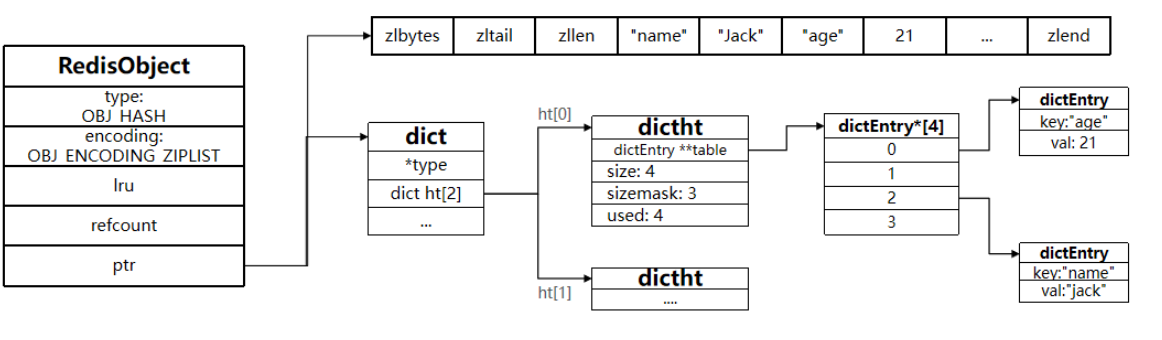
数据量少时,使用ziplist(压缩列表)
使用条件:
- Hash 对象保存的所有字段和值的字符串长度都小于 hash-max-ziplist-value 配置值(默认 64 字节)。
- Hash 对象保存的字段数量小于 hash-max-ziplist-entries 配置值(默认 512)。
存储方式: 和 ZSet 的 ziplist 类似,所有字段和值在内存中紧凑地、连续地存储。先是 field1,然后是 value1,接着是 field2,value2,以此类推。对于小 Hash 来说,这种方式非常节省内存。
当不满足上述条件时,使用dict(字典,哈希表)
dict查找删除,新增效率接近0(1),。虽然内存开销比 ziplist 大,但操作效率非常高,尤其适合字段多或值大的情况。
3.应用场景
1.对象缓存 hset stu:001 name zhangsan age 20 gender man
2.购物车
- 以用户id作为key, 以商品id作为field,以商品数量作为value
- 添加商品: hset user:001 s:001 1
- 删除商品: hincrby user:001 s:001 -1
- 查看购物车商品总数: hlen user:001
- 查看单个商品数量: hget user:001 s:001
- 删除商品 : hdel user:001 s:001
- 获取所有商品: hgetall user:001