高级 RAG 技术原理和前沿进展
思维导图
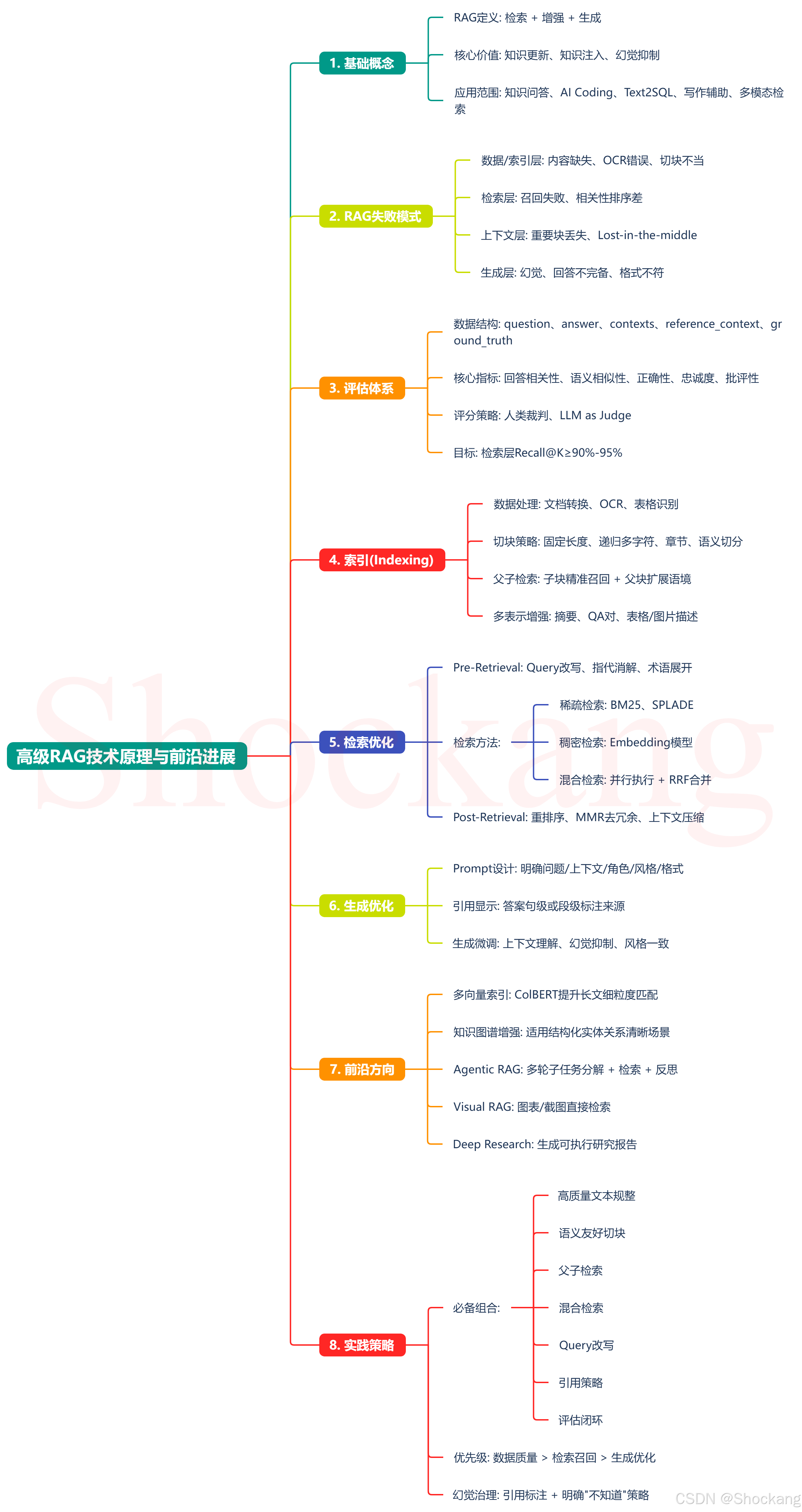
课程内容
1. 背景与核心动机
- 现实:约 95% 知识为企业私有数据,通用大模型只覆盖 5% 公共语料。
- 类比:LLM 像 CPU,RAG 像“从外部存储加载知识”机制。
- 目标:让企业成员“低摩擦”获得组织集体智慧;本质是重构“搜索 → 决策/执行”链条,而不是简单问答替代。
- 痛点:模型内部知识滞后、专业场景幻觉高、长尾问题覆盖差、精确引用与可追溯需求上升。
2. RAG 的三大基础价值
- 知识更新(外部数据即时接入)
- 知识注入(专业/私域语料增强)
- 幻觉抑制(答案与上下文绑定)
3. 应用范围扩展
-
不仅是 FAQ/知识库问答
-
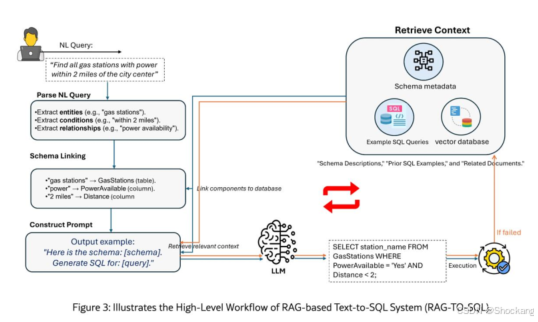
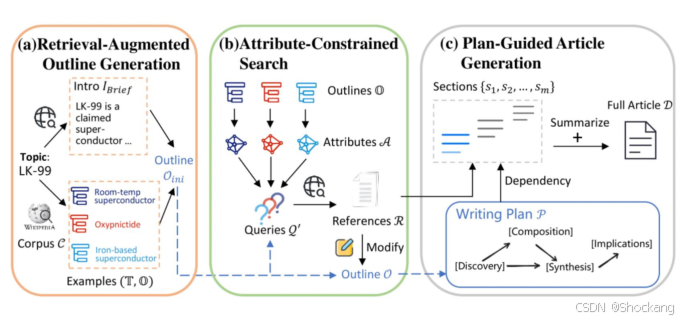
典型扩展:Text2SQL / SQL 生成辅助、代码检索 + 模式示例参考、写作与报告生成、信息抽取、日志/运维语义检索、Agent 工具编排、Deep Search / Deep Research、多模态(图 + 文档截图)检索。
4. RAG 常见失败模式(典型分层定位)
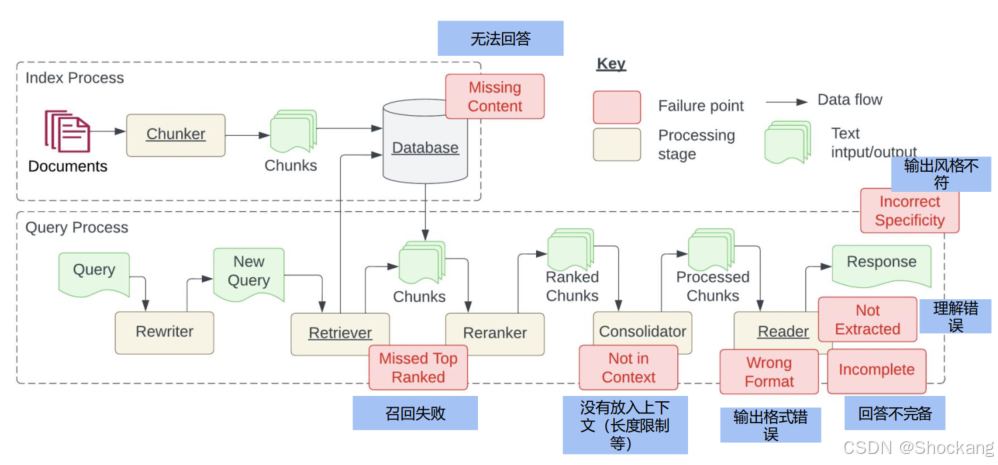
| 层级 | 失败现象 |
|---|---|
| 数据/索引 | 无对应内容(超纲)、OCR/解析错误、切块跨语义 |
| 检索 | 召回失败、相关性排序差、短文本/噪声块干扰 |
| 上下文注入 | 重要块丢失(长度裁剪)、Lost-in-the-middle |
| 生成 | 幻觉(预训练 or 上下文误读)、答案不完备、格式不符、风格不匹配、引用错乱 |
| 评估 | 指标缺失或只看主观体验,优化无方向 |
补充:上下文幻觉 = 已提供正确材料仍答错;结构性缺失多源于理解/注意力集中模式。
5. 评估体系
5.1 数据结构(CRAG 类)
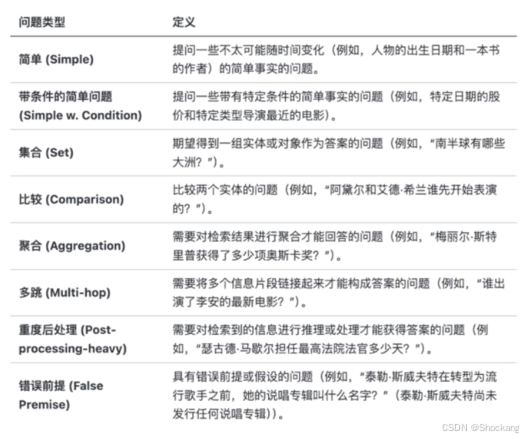
- question
- answer(系统输出)
- contexts(检索返回按相似度排序)
- reference_context(标注相关上下文)
- ground_truth(参考答案)
5.2 核心指标
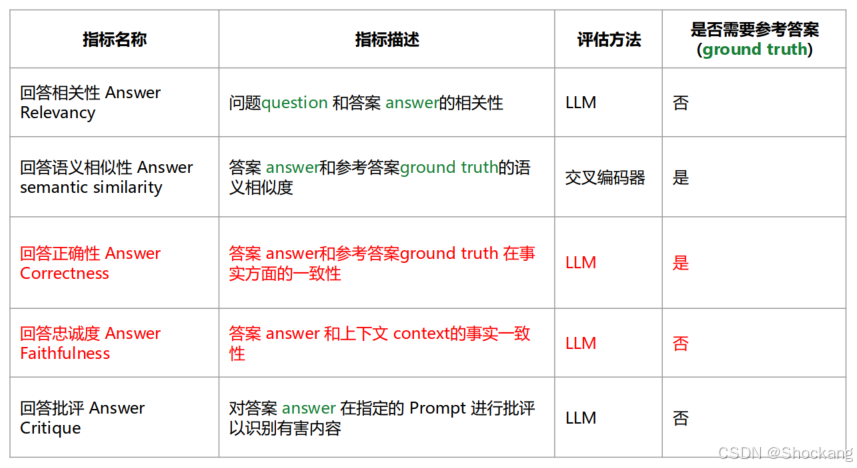
- Answer Relevancy(问答相关性,LLM 0/1 判)
- Answer Semantic Similarity(与 ground truth 语义相似度,交叉编码器)
- Answer Correctness(事实一致性,LLM 判)
- Answer Faithfulness(对已提供 context