llm的一点学习笔记
链接:https://mp.weixin.qq.com/s/QKMqadee_oT1Jvza2lx7PQ
OPENAI参考资料地址:https://cdn.openai.com/pdf/d04913be-3f6f-4d2b-b283-ff432ef4aaa5/why-language-models-hallucinate.pdf
Hallucination语言模型生成看起来合理,实则错误离谱。
语言模型出现幻觉的根本原因在于,当前标准的训练和评估程序更倾向于对猜测进行奖励,而缺乏对模型坦诚表达不确定性的奖励机制。
一、预训练阶段就埋下幻觉种子
1. 统计必然性
把生成问题等价到二分类“Is-It-Valid?”——只要分类器会犯错,生成就会出错(定理 1)。
2. 数据稀缺性
训练语料里只出现一次的“冷知识”(singleton)注定会被模型记错,错误率 ≥ singleton 占比(定理 2)。
3. 模型表达能力不足
如果模型族本身就无法学到规律(如 trigram 数不对字母),幻觉率下限直接拉满(定理 3)。

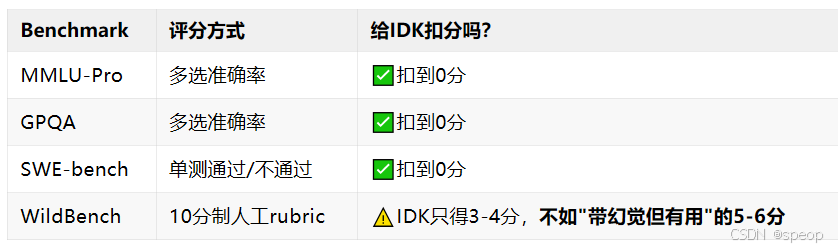
二、后训练阶段“考试机制”强化幻觉
对10个主流评测做了元评测,发现清一色惩罚不确定性:
三、解法:把"交白卷"变成可选项
呼吁不需要新benchmark,只要改评分规则:
1.明示信心阈值
在prompt里直接写:
"只有在你置信度>t时才回答:答错扣t/(1-t)分,IDK得0分。
2.让"弃权"成为最优策略
当模型真实置信度<t时,说“我不知道"的期望得分最高,说谎反而吃亏。
总结
OpenAI 表示:我们希望本文中的统计学视角能够阐明幻觉的本质,并纠正一些常见的误解:
误解1:通过提高准确性可以消除幻觉,因为一个 100%准确的模型永远不会产生幻觉。
发现:准确性永远无法达到100%,因为无论模型规模如何,搜索和推理能力怎样,一些现实世界的问题本质上是无法回答的。
误解2:幻觉是不可避免的。
发现:幻觉并非不可避免,因为语言模型在不确定时可以选择不作答。
误解3:避免幻觉需要一定程度的智能,而这种智能只有通过更大的模型才能实现。
发现:小型模型可能更容易了解到自身的局限性。比方说,当被要求回答毛利语问题时,一个完全不懂毛利语的小型模型可以直接说“我不知道”,而一个懂一些毛利语的模型必须确定其置信度。正如论文中所讨论的,“校准”所需的计算量远小于实现回答准确性的计算量。
误解4:幻觉是现代语言模型中一种神秘的缺陷。
发现:我们已经理解了幻觉产生的统计学机制,以及它们在评估中获得奖励的原因。
误解5:要衡量幻觉,我们只需要一个好的幻觉评估方法。
发现:尽管已经提出了多种幻觉评估方法,但一个优秀的评估方法对于目前现有的数百种传统准确性指标几乎没有影响。这些传统指标往往惩罚表达谨慎、谦逊的回答,并奖励猜测行为。因此,所有主要的评估指标都需要重新设计,更好地鼓励模型在表达上体现出不确定性。
大模型法则:读懂最火上下文工程
链接:https://mp.weixin.qq.com/s/CTpsm6sQ8lo9f84dwEhXNA
指令跟随
GIGPO将LLM进行复杂推理推广到Agent领域:LLM通过强化微调可以提升完成Agent任务的能力。这看起来好像和指令跟随有关系(这里[1]也有一些相关研究)
指令跟随(Instruction Following)是指在自然语言处理和人工智能领域,模型根据给定的自然语言指令或命令执行特定任务的能力。
无论是提示词、RAG、ToolCall还是Agent、MCP,它们其实都是偏应用层面的东西,当然不是说它不是算法,至少它们都是以LLM为核心的。
其实无论这些概念有多少,无论是新的还是旧的,无论怎么变化,都有一个共同核心——它们都是LLM的“上下文”。简单来说,它们都是给LLM提供某种信息的。
上下文工程
这个词来自《Context Engineering for AI Agents: Lessons from Building Manus[5]》
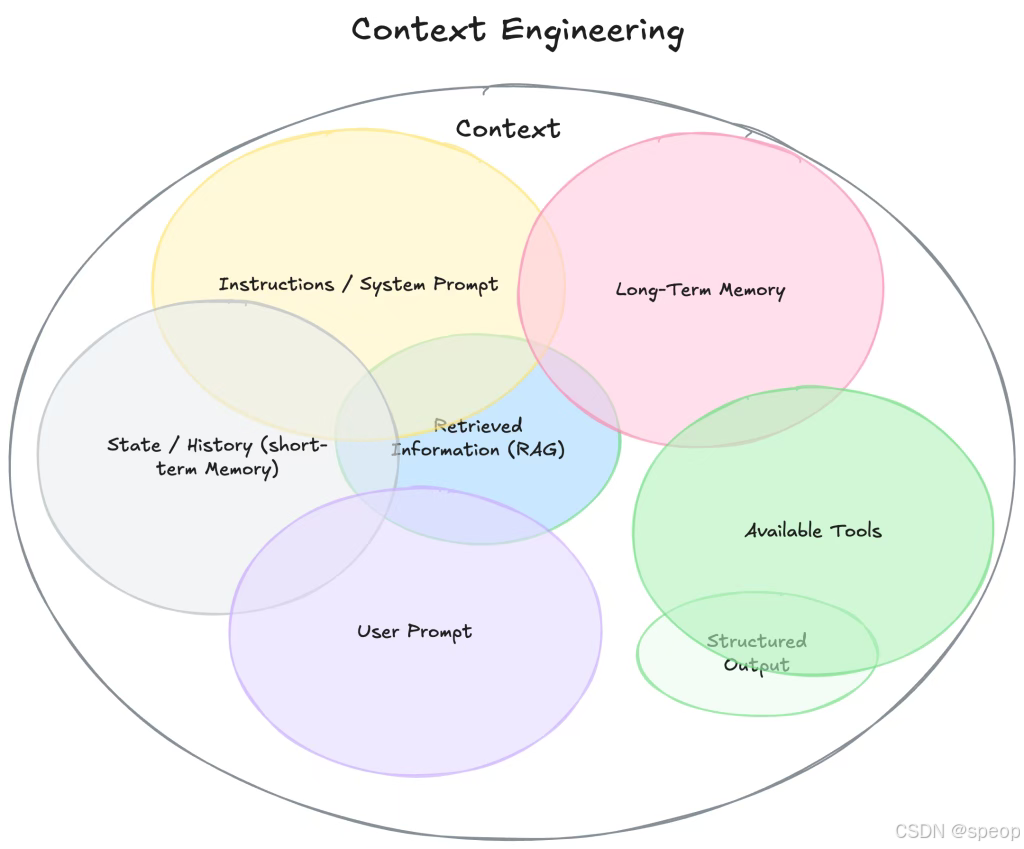
围绕KV Cache设计
定义:KV Cache 是指在 Transformer 模型的自回归推理过程中,缓存的 Key 和 Value。在 Transformer 的自注意力机制中,每个输入序列会生成 Query(查询)、Key(键)和 Value(值)三个矩阵,KV Cache 就是将之前计算得到的 Key 和 Value 张量进行缓存
工作原理:在 Transformer 的每一层和每个注意力头中,将计算得到的 Key 和 Value 张量存储到内存中。当生成新 token 时,仅计算新 token 的 Query、Key、Value,并将新 token 的 Key 和 Value 追加到缓存中。在注意力计算中,使用缓存的 Key 和 Value,结合新 token 的 Query,计算注意力输出。
存储结构:KV Cache 通常为每个 Transformer 层和每个注意力头维护单独的缓存,一般存储在 GPU 显存中,以保证快速访问。
缺点与挑战:对于长序列或多层大模型,显存占用可能成为瓶颈;需要高效管理缓存的分配和释放,否则可能导致显存泄漏;当序列长度超过一定限制,需要截断缓存或使用其他优化技术。
显然这是一个推理性能相关问题,KV Cache能够极大地提升推理效率。而且,随着上下文越来越长,输入输出Token比会越来越大,KV Cache的作用会更加明显。所以,尽量保证输入前缀的稳定性,新的信息从后面追加。如果使用vLLM,记得启动时开启prefix-caching[6],这样能够大大缩短预填充时间。这在长上下文任务和多轮对话场景下尤其有用。
Mask而非按需加载
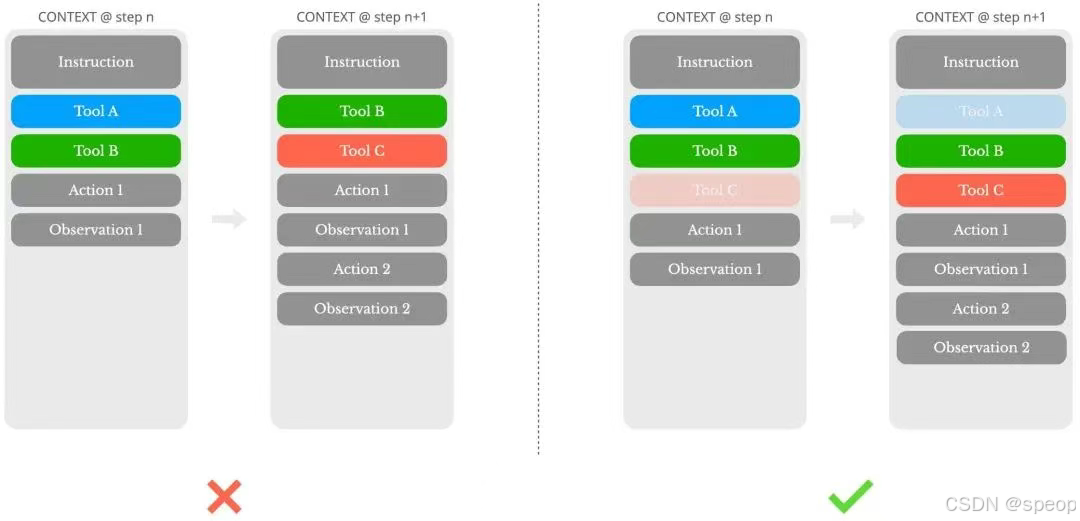
主要说的就是这些提供上下文的“信息源”,动态增删不仅会导致KV Cache失效,而且当先前的动作和观察仍然涉及当前上下文中不再定义的工具时,模型会感到困惑进而可能导致幻觉。Manus使用一个上下文状态感知状态机管理工具可用性,通过在解码过程中掩蔽token的logits,以基于当前上下文阻止(或强制)选择某些动作。
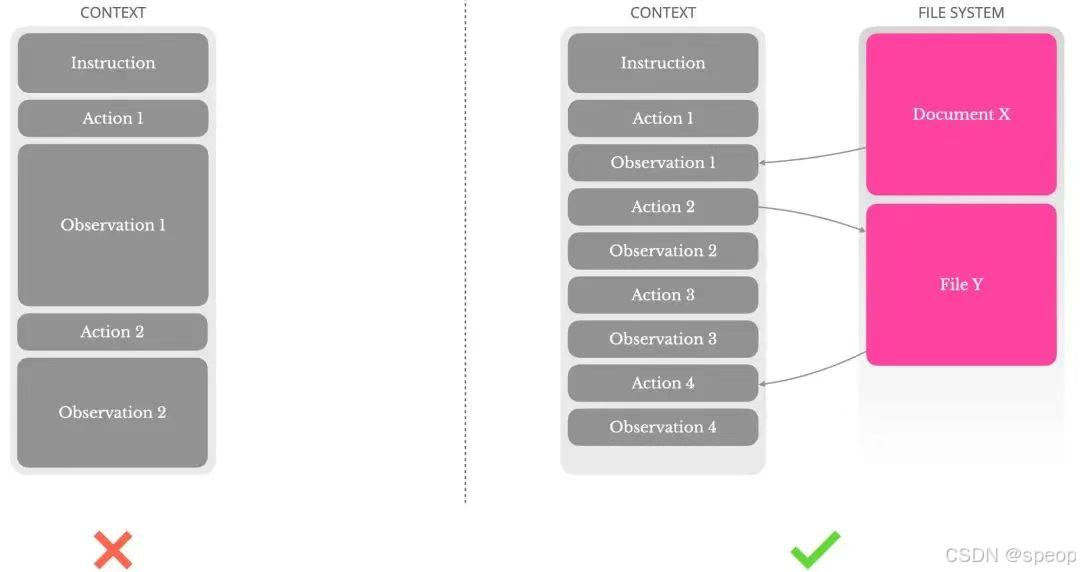
文件系统作为上下文
Agent的上下文信息经常太长,超出模型限制后性能下降,而且长输入成本也高。上下文截断或压缩策略可能导致信息损失,而且更关键的,Agent必须根据所有先前状态预测下个动作,我们没法保证那个信息在未来可能非常有用。所以,Manus将文件系统视为上下文,按需写入和读取。这里的压缩策略始终设计为可恢复的。比如,只要保留URL,网页内容就可以从上下文中移除。
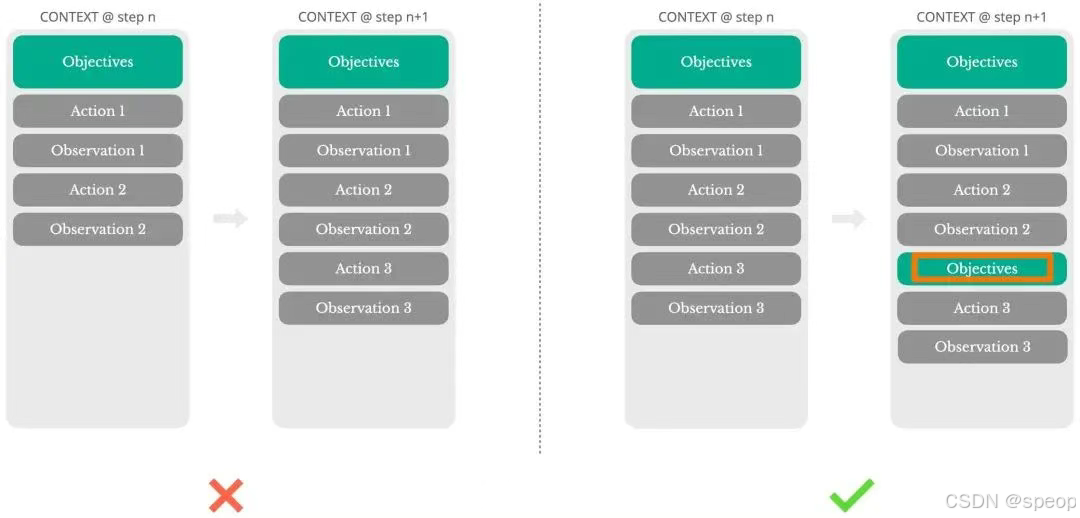
通过复述控制记忆
通过不断重复TODO,将目标复述到上下文末尾,缓解主题偏离和早期目标遗忘问题
保留错误内容
把错误的尝试保留在上下文中。当模型看到一次失败的动作——以及由此产生的观察结果或错误堆栈信息——它会在内部隐式地更新自己的信念。这会让模型对类似动作的“先验”偏好发生转变,从而降低再次犯同样错误的概率。
增加提示样本结构多样性
LLM模仿上下文中的行为模式。如果上下文充满了类似的过去行动-观察对,模型将倾向于遵循该模式,即使这不再是最优的。Manus在行动和观察中引入少量的结构化变化——不同的序列化模板、替代性措辞、顺序或格式上的微小噪音。这种受控的随机性有助于打破模式并调整模型的注意力。
小结
都是相当实用的设计,而且它是“通用”的,因为它针对的就是“上下文”。最后,引用文章最后的话
上下文工程仍是一门新兴的科学——但对于智能体系统来说,它已经变得不可或缺。虽然模型正变得更强大、更快速、更低成本,但再强的能力也无法取代记忆、环境和反馈的作用。你如何构建上下文,最终决定了智能体的行为方式:它运行得有多快、恢复得有多好、扩展得有多远。The agentic future will be built one context at a time. Engineer them well.
每家AI公司都应该问但没有问自己的一个问题是什么?如果你是前沿研究实验室,应该问:“我们的模型是在实现真正的智能进展,还是只是通过benchmark hacking在刷榜?”如果你是应用层公司,应该问:“我们做的事情,为什么大型模型厂商未来不会一秒钟就替代我们?
永远专注于能带来10倍提升的事,而不是纠结于那些只能带来 10% 改进的细节。
总的来说,高质量数据与LLM能力有关,但上下文工程可以更有效率地释放其能力。