本地部署的Qwen3,测试不同数量并发请求的吞吐量

当我们在本地部署一个模型后,往往对其处理并发请求的能力比较看重。
本文介绍测试本地部署模型吞吐量,以vllm部署的Qwen3为例,测试在不同数量级的并发用户请求场景下,模型吞吐量如何,回答响应时间怎么样,高并发会不会导致模型崩溃。
API格式
这里给出qwen3 的流式输出api调用python脚本:
from openai import OpenAIclient = OpenAI(base_url="http://server_ip:8001/v1",api_key="123456"
)
result = client.chat.completions.create(model="Qwen3-32B",messages=[{"role": "user", "content": "hello"}],max_tokens=2048,stream=True,
)for chunk in result:print(chunk.choices[0].delta.content,end="",flush=True)
测试指标
TTFT(time to first token),模型返回第一个token的时延。这个指标的来源主要是因为大语言模型输出有两个区分性的阶段:prefill阶段和生成阶段,prefill是模型前向传播所有的输入token,生成第一个输出token;生成阶段则是自回归的逐个预测下一个token。TPS(token per second),模型每秒生成多少个token,衡量生成文本的速度,吞吐量。
测试设定
我们基于令牌桶的方式,测试并发吞吐量,有两个主要参数:CONCURRENCY并发数,即同时发送请求的上限,NUM_REQUESTS总请求数,即模拟一个并发的测试阶段。如CONCURRENCY为50和NUM_REQUESTS为150,在测试开始时,50个请求同时发往模型,哪个请求结束了就从剩下的100个里面补上,保持50个请求的并发,直到150个请求全部完成。
限制模型的输入长度和输出长度,这两个都会影响响应时间。
import asyncio
import httpx
import time
import statistics
import jsonAPI_URL = "http://server_ip:8001/v1/chat/completions"
API_KEY = "12345"
CONCURRENCY = 5000 # 并发请求数
NUM_REQUESTS = CONCURRENCY*3 # 总请求数RAG_content = "多模态基础模型是人工智能大模型的基础技术。。。“async def call_model(semaphore, idx):async with semaphore:headers = {"Authorization": f"Bearer {API_KEY}"}prompt_ = f"请总结下面这段参考资料的主要内容,以精炼的语言概括,300字左右。参考资料:{RAG_content}" prompt = prompt_ #[:6100]payload = {"model": "Qwen3-32B","messages": [{"role": "user", "content": prompt}],"max_tokens": 120,"stream": True # 支持流式输出}async with httpx.AsyncClient(timeout=None) as client:t0 = time.time()t_first = Nonet_end = Noneoutput_text = ""async with client.stream("POST", API_URL, headers=headers, json=payload) as response:async for chunk in response.aiter_text():for line in chunk.splitlines():line = line.strip()# print(line)if not line:continuetry:# print(line[6:])data = json.loads(line[6:])# print(data)# 取 delta.contentchoices = data.get("choices", [])for choice in choices:delta = choice.get("delta", {})content = delta.get("content", "")if content:if not t_first:t_first = time.time() # 记录第一个 token 时间output_text += content# print(content, end="")except json.JSONDecodeError:passt_end = time.time()ttft = (t_first - t0) * 1000 if t_first else Nonefull_latency = (t_end - t0) * 1000input_len = len(prompt) # 粗略按空格计算 token# print(output_text)output_len = len(output_text) # 同样按空格拆分,若 API 返回 token 数可直接用if output_len <= 100:print(output_text)tokens_per_sec = (output_len / (full_latency / 1000)) if output_len > 0 else 0print(f"[{idx}] TTFT: {ttft:.2f} ms, Full: {full_latency:.2f} ms, Input tokens: {input_len}, Output tokens: {output_len}, Throughput: {tokens_per_sec:.2f} tok/s")return ttft, full_latency, input_len, output_len, tokens_per_secasync def main():semaphore = asyncio.Semaphore(CONCURRENCY)tasks = [call_model(semaphore, i) for i in range(NUM_REQUESTS)]results = await asyncio.gather(*tasks)ttft_list = [r[0] for r in results if r[0] is not None]full_list = [r[1] for r in results]input_lens = [r[2] for r in results]output_lens = [r[3] for r in results]tps_list = [r[4] for r in results]print("\n=== Statistics ===")print(f"Input tokens: mean={statistics.mean(input_lens):.2f}, max={max(input_lens)}, min={min(input_lens)}")print(f"Output tokens: mean={statistics.mean(output_lens):.2f}, max={max(output_lens)}, min={min(output_lens)}", "\n")print(f"TTFT: mean={statistics.mean(ttft_list):.2f} ms, p2={statistics.quantiles(ttft_list, n=100)[2]:.2f} ms, p99={statistics.quantiles(ttft_list, n=100)[98]:.2f} ms")# print(f"Full: mean={statistics.mean(full_list):.2f} ms, p2={statistics.quantiles(full_list, n=100)[2]:.2f} ms, p99={statistics.quantiles(full_list, n=100)[98]:.2f} ms")print(f"Throughput: mean={statistics.mean(tps_list):.2f} tok/s, min={min(tps_list):.2f}, max={max(tps_list):.2f}")failed_num = 0for output_len in output_lens:if output_len<=100:failed_num += 1print(f"Failed Number: {failed_num}")if __name__ == "__main__":asyncio.run(main())
测试分析
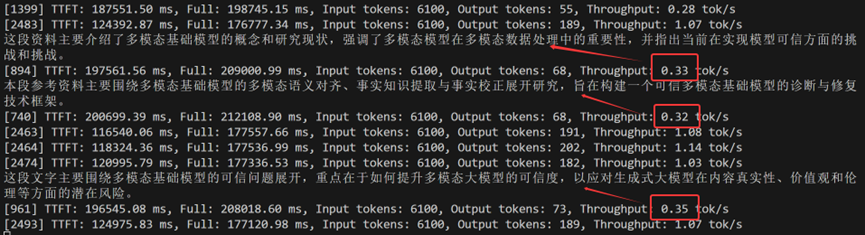
如上图,测试发现:在高并发场景下,有些请求的TPS会很小,即模型输出token很缓慢。这时系统倾向于输出“精简回答”以快速结束该请求,这是一种推理优化机制:
1、 为了降低整体延迟,有些服务会提前截断长回复,或者优先保证“先给点输出”,避免某些请求长时间占用显卡资源;
2、 vLLM在高负载下会动态调整,early stopping 策略、动态截断,这些策略会让平均输出变短,即使 prompt 相同;
3、 高并发时平台切换到 更保守的采样策略(例如降低温度,避免长而发散的输出),模型会偏向更短更直接的回答。
但并不代表高并发就一定会出现这种情况,只能说是一种概率。在高并发场景,更有可能出现一些请求的TPS很小的情况,TPS很小时则会触发简短输出。下面的截图和上面截图是同一次测试实验的不同阶段,下图的TPS虽然在高并发前提下也都不高,但较稳定,就没有出现简短回复。根据测试经验,如果系统的请求并发数量比较稳定(即使是高并发),虽然回复慢,但不会出现简短回复(如下图,高并发测试实验的后期);如果短时间突增到高并发(如上图,高并发测试实验的发起阶段),不稳定,则可能出现简短回复。
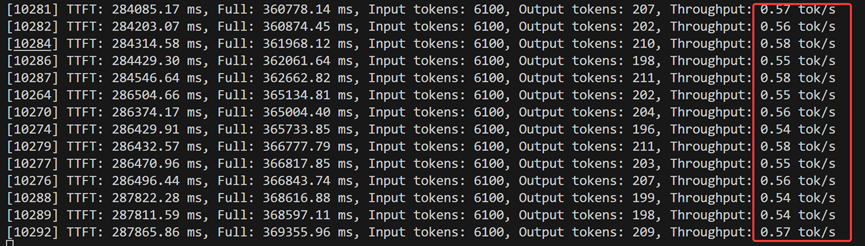
测试发现,在超高并发下,vllm也不会崩溃(拒绝回答,或者模型OOM),但响应时间会显著增加,这是因为,vllm主要采取队列措施,高并发请求是以排队的方式被处理,而不是一次性全扔进模型,所以不会崩溃,但延迟大大增加:
1、 vLLM 默认不会丢弃请求(不像一些在线服务会启用 限流/拒绝策略),如果并发持续超负荷,延迟会线性累积,用户可能要等几十秒甚至几分钟。
2、 如果超高并发 + 特别长的 context length,vLLM 可能会 fallback 到 CPU paging(把 KV swap 出去),这时生成速度会骤降,但依然不会直接崩溃。
总结:高并发场景下,vllm不会限流、不会超时、不会崩溃,只会延长排队,导致时延显著增加。时延较长可能触发API请求超时(通常调用商业api出错应该是这里超时)或者网页端http超时,但后台模型推理不会有问题,即使这个时延对用户来说已经完全不可接受。
所以可以在api里面限流,因为当队列过长时,延时太大,返回没有意义,不如直接不要浪费计算资源。