多模态大模型Keye-VL-1.5发布!视频理解能力更强!
近日,快手正式发布了多模态大语言模型Keye-VL-1.5-8B。
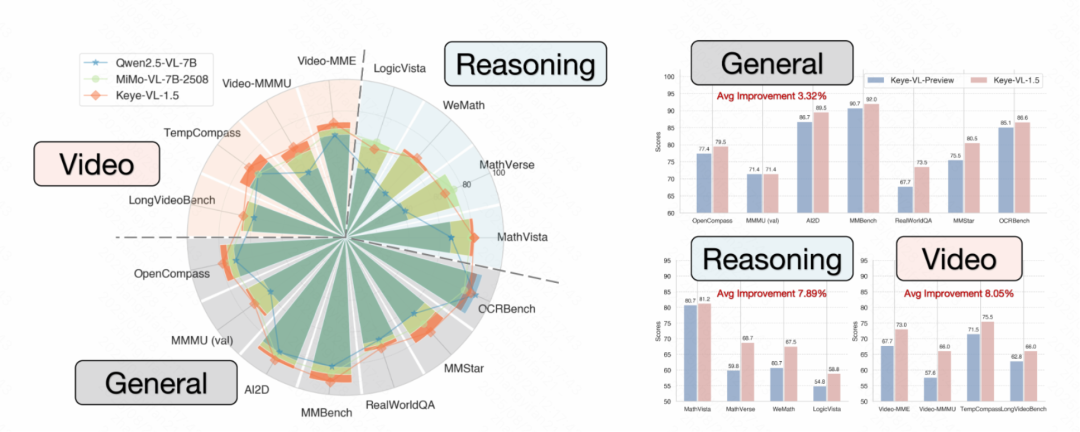
与之前的版本相比,Keye-VL-1.5的综合性能实现显著提升,尤其在基础视觉理解能力方面,包括视觉元素识别、推理能力以及对时序信息的理—表现尤为突出。Keye-VL-1.5在同等规模的模型中表现出色,甚至超越了一些闭源模型如GPT-4o。
Keye-VL-1.5-8B在技术上实现了三项关键创新:
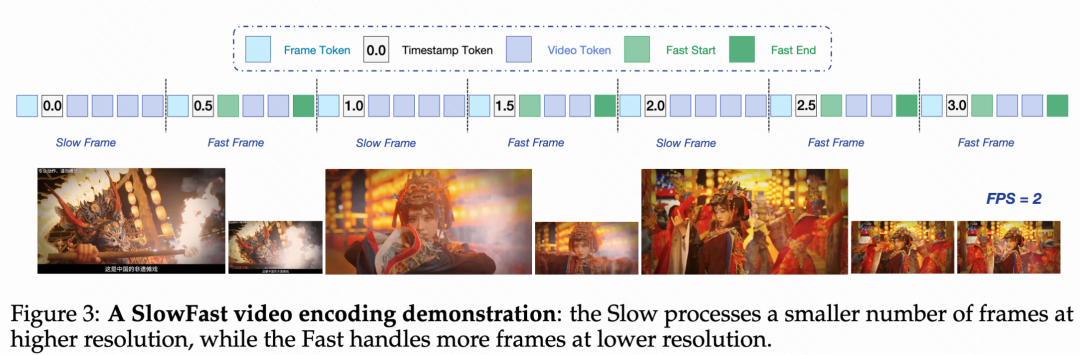
- 引入慢快编码策略(Slow-Fast):该策略基于相似性算法自动区分慢帧与快帧,并将快帧的 token 预算控制为慢帧的 30%。同时,通过引入特殊 token 和时间戳标记帧边界,有效平衡了性能与计算成本。
- 采用渐进式四阶段预训练方法:从跨模态对齐与多任务预训练起步,在退火阶段将模型上下文长度从 8K 扩展至 128K,使其能够处理更长视频和更复杂的视觉内容,大幅增强视频理解能力。最终的模型融合阶段通过使用不同数据混合训练的模型进行组合,以提高鲁棒性并减少偏差。
- 全面优化后训练流程:提出五步自动化数据构造流水线,基于 GSPO 算法迭代通用强化学习与对齐阶段,全面提升模型的推理能力并与人类偏好对齐。
在多个公开的视频基准测试中,Keye-VL 1.5 8B在同等规模的模型中性能最优,并在MMMUval和AI2D等大规模基准测试中,Keye-VL 1.5 8B取得了业界最佳成绩!
Keye-VL-1.5-8B现已开源,并公布了公开技术报告,欢迎各位开发者前往体验和交流。
项目主页:https://kwai-keye.github.io/
技术报告:https://arxiv.org/pdf/2509.01563
Github:https://github.com/Kwai-Keye/Keye
Model:https://huggingface.co/Kwai-Keye/Keye-VL-1.5-8B
先来看三个案例:
案例一:时序信息理解
demo1
Prompt:视频中包出现的时间段是多少?
Keye:视频中包出现的时间段是22.3秒至23.8秒。
案例二:推理能力
demo2
Prompt:视频里大狗咬小狗的耳朵是为什么?
keye:视频中,小狗试图扒着桌子够取食物,大狗(狗爸)通过轻咬小狗耳朵的行为,实则是在**纠正小狗的不当行为**。这种轻咬是狗群中常见的“教育”方式,成年狗会用它告诉幼崽“这样做不对”,需遵守规则。当小狗收到这一信号后,便从站立够食的状态逐渐坐下来,最终躺下服从管理,说明大狗的行为成功传递了“不能偷食桌上食物”的警告。 \boxed{大狗咬小狗耳朵是纠正其试图偷吃桌上食物的错误行为,通过轻咬传递警告让小狗服从管理。}
案例三:描述能力
demo3
Prompt:请仔细描述视频中的场景内容?
Keye:视频的主要场景是一个被茂密森林环绕的潮湿角落,画面中间是一条破损的老旧石阶,石板的石板有裂,表面长满绿色苔藓和杂草,显得斑驳沧桑。周围是高大的深色树木,树枝上挂着鲜绿色的树叶,树叶间透出柔和的散射光,给场景增添了一层朦胧感。地面上散落着许多小白花或菌类,与绿色苔藓交织,形成生机盎然的地面覆盖。背景中森林延伸至远方,树木逐渐模糊,展示出场景的深度与神秘感。空气中似乎带着细密的雨雾,地面和石阶都显得潮湿,偶尔有雨滴落下,进一步强化了潮湿的气氛。整体色调绿色和棕色为主,呈现出一种静谧。自然且略带荒凉的原始森林景象。
「核心技术架构全公开」
Keye-VL-1.5采用经典的多模态大语言模型架构,由三个核心组件构成:视觉Transformer(ViT)、MLP投影器和语言解码器。该模型使用SigLIP-400M-384-14作为视觉编码器,Qwen3-8B作为语言解码器。在Vision encoder方面,采取了原生分辨率ViT,2D ROPE增强高分图像理解,使用了500B Token的多源数据进行预训练。在视觉特征处理方面,针对不同视觉输入采用差异化编码策略。对于图像,每张图像使用20,480个token来保证细节捕获。
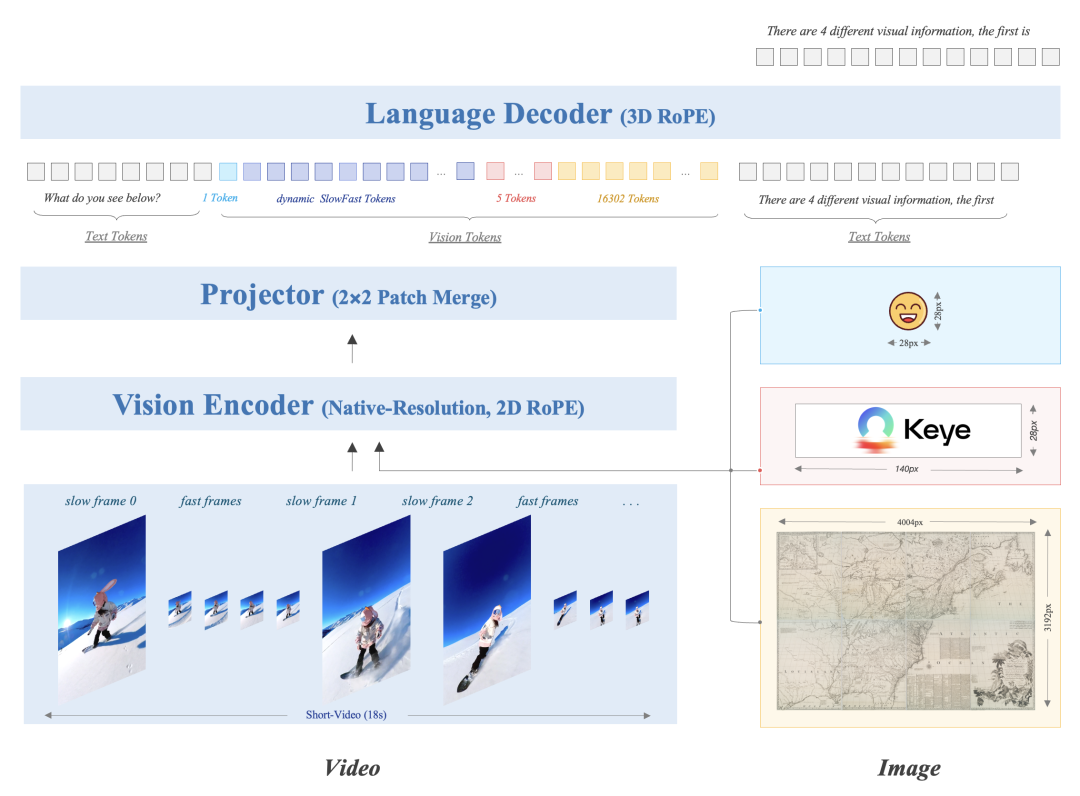
一、慢快编码策略:兼顾性能与成本
视频内容通常包含两种类型的画面:一种是快速变化、富含细节的画面(如运动场景),另一种是相对静态的画面(如静止风景)。为了在短视频理解任务中同时实现高准确性与高效率。Keye-VL-1.5 创新性地提出了慢快编码策略 (slow-fast),该策略设置慢通路处理快速变化帧(低帧数-高分辨率),快通路处理静态帧(高帧数-低分辨率),从而在节省计算资源的同时保留关键信息。
具体来说,通过基于图片相似性的算法自动识别慢快帧,快帧的token预算设为慢帧的30%,并引入特殊token和时间戳来标识帧边界,实现了性能与计算成本的有效平衡。
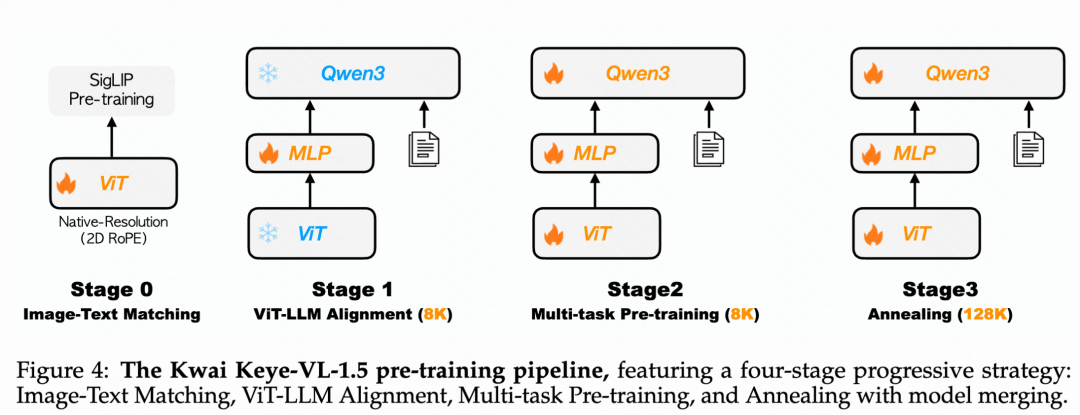
二、Pretrain 策略:渐进式四阶段预训练方法
Keye-VL-1.5采用精心设计的四阶段渐进式训练流水线,确保每个阶段都有清晰且相互关联的目标。
视觉编码器预训练:使用SigLIP-400M权重初始化ViT,通过SigLIP对比损失函数进行持续预训练,适应内部数据分布。
第一阶段 - 跨模态对齐:专注优化投影MLP层,建立跨模态特征的稳固对齐基础。
第二阶段 - 多任务预训练:解冻所有模型参数进行端到端优化,显著增强模型的基础视觉理解能力。
第三阶段 - 退火训练:在精选高质量数据上进行微调,解决第二阶段大规模训练中高质量样本接触不足的问题。同时将序列长度从8K扩展至128K,RoPE逆频率从100万重置为800万,并引入长视频、长文本和大尺度图像等长上下文模态数据。
模型融合:为减少固定数据比例带来的内在偏差,在预训练最终阶段采用同质-异质融合技术,对不同数据混合比例下退火训练的模型权重进行平均,保持多样化能力的同时减少整体偏差,增强模型鲁棒性。
三、Post-training策略:全面提升推理能力与人类偏好对齐
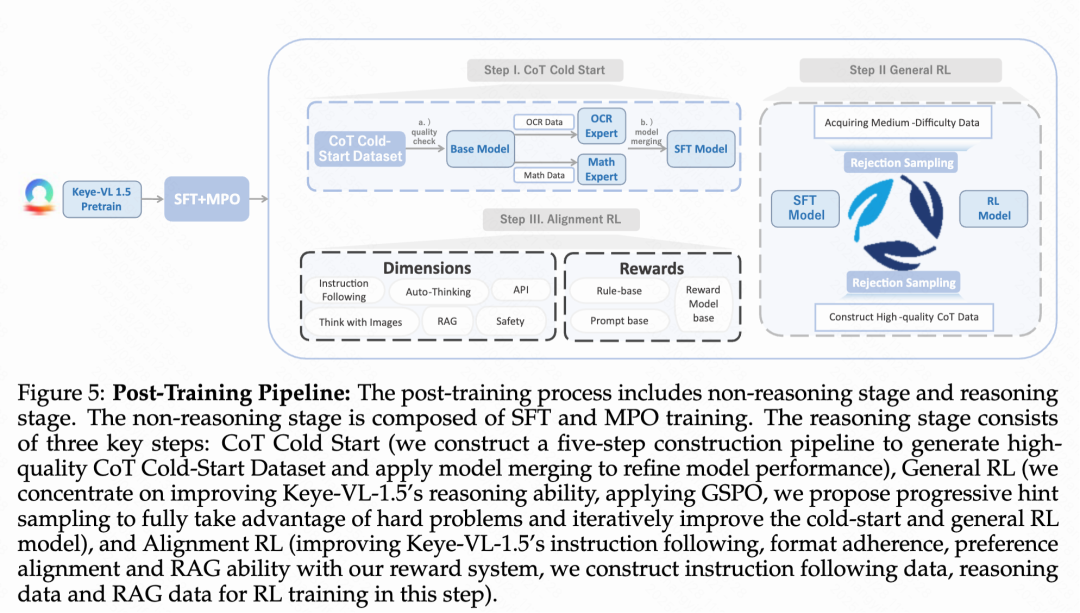
Keye-VL-1.5的训练后处理包含四个主要阶段:
Stage 1:监督微调与多偏好优化
使用750万个多模态问答样本进行监督微调,然后通过MPO算法进一步提升性能。
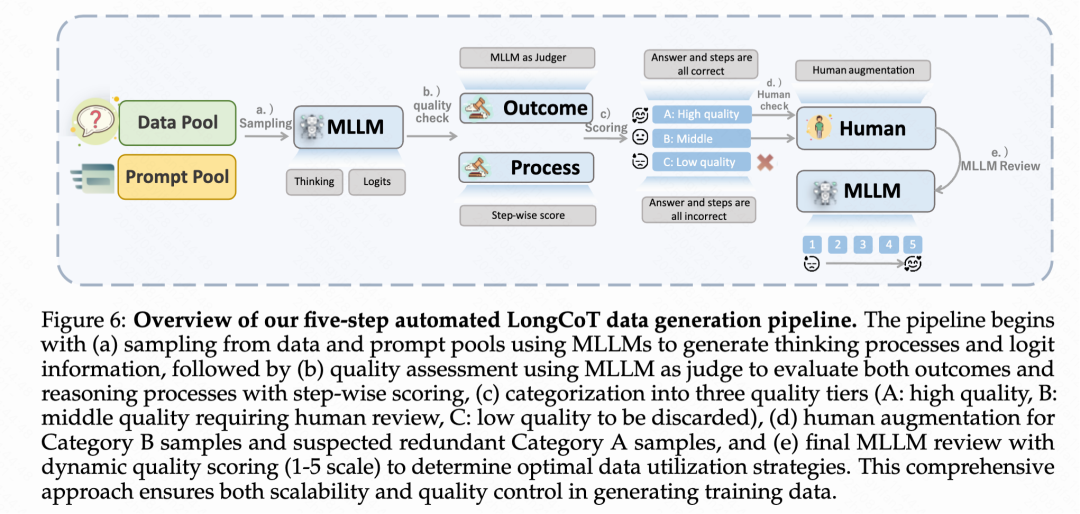
Stage 2:长链思考冷启动
为了获取高质量的冷启动训练数据,Keye-VL-1.5提出了一个全面的五步自动化流水线来生成高质量长链思考数据。首先从多个挑战性领域收集多模态问答数据,并使用专有模型进行问题重写和任务合并以增加复杂性;然后为每个问答对生成多个推理轨迹并量化模型置信度;接着实施双层质量评估框架,同时评估答案正确性和推理过程有效性,将样本分为高质量(A类)、中等质量(B类)和低质量(C类)三个等级;对于B类样本和部分A类样本,采用人工指导的改进过程来提升推理质量;最后实施五点质量评分系统和自适应数据利用策略,让高质量样本在训练中被更频繁使用。
Stage 3:迭代通用强化学习
使用GSPO算法进行可验证奖励强化学习训练,采用渐进提示采样处理困难样本(对于模型多次rollout都回答不对的样本,在prompt中给予不同程度的提示),通过多轮迭代持续优化模型推理能力。这个阶段和long cot sft迭代进行,使用RL模型 rollout更好的response(reward model 打分)进行SFT,然后使用SFT模型进行下一阶段的RL数据筛选与训练。
Stage 4:对齐强化学习
重点增强模型在指令遵循(生成满足用户内容、格式、长度要求的回应),instruction following(确保回应符合预定义格式如思考-回答等模式)和偏好对齐(提高开放式问题回应的可靠性和交互性)三个维度的能力。
四、实验效果
Keye-VL在多模态AI领域取得突破性进展
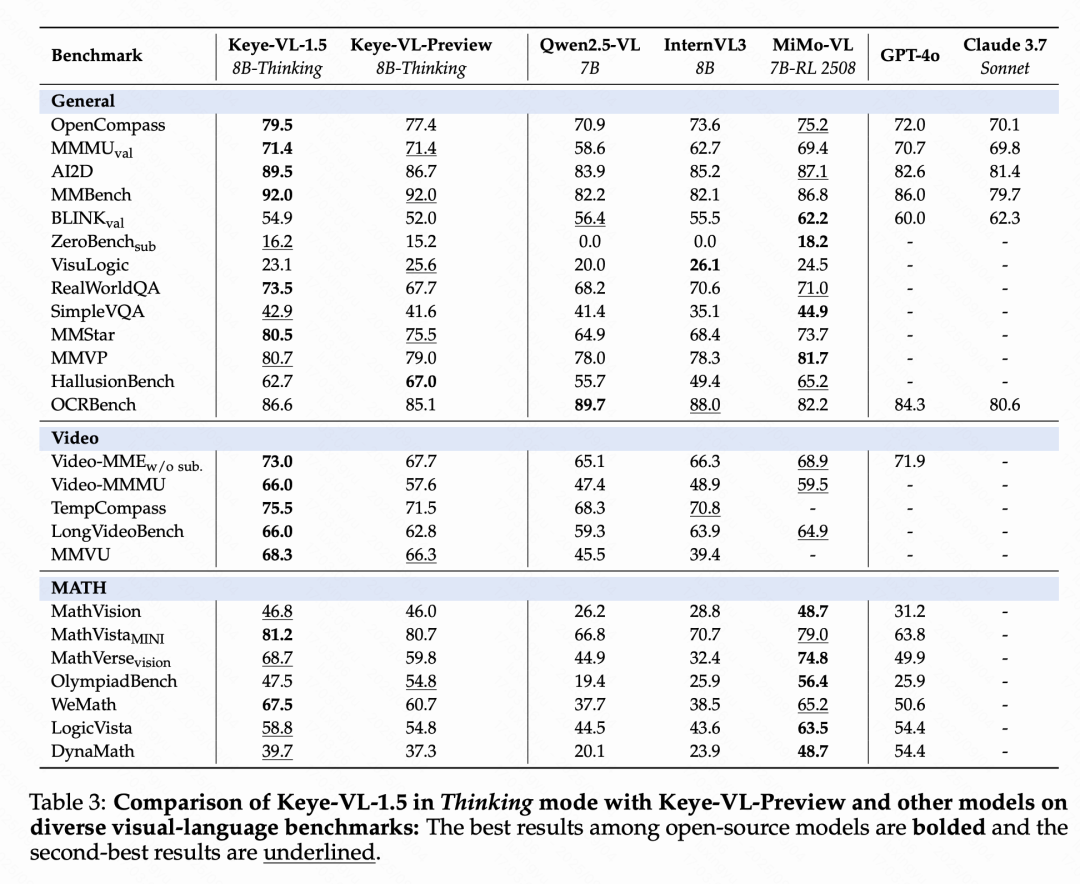
在通用视觉语言任务中,该模型在思考模式下于MMMUval和OpenCompass等大规模基准测试中分别获得71.4%和79.5%的同等scale的业界最佳成绩,在ZeroBenchsub和MMVP等挑战性测试中同样表现卓越,并在HallusionBench中实现62.7%准确率,显著降低AI幻觉现象。在视频理解领域,Keye-VL表现更佳,在Video-MMMU测试中达到了66分,充分证明了其在视频内容理解方面的技术优势。
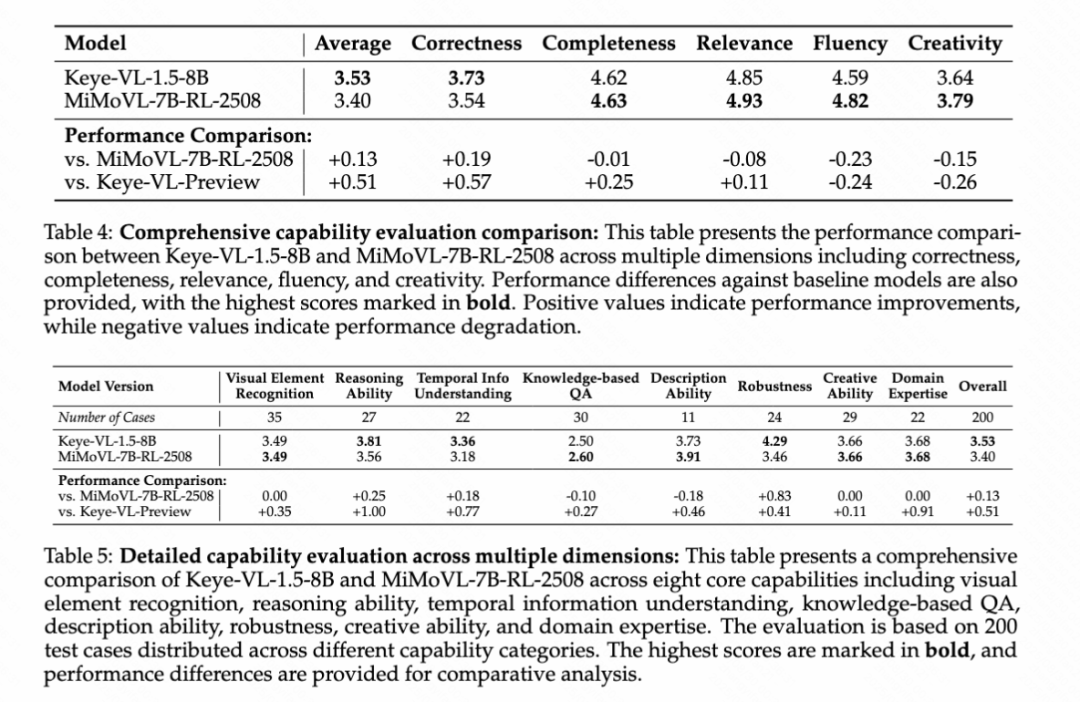
Keye-VL内部人工基准测试显示显著性能提升
为了全面评估模型能力,快手Keye团队构建了严格的内部视频评估基准,解决了公开基准测试存在的任务覆盖有限、问题格式过于简化、答案方法受限、数据污染风险和语言文化偏见等问题。该基准涵盖视觉元素识别、推理能力、时序信息理解、基于知识的问答、描述能力、鲁棒性、创造能力和领域专业知识八个维度,采用多模型对比评估和GSB偏好选择的评分方法。
评估结果显示,Keye-VL-1.5-8B取得了显著的性能提升:总体综合得分达到3.53,相比Keye-VL-Preview提升0.51分,在正确性(+0.57)和完整性(+0.25)方面表现尤为突出。与行业基准MiMoVL-7B-RL-2508的直接对比中,Keye-VL-1.5-8B获得更高的总体得分(3.53对3.40),在正确性方面领先0.19分。详细能力分析显示,该模型在推理能力(3.81)、时序信息理解(3.36)和鲁棒性(4.29)方面表现卓越,其中鲁棒性相比竞品领先0.83分,充分证明了模型在处理复杂分析任务和保持稳定性能方面的强大优势。相比前版本,模型在基础视觉理解能力方面建立了坚实基础,视觉元素识别提升0.35分,推理能力提升1.00分,时序信息理解提升0.77分,为处理复杂多模态推理任务提供了强大的技术支撑。
展望未来,依托快手在短视频领域深厚的技术积累,Kwai Keye-VL 在视频理解方面具备独特优势。该模型的发布与开源,标志着多模态大语言模型在视频理解新纪元的探索迈出了坚实一步。