如何在本地机器上使用LLM构建知识图谱(一)
本篇文章How to Build Knowledge Graphs using LLMs on Local Machine | by Asutosh Nayak | The Muse Junction | Aug, 2025 | Medium适合对知识图谱构建感兴趣的初学者,亮点在于利用小型的LLM(如Gemma3 4B模型)在本地构建知识图谱,简化了实体提取和关系映射的过程。文章详细介绍了如何通过系统提示和代码实现这一过程,适合在资源有限的情况下进行尝试。
文章目录
- 1 知识图谱入门
- 2 如何使用大型语言模型构建知识图谱
- 3 代码实现
- 4 结论
任何做过实体抽取(Entity Extraction)或构建过知识图谱(Knowledge Graphs,以下简称 KG)的人都知道这其中涉及多少工作,尤其是在文本预处理和共指消解(将“他”这样的词映射到实体)等语法相关方面。因此,随着大型语言模型(LLMs)能力的不断增强,我希望亲自动手尝试一下,看看 LLMs 是否能简化这项工作以及它们的表现如何。我主要对那些可以在笔记本电脑上舒适运行的小型模型感兴趣,因为并非每个人都有庞大的预算或高端 GPU。
我将简要介绍知识图谱(仅足以理解本文内容),解释 LLMs 如何辅助知识图图谱的构建,最后展示实现此目的的代码。代码位于 GitHub 仓库中:https://github.com/nayash/knowledge-graph-demo
在这篇博客中,我选择了 Google 的 Gemma3 4B 模型,它经过指令微调和量化处理(Google 发布的 gemma3–4b-it-qat),因为它比 1B 模型更大(我之前在其他任务上测试过 llama-1b 模型,但效果不佳),但又足够小,可以适应 8GB GPU。Google 发布了它的量化版本,这进一步帮助了我。
1 知识图谱入门
知识图谱 (KG) 是一种以结构化、互联的形式表示知识的方式——几乎就像一张事实地图。KG 不会将信息存储为孤立的文本或表格,而是将知识组织成:
- 实体(节点): 世界中的“事物”(例如,巴拉克·奥巴马、乌鸦、水)。
- 关系(边): 这些事物如何连接(例如,巴拉克·奥巴马 → 出生于 → 夏威夷,乌鸦 → 喝 → 水)。
这种实体和关系的网络形成了一个可以搜索、推理和可视化的图。边也可以有权重、属性、方向等。
示例:语句——“比尔博·巴金斯正在庆祝他的 111 岁生日。”——应该生成 比尔博·巴金斯[节点] → 庆祝[边] → 生日[节点] 这样的图。在高级情况下,我们还可以为边/关系关联一个属性(这里是 111 岁)。
2 如何使用大型语言模型构建知识图谱
以下是我们从给定文本中构建 KG 所需的步骤:
- 选择要构建 KG 的文本。
- 构建一个良好的系统提示,指示 LLM 执行文本清理和实体关系抽取(我将在此处提供一个示例)。
- 将文本传递给 LLM 并保存响应。
- 解析响应以形成 KG。
3 代码实现
- 为了尝试这种方法,我选择了一个著名的短篇故事“口渴的乌鸦”(一段文本)。但由于我们打算通过 LLM 而不是编写代码来预处理文本,我们将保持文本原样。我还将这种方法应用于卡夫卡的《变形记》。你将在结论中找到详细信息。
炎热的一天,一只口渴的乌鸦飞来飞去寻找水。过了很久,它在一个花园里看到一个水罐。乌鸦往里面看,发现底部只有很少的水。
它试图用喙够到水,但水太低了。然后聪明的乌鸦想到了一个计划。它一个接一个地捡起小石子,把它们扔进水罐里。
慢慢地,水位越来越高。乌鸦高兴地喝了水,然后飞走了。
如前所述,我选择了“gemma3:4b-it-qat”模型作为 LLM,因为它足够大,可以遵循指令,又足够小,可以适应消费级笔记本电脑,而且它也有不错的性能。为了在我的系统上运行这个模型,我使用了 Ollama。通过 Ollama 下载和提供模型都很容易。
ollama pull gemma3:4b-it-qat # 下载模型
ollama run gemma3:4b-it-qat # 在你的机器上运行模型
- 最大的挑战是向模型提供一个好的系统级提示,以指示模型正确抽取实体关系。首先,我尝试了一个我手动编写的提示。它运行良好。但后来我将该提示输入给 ChatGPT,并要求它为我生成另一个提示。我选择了第二个,因为它提供了更好的抽取效果。请注意,我没有对生成的提示进行任何更改,也没有努力改进它,因此仍有很大的改进空间。这是提示:
你是一名擅长英语的辅助助手,任务是从输入句子中抽取可用于知识图谱的(entity-relation-entity)三元组。
你的工作是识别适合高质量知识图谱构建的实体-关系-实体三元组。
输出格式:
仅返回一个 JSON 对象数组,不包含任何额外字符、解释或周围文本。
每个对象必须遵循此精确模式(如果属性不存在,则为空字符串):
[{"head_entity":{"entity":"<string>", "attribute":"<string>"},"relation":{"relation":"<string>", "attribute":"<string>"},"tail_entity":{"entity":"<string>", "attribute":"<string>"}}]核心抽取规则:
关系:对谓词使用小写词元(词根)形式;通过词形还原规范化屈折形式(例如,“celebrated” → “celebrate”)。
共指消解:解决跨句的代词和名词指代,并将其替换为规范实体提及(例如,“He” → “Bilbo Baggins”)。
去重:规范化后避免重复的三元组;保留相同头-关系-尾的单个实例。
实体清理:剥离限定词和标点符号,保留多词名称,并在可解析的情况下使用清理后的规范表面形式。
形容词和修饰语:将描述性形容词、序数词、数字、日期和类似的修饰语作为最近相关实体的属性(例如,“111th”在“birthday”上)。
介词和规范化关系:在适当的时候将常见介词或名词模式映射到规范的蛇形命名法(snake_case)关系名称(例如,give_to, located_in, part_of, born_in, work_at)。
语态规范化:对于被动语态结构,将逻辑主语恢复为头实体,将宾语恢复为尾实体(例如,“The ring was given to Frodo by Bilbo” → head=Bilbo, relation=give_to, tail=Frodo)。
并列结构:当并列成分表示独立事实时,将其拆分为多个三元组(例如,“Bilbo and Frodo traveled to Rivendell” → 两个三元组,每个主体一个)。
否定:如果谓词被明确否定(例如,“not”、“never”),则保持关系为词元形式,并将 relation.attribute 设置为“negated”。
不确定性和条件句:对于明确的模态/条件性(例如,“may”、“might”、“if”),保持词形还原后的关系,并将 relation.attribute 设置为简短的限定词,如“modal:may”或“conditional”。
文档级关系:当通过共指消解或语篇明确表达时,允许跨句关系,但不要推断未说明的事实。
不要凭空创造属性:只包含文本中明确存在或可安全规范化的属性;否则使用空字符串。
最佳实践提醒:
优先使用以动词为中心的谓词;当这能更好地捕捉关系时,将名词化转换为其动词词元(例如,“celebration” → “celebrate”)。
保持实体和关系简洁明确;避免重叠或同义的重复(例如,对于相同的事实,不要同时发出 give 和 give_to)。
始终使用英语;在抽取前对文本进行清理。
示例:
输入:“Bilbo Baggins was celebrating his 111th birthday.”
输出:
[{"head_entity":{"entity":"Bilbo Baggins","attribute":""},"relation":{"relation":"celebrate","attribute":""},"tail_entity":{"entity":"birthday","attribute":"111th"}}]输入:“Bilbo was celebrating his birthday. He gave the ring to Frodo.”
输出:
[{"head_entity":{"entity":"Bilbo Baggins","attribute":""},"relation":{"relation":"celebrate","attribute":""},"tail_entity":{"entity":"birthday","attribute":""}}, {"head_entity":{"entity":"Bilbo Baggins","attribute":""},"relation":{"relation":"give_to","attribute":""},"tail_entity":{"entity":"Frodo","attribute":""}}]输入:“Bilbo was celebrating his birthday. Frodo celebrated the party.”
输出:
[{"head_entity":{"entity":"Bilbo","attribute":""},"relation":{"relation":"celebrate","attribute":""},"tail_entity":{"entity":"party","attribute":""}}, {"head_entity":{"entity":"Frodo","attribute":""},"relation":{"relation":"celebrate","attribute":""},"tail_entity":{"entity":"party","attribute":""}}]输入:“The ring was given to Frodo by Bilbo.”
输出:
[{"head_entity":{"entity":"Bilbo","attribute":""},"relation":{"relation":"give_to","attribute":""},"tail_entity":{"entity":"Frodo","attribute":""}}]输入:“Bilbo did not attend the party.”
输出:
[{"head_entity":{"entity":"Bilbo","attribute":""},"relation":{"relation":"attend","attribute":"negated"},"tail_entity":{"entity":"party","attribute":""}}]仅返回指定格式的 JSON 数组,精确匹配模式,不包含任何额外字符。
这个提示向模型解释了它的目标以及它应该如何返回响应。你可以通过查看提示中的示例来理解响应结构。
- 现在我们的提示已准备就绪,我们可以将文本传递给它。但我们需要分批传递文本,以避免内存或上下文长度问题。此外,我注意到过长的文本会稍微降低模型输出的质量。因此,批处理大小也是一个可以进一步探索的超参数。
def process_chunk(text, out):response = ollama.chat(model=model, messages=[{"role": "system", "content": system_prompt},{"role": "user", "content": text}])resp_content = remove_extras(response['message']['content'])try:t = json.loads(resp_content)out.extend(t)except json.JSONDecodeError:print(f"Failed to decode JSON from response: {resp_content}")return responsesentences = full_content.split('.')
batch_size = config['batch_size']
for i in tqdm(range(0, len(sentences), batch_size)):batch = sentences[i:i+batch_size]paragraph = ".".join(batch)process_chunk(paragraph, all_triples)if i % 100:save_obj(all_triples, f"./output/{out_label}_all_triples.pkl")print(f'{len(all_triples)} triples found')
save_obj(all_triples, f"./output/{out_label}_all_triples.pkl")
首先,我将文本内容读取到变量 full_content 中,然后将其拆分为句子。这只是为了形成一些批次,模型仍然以段落形式接收句子。然后,这批句子通过 ollama.chat 调用传递给模型。系统提示也在此处传递。模型的输出是一个实体-关系-实体三元组列表,存储在变量 all_triples 中。
- 一旦模型处理完所有文本,我们就会使用
all_triples中的值来形成一个图(KG)。为此,我使用了 Python 包networkX。
G = nx.MultiDiGraph()for triple in tqdm(all_triples):head = triple['head_entity']['entity']if 'tail_entity' in triple:tail = triple['tail_entity']['entity']else:tail = "null"print(f'triple with no tail entity: {triple}')relation = triple['relation']['relation']G.add_node(head, attr=triple['head_entity']['attribute'])G.add_node(tail, attr=triple['tail_entity']['attribute'] if 'tail_entity' in triple and 'attribute' in triple['tail_entity'] else "")G.add_edge(head, tail, relation=relation)
就是这样!现在你有了你的知识图谱。但是我们怎么知道 LLM 是否正确地抽取了数据呢?
- 我们需要在图表中查看数据。我在这里使用了另一个 Python 包
pyvis来可视化 KG。pyvis能够精美地绘制图表,而且它还是交互式的!
net = Network(notebook=True, cdn_resources='in_line')
net.set_edge_smooth('dynamic')
net.toggle_physics(True)
net.from_nx(G)for edge in net.edges:edge['label'] = edge['relation']net.show(f"./output/graph_{out_label}.html")
一旦上述代码运行,我们将在给定文件路径中得到一个 HTML 格式的图表。你可以在任何浏览器中打开它。
对于“口渴的乌鸦”的故事,知识图谱看起来像这样:
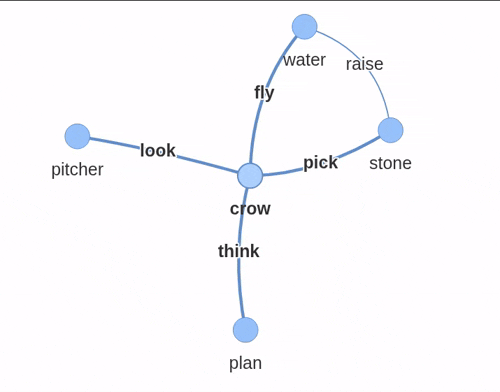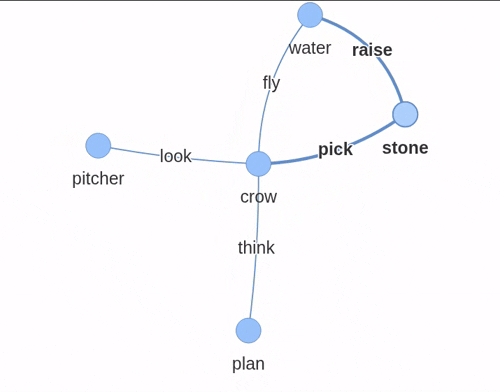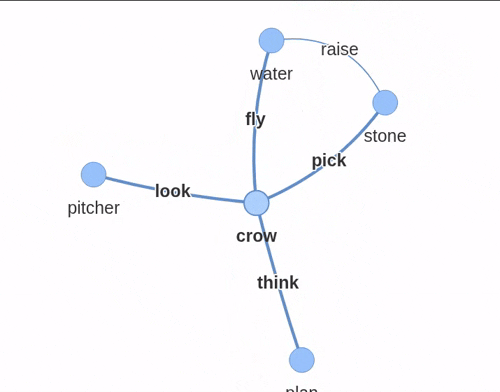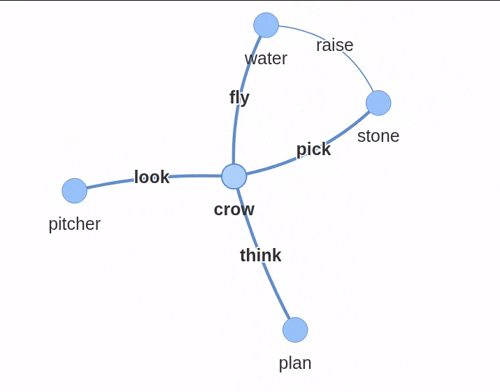
使用 pyvis 构建的交互式知识图谱
4 结论
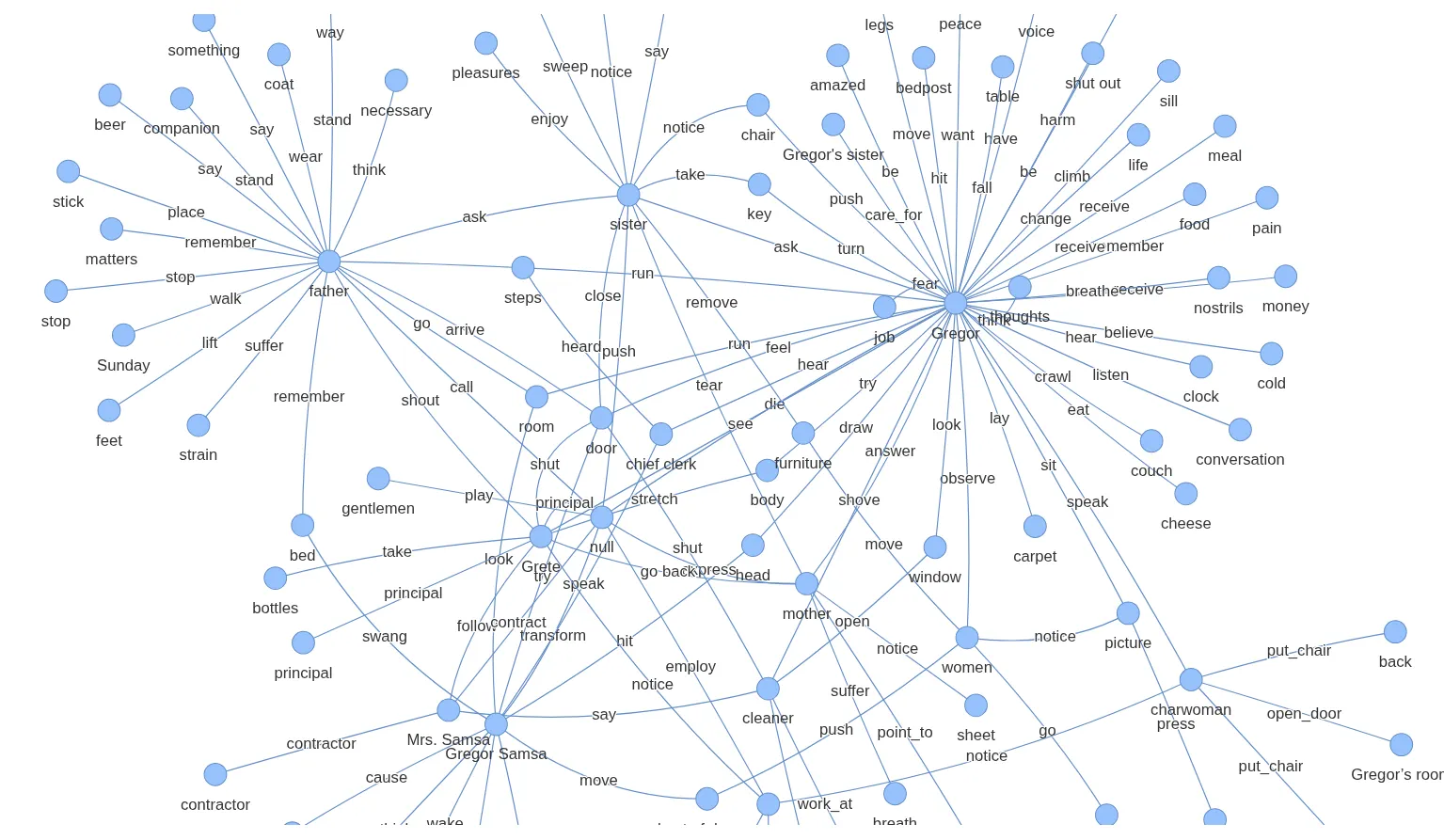
看到即使是较小的 LLM 也能够在本地理解和解决复杂的任务,这无疑是令人兴奋和充满希望的。虽然它对于较小和简单的文本效果很好,但我注意到对于较大的文本存在一些局限性。我曾尝试将其应用于更大、更复杂的文本——《变形记》一书。虽然模型仍然能够令人印象深刻地映射关系(知识图谱是这篇博客的标题图片),但还需要更多的工作来改进提示,使其更健壮,但这与文本预处理有关。我还发现 gemma3–4b 模型在遵循更长或更复杂的系统提示方面存在一些局限性。因此,这种方法肯定会从更大的 LLM 中受益。
总的来说,使用较小的 LLM 构建知识图谱似乎很有前景。也许我会尝试使用构建的知识图谱进行问答,看看它的表现如何。请在评论中告诉我你的想法。