Hash桶的讲解
时隔几月,终于有空继续来分析学习编程时的笔记过程了。
接上次更新上一篇讲完hash表的模拟后,本次,我们接着来继续对hash桶的认识!
前言:
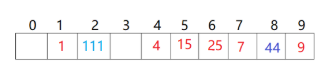
上一篇我们用到的开放定址法:有个缺点,就是冲突会相互影响,如下图,4,5,6,7位置映射的值都会相互影响。
哈希桶是什么?
所以,我们现在有另一种方法:拉链法/哈希桶。
(教材中把它叫做开散列法。)
开散列法又叫链地址法(开链法),首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。
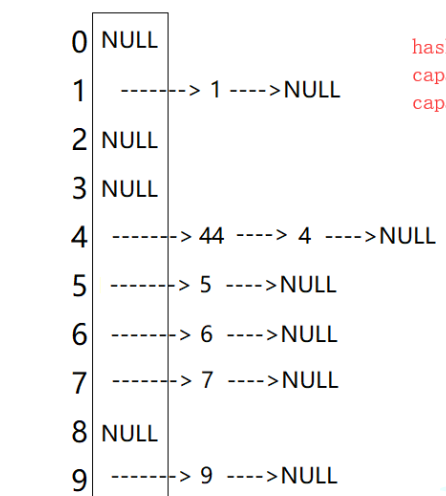
什么叫哈希桶呢?单看概念有点晦涩难懂,那我们就用图片来帮助理解:
优势:由图可以看出来开散列中每个桶中放的都是发生哈希冲突的元素

那么,下面我们直接通过模拟实现来进一步理解哈希桶的细节。
注意:我们主要目的是对于哈希桶的进一步理解。我们这里主要实现的是哈希桶的增删查改这几个常见的接口。
搭建框架
namespace hash_bucket
{template<class T>struct HashNode{T _data;HashNode<T>* _next;HashNode(const T& data):_data(data),_next(nullptr){}};template<class K, class T>class HashTable{typedef HashNode<T> Node;public:private:vector<Node*> _table; // 指针数组size_t _n = 0; // 存储了多少个有效数据}
}这里,我们需要自己创建结点,创建单链表。
对于变量名vector<Node*>,有人可能会问了:为啥不用vector<list>?没必要,我们直到list属于任意位置插入,每个结点多了prev,多了头哨兵位结点,此时用list的话就没那么好实现后续的迭代器了。
构造函数
HashTable(){_table.resize(10, nullptr);}析构函数
~HashTable(){for (size_t i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next;delete cur;cur = next;}_table[i] = nullptr;}}定位到该位置,利用循环进行对链表结点的逐一释放。
插入部分
(有坑,后面改)
bool Insert(const T& data){if(Find(data)){return false;}// 负载因子到1就扩容if (_n == _table.size()){size_t newSize = _table.size()*2;vector<Node*> newTable;newTable.resize(newSize, nullptr);// 遍历旧表,顺手牵羊,把节点牵下来挂到新表for (size_t i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next;// 头插到新表size_t hashi = cur->_data % newSize;cur->_next = newTable[hashi];newTable[hashi] = cur;cur = next;}_table[i] = nullptr;}_table.swap(newTable);}size_t hashi = data % _table.size();// 头插Node* newnode = new Node(data);newnode->_next = _table[hashi];_table[hashi] = newnode;++_n;return true;我们先来个图分析分析:
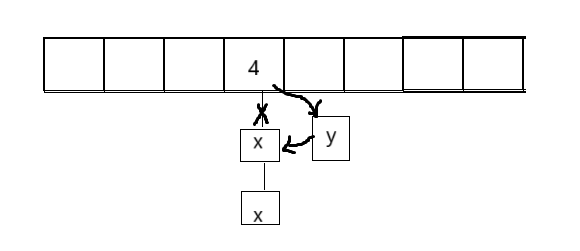
我们插入过程是这样的:
newnode->next=table[hashi];
table[hashi]=newnode;我们位置存的是指针(第一个结点的指针),链表连的是把你的地址给给我。
1.首先,我们先思考一个问题:哈希桶插入时要不要扩容呢?
答案是要的。插入数据越多,不扩容的话,某些桶会越来越长,那么效率得不到保证。
而且,我们的负载因子适当放大一些,一般负载因子控制在1,平均下来,每一个桶一个数据(理想状态下)。
而我们的扩容起到了冲突分散的作用。eg:原来冲突的->不冲突。(虽然也有不冲突的->冲突)但至少概率上分散了(100个位置->200个位置)。
2.开放定址法的做法:(如下)
那么,哈希桶这里,也像开放定址法一样复用insert好不好?
答案是不好;insert进来肯定不会扩容,因为空间之间已经开好的。关键是它会再次去newnode。
eg:首先遇到1,去新开一个结点,下一个111,它会到11位置去新开一个结点的。
新开结点后,你要把旧表释放,把一个个结点释放,相当于扩容逻辑中,把结点新开一遍(浪费了资源,你insert的是值。),旧结点释放一遍。而先在有了结点,我们不妨使用另一种方法
之前为什么需要复用?如果不用的话,你就要把探测的逻辑重新写一遍(因为,它并不存在挂结点问题)。
那么,我们这里定义一个newtable,在resize,此时,由于存在挂结点了,那么这时候我们就可以做到遍历旧表即可顺手牵羊的把结点牵下来,挂到新表了。
vector<Node*> newTable;newTable.resize(newSize, nullptr);
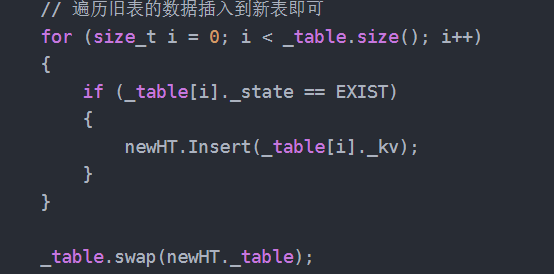

3.另外,我们需要保存起来下一个(方便头插),不然就找不到了。
// 头插 Node* newnode = new Node(data); newnode->_next = _table[hashi]; _table[hashi] = newnode;此外,针对哈希表遇到扩容就会变慢,这个我们在开放定址法也说过了,没有大方法解决它,但总体上问题不大。
4.vector会不会释放结点?(链表)(vector<Node*> newTable;)
答案是不会的,你swap交换后,由于你之前new table,要调用析构函数释放,但并不会去释放结点,因为选取调用delete[],但这个表上每个对象是什么类型?
内置类型(指针),所以它没有默认的析构函数,需要单独去写析构函数(这也是为什么上面我们有写析构函数的原因。)
ps:若忘了什么时候有默认的析构函数的情况,可以去下面文章复习复习噢。
C++——类与对象2-CSDN博客
_table.swap(newTable);
下一步,我们来讲解一下关于封装unordered_map与unordered_set的细节问题:
我们改用HashNode<T>来确认是K还是<K,V>:
unordered_set:是K
unordered_map:<K,V>
但是,到后面你会发现,set中是<K,K>?那么,我们来思考思考,明明我们并没有需要用到后面的value,那么我们为什么还要保留下来,并设置为<K,K>?
(为什么set不需要用,map又需要用到?)
这个我们之前也讲到过,在find这个函数接口中,map可不能只用T。
因此,为了更好结合这两个一起封装,我们将set弄成<K,K>
这种方法叫做:泛型:针对的是广泛(两种以上)的类型,代码不是针对某种具体的类型。
而模板是实现泛型的一种方式。
提取K与KV
那么问题又来了,我们既然采用这种方式,那怎么样将K,KV都同时跑起来呢?
这儿我们采用:提取出来。
取KofT模板,把T里面的K取出来(利用仿函数),它不是针对(K,K)(K,V)来写的。
unordered_set部分
namespace bai //防止与库里面的unordered_set冲突 {template<class K>class unordered_set{struct SetKeyOfT //提取K,采用仿函数策略{const K& operator()(const K& key){return key;}};public:private:hash_bucket::HashTable<K, K, SetKeyOfT> _ht;}; }unordered_map部分
namespace bai {template<class K, class V>class unordered_map{struct MapKeyOfT{const K& operator()(const pair<K, V>& kv){return kv.first;}};public:private:hash_bucket::HashTable<K, pair<K, V>, MapKeyOfT> _ht;}; }
好,下一步,我们继续回到哈希桶的函数:
我们会发现,我们的insert函数需要针对这两种进行区分,不同情况不同提取,所以我们需要另外写一个模板(提取方法,即我们在unordered_set,unordered_map中写的,参杂进去),除了这个之外,我们在上一篇也讲到过,我们data的类型不仅仅是整形,它也可能是浮点型,字符串.....因此像开放定址法那样引入类模板。
类模板
template<class K, class T, class KeyOfT, class HashFunc = DefaultHashFunc<K>>template<class K>
struct DefaultHashFunc
{size_t operator()(const K& key){return (size_t)key;}
};//模板特例化,针对string
template<>
struct DefaultHashFunc<string>
{size_t operator()(const string& str){// BKDRsize_t hash = 0;for (auto ch : str){hash *= 131;hash += ch;}return hash;}
};改进insert部分(一)
bool Insert(const T& data){KeyOfT kot;if(Find(kot(data))){return false;}HashFunc hf;// 负载因子到1就扩容if (_n == _table.size()){size_t newSize = _table.size()*2;vector<Node*> newTable;newTable.resize(newSize, nullptr);// 遍历旧表,顺手牵羊,把节点牵下来挂到新表for (size_t i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next;// 头插到新表size_t hashi = hf(kot(cur->_data)) % newSize;cur->_next = newTable[hashi];newTable[hashi] = cur;cur = next;}_table[i] = nullptr;}_table.swap(newTable);}size_t hashi = hf(kot(data)) % _table.size();// 头插Node* newnode = new Node(data);newnode->_next = _table[hashi];_table[hashi] = newnode;++_n;return true;}Find部分
Node* Find(const K& key){HashFunc hf;KeyOfT kot;size_t hashi = hf(key) % _table.size();Node* cur = _table[hashi];while (cur){if (kot(cur->_data) == key){return cur;}cur = cur->_next;}return nullptr;}代码逻辑简单,就不讲解了。
Erase部分
bool Erase(const K& key){HashFunc hf;KeyOfT kot;size_t hashi = hf(key) % _table.size();Node* prev = nullptr;Node* cur = _table[hashi];while (cur){if (kot(cur->_data) == key){//如果prev为空,说明删除结点就在第一个位置if (prev == nullptr){_table[hashi] = cur->_next;}else{prev->_next = cur->_next;}--_n;delete cur; return true;}prev = cur;cur = cur->_next;}return false;}如果不理解,可以画一下图辅助一下
迭代器部分
接下来,我们就开始写begin,end接口,所以需要用到迭代器。我们先来完成迭代器。
搭建框架
// 前置声明template<class K, class T, class KeyOfT, class HashFunc>class HashTable;template<class K, class T, class KeyOfT, class HashFunc>struct HTIterator{Node* _node;HashTable<K, T, KeyOfT, HashFunc>* _pht;HTIterator(Node* node, HashTable<K, T, KeyOfT, HashFunc>* pht):_node(node),_pht(pht){}};1.我们的迭代器需要用到HashTable,所以需要进行前置声明,否则会报错。
ps:前置声明:告诉编译器已经声明了,相当于打招呼。
2.另外,你仔细观察一下,这是迭代器部分与HashTable部分两者进行了相互使用:
即:哈希表使用迭代器,迭代器使用哈希表。
那么,迭代器为什么需要用到HashTable呢?迭代器需要持有执行哈希表的指针,另外增强了代码的复用性:后续对哈希表的底层进行优化,重要哈希表提供的接口不变,迭代器大概率可以继续使用,减少了代码的重复开发。
operator*
operator&
operator!=
T& operator*(){return _node->_data;}T* operator->(){return &_node->_data;}bool operator!=(const Self& s){return _node != s._node;}
operator++
Self& operator++(){if (_node->_next){// 当前桶还没完_node = _node->_next;}else{KeyOfT kot;HashFunc hf;size_t hashi = hf(kot(_node->_data)) % _pht->_table.size();// 从下一个位置查找查找下一个不为空的桶++hashi;while (hashi < _pht->_table.size()){if (_pht->_table[hashi]){_node = _pht->_table[hashi];return *this;}else{++hashi;}}_node = nullptr;}return *this;}逻辑:算自己是几号桶,除了知道下标,还要知道哈希表对象,找到下标,先++,进入循环,遇到不为空,跳出循环,说明找到了,反正++hash,走到结尾都找不到下一个桶
总结:这个前置 ++ 操作的目的是:让迭代器从当前位置,移动到哈希表中的“下一个有效元素”(优先在当前桶内找后续节点;桶内找完,就找数组中后续的非空桶)。当所有元素遍历完,迭代器会被置为 nullptr ,表示遍历结束。
注意:在写迭代器时,会有报错:
这里需要用到模板友元(简单理解-->):我想访问你的私有,所以让我成为你的朋友。
再写模板友元的时候,要把模板参数带上,让迭代器成为哈希表的朋友
template<class K, class T>class HashTable{typedef HashNode<T> Node;// 友元声明template<class K, class T, class KeyOfT, class HashFunc>friend struct HTIterator;public://让后续写begin,end更简洁typedef HTIterator<K, T, KeyOfT, HashFunc> iterator;.....................private:vector<Node*> _table; // 指针数组size_t _n = 0; // 存储了多少个有效数据}好了,完了迭代器部分,我们正式进入begin,end的接口编写:
begin
iterator begin(){// 找第一个桶for (size_t i = 0; i < _table.size(); i++){Node* cur = _table[i];if (cur){return iterator(cur, this);}}return iterator(nullptr, this);}复习this指针概念:
1. this 指针的基本概念
当一个对象调用其成员函数时,编译器会自动将该对象的地址作为 this 指针传递给成员函数。在成员函数内部,可以通过 this 指针来访问当前对象的成员(包括成员变量和成员函数)。
2. 在 HashTable 的 begin 函数中在 HashTable 类的 begin 函数里,有return iterator(cur, this); 这里的 this 指向当前调用 begin 函数的 HashTable 对象。
- 通过将 this (当前哈希表对象的地址)传递给迭代器的构造函数,迭代器就持有了指向该哈希表对象的指针(迭代器的 _pht 成员),从而可以在迭代器的操作中,基于这个指针访问对应的哈希表的结构和数据。
****this指针可以关联到具体的哈希表对象。*****
end
iterator end(){return iterator(nullptr, this);}
写完哈希表接口后,我们继续回去到unordered_set,unordered_map封装那里。
unordered_set部分
namespace bai //防止与库里面的unordered_set冲突 {template<class K>class unordered_set{struct SetKeyOfT //提取K,采用仿函数策略{const K& operator()(const K& key){return key;}};public:typedef typename hash_bucket::HashTable<K, K, SetKeyOfT>::const_iterator iterator;typedef typename hash_bucket::HashTable<K, K, SetKeyOfT>::const_iterator const_iterator;const_iterator begin() const{return _ht.begin();}const_iterator end() const{return _ht.end();}private:hash_bucket::HashTable<K, K, SetKeyOfT> _ht;}; }1.问题:这里迭代器能不能只定义const_iterator?
不能,平时用的还是iterator,只是它的底层是const而已。
2.要取类模板里面的内嵌类型,不能区分静态变量还是类型,所以要加上typename,这个在后面在封装时对迭代器的部分有体现到。
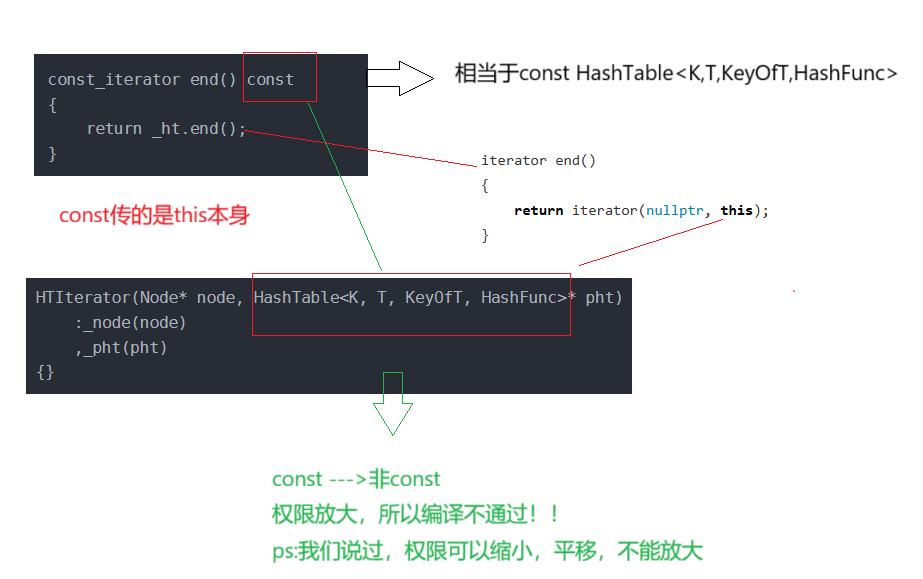
3.此时如果你这样写的话,编译器会编译不过,为什么呢?
那之前为啥没遇到过?以前的迭代器要不要传哈希表过去?
eg:红黑树不需要传呀,它只要传结点的指针过去就可。
那么我们该怎么改?
1.把vector传过去可以吗?不可以,因为const修饰*this,指向的内容也会有问题。
2.重载一个?不可以,这只顾了一边,实参可传形参,形参初始化成员?所以不可以的
3.所以我们的做法是:不如把成员改成const,迭代器里不会修改哈希表的内容,而是通过node修改的,类模板只要给不同的模板参数,就是不同类型。
原:HTIterator(Node* node, HashTable<K, T, KeyOfT, HashFunc>* pht):_node(node), _pht(pht){} 改:HTIterator(Node* node, const HashTable<K, T, KeyOfT, HashFunc>* pht):_node(node), _pht(pht){}
unordered_map部分
namespace bit {template<class K, class V>class unordered_map{public:typedef typename hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT>::iterator iterator;typedef typename hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT>::const_iterator const_iterator;iterator begin(){return _ht.begin();}iterator end(){return _ht.end();}const_iterator begin() const{return _ht.begin();}const_iterator end() const{return _ht.end();}private:hash_bucket::HashTable<K, pair<const K, V>, MapKeyOfT> _ht;}; }跟上面的unordered_set差不多.
封装insert部分
我们这里结合起来讲解:
bool insert(const pair<K, V>& kv){return _ht.Insert(kv);}可能一开始会这么写,但是现在我们引入了迭代器了,随机我们的返回值也需要随之改变
变成:
unordered_set:pair<const_iterator,bool>unordered_map:pair<iterator,bool>pair是两个不同的模板参数,是不同的类型,自定义类型,
注意:这里没有缩小概念,只要指针与引用才有这概念。
类模板给不同的模板参数,就是不同类型,如果不在同一个类,会存在私有问题。
但是,当你写了这步骤后,你又会发现,编译不过去?此时该怎么办呢?
在迭代器那里写一个构造函数
// 普通迭代器时,他是拷贝构造// const迭代器时,他是构造HTIterator(const Iterator& it):_node(it._node), _pht(it._pht){}本来,迭代器是不需要写拷贝构造的,因为它是浅拷贝,就是那个结点的指针拷贝
而现在写了后,当它充当是普通迭代器时,这个函数就是拷贝构造,充当const迭代器时,const_iterator这个函数是构造,支持普通迭代器转化成const迭代器的构造。
此时,unordered_map的insert部分
pair<iterator, bool> insert(const pair<K, V>& kv){return _ht.Insert(kv);}
unordered_set部分
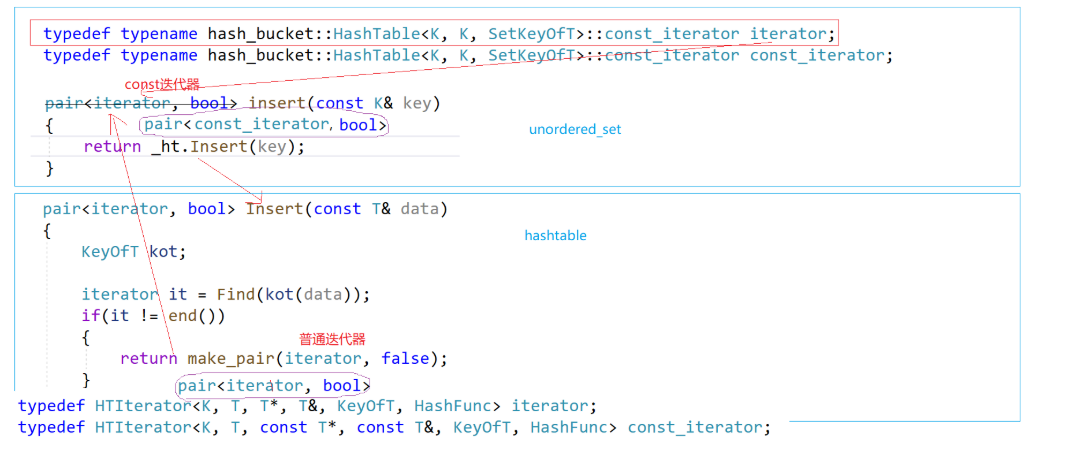
pair<const_iterator, bool> insert(const K& key) {//return _ht.Insert(key);<typename hash_bucket::HashTable<K, K, SetKeyOfT>::iterator, bool> ret = _ht.Insert(key);return pair<const_iterator, bool>(ret.first, ret.second); }大家可能会发现unordered_set的return没有直接//return _ht.Insert(key);
因为如果那么做的话,它会有不确定性,有可能编译通过,有可能编译不过。
而大家可能会有疑惑,为什么之前在实现Myset.h的时候可以直接//return _ht.Insert(key)?
因为:相当于把这两个参数提取出来,当独立去调pair的构造,ret.first是普通迭代器,在pair的初始化列表,对自定义类型要调谁---直接调构造
unordered_map实现operator[]重载
这也是为什么insert我们要return pair的原因之一。
V& operator[](const K& key) {pair<iterator, bool> ret = _ht.Insert(make_pair(key, V()));return ret.first->second; }自行去HashTable改返回值
pair<iterator, bool> Insert(const T& data)改进insert部分(二)
pair<iterator, bool> Insert(const T& data){KeyOfT kot;iterator it = Find(kot(data));if(it != end()){return make_pair(it, false);}HashFunc hf;// 负载因子到1就扩容if (_n == _table.size()){//size_t newSize = _table.size() * 2;size_t newSize = GetNextPrime(_table.size());vector<Node*> newTable;newTable.resize(newSize, nullptr);// 遍历旧表,顺手牵羊,把节点牵下来挂到新表for (size_t i = 0; i < _table.size(); i++){Node* cur = _table[i];while (cur){Node* next = cur->_next;// 头插到新表size_t hashi = hf(kot(cur->_data)) % newSize;cur->_next = newTable[hashi];newTable[hashi] = cur;cur = next;}_table[i] = nullptr;}_table.swap(newTable);}size_t hashi = hf(kot(data)) % _table.size();// 头插Node* newnode = new Node(data);newnode->_next = _table[hashi];_table[hashi] = newnode;++_n;//分析1:return make_pair(iterator(newnode, this), true);}分析1.如果按照之前的情况,就发送错误了,原因如下
所以我们还需要传它是const迭代器还是普通迭代器?
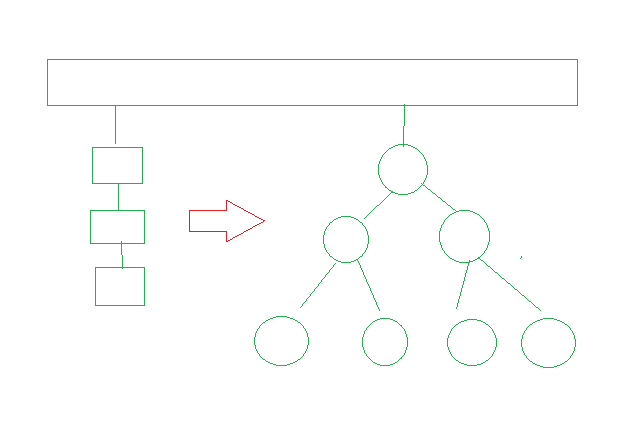
优化:链表与树的转化
有方法将链表转化为树的效率:
伪代码:
insert hash (哈希方式插入)和 insert tree (树方式插入)分开,当单个桶里元素过多(比如达到1000个),会考虑从链表转换为树(比如红黑树)来优化查找效率(因为树的查找时间复杂度是 O(\log n),优于链表的 O(n))。
如果树要遍历链表,是不是要改变结构?
不需要。可以遍历链表,把链表元素全部插入到新建的树中,根,左子树,右子树,然后原来DELETE的结点给root,(将树的根节点赋值给对应的存储位置)(比如通过 root 指针),这样就完成了从链表到树的转换,同时不影响整体结构的逻辑一致性。
总结:哈希表处理冲突时,链表与树两种存储结构的配合与动态转换,以平衡空间和时间效率。

除留余数法:
减少hash冲突的概率---数据结构--(大概了解)
*****************“字符串的hash算法”*****************************
size_t GetNextPrime(size_t prime){static const int __stl_num_primes = 28;static const unsigned long __stl_prime_list[__stl_num_primes] ={53, 97, 193, 389, 769,1543, 3079, 6151, 12289, 24593,49157, 98317, 196613, 393241, 786433,1572869, 3145739, 6291469, 12582917, 25165843,50331653, 100663319, 201326611, 402653189, 805306457,1610612741, 3221225473, 4294967291};size_t i = 0;for (; i < PRIMECOUNT; ++i){if (primeList[i] > prime)return primeList[i];}return primeList[i];}
好了,终于对于哈希桶的简单分享完成了,希望大家都有所收获!!!
最后,来到了本次鸡汤环节:
想全是问题,做全是答案!
