Java ConcurrentHashMap 底层原理与线程安全机制深度解析
ConcurrentHashMap 是 Java 并发包(java.util.concurrent)中核心的线程安全哈希表实现,专为高并发场景设计。它既解决了 HashMap 的线程不安全问题,又克服了 Hashtable 全表加锁导致的性能瓶颈,实现了 “高效并发” 与 “数据安全” 的平衡。本文将从版本演进、核心结构、线程安全机制、关键方法及使用场景等维度,全面剖析 ConcurrentHashMap 的底层逻辑。
目录
一、版本演进:JDK 7 到 JDK 8 的核心优化
1.1 JDK 7:分段锁(Segment)机制
1.2 JDK 8:CAS + synchronized 细粒度锁
二、JDK 8 核心结构与线程安全机制
2.1 核心结构:数组 + 链表 / 红黑树
2.2 线程安全核心:CAS + synchronized
2.2.1 CAS 无锁操作:解决 “初始化” 与 “计数” 的并发问题
2.2.2 synchronized 局部锁:解决 “节点修改” 的并发问题
2.3 关键变量:sizeCtl 与 size 计数
2.3.1 sizeCtl:状态控制核心变量
2.3.2 size 计数:并发环境下的精确计数
三、核心方法解析:put 与扩容的并发逻辑
3.1 put 方法:线程安全的插入 / 更新流程
3.2 扩容机制:并发扩容(多线程协助扩容)
四、与 HashMap、Hashtable 的核心差异
五、使用场景与注意事项
5.1 适用场景
5.2 注意事项
总结
一、版本演进:JDK 7 到 JDK 8 的核心优化
ConcurrentHashMap 的设计在 JDK 7 和 JDK 8 中有显著差异,核心目标均为 “减少锁粒度,提升并发效率”,但实现方式截然不同。
1.1 JDK 7:分段锁(Segment)机制
JDK 7 中,ConcurrentHashMap 采用 “数组 + Segment + 链表” 的三层结构,核心是 分段锁 设计:
- Segment(分段锁):本质是一个可重入锁(ReentrantLock),每个 Segment 对应一个 “子哈希表”,存储部分 Key-Value 对;
- 底层数组:数组元素是 Segment 对象,默认数组长度为 16(即默认 16 个分段锁),可通过构造函数指定;
- 链表:每个 Segment 内部包含一个哈希表数组,数组元素是链表节点,用于解决哈希冲突。
线程安全逻辑:当线程操作 ConcurrentHashMap 时,仅需获取对应 Segment 的锁,而非全表锁。例如,线程 1 操作 Segment 0 中的数据,线程 2 操作 Segment 1 中的数据,二者可并行执行,仅当多个线程操作同一 Segment 时才需互斥。这种 “分段加锁” 机制将锁粒度从 “全表” 缩小到 “Segment”,极大提升了并发效率。
局限性:
- 锁粒度仍不够细:同一 Segment 内的并发操作仍需排队,当某一 Segment 数据量过大时,会成为并发瓶颈;
- 结构复杂:三层结构(数组→Segment→数组→链表)增加了数据存储与查询的开销;
- 扩容效率低:Segment 是独立的哈希表,扩容仅针对单个 Segment,但若多个 Segment 同时扩容,会占用更多资源。
1.2 JDK 8:CAS + synchronized 细粒度锁
JDK 8 彻底重构了 ConcurrentHashMap 的结构,摒弃了 Segment 分段锁,采用 “数组 + 链表 / 红黑树” 的两层结构(与 HashMap 结构相似),并通过 CAS 无锁操作 + synchronized 局部锁 实现线程安全,核心优化如下:
- 结构简化:移除 Segment,直接使用 “哈希桶数组” 存储数据,数组元素是链表节点或红黑树节点;
- 锁粒度细化:从 “Segment 级锁” 缩小到 “节点级锁”—— 仅对哈希桶中 “待操作的节点” 加锁,而非整个哈希桶;
- 无锁优化:对 “空节点的初始化”“计数更新” 等场景,采用 CAS 无锁操作,进一步减少锁竞争;
- 红黑树优化:当链表长度超过阈值(默认 8)且数组容量 ≥ 64 时,链表转为红黑树,提升查询效率(与 HashMap 逻辑一致)。
JDK 8 的设计既保留了 HashMap 的高效查询特性,又通过更细粒度的锁机制和无锁操作,将并发效率提升到新高度,成为目前高并发场景的首选哈希表实现。
二、JDK 8 核心结构与线程安全机制
JDK 8 是目前主流版本,以下重点解析其核心设计:
2.1 核心结构:数组 + 链表 / 红黑树
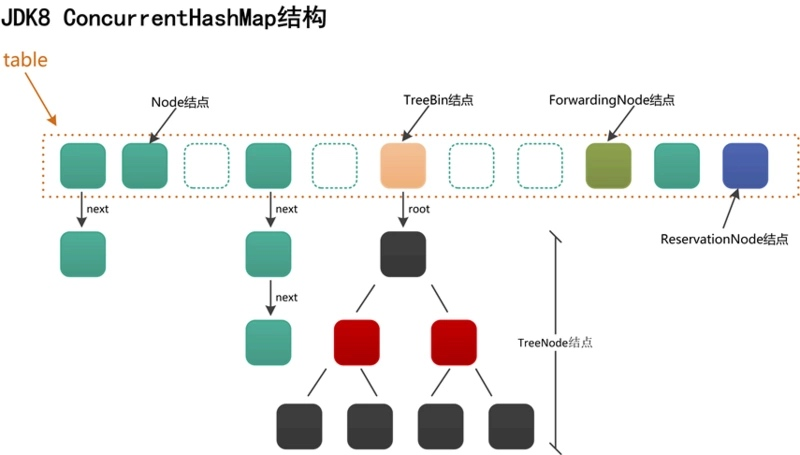
- 哈希桶数组(table):核心存储容器,数组元素是 Node 节点(链表节点)或 TreeNode 节点(红黑树节点);
- Node 节点:存储 Key-Value 对的基础节点,key 和 value 均为 final 修饰(保证不可变),next 指针通过 volatile 修饰(保证可见性),定义如下:
static class Node<K,V> implements Map.Entry<K,V> {final int hash;final K key;volatile V val;volatile Node<K,V> next;// 构造函数与方法省略}- TreeNode 节点:红黑树节点,继承自 Node,额外包含红黑树的结构信息(如 parent、left、right 指针,color 颜色标记),用于解决链表过长导致的查询效率问题。
2.2 线程安全核心:CAS + synchronized
JDK 8 中,ConcurrentHashMap 通过 “CAS 无锁操作” 和 “synchronized 局部锁” 结合,实现不同场景下的线程安全,具体逻辑如下:
2.2.1 CAS 无锁操作:解决 “初始化” 与 “计数” 的并发问题
CAS(Compare and Swap,比较并交换)是一种乐观锁机制,无需加锁即可实现并发安全,适用于 “冲突概率低” 的场景,ConcurrentHashMap 主要在以下场景使用 CAS:
- 哈希桶数组初始化:当 table 未初始化时,多个线程可能同时触发初始化,通过 CAS 确保仅一个线程能完成初始化:
// 简化逻辑:通过 CAS 尝试将 table 从 null 设为新数组if (table == null) {Node<K,V>[] tab = new Node[initialCapacity];if (CAS(table, null, tab)) {// 初始化成功}}- 空节点插入:当哈希桶为空(table [index] == null)时,线程通过 CAS 尝试将新节点插入,避免加锁开销:
// 简化逻辑:CAS 尝试将 table[index] 从 null 设为新节点if (table[index] == null && CAS(table, index, null, new Node(hash, key, value))) {// 插入成功,无需加锁break;}- 计数更新(sizeCtl):sizeCtl 是控制 ConcurrentHashMap 状态的核心变量(如初始化、扩容、容量阈值),通过 CAS 更新 sizeCtl,确保状态修改的原子性。
2.2.2 synchronized 局部锁:解决 “节点修改” 的并发问题
当哈希桶已存在节点(table [index] != null)时,需对 “待操作的节点” 加 synchronized 锁,避免多线程同时修改同一节点或链表 / 红黑树结构,主要场景包括:
- 链表节点插入 / 更新:若 table [index] 是链表节点,线程会对该节点加锁,再遍历链表查找 Key:
-
- 若找到相同 Key,更新 Value;
-
- 若未找到,在链表尾部插入新节点;
-
- 插入后判断链表长度是否超阈值,若超则转为红黑树。
- 红黑树节点插入 / 更新:若 table [index] 是红黑树节点,线程会对该节点加锁,再通过红黑树的插入 / 更新逻辑处理数据,确保红黑树结构的完整性。
锁粒度优势:synchronized 仅锁定 “当前哈希桶的节点”,而非整个数组或哈希桶。例如,线程 1 操作 index=0 的节点,线程 2 操作 index=1 的节点,二者可并行执行;即使同一哈希桶内有多个节点,也仅锁定 “待操作节点”,其他节点的操作仍可并发,极大降低了锁竞争。
2.3 关键变量:sizeCtl 与 size 计数
2.3.1 sizeCtl:状态控制核心变量
sizeCtl 是一个 volatile 修饰的 int 变量,用于控制 ConcurrentHashMap 的初始化、扩容及容量阈值,不同取值代表不同状态:
- sizeCtl < 0:表示当前有特殊操作正在进行:
-
- sizeCtl = -1:正在初始化;
-
- sizeCtl = -(1 + 扩容线程数):正在扩容(如 sizeCtl = -2 表示 1 个线程正在扩容);
- sizeCtl = 0:默认状态,未初始化;
- sizeCtl > 0:未初始化时表示 “初始容量”,初始化后表示 “下次扩容的阈值”(类似 HashMap 的 loadFactor × 容量)。
2.3.2 size 计数:并发环境下的精确计数
ConcurrentHashMap 的 size(元素总数)是通过 CounterCell 数组 实现的,而非单一变量:
- 当线程更新 size 时,会通过 CAS 尝试更新某一个 CounterCell 的值;
- 若 CAS 失败(如多个线程同时更新同一 CounterCell),则创建新的 CounterCell 或重试;
- 读取 size 时,遍历所有 CounterCell,累加其值得到总 size。
这种 “分段计数” 机制避免了单一变量的 CAS 竞争,确保高并发场景下 size 计数的效率与准确性。
三、核心方法解析:put 与扩容的并发逻辑
3.1 put 方法:线程安全的插入 / 更新流程
JDK 8 中,ConcurrentHashMap 的 put(K key, V value) 方法是线程安全的核心体现,流程如下:
- 参数校验:若 Key 或 Value 为 null,直接抛出 NullPointerException(区别于 HashMap,HashMap 允许 Key/Value 为 null);
- 哈希计算:调用 spread(int hash) 方法计算 Key 的哈希值(类似 HashMap 的扰动处理,但增加了 “与 INT_MAX 按位与” 步骤,确保哈希值为正数):
static final int spread(int h) {return (h ^ (h >>> 16)) & Integer.MAX_VALUE;}- 循环尝试插入:遍历哈希桶数组,通过 CAS 或 synchronized 实现线程安全插入:
-
- 若 table 未初始化,调用 initTable() 方法,通过 CAS 确保仅一个线程初始化 table;
-
- 计算哈希桶下标 index,若 table [index] == null,通过 CAS 尝试插入新 Node 节点,插入成功则跳出循环;
-
- 若 table [index] 不为 null,判断当前是否处于扩容中(通过 sizeCtl < 0 判断),若是则协助扩容(见 3.2 节);
-
- 若不处于扩容中,对 table [index] 加 synchronized 锁,根据节点类型(链表 / 红黑树)执行插入 / 更新:
-
-
- 链表:遍历链表,存在相同 Key 则更新 Value,否则插入尾部,插入后判断是否转红黑树;
-
-
-
- 红黑树:调用红黑树的插入方法,更新或插入节点;
-
- 更新 size:插入 / 更新成功后,调用 addCount() 方法,通过 CounterCell 数组更新 size,并判断是否需要触发扩容;
- 返回结果:若插入新节点,返回 null;若更新现有节点,返回旧 Value。
3.2 扩容机制:并发扩容(多线程协助扩容)
ConcurrentHashMap 的扩容是 多线程协作 完成的,避免了单线程扩容的效率瓶颈,核心流程如下:
- 触发扩容:当 addCount() 方法检测到 size 超过 sizeCtl(扩容阈值)时,当前线程尝试触发扩容;
- 初始化扩容状态:通过 CAS 将 sizeCtl 从 “扩容阈值” 更新为 “-2”(表示 1 个线程正在扩容),若 CAS 成功,当前线程成为 “扩容主导线程”;
- 划分扩容任务:扩容主导线程将旧数组(oldTab)划分为多个 “任务段”,每个线程负责一个任务段的节点迁移(从 oldTab 迁移到新数组 newTab);
- 多线程协助扩容:其他线程执行 put/remove 等操作时,若检测到当前处于扩容中(sizeCtl < 0),会自动协助迁移未处理的任务段,直到扩容完成;
- 扩容完成:所有任务段迁移完成后,将 newTab 赋值给 table,更新 sizeCtl 为 “新的扩容阈值”(newCap × 负载因子),扩容结束。
并发扩容优势:多线程协作迁移数据,大幅缩短扩容时间,避免单线程扩容导致的并发阻塞。
四、与 HashMap、Hashtable 的核心差异
为更清晰理解 ConcurrentHashMap 的定位,下表对比三者的核心特性:
| 特性 | ConcurrentHashMap(JDK 8) | HashMap | Hashtable |
| 线程安全 | 是(CAS + synchronized) | 否 | 是(全表 synchronized) |
| 锁粒度 | 节点级锁 | 无锁 | 全表锁 |
| Key/Value 允许为 null | 否(抛 NPE) | 是(Key 仅一个 null) | 否(抛 NPE) |
| 数据结构(JDK 8) | 数组 + 链表 / 红黑树 | 数组 + 链表 / 红黑树 | 数组 + 链表 |
| 扩容机制 | 多线程协助扩容 | 单线程扩容 | 单线程扩容 |
| 并发性能 | 高(支持高并发读写) | 无并发安全性 | 低(全表锁阻塞) |
五、使用场景与注意事项
5.1 适用场景
ConcurrentHashMap 是高并发场景下的首选哈希表,典型场景包括:
- 多线程读写共享数据:如分布式系统中的本地缓存、秒杀系统中的库存计数;
- 高并发查询与更新:如电商平台的商品信息存储、用户会话管理;
- 替代 Hashtable 与 synchronizedMap:当需要线程安全且追求高并发性能时,避免使用效率低下的 Hashtable 或 Collections.synchronizedMap(new HashMap<>())。
5.2 注意事项
- 不支持原子性的 “复合操作”:ConcurrentHashMap 仅保证单个方法(如 put、remove)的线程安全,不保证 “先查后改” 等复合操作的原子性。例如:
// 非原子操作,可能存在并发问题if (map.containsKey(key)) {map.put(key, map.get(key) + 1);}解决方案:使用 computeIfPresent() 等原子方法:
// 原子操作,确保线程安全map.computeIfPresent(key, (k, v) -> v + 1);- 迭代器弱一致性:ConcurrentHashMap 的迭代器是 “弱一致性” 的,即迭代过程中允许其他线程修改数据,但迭代器不会抛出 ConcurrentModificationException,也不会实时反映最新数据(仅反映迭代开始时的快照);
- 避免频繁扩容:初始化时建议指定合理容量(如预计存储 1000 个元素,可设初始容量为 1000),减少扩容次数,提升性能;
- Key 需重写 hashCode () 与 equals ():与 HashMap 一致,若 Key 是自定义对象,需重写这两个方法,避免哈希冲突加剧或 Key 无法匹配。
总结
ConcurrentHashMap 是 Java 并发编程中的核心组件,其 JDK 8 版本通过 “CAS 无锁操作 + synchronized 局部锁” 的创新设计,实现了 “细粒度锁” 与 “高效并发” 的平衡,解决了 HashMap 线程不安全和 Hashtable 性能低下的问题。理解其底层结构、线程安全机制及扩容逻辑,不仅能帮助开发者在高并发场景下正确使用 ConcurrentHashMap,还能为设计并发数据结构提供思路。在实际开发中,需结合业务的并发量与数据特性,合理配置初始容量,避免复合操作的并发风险,充分发挥其高效并发的优势。