MySQL软件架构概述
MySQL软件架构
B站上面的课程喜欢把这部分称之为MySQL高级,其实也不怎么高级,只是说从MySQL的使用转到研究MySQL这个软件,两个不同的方向,不过想要使用的更好,确实是需要深入理解MySQL内部结构的。
图:基本围绕如何使用MySQL和MySQL是如何设计的展开的
概述
想要了解MySQL这个软件是如何运作的,需要了解一些关于数据库的背景知识,然后再去了解MySQL的具体实现,这样对于MySQL的特点就有了比较性的认识。
数据库系统是什么?
MySQL属于数据库管理系统(Database Management System)是一种操纵和管理数据库的大型软件,用于建立、使用和维护数据库,简称DBMS。属于一种极为复杂的大型应用软件,因此了解DBMS的通用性的实现是了解MySQL的必经之路。
数据以文本形式保存,这个文件就是数据库存储在电脑上数据,文件的管理归操作系统(有些是直接写入磁盘,跳过操作系统的文件管理系统)。数据存储在文件上面,那么如何进行检索呢?数据的检索是DBMS中极为重要的一个部分,通常来说我们是通过索引这个数据结构来对数据进行检索。针对MySQL,根据存储引擎的不同,索引的构造也是不同的,有时与数据是一体的(innoDB),有时与数据是分开来放置的(MyISAM)。因此对于一个表而言,底层的数据文件根据存储引擎的不同,会有所不同,其实也有索引不同的原因。
到了这一步,数据有了操作的基石,那么如何使用SQL去操作这些表?这些表暴露出来的接口比较原始与简单,而一条SQL语句包含了很多个接口的操作,因此为了将SQL转化为表可以理解的可以执行的语句,需要一个解释器,将一条SQL语句转换为一系列的接口语言( GET、PUT等)。而当需要进行多表的操作与查询时,还需要一个优化器来决定首先读取哪个表(通常根据每个表的行数和可用索引)以及如何将它与下一个表关联。
完成以上的功能,数据库就有了使用SQL进行增删改查的功能了,但是为了完善数据库的增删改查(crud)功能,增加性能与系统的健壮性,还需要引入索引、日志、锁、mvcc(innoDB特有)等功能。索引文件是为了更快速的检索数据(查询),事务日志与锁或者MVCC等等功能是为了数据库可以实现高性能并发,还有一些其他的日志系统,是为了以防万一数据库出现问题方便进行排查,以及备份数据库等其他功能。
注意,如果希望客户端程序(例如php myadmin这样的SQL UI)驻留在与数据库服务器不同的机器上,则需要编写一个连接管理器,通过TCP/IP向服务器发送SQL请求,然后使用一些凭证对其进行身份验证,解析请求,运行get并将数据发送回客户端。(网络连接)
MySQL架构
三层架构介绍
MySQL分为三层架构,最上层为连接管理,中间层是SQL语句的解析与优化等,底层是存储引擎层。(连接层、服务层、存储层)。
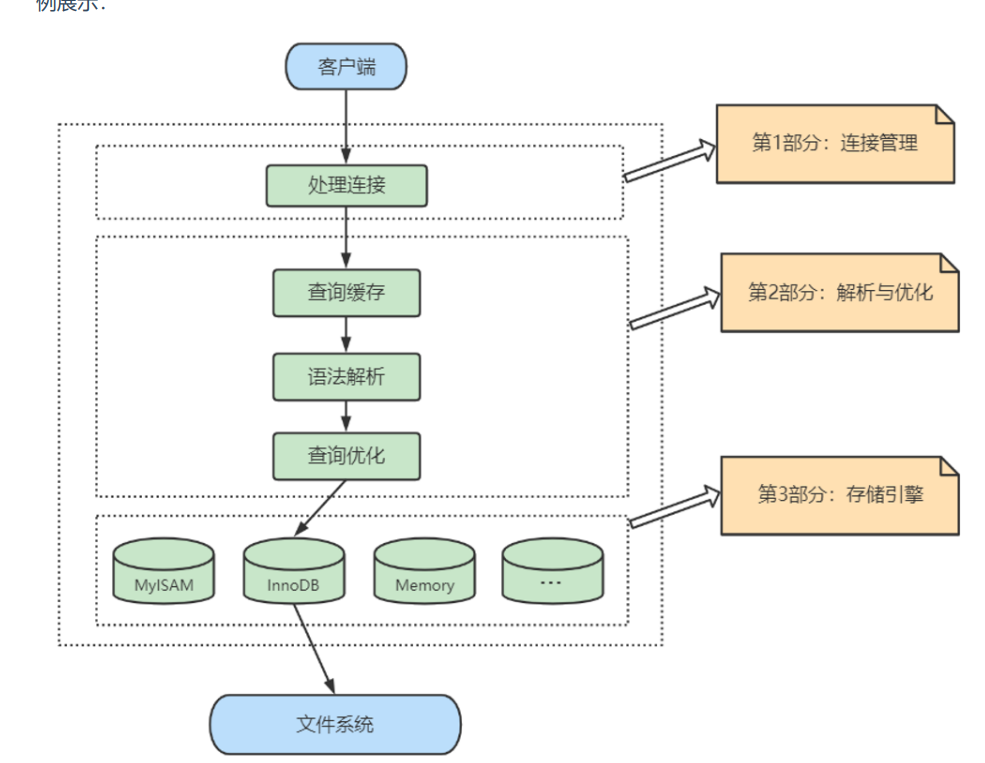
第一层是客户端/服务器通信层(连接层),这并不是MySOL所独有的,大多数基于网络的客户端/服务器的工具或者服务都有类似的架构,比如连接处理、授权认证、安全等等。MySQL采用客户端-服务器模型,支持多种通信协议(如TCP/IP、UNIX套接字等)以实现客户端和服务器之间的通信。客户端可以是命令行工具、图形界面工具或者其他应用程序。这一层负责连接管理、权限验证和数据传输。与MySQL建立连接方式很多,这里把各种连接的方式统一起来。
第二层是server层(服务层),主要负责解析和优化SQL查询,大多数MySQL的核心服务功能都在这一层,包括查询解析、分析、优化、缓存以及所有的内置函数(例如,日期、时间、数学和加密函数),所有跨存储引擎的功能都在这一层实现:存储过程、触发器、视图等。
a. 查询解析器:解析和验证SQL语句的语法和语义,将其转换为内部数据结构。
b. 查询优化器:负责对查询进行优化,选择最佳的执行计划以提高查询性能。
c. 查询缓存:对已执行的查询结果进行缓存,提高重复查询的响应速度。但是,MySQL 8.0之后弃用了查询缓存功能,推荐使用其他缓存解决方案,例如代理缓存。
总的来说,就是把SQL语句转成解析树,然后再优化转化成为查询树(执行计划)的一层(执行计划是传递给存储引擎调用api实现需求的)。SQL–>解析树(语法树)–>查询树(执行计划)
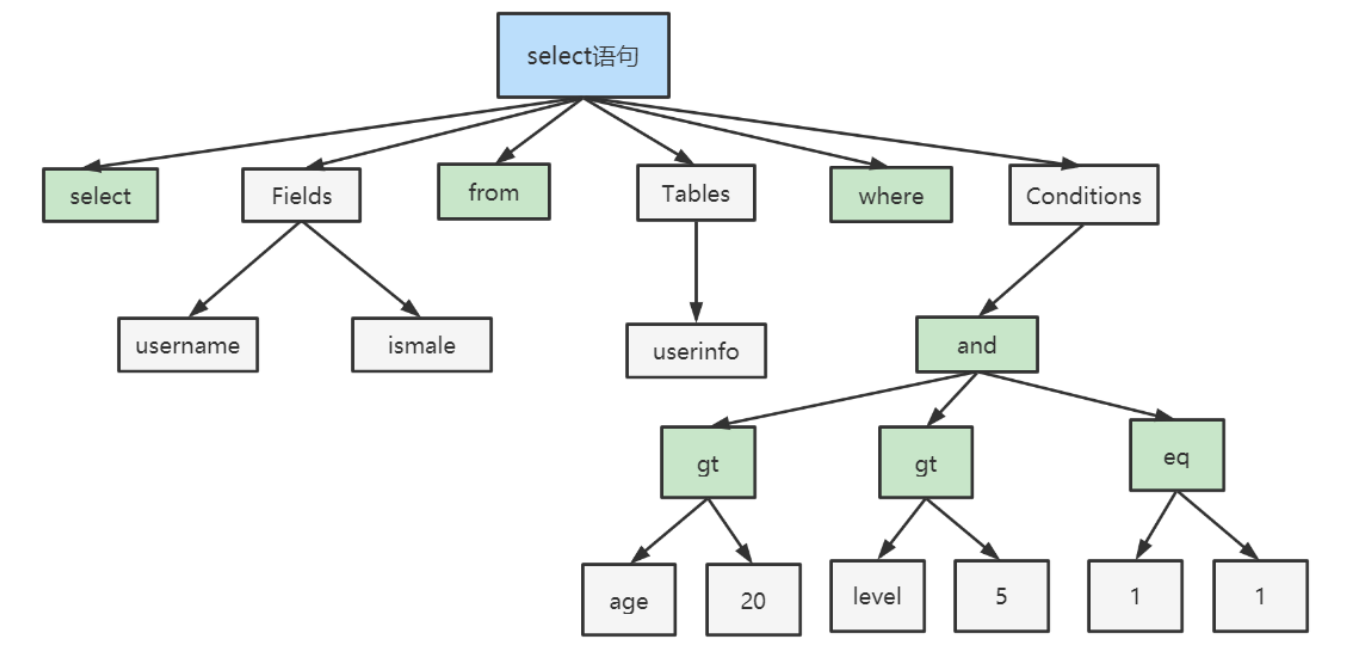
解析树 = 语法树 = 语法分析树
查询树 = 执行计划
内部数据结构 = 以上所有
第三层包含了存储引擎(存储层)。存储引擎负责MySOL中数据的存储和提取。和GNU/Linux下的各种文件系统一样,每个存储引擎都有它的优势和劣势。服务器通过API与存储引警进行通信。这些接口屏蔽了不同存储引擎之间的差异,使得这些差异对上层的查询过程透明。存储引擎API包含几十个底层函数,用于执行诸如“开始一个事务”或者“根据主键提取一行记录”等操作。但存储引擎不会去解析SOL,不同存储引擎之间也不会相互通信,而只是简单地响应上层服务器的请求
存储引擎简介
关于存储引擎(MySQL),存储引擎是MySQL特有的,是存储数据、建立索引、更新/查询数据等技术的实现方式。存储引擎是基于表的,而不是基于库的,所以存储引擎也可被称为“表类型”。(存储引擎是MySQL将数据存储在文件系统中的存储方式或者存储格式)
存储引擎工作方式:
存储引擎本身不直接理解SQL语句。在MySQL的架构中,SQL语句的解析和优化是由查询处理层(中间层)负责的,而存储引擎主要负责数据的存储和管理。
当用户向MySQL发送一个SQL查询时,首先进入解析优化层(服务层)。这里,查询解析器负责解析SQL语句的语法和语义,并将其转换为解析树。然后,查询优化器对查询进行优化,生成执行计划(查询树),选择最佳的执行计划。经过优化后,查询处理层会将SQL转换为一个具体的执行计划。执行计划是一系列针对底层存储引擎API的操作,包括数据读取、写入、更新等。(查询树转为一串操作指令)然后根据执行计划调用存储引擎的api以完成相应的操作。
总的来说,存储引擎不直接理解SQL语句,而是通过查询处理层将SQL语句转换为它能够理解和执行的底层API调用。这种解耦使得MySQL可以灵活地支持多种存储引擎,根据实际需求选择合适的引擎以优化性能。
(存储引擎提供的api大致都是相似的)
虽然不同存储引擎可能提供的API功能子集有所差异,但它们通常都遵循相似的底层存储引擎API设计。这意味着大部分存储引擎都会提供一组基本的数据库操作接口,例如表操作、记录操作、索引操作等。这种设计有助于实现存储引擎之间的通信和互操作性。
基于这些相似的API,MySQL可以在不同存储引擎之间进行切换,同时保持上层查询处理逻辑的一致性。这为数据库设计者和开发者提供了灵活性,使他们能够根据实际应用场景和性能要求选择合适的存储引擎。
然而,在选择存储引擎时,仍需要了解各个存储引擎所支持的API功能和特性,因为每个存储引擎可能在实现细节、性能和特性方面有所差异。通过了解这些差异,可以确保为特定的应用场景选择最适合的存储引擎。
SQL执行流程
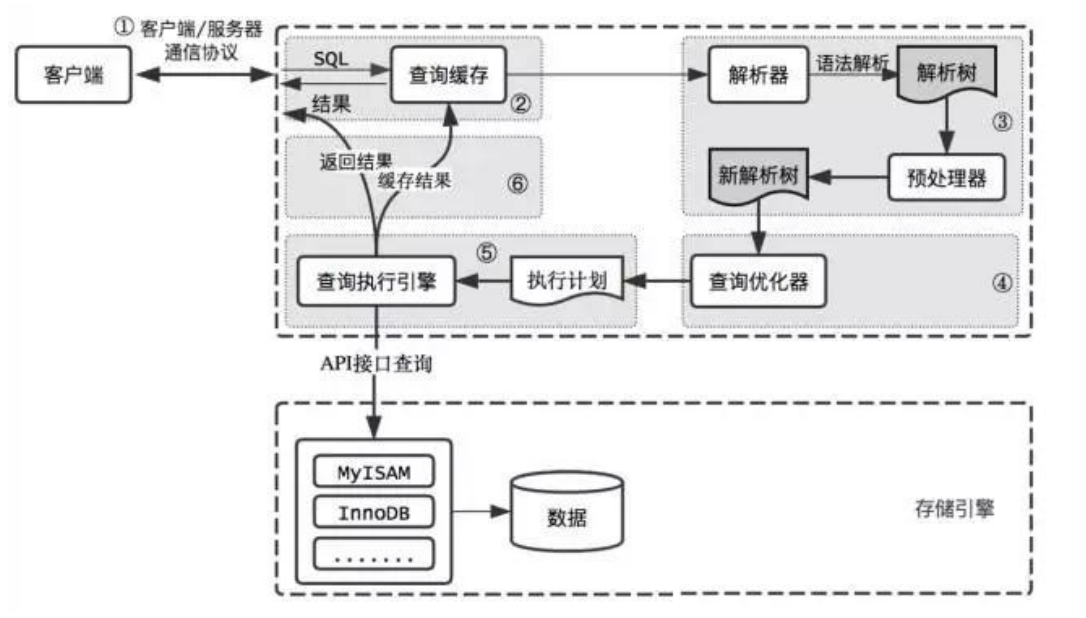
大致流程如下:(SQL->解析树->查询树->结果)

也可以这么体现:
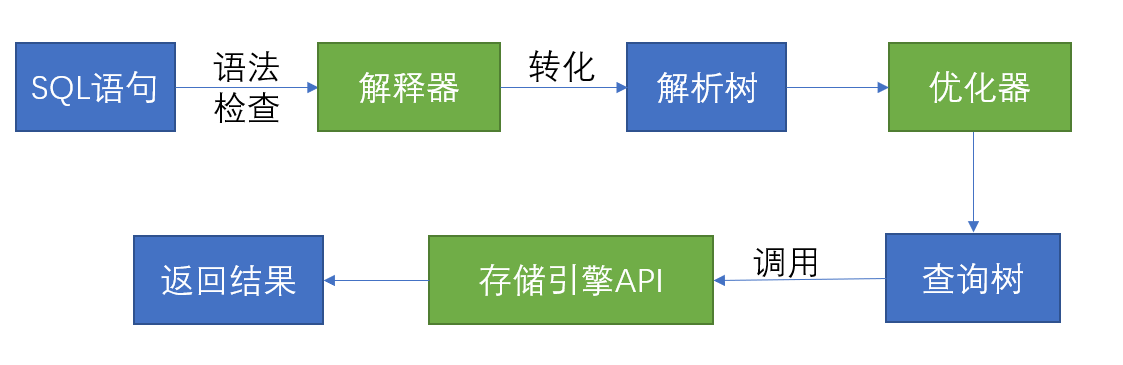
当用户向MySQL发送一个SQL查询时,查看缓存是否命中,如果命中则返回结果,没命中,进入下面的流程:首先进入查询处理层。这里,查询解析器负责解析SQL语句的语法和语义,并将其转换为解析树。然后,查询优化器对查询进行优化,生成执行计划(查询树),选择最佳的执行计划进行执行,执行调用底层存储引擎的api得到结果,然后保存在缓存中并返回结果,查询结束。
缓存
这个缓存并非buffer pool
MySQL的缓存太拉胯了,8中已经取消了,原因是命中率太低,命中率的原因在于缓存机制,查询缓存必须得SQL一模一样才行,而且即使是一模一样,有时候因为使用了函数例如NOW,也会导致结果出现问题。综上所述,这个缓存大家都不喜欢。
存储引擎
内容太大,这里就不展开了
MySQL中数据是存储到表这种结构中的,而根据不同的特性(事务、锁、崩溃恢复),表是具备不同的类型结构的。也就是说表中有个重要的属性,叫表结构,决定了表在数据库层面的功能与性能。这个表结构就是存储引擎(官方起的名)。MySQL中提供了很多存储引擎,其中InnoDB 和 MyISAM (My-Eye-Sam)是最常用的两种存储引擎。
innoDB是5.5之后的存储引擎,myisam是5.5之前的默认存储引擎,可以说innoDB把myisam淘汰了。
其中两者的不同点:(事务、行锁、外键、崩溃恢复、MVCC)
- InnoDB 支持事务,MyISAM 不支持事务。
- InnoDB 支持行级锁,MyISAM 只支持表级锁。
- InnoDB 支持外键,MyISAM 不支持外键。
- InnoDB 支持崩溃恢复,MyISAM 不支持崩溃恢复。
- InnoDB 支持 MVCC(多版本并发控制),MyISAM 不支持 MVCC。
总之:InnoDB 的性能比 MyISAM 更强大。除非有非常特别的原因需要使用其他的存储引擎,否则应该优先考虑InnoDB引擎。
啥情况用myisam呢,读的情况很多的时候。
innoDB有恢复崩溃的功能,这个功能是redo log实现的。
innoDB
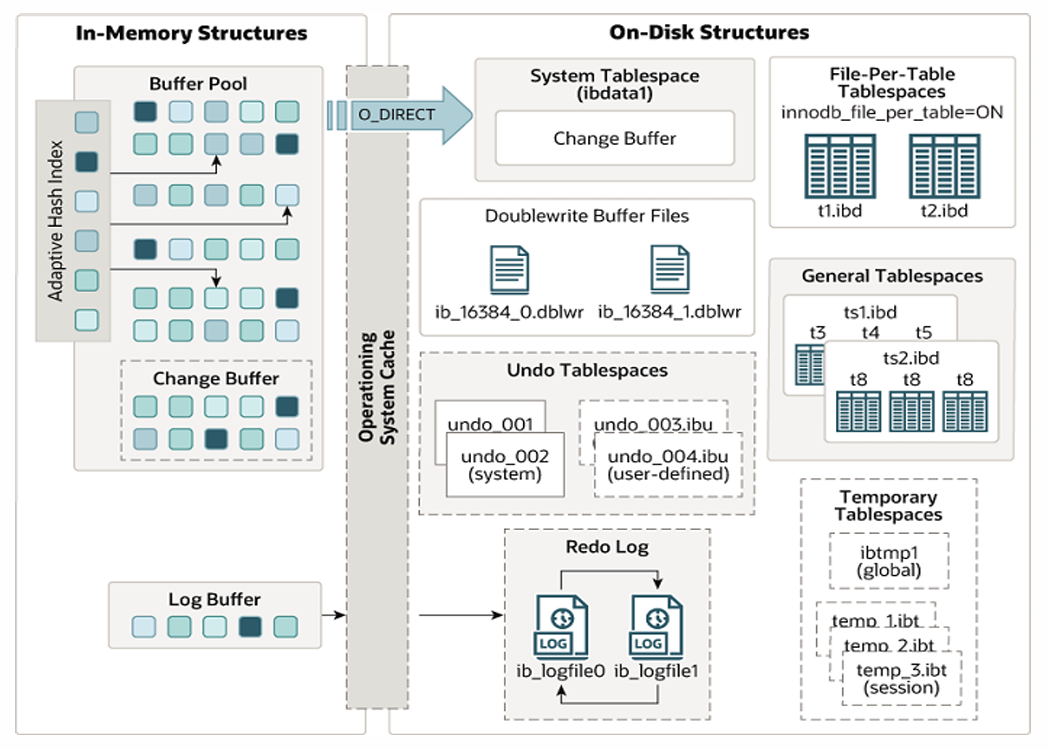
分为内存结构和磁盘结构两个部分,其中内存结构的主要部分是buffer pool。
内容太大,这里就不展开了