批量标准化(Batch Normalization):为什么它能让深度学习模型跑得更快、更稳?
批量标准化(Batch Normalization):为什么它能让深度学习模型跑得更快、更稳?
在过去十几年里,深度神经网络的发展突飞猛进,从语音识别到图像理解再到大模型应用,背后都少不了训练技巧的不断演进。其中有一个“小技巧”,几乎成为现代神经网络的“标配”——那就是 批量标准化(Batch Normalization,简称 BN)。
很多刚入门的朋友经常会疑惑:
为什么大家的网络训练能又快又稳,而我这边的模型老是训练半天收敛不了?
为什么有时候训练时梯度要么爆炸要么消失?
其实,BN 的出现就是为了解决这些经典难题。
批量标准化为什么会诞生?
BN 是 2015 年由 Sergey Ioffe 和 Christian Szegedy 提出的(论文名字很长:《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》😂)。
它的出发点很简单:在训练神经网络时,随着参数不断更新,每一层输入分布会不停变化,这让训练过程变得缓慢甚至不稳定。这就是所谓的 “内部协变量偏移(Internal Covariate Shift)”。
简单打个比方:
你在跑步机上训练,突然跑带的速度一直变快变慢,你是不是很难适应?
网络的各层也是一样,输入分布老是变化,模型就得不停去“适应”,自然效率就低了。
于是 BN 就登场了,它的核心思想是:在激活函数之前,把每一层的输入先做一次标准化,让数据的分布更稳定。
它是如何工作的?
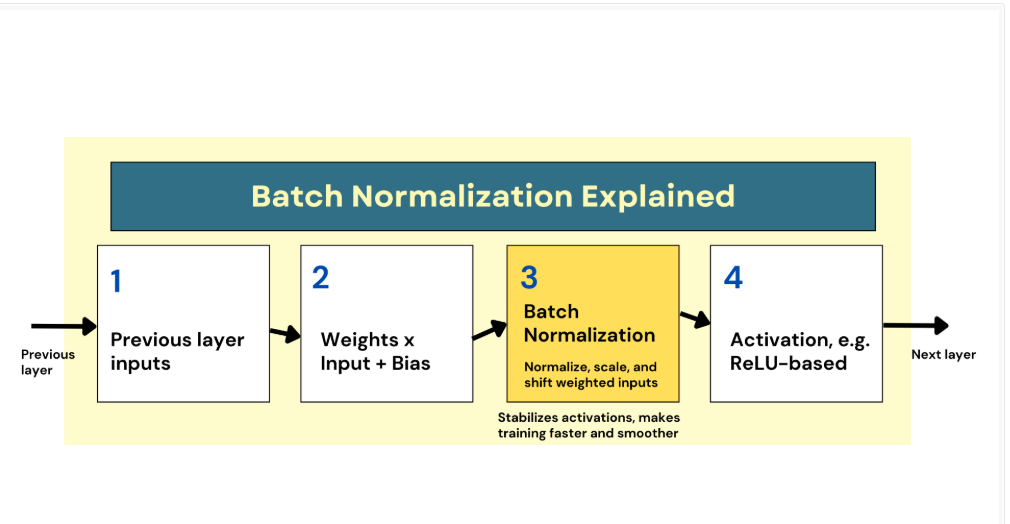
为了解决上述问题,提出了 批量标准化方法,对神经网络各层的输入进行标准化,有助于稳定训练过程。
在实践中,BN 会在加权输入送入激活函数之前,额外引入一个标准化步骤。
最简单的形式包括三步:
零中心化:让输入的均值为 0;
缩放:调整到单位方差,让数据尺度一致;
平移:再通过可学习参数 γ 和 β,恢复到模型更合适的分布。
这一简单操作能让网络在不同层次上更好地学习输入的尺度和均值。反向传播时,梯度流动也会更加平滑,从而减少对权重初始化方法(例如 He 初始化)的敏感性。
最重要的是,它能让训练更快、更稳定。
两个常见问题
1️⃣ 为什么叫“批量”标准化?
因为均值和方差不是在整个数据集上算的,而是 在 mini-batch 上计算的。比如 batch size=32,那就是这 32 个样本一起算统计量。
2️⃣ 所有层都要加 BN 吗?
输入层:通常不需要,因为输入数据在进入模型前就已经归一化过。
隐藏层:这是 BN 的主战场,能显著提升稳定性。
输出层:一般不建议加,尤其是做回归任务时,BN 会破坏输出的分布。
BN 的好处
🚀 加快收敛速度:模型能更快达到较优解。
🛡️ 减少梯度消失/爆炸:反向传播更稳定。
🎯 降低对初始化的依赖:不用再纠结用 Xavier 还是 He 初始化。
🧩 带来正则化效果:一定程度上能抑制过拟合,甚至可以少用 Dropout。
Keras 实现 BN 的示例
在 Keras 里,BN 的使用非常简单,只需要在 Dense 层和激活函数之间插入一行:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, BatchNormalization, Activation
from tensorflow.keras.optimizers import Adam
model = Sequential([Dense(64, input_shape=(20,)), BatchNormalization(), Activation('relu'), Dense(32),BatchNormalization(),Activation('relu'),Dense(1, activation='sigmoid')
])
model.compile(optimizer=Adam(),loss='binary_crossentropy',metrics=['accuracy'])
model.summary()这里要注意:
如果用了 BN,就不要直接在 Dense(32, activation='relu') 里写激活函数,而是分开写成三行。虽然 Keras 内部会自动拆分,但我们显式写出来逻辑更清晰。
总结
BN 看似只是一个小技巧,但它极大地改变了神经网络的训练方式。现在几乎所有主流架构(ResNet、Transformer 等)都会把 BN 当成“标配”。
如果你在训练模型时遇到以下情况:
收敛慢
梯度不稳定
模型对初始化很敏感
不妨试试在网络里加上 Batch Normalization,很可能立竿见影。