Shell 秘典(卷十)—— 服务器资源自动化监控脚本的设计与实现
文章目录
- 前言
- 一、系统组成介绍
- 1.1 配置文件 (`config.conf`)
- 1.2 配置校验脚本 (`check_config.sh`)
- 1.3 主监控脚本 (`system_monitor.sh`)
- 1.3.1 脚本头部与基础变量定义
- 1.3.2 加载配置:`load_config()`
- 1.3.3 CPU监控:`check_cpu()`
- 1.3.4 内存监控:`check_memory()`
- 1.3.5 磁盘监控:`check_disk()`
- 1.3.6 IO等待监控:`check_io_await()`
- 1.3.7 网络带宽监控:`check_bandwidth()`
- 1.3.8 主函数:`main()`
- 二、部署与自动化
- 三、成果展示与压测验证
- 3.1 脚本正常执行结果展示
- 3.2 综合压测方案设计
- 3.2.1 压测环境准备
- 3.2.2 综合压测执行脚本
- 3.2.3 执行压测
- 3.3 压测结果展示
- 3.3.1 监控日志输出 (`/opt/export/resource_monitor.log`)
- 3.3.2 错误日志输出 (`/opt/export/resource_monitor_error.log`)
- 3.3.3 告警邮件内容
- 总结
前言
现代运维工作中,服务器性能指标(包括CPU、内存、磁盘、IO和网络带宽)的持续监控与异常告警是保障服务稳定性的核心要素。传统的手动检查方式效率低且难以及时响应突发状况,因此采用自动化监控脚本配合告警机制已成为运维团队的必备工具。
本文将详细介绍一套基于Shell脚本开发的服务器资源监控告警系统。该系统通过check_config.sh校验配置合法性,通过system_monitor.sh实现核心监控逻辑,并结合crontab定时任务,实现了对服务器多项关键指标的持续监控,并在资源使用超过阈值时自动发送邮件告警,极大提升了运维效率和系统可靠性。
一、系统组成介绍
本系统主要由四个部分构成:
config.conf:资源监控阈值配置文件。check_config.sh:配置文件校验脚本。system_monitor.sh:核心监控脚本。resource_monitor.log&resource_monitor_error.log:监控日志与错误告警日志。
1.1 配置文件 (config.conf)
配置文件 (config.conf)用于集中管理所有监控项的阈值参数,便于灵活调整而不需修改脚本代码。
路径:/opt/export/config.conf
# ============================ 服务器资源监控配置文件 ============================
# 注意:修改此文件后,建议运行 check_config.sh 校验配置有效性# ---------------------------- CPU监控配置 ----------------------------
# CPU使用率阈值(百分比),超过此值触发告警
CPU_THRESHOLD=80# ---------------------------- 内存监控配置 ----------------------------
# 内存使用率阈值(百分比),超过此值触发告警
MEMORY_THRESHOLD=80# ---------------------------- 磁盘监控配置 ----------------------------
# 磁盘使用率阈值(百分比),超过此值触发告警
DISK_THRESHOLD=80# 监控的文件系统(挂载点),默认为根目录
FILESYSTEM="/"# ---------------------------- IO监控配置 ----------------------------
# IO等待时间阈值(毫秒),超过此值触发告警
IO_AWAIT_THRESHOLD=50# iostat命令采样间隔时间(秒),用于获取IO统计数据
IO_SAMPLE_INTERVAL=5# ---------------------------- 网络带宽监控配置 ----------------------------
# 入站带宽使用率阈值(%),超过此值可能触发告警
BANDWIDTH_IN_THRESHOLD=20# 出站带宽使用率阈值(%),超过此值可能触发告警
BANDWIDTH_OUT_THRESHOLD=20# 手动设置的入站带宽总速率(单位: Mbps),用于计算使用率
# 请根据实际网络环境调整此值
BANDWIDTH_IN_SPEED=50# 手动设置的出站带宽总速率(单位: Mbps),用于计算使用率
# 请根据实际网络环境调整此值
BANDWIDTH_OUT_SPEED=50# 带宽采样次数,网络监控会进行多次采样取平均值
SAMPLE_COUNT=5# 触发告警的超阈值次数,需要多次采样中超过此次数才会触发告警
# 此值必须小于或等于 SAMPLE_COUNT
OVER_THRESHOLD_COUNT=3
1.2 配置校验脚本 (check_config.sh)
该脚本用于在主监控脚本运行前对配置文件进行语法和合法性校验,避免因配置错误导致监控异常。
主要功能:
- 检查配置文件是否存在、是否可读
- 检查各项阈值参数格式是否正确(数字范围、有效性)
- 检查指定的文件系统是否存在
- 校验
OVER_THRESHOLD_COUNT不能大于SAMPLE_COUNT
#!/bin/bash# ============================ 配置文件校验脚本 ============================
# 功能:检查 config.conf 配置文件的完整性和有效性
# 用法:可直接运行或在其他脚本中调用# -------------------------- 定义基础变量(日志路径等) --------------------------# 配置文件绝对路径
CONFIG_FILE="/opt/export/config.conf"# 正常监控日志文件路径(用于记录监控结果)
LOG_FILE="/opt/export/resource_monitor.log"# 错误日志文件路径(用于记录告警和错误信息)
ERROR_LOG_FILE="/opt/export/resource_monitor_error.log"# -------------------------- 时间格式化函数 --------------------------------# 功能:获取格式化的当前时间字符串
# 输出:YYYY-MM-DD HH:MM:SS 格式的时间字符串
get_current_time() {date +"%Y-%m-%d %H:%M:%S"
}# -------------------------- 错误日志记录函数 --------------------------------# 功能:将错误信息同时输出到标准错误流和错误日志文件
# 参数:$1 - 要记录的错误消息
log_error() {local message="$1"# 输出到标准错误流(终端可见)echo "$message" >&2# 追加到错误日志文件echo "$message" >> "$ERROR_LOG_FILE"
}# -------------------------- 配置文件校验主函数 --------------------------------# 功能:全面校验配置文件的各项参数
# 返回值:校验通过返回0,校验失败返回1并记录错误信息
check_config() {# 检查配置文件是否存在if [[ ! -f "$CONFIG_FILE" ]]; thenlog_error "[$(get_current_time)] [错误]:配置文件 $CONFIG_FILE 不存在,请检查路径是否正确"exit 1fi# 检查配置文件是否可读if [[ ! -r "$CONFIG_FILE" ]]; thenlog_error "[$(get_current_time)] [错误]:配置文件 $CONFIG_FILE 不可读,请检查文件权限"exit 1fi# 从配置文件中读取变量,并捕获可能的语法错误source "$CONFIG_FILE" 2>/dev/nullif [[ $? -ne 0 ]]; thenlog_error "[$(get_current_time)] [错误]:配置文件 $CONFIG_FILE 格式错误,可能存在语法问题,无法正确解析"exit 1fi# 校验结果标志位,0表示有效,1表示存在无效配置local invalid=0# 检查CPU阈值:必须是1-100之间的整数if [[ ! "$CPU_THRESHOLD" =~ ^[1-9][0-9]?$|^100$ ]]; thenlog_error "[$(get_current_time)] [错误]:配置文件中 CPU_THRESHOLD=$CPU_THRESHOLD 无效(需为1-100的整数)"invalid=1fi# 检查内存阈值:必须是1-100之间的整数if [[ ! "$MEMORY_THRESHOLD" =~ ^[1-9][0-9]?$|^100$ ]]; thenlog_error "[$(get_current_time)] [错误]:配置文件中 MEMORY_THRESHOLD=$MEMORY_THRESHOLD 无效(需为1-100的整数)"invalid=1fi# 检查磁盘阈值:必须是1-100之间的整数if [[ ! "$DISK_THRESHOLD" =~ ^[1-9][0-9]?$|^100$ ]]; thenlog_error "[$(get_current_time)] [错误]:配置文件中 DISK_THRESHOLD=$DISK_THRESHOLD 无效(需为1-100的整数)"invalid=1fi# 检查监控的文件系统是否存在且有效if ! df -h "$FILESYSTEM" &> /dev/null; thenlog_error "[$(get_current_time)] [错误]:配置文件中 FILESYSTEM=$FILESYSTEM 不存在或不是有效的挂载点"invalid=1fi# 检查IO等待阈值:必须是大于0的正整数if [[ ! "$IO_AWAIT_THRESHOLD" =~ ^[1-9][0-9]*$ ]]; thenlog_error "[$(get_current_time)] [错误]:配置文件中 IO_AWAIT_THRESHOLD=$IO_AWAIT_THRESHOLD 无效(需为大于0的正整数)"invalid=1fi# 检查IO采样间隔:必须是大于0的正整数if [[ ! "$IO_SAMPLE_INTERVAL" =~ ^[1-9][0-9]*$ ]]; thenlog_error "[$(get_current_time)] [错误]:配置文件中 IO_SAMPLE_INTERVAL=$IO_SAMPLE_INTERVAL 无效(需为大于0的正整数)"invalid=1fi# 检查入站带宽阈值:必须是1-100之间的整数if [[ ! "$BANDWIDTH_IN_THRESHOLD" =~ ^[1-9][0-9]?$|^100$ ]]; thenlog_error "[$(get_current_time)] [错误]:配置文件中 BANDWIDTH_IN_THRESHOLD=$BANDWIDTH_IN_THRESHOLD 无效(需为1-100的整数)"invalid=1fi# 检查出站带宽阈值:必须是1-100之间的整数if [[ ! "$BANDWIDTH_OUT_THRESHOLD" =~ ^[1-9][0-9]?$|^100$ ]]; thenlog_error "[$(get_current_time)] [错误]:配置文件中 BANDWIDTH_OUT_THRESHOLD=$BANDWIDTH_OUT_THRESHOLD 无效(需为1-100的整数)"invalid=1fi# 检查入站带宽速度:必须是大于0的正整数if [[ ! "$BANDWIDTH_IN_SPEED" =~ ^[1-9][0-9]*$ ]]; thenlog_error "[$(get_current_time)] [错误]:配置文件中 BANDWIDTH_IN_SPEED=$BANDWIDTH_IN_SPEED 无效(需为大于0的正整数)"invalid=1fi# 检查出站带宽速度:必须是大于0的正整数if [[ ! "$BANDWIDTH_OUT_SPEED" =~ ^[1-9][0-9]*$ ]]; thenlog_error "[$(get_current_time)] [错误]:配置文件中 BANDWIDTH_OUT_SPEED=$BANDWIDTH_OUT_SPEED 无效(需为大于0的正整数)"invalid=1fi# 检查采样次数:必须是大于0的正整数if [[ ! "$SAMPLE_COUNT" =~ ^[1-9][0-9]*$ ]]; thenlog_error "[$(get_current_time)] [错误]:配置文件中 SAMPLE_COUNT=$SAMPLE_COUNT 无效(需为大于0的正整数)"invalid=1fi# 检查超阈值次数:必须是大于0的正整数且不能大于采样次数if [[ ! "$OVER_THRESHOLD_COUNT" =~ ^[1-9][0-9]*$ ]]; thenlog_error "[$(get_current_time)] [错误]:配置文件中 OVER_THRESHOLD_COUNT=$OVER_THRESHOLD_COUNT 无效(需为大于0的正整数)"invalid=1elif [[ "$OVER_THRESHOLD_COUNT" -gt "$SAMPLE_COUNT" ]]; thenlog_error "[$(get_current_time)] [错误]:配置文件中 OVER_THRESHOLD_COUNT=$OVER_THRESHOLD_COUNT 不能大于 SAMPLE_COUNT=$SAMPLE_COUNT"invalid=1fi# 若存在无效配置,脚本退出并返回错误码if [ $invalid -eq 1 ]; thenexit 1fi# 所有配置校验通过,输出成功信息echo "[$(get_current_time)] 配置文件校验完成,所有配置项均有效。"
}# ------------------------------------ 脚本执行入口 ----------------------------------
# 调用配置校验函数
check_config1.3 主监控脚本 (system_monitor.sh)
这是系统的核心脚本,包含多个监控函数。
1.3.1 脚本头部与基础变量定义
功能描述:定义脚本中使用的基础路径变量、日志文件路径和时间获取函数,为后续监控功能提供基础支持。
#!/bin/bash# ============================ 服务器资源监控主脚本 ============================
# 功能:监控CPU、内存、磁盘、IO、网络带宽等资源使用情况
# 依赖:需要系统安装 bc、mail、iostat 等工具# -------------------------- 定义基础变量(日志路径等) ------------------------# 配置文件绝对路径
CONFIG_FILE="/opt/export/config.conf"# 正常监控日志文件路径(记录每次监控的详细结果)
LOG_FILE="/opt/export/resource_monitor.log"# 错误日志文件路径(记录告警和异常信息)
ERROR_LOG_FILE="/opt/export/resource_monitor_error.log"# -------------------------- 时间获取函数 --------------------------------# 功能:获取格式化的当前时间字符串
# 输出:返回 YYYY-MM-DD HH:MM:SS 格式的时间字符串
# 说明:统一整个脚本的时间格式,便于日志分析
get_current_time() {date +"%Y-%m-%d %H:%M:%S"
}
1.3.2 加载配置:load_config()
功能描述:负责加载和验证配置文件,确保脚本能够正确读取所有监控阈值参数。如果配置文件不存在或不可读,会记录错误日志并退出脚本。
# -------------------------------- 配置文件加载函数 ---------------------------------# 功能:加载并验证配置文件
# 异常处理:配置文件不存在或不可读时,记录错误并退出脚本(退出码1)
load_config()
{# 检查配置文件是否存在且具有读权限if [ ! -f "$CONFIG_FILE" ] || [ ! -r "$CONFIG_FILE" ] ; then# 构造错误消息,包含时间戳和详细错误描述local err_msg="[$(get_current_time)] [错误]:配置文件 $CONFIG_FILE 不存在或无读取权限!请检查文件路径和权限设置。"# 输出到标准错误流(终端可见),方便实时查看错误echo "$err_msg" >&2# 同时将错误信息记录到错误日志文件,便于后续排查echo "$err_msg" >> "$ERROR_LOG_FILE"# 配置文件是脚本运行的基础,如果加载失败则直接退出(退出码1表示错误)exit 1fi# 使用source命令加载配置文件中的所有变量到当前shell环境# 这样后续函数可以直接使用 CPU_THRESHOLD、MEMORY_THRESHOLD 等变量source "$CONFIG_FILE"# 记录配置加载成功的日志(可选,如果需要更详细的日志可以取消注释)# echo "[$(get_current_time)] 配置文件加载成功" >> "$LOG_FILE"
}1.3.3 CPU监控:check_cpu()
功能描述:监控当前CPU的使用率,通过top命令获取CPU的总体使用情况(用户态+系统态),与配置文件中设置的阈值进行比较。如果超过阈值,则发送邮件告警并记录错误日志。
# --------------------------------- CPU使用率检查函数 --------------------------------# 功能:监控当前CPU总体使用率(用户态+系统态)
# 实现原理:使用top命令的非交互模式获取CPU数据,通过awk提取并计算使用率
# 输出:记录监控结果到日志文件,超阈值时发送告警邮件
check_cpu()
{# 使用top命令获取CPU使用率数据# -bn1: b-批处理模式,n1-只运行1次# awk过滤包含'Cpu'的行,计算第2列(用户态)和第4列(系统态)的和,保留1位小数local cpu_usage=$(top -bn1 | awk '/Cpu/{printf ("%.1f\n"), ($2 + $4)}') # 构造监控结果日志消息,包含时间戳和当前CPU使用率local log_msg="[$(get_current_time)] CPU检查结果:当前CPU使用率为 $cpu_usage %"# 将监控结果记录到正常日志文件echo "$log_msg" >> "$LOG_FILE"# 使用bc进行浮点数比较,检查CPU使用率是否超过配置的阈值# bc -l: 启动bc计算器并加载数学库,支持浮点数运算if (( $(echo "$cpu_usage > $CPU_THRESHOLD" | bc -l) )); then# 构造告警消息,包含详细的使用率和阈值信息local alert_msg="[$(get_current_time)] [警告]:当前CPU使用率为 $cpu_usage %,超过阈值 ${CPU_THRESHOLD}%"# 发送告警邮件到指定邮箱,邮件主题明确标识告警类型echo "$alert_msg" | mail -s "服务器CPU使用率警告" 1321072533@qq.com# 同时将告警信息记录到错误日志文件,便于后续统计和分析echo "$alert_msg" >> "$ERROR_LOG_FILE" fi
}1.3.4 内存监控:check_memory()
功能描述:监控系统内存使用率,通过free命令获取内存使用数据,计算已用内存占总内存的百分比,与配置阈值进行比较并在超阈值时告警。
# --------------------------------- 内存使用率检查函数 --------------------------------# 功能:监控系统内存使用率
# 实现原理:使用free命令获取内存信息,awk计算已用内存的百分比
# 输出:记录监控结果到日志文件,超阈值时发送告警邮件
check_memory()
{# 使用free命令获取内存信息,awk过滤包含'Mem'的行# 计算第3列(已用内存)除以第2列(总内存)的百分比,保留1位小数local memory_usage=$(free | awk '/Mem/{printf("%.1f\n"), $3*100/$2}')# 构造监控结果日志消息,包含时间戳和当前内存使用率local log_msg="[$(get_current_time)] 内存检查结果:当前内存使用率为 $memory_usage %"# 将监控结果记录到正常日志文件echo "$log_msg" >> "$LOG_FILE"# 使用bc进行浮点数比较,检查内存使用率是否超过配置的阈值if (( $(echo "$memory_usage > $MEMORY_THRESHOLD" | bc -l) )); then# 构造告警消息,包含详细的使用率和阈值信息local alert_msg="[$(get_current_time)] [警告]:当前内存使用率为 $memory_usage %,超过阈值 ${MEMORY_THRESHOLD}%"# 发送告警邮件到指定邮箱,邮件主题明确标识告警类型echo "$alert_msg" | mail -s "服务器内存使用率警告" 1321072533@qq.com# 同时将告警信息记录到错误日志文件echo "$alert_msg" >> "$ERROR_LOG_FILE"fi
}
1.3.5 磁盘监控:check_disk()
功能描述:监控指定文件系统的磁盘使用率,默认监控根分区(/),通过df命令获取磁盘使用数据,与配置阈值进行比较并在超阈值时告警。
# --------------------------------- 磁盘使用率检查函数 --------------------------------# 功能:监控指定文件系统的磁盘使用率
# 实现原理:使用df命令获取磁盘信息,awk计算使用率百分比
# 注意:默认监控根分区(/),可通过配置文件中的FILESYSTEM变量修改
# 输出:记录监控结果到日志文件,超阈值时发送告警邮件
check_disk()
{# 使用df命令获取指定文件系统的磁盘信息# awk 'NR==2': 取第二行(第一行是标题行)# 计算第3列(已用空间)除以第2列(总空间)的百分比,保留1位小数local disk_usage=$(df "$FILESYSTEM" | awk 'NR==2{printf("%.1f\n"), $3*100/$2}')# 构造监控结果日志消息,包含时间戳、监控的文件系统和当前使用率local log_msg="[$(get_current_time)] 磁盘检查结果:文件系统 $FILESYSTEM 当前使用率为 $disk_usage %"# 将监控结果记录到正常日志文件echo "$log_msg" >> "$LOG_FILE"# 使用bc进行浮点数比较,检查磁盘使用率是否超过配置的阈值if (( $(echo "$disk_usage > $DISK_THRESHOLD" | bc -l) )); then# 构造告警消息,包含详细的使用率、阈值和文件系统信息local alert_msg="[$(get_current_time)] [警告]:文件系统 $FILESYSTEM 使用率为 $disk_usage %,超过阈值 ${DISK_THRESHOLD}%"# 发送告警邮件到指定邮箱,邮件主题明确标识告警类型echo "$alert_msg" | mail -s "服务器磁盘使用率警告" 1321072533@qq.com# 同时将告警信息记录到错误日志文件echo "$alert_msg" >> "$ERROR_LOG_FILE"fi
}1.3.6 IO等待监控:check_io_await()
功能描述:监控所有磁盘设备的IO等待时间(await),通过iostat命令获取每个磁盘设备的IO性能数据,与配置阈值进行比较并在超阈值时告警。
# --------------------------------- IO等待时间检查函数 --------------------------------# 功能:监控所有磁盘设备的IO等待时间(await)
# 实现原理:使用iostat命令获取磁盘IO数据,遍历每个设备检查await值
# await: 平均每次IO操作的等待时间(毫秒),是衡量磁盘性能的关键指标
# 输出:为每个设备记录监控结果到日志文件,超阈值时发送告警邮件
check_io_await()
{# 获取系统中所有磁盘设备列表(排除光驱等非磁盘设备)# iostat -x -d: 显示扩展磁盘统计信息# awk过滤:NR>3跳过标题行,排除scd0(光驱),排除空行,打印设备名# sort -u: 排序并去重,确保每个设备只检查一次local devices=$(iostat -x -d | awk 'NR>3 && $1 != "scd0" && $1 != "" {print $1}' | sort -u)# 遍历每个磁盘设备进行检查for dev in $devices; do# 使用iostat获取指定设备的IO await数据# iostat -x -d $IO_SAMPLE_INTERVAL 2: 每IO_SAMPLE_INTERVAL秒采样一次,共采样2次# grep -w "$dev": 精确匹配设备名# tail -1: 取最后一次采样的数据(第一次是历史平均值,第二次是近期平均值)# awk '{print $10}': 取第10列(await值)local io_await=$(iostat -x -d $IO_SAMPLE_INTERVAL 2 | grep -w "$dev" | tail -1 | awk '{print $10}')# 处理可能的空值情况(某些设备可能没有IO活动)if [ -z "$io_await" ]; thenio_await=0 # 如果没有数据,则认为是0(无IO等待)fi# 构造监控结果日志消息,包含时间戳、设备名、采样周期和await值local log_msg="[$(get_current_time)] IO检查结果:设备 $dev 在 ${IO_SAMPLE_INTERVAL} 秒采样周期内,平均IO await 为 $io_await 毫秒"# 将监控结果记录到正常日志文件echo "$log_msg" >> "$LOG_FILE"# 使用bc进行浮点数比较,检查IO await是否超过配置的阈值if (( $(echo "$io_await > $IO_AWAIT_THRESHOLD" | bc -l) )); then# 构造告警消息,包含详细的设备信息、await值和阈值local alert_msg="[$(get_current_time)] [警告]:设备 $dev IO异常:在 ${IO_SAMPLE_INTERVAL} 秒采样周期内,平均IO await 达到 $io_await 毫秒,超过阈值 ${IO_AWAIT_THRESHOLD} 毫秒"# 发送告警邮件到指定邮箱,邮件主题明确标识告警类型echo "$alert_msg" | mail -s "服务器IO等待警告" 1321072533@qq.com# 同时将告警信息记录到错误日志文件echo "$alert_msg" >> "$ERROR_LOG_FILE"fidone
}1.3.7 网络带宽监控:check_bandwidth()
功能描述:监控指定网络接口的入站和出站带宽使用率,通过多次采样计算平均使用率,并在满足告警条件时发送告警。
# --------------------------------- 网络带宽监控函数 --------------------------------# 功能:监控指定网络接口的入站和出站带宽使用率
# 实现原理:通过读取/proc/net/dev文件统计网络流量,进行多次采样计算平均值
# 告警条件:平均使用率超阈值 AND 超阈值次数≥设定值(避免瞬时峰值误报)
# 输出:记录采样汇总信息到日志文件,满足条件时发送告警邮件
check_bandwidth() {# 要监控的网络接口名称(根据实际系统网卡名称调整,如eth0、ens33等)local interface="ens33"# -------------------------- 初始化监控变量 --------------------------local in_over_count=0 # 入站带宽超阈值次数计数local out_over_count=0 # 出站带宽超阈值次数计数local in_traffic_sum=0 # 入站流量速率总和(用于计算平均值)local out_traffic_sum=0 # 出站流量速率总和(用于计算平均值)local in_traffic_avg=0 # 入站流量速率平均值local out_traffic_avg=0 # 出站流量速率平均值local in_usage_avg=0 # 入站带宽使用率平均值local out_usage_avg=0 # 出站带宽使用率平均值# -------------------------- 计算带宽阈值(转换为KB/s) --------------------------# 注意:1 Mbps = 125 KB/s(因为 1 Byte = 8 bits)# 计算入站带宽阈值:总带宽 * 使用率阈值%local in_threshold_KBps=$(echo "scale=5; ($BANDWIDTH_IN_SPEED * 125) * $BANDWIDTH_IN_THRESHOLD / 100" | bc | xargs printf "%.1f")# 计算出站带宽阈值:总带宽 * 使用率阈值%local out_threshold_KBps=$(echo "scale=5; ($BANDWIDTH_OUT_SPEED * 125) * $BANDWIDTH_OUT_THRESHOLD / 100" | bc | xargs printf "%.1f")# -------------------------- 执行多次采样 --------------------------# 循环进行SAMPLE_COUNT次采样,获取更准确的网络流量数据for ((i=1; i<=$SAMPLE_COUNT; i++)); do# 第一次获取流量数据:读取/proc/net/dev文件,获取指定接口的流量统计local first_in=$(cat /proc/net/dev | grep "$interface" | awk '{print $2}') # 第2列:接收字节数local first_out=$(cat /proc/net/dev | grep "$interface" | awk '{print $10}') # 第10列:发送字节数# 等待1秒,让网络流量有所变化sleep 1# 第二次获取流量数据local second_in=$(cat /proc/net/dev | grep "$interface" | awk '{print $2}')local second_out=$(cat /proc/net/dev | grep "$interface" | awk '{print $10}')# 计算每秒流量变化(转换为KB/s),保留1位小数# 公式:(第二次数据 - 第一次数据) / 1024 (字节转KB)local in_traffic=$(echo "scale=5; ($second_in - $first_in) / 1024" | bc | xargs printf "%.1f")local out_traffic=$(echo "scale=5; ($second_out - $first_out) / 1024" | bc | xargs printf "%.1f")# 累加采样结果到总和,用于后续计算平均值in_traffic_sum=$(echo "scale=5; $in_traffic_sum + $in_traffic" | bc)out_traffic_sum=$(echo "scale=5; $out_traffic_sum + $out_traffic" | bc)# 统计当前采样是否超阈值if (( $(echo "$in_traffic > $in_threshold_KBps" | bc -l ) )); then((in_over_count++)) # 入站超阈值计数加1fiif (( $(echo "$out_traffic > $out_threshold_KBps" | bc -l ) )); then((out_over_count++)) # 出站超阈值计数加1fidone# -------------------------- 计算平均值 --------------------------# 计算入站流量平均值:总和 / 采样次数in_traffic_avg=$(echo "scale=5; $in_traffic_sum / $SAMPLE_COUNT" | bc | xargs printf "%.1f")# 计算出站流量平均值:总和 / 采样次数out_traffic_avg=$(echo "scale=5; $out_traffic_sum / $SAMPLE_COUNT" | bc | xargs printf "%.1f")# 计算入站使用率平均值:平均流量 / 总带宽 * 100%in_usage_avg=$(echo "scale=5; $in_traffic_avg / ($BANDWIDTH_IN_SPEED * 125) * 100" | bc | xargs printf "%.1f")# 计算出站使用率平均值:平均流量 / 总带宽 * 100%out_usage_avg=$(echo "scale=5; $out_traffic_avg / ($BANDWIDTH_OUT_SPEED * 125) * 100" | bc | xargs printf "%.1f")# -------------------------- 记录采样汇总日志 --------------------------local log_msg="[$(get_current_time)] 带宽采样汇总(${SAMPLE_COUNT}次):入站平均使用率 ${in_usage_avg}%,平均速率 ${in_traffic_avg} KB/s(超阈值次数:${in_over_count}次),出站平均使用率 ${out_usage_avg}%,平均速率 ${out_traffic_avg} KB/s(超阈值次数:${out_over_count}次)" echo "$log_msg" >> "$LOG_FILE"# -------------------------- 入站带宽告警检查 --------------------------# 告警条件:平均使用率超阈值 AND 超阈值次数≥设定值(避免误报)if (( $(echo "$in_usage_avg > $BANDWIDTH_IN_THRESHOLD" | bc -l) )) && [ $in_over_count -ge $OVER_THRESHOLD_COUNT ]; thenlocal alert_msg="[$(get_current_time)] [警告]:入站带宽${SAMPLE_COUNT} 次采样汇总,平均使用率 ${in_usage_avg}%,平均速率 ${in_traffic_avg} KB/s(超阈值次数:${in_over_count}次),超过阈值 ${BANDWIDTH_IN_THRESHOLD}%"# 发送告警邮件echo "$alert_msg" | mail -s "服务器入站带宽使用率警告" 1321072533@qq.com# 记录告警信息到错误日志echo "$alert_msg" >> "$ERROR_LOG_FILE" fi# -------------------------- 出站带宽告警检查 --------------------------# 告警条件:平均使用率超阈值 AND 超阈值次数≥设定值if (( $(echo "$out_usage_avg > $BANDWIDTH_OUT_THRESHOLD" | bc -l) )) && [ $out_over_count -ge $OVER_THRESHOLD_COUNT ]; thenlocal alert_msg="[$(get_current_time)] [警告]:出站带宽${SAMPLE_COUNT}次采样汇总,平均使用率 ${out_usage_avg}%,平均速率 ${out_traffic_avg} KB/s(超阈值次数:${out_over_count}次),超过阈值 ${BANDWIDTH_OUT_THRESHOLD}%"# 发送告警邮件echo "$alert_msg" | mail -s "服务器出站带宽使用率警告" 1321072533@qq.com# 记录告警信息到错误日志echo "$alert_msg" >> "$ERROR_LOG_FILE"fi
}
1.3.8 主函数:main()
功能描述:脚本的主执行函数,按顺序调用各个监控功能函数,确保监控流程的有序执行。
# ----------------------------------- 主执行函数 ------------------------------------# 功能:按顺序执行所有监控检查函数
# 执行流程:1.加载配置 → 2.CPU监控 → 3.内存监控 → 4.磁盘监控 → 5.IO监控 → 6.带宽监控
# 设计理念:模块化设计,每个监控功能独立,便于维护和扩展
main()
{# 第一步:加载配置文件,确保所有阈值参数可用load_config# 第二步:检查CPU使用率check_cpu# 第三步:检查内存使用率check_memory# 第四步:检查磁盘使用率check_disk# 第五步:检查IO等待时间check_io_await # 第六步:检查网络带宽使用率check_bandwidth
}# ----------------------------------- 脚本执行入口 ------------------------------------
# 调用主函数开始执行监控任务
main
二、部署与自动化
- 将脚本和配置文件放入指定目录,例如
/opt/export/。 - 赋予脚本执行权限:
chmod +x /opt/export/check_config.sh /opt/export/system_monitor.sh
- 配置邮件客户端:确保系统已安装并配置好
mailx或sendmail等邮件发送工具,以便脚本能够发送邮件。邮件发送功能配置可以参考这篇博客:Shell 秘典(卷九)—— Linux系统中配置邮箱的发送功能 - 配置crontab定时任务:使用
crontab -e编辑定时任务,实现周期性自动监控。
# ============================ Crontab定时任务配置 ============================
# 编辑当前用户的crontab:crontab -e
# 添加以下行实现每分钟执行一次监控# 每分钟执行一次监控脚本
* * * * * /usr/bin/sh /opt/export/system_monitor.sh# 每周一凌晨3点校验配置文件(可选)
0 3 * * 1 /usr/bin/sh /opt/export/check_config.sh

三、成果展示与压测验证
3.1 脚本正常执行结果展示
配置文件校验结果:
[root@simon110 export]# sh /opt/export/check_config.sh
[2025-09-07 21:15:05] 配置文件校验完成,所有配置项均有效。
正常监控日志示例 (/opt/export/resource_monitor.log):
tail -f /opt/export/resource_monitor.log

错误日志状态 (/opt/export/resource_monitor_error.log):
在正常负载下,错误日志保持为空或仅有历史记录。
手动执行监控脚本:
sh /opt/export/system_monitor.sh
监控日志 (/opt/export/resource_monitor.log)会立刻显示以下记录:

3.2 综合压测方案设计
使用stress和ab(Apache Benchmark)工具模拟高负载场景,验证监控脚本的告警功能。
3.2.1 压测环境准备
安装必要工具:
# Ubuntu/Debian
sudo apt-get update
sudo apt-get install stress apache2-utils -y# CentOS/RHEL
sudo yum install epel-release -y
sudo yum install stress httpd-tools -y
3.2.2 综合压测执行脚本
创建压测脚本 pressure_test.sh:
#!/bin/bash
echo "开始压测测试"
echo "当前时间: $(date +"%Y-%m-%d %H:%M:%S")"
echo "=============================================="# 压测参数
TEST_DURATION=60 # 单次测试时长(秒)
COOL_DOWN_TIME=5 # 测试间隔冷却时间(秒)
DISK_TEST_FILE="/tmp/stress_disk_test" # 磁盘测试文件路径# 1. CPU压测(4核心)
echo "1. CPU压测:4核心负载(${TEST_DURATION}秒)..."
stress --cpu 4 --timeout $TEST_DURATION
echo "CPU压测完成,冷却${COOL_DOWN_TIME}秒..."
sleep $COOL_DOWN_TIME# 2. 内存压测(80%可用内存)
echo "2. 内存压测:占用80%可用内存(${TEST_DURATION}秒)..."
TOTAL_AVAIL=$(free -m | awk '/Mem/{print $7}')
MEM_TO_USE=$((TOTAL_AVAIL * 80 / 100))M
stress --vm 4 --vm-bytes $MEM_TO_USE --timeout $TEST_DURATION
echo "内存压测完成,冷却${COOL_DOWN_TIME}秒..."
sleep $COOL_DOWN_TIME# 3. 磁盘压测(dd简单写入)
echo "3. 磁盘压测:1GB文件写入..."
dd if=/dev/zero of=$DISK_TEST_FILE bs=1M count=1024 oflag=direct 2>/dev/null
echo "磁盘写入完成,清理测试文件..."
rm -f $DISK_TEST_FILE
sleep $COOL_DOWN_TIME# 4. 网络压测(ab测试百度)
echo "4. 网络压测:向百度发起请求(${TEST_DURATION}秒)..."
ab -n 1000 -c 10 https://www.baidu.com/ >/dev/null 2>&1 &
AB_PID=$!
sleep $TEST_DURATION
kill $AB_PID 2>/dev/null
wait 2>/dev/null
echo "网络压测完成!"echo "=============================================="
echo "所有压测项已完成!请检查:"
echo "1. 监控告警邮件"
echo "2. 错误日志:tail -f /opt/export/resource_monitor_error.log"
echo "3. 监控日志:tail -f /opt/export/resource_monitor.log"
3.2.3 执行压测
# 赋予执行权限
chmod +x pressure_test.sh# 执行压测
./pressure_test.sh

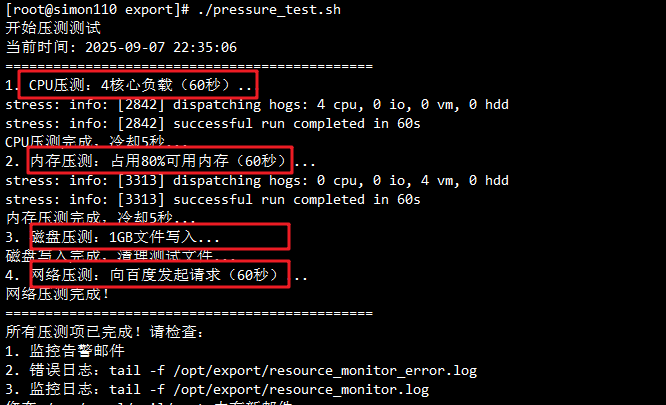
3.3 压测结果展示
3.3.1 监控日志输出 (/opt/export/resource_monitor.log)

3.3.2 错误日志输出 (/opt/export/resource_monitor_error.log)
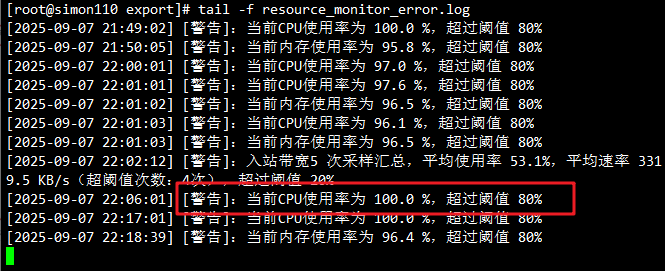
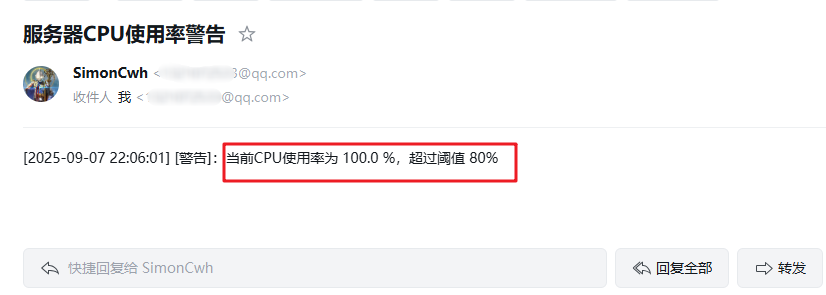
3.3.3 告警邮件内容
CPU告警邮件:
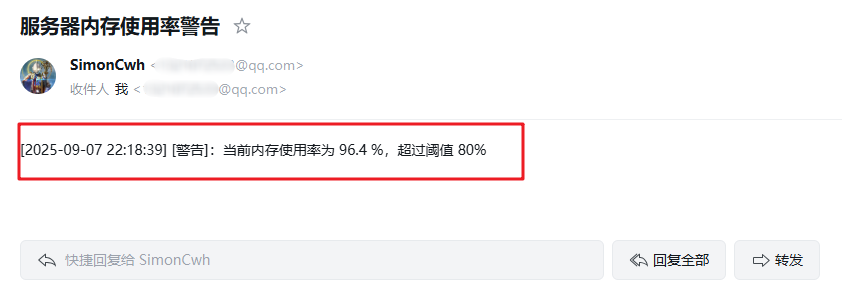
内存告警邮件:
IO告警邮件:
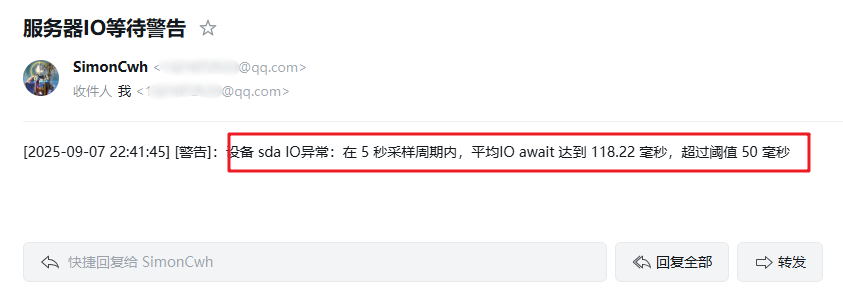
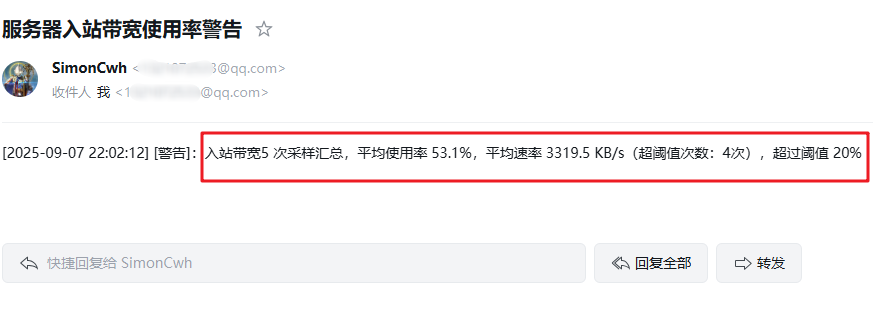
带宽告警邮件:
总结
本系统通过Shell脚本实现了对Linux服务器多项关键资源的自动化监控与告警,具有以下特点:
- 配置灵活:所有阈值参数均通过配置文件管理,修改方便。
- 安全可靠:提供配置校验脚本,避免因配置错误导致脚本异常。
- 监控全面:覆盖CPU、内存、磁盘、IO、网络带宽等核心指标。
- 告警及时:支持邮件告警,并可扩展其他告警方式。
- 减少误报:网络带宽监控采用“多次采样、双重判断”策略,大大降低了误报的可能性。
- 日志完善:正常日志和错误日志分离,便于问题排查。
该系统轻量、高效、易于部署,非常适合中小型服务器环境的监控需求。用户可根据实际环境调整监控阈值和告警策略,进一步提升系统的适用性和可靠性。