视频动作识别-VideoSwin
🎯 VideoSwin —— 基于 Swin Transformer 的视频理解新范式
论文:Video Swin Transformer
作者:Zheng Zhang 等(Microsoft, CVPR 2022)
关键词:VideoSwin、Swin Transformer、视频分类、时空建模、Transformer
一、背景:为什么需要 VideoSwin?
随着 Transformer 在图像领域大获成功(如 ViT、Swin Transformer),研究者开始思考:
❓ 能不能把 Transformer 的强大建模能力 引入视频理解?
但直接将 ViT 用于视频会面临两个问题:
- 计算复杂度爆炸:视频是 4D 数据(T×H×W×C),自注意力复杂度是 $ O((T×H×W)^2) $,无法处理长视频;
- 缺乏局部性建模:全局注意力对局部运动建模效率低。
👉 VideoSwin 正是为了解决这些问题而提出的。
二、核心思想:将 Swin Transformer 从 2D 扩展到 3D
✅ 把 Swin Transformer 的“滑动窗口 + 移位机制”从空间扩展到时空维度,实现高效、可扩展的视频建模。
🔥 三大创新点:
| 创新 | 说明 |
|---|---|
| 1. 3D 局部窗口注意力 | 在时空立方体上划分局部窗口,限制注意力范围 |
| 2. 跨窗口信息交互 | 通过“移位窗口”机制实现全局信息流动 |
| 3. 层次化下采样 | 逐步降低时空分辨率,构建多尺度特征金字塔 |
三、网络结构详解
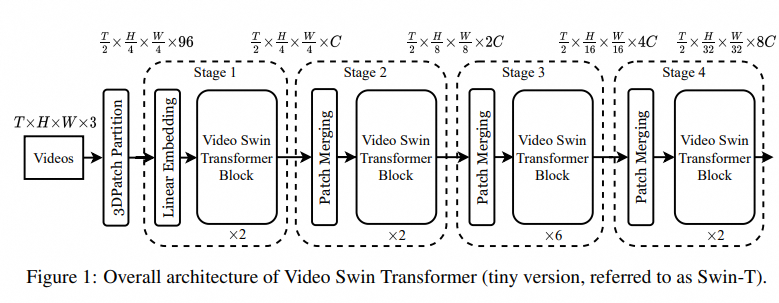
1. 整体架构
输入:T × H × W × 3 视频帧↓
3D Patch Embedding → 将视频切分为 3D patch(如 2×4×4)↓
Swin Transformer Blocks(堆叠)↓
Hierarchical Feature Maps↓
Global Pooling + Classifier↓
输出:动作类别
- 类似 Swin-T/S/B/L,有不同规模变体(VideoSwin-Tiny, Small, Base, Large)
2. 3D Patch Embedding
- 将视频划分为 3D patches(时间 + 空间);
- 例如:每个 patch 大小为
2×4×4(2 帧,4×4 像素); - 线性映射后得到 patch embeddings。
✅ 相比 2D patch,保留了时间连续性。
3. 3D Shifted Window Attention(核心)
(1)局部窗口划分
- 在每个 block 中,将特征图划分为 不重叠的 3D 局部窗口(如 8×7×7);
- 每个窗口内计算 局部自注意力,复杂度从 $ O(N^2) $ 降为 $ O(M^2) $,其中 $ M \ll N $。
(2)移位窗口(Shifted Windows)
- 下一个 block 将窗口循环移位半个窗口大小;
- 使不同窗口之间能交互信息;
- 实现全局感受野,但保持低计算量。
💡 这是 Swin 系列的核心设计,VideoSwin 将其扩展到时间维度。
4. 层次化结构(4 个 Stage)
| Stage | 时空分辨率 | 窗口大小 | Patch 合并 |
|---|---|---|---|
| 1 | T×H×W | 8×7×7 | 无 |
| 2 | T/2 × H/2 × W/2 | 8×7×7 | 2×2×2 |
| 3 | T/4 × H/4 × W/4 | 8×7×7 | 2×2×2 |
| 4 | T/8 × H/8 × W/8 | 8×7×7 | 2×2×2 |
- 每个 stage 后进行 3D Patch Merging(类似池化);
- 构建多尺度特征金字塔,适合下游任务(如检测、分割)。
四、为什么 VideoSwin 强?
| 优势 | 说明 |
|---|---|
| ✅ 高效时空建模 | 局部窗口注意力大幅降低计算量 |
| ✅ 长序列建模能力 | 支持 32~64 帧输入,适合长动作 |
| ✅ 层次化特征 | 输出多尺度特征,可用于检测/分割 |
| ✅ 可扩展性强 | 有 Tiny 到 Large 多种规模 |
| ✅ 性能 SOTA | 在 Kinetics、Something-Something、Charades 等 benchmark 上刷新记录 |
五、性能对比(Kinetics-400 Top-1 Acc)
| 模型 | 准确率 | FLOPs | 参数量 |
|---|---|---|---|
| I3D (ResNet-50) | ~73% | ~108G | ~26M |
| SlowFast (8x8) | ~79% | ~175G | ~36M |
| TimeSformer | ~77% | ~106G | ~121M |
| VideoSwin-T | 79.8% | ~97G | ~24M |
| VideoSwin-B | 82.8% | ~158G | ~88M |
✅ VideoSwin-B 在 Kinetics 上达到 82.8% Top-1 准确率,远超传统 CNN 和早期 Transformer。
六、应用场景
| 场景 | 说明 |
|---|---|
| 📊 视频分类 | Kinetics、SSv2、Moments in Time |
| 🧠 视频检测 | AVA、ActivityNet(作为 backbone) |
| 🖼️ 视频分割 | Video Panoptic Segmentation |
| 🔍 异常检测 | 利用重建误差或注意力分析 |
| 🧪 自监督预训练 | Masked Video Modeling(如 MVM) |
七、局限性
| 局限 | 说明 |
|---|---|
| ❌ 计算量仍较大 | 尤其是 Large 版本,不适合移动端 |
| ❌ 训练成本高 | 需要大规模数据(如 Kinetics)和多卡 GPU |
| ❌ 对短动作不敏感 | 相比 TSM/TAdaConv,对快速动作建模略慢 |
| ❌ 依赖大量数据 | 小数据集上容易过拟合 |
八、后续发展
VideoSwin 启发了大量后续工作:
| 方法 | 改进点 |
|---|---|
| Video Swin V2 | 更大模型、更长训练、窗口注意力优化 |
| Focal Transformer | 引入多粒度注意力,增强局部建模 |
| VideoMAE | 基于 VideoSwin 的掩码自编码器,自监督学习 |
| UniFormer | 结合 CNN 和 Transformer 的混合架构 |
九、与 SlowFast 对比
| 特性 | SlowFast | VideoSwin |
|---|---|---|
| 主干 | 3D ResNet | 3D Swin Transformer |
| 建模方式 | 卷积 + 双流 | 自注意力 + 移位窗口 |
| 计算效率 | 中等 | 高(局部注意力) |
| 多尺度 | 是(双支路) | 是(层次化) |
| 性能 | 强(~79%) | 更强(~82.8%) |
| 是否适合端侧 | ❌ | ❌(但 Tiny 版可轻量化) |
十、总结
| 项目 | 内容 |
|---|---|
| 🧠 核心思想 | 将 Swin Transformer 扩展到时空域 |
| 📦 输入形式 | 32~64 帧 × 224×224 |
| 🕒 时序建模 | 3D 局部窗口注意力 + 移位机制 |
| ✅ 优点 | 高效、性能强、支持多任务 |
| ❌ 缺点 | 重、训练贵、不适合小数据 |
| 🚀 历史地位 | Transformer 视频理解的标杆模型 |
💬 一句话概括 VideoSwin:
VideoSwin = 3D Patch + 移位窗口注意力 = 高效强大的视频 Transformer
它标志着视频理解从“CNN 时代”正式进入“Transformer 时代”。