Visual acoustic Field,360+X论文解读
目录
一、Visual acoustic Field
1、概述
2、方法
2.1 视觉声音对数据集
2.2 视觉位置预测声音
2.3 根据声音进行空间定位
二、360+X
1、概述
2、方法
一、Visual acoustic Field
1、概述
motivation:由于视觉-声音跨模态问题上,音频一般与整张2D图像或视频配对,无法确定具体物体的声音,也同时缺乏对物体材质、空间位置与声音关联的3D建模。
下图为以往的视听数据信息,缺乏场景级,真实交互,3D建模数据。
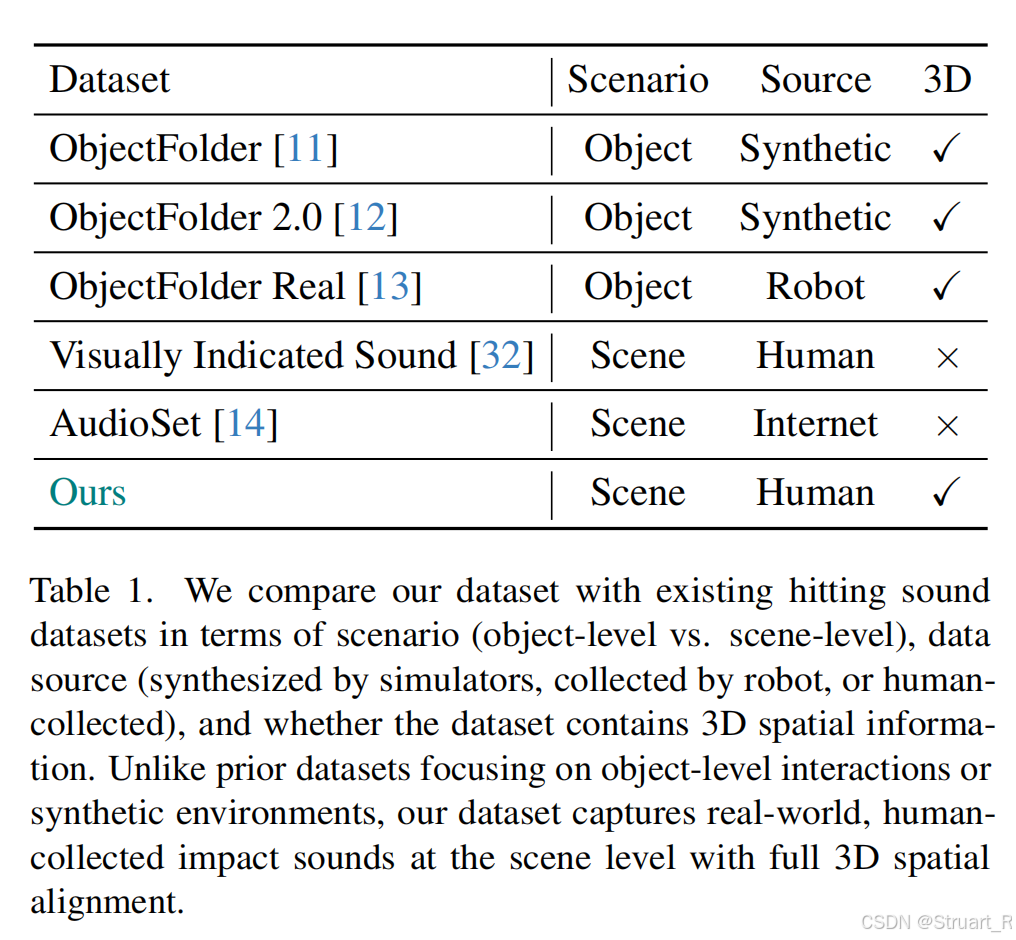
contribution:提出了首个3D场景级视听数据集,场景多视角图像,带标记的敲击图像,敲击声音。统一框架实现对给定位置的声音生成,或者给定声音输出声源位置。

2、方法
2.1 视觉声音对数据集
数据采集
设备:只需手机录制多视角图像和敲击声音。
图像信息:视频抽帧300张图像,覆盖全视角,作为数据集。
敲击图像集:在物体表面贴标记点(贴纸),拍摄标记位置并同步录制敲击声
声音:统一用谱门限法去噪,并截取0.5s有效敲击音频,RMS归一化消除力度差异影响。
数据处理
为了防止单独对图像信息运行COLMAP导致坐标系不一致,所以将图像信息与敲击图像合并到一个集合并输入到COLMAP上,来估计所有相机位姿包括图像信息的和敲击图像集的位姿
。(他这里实验证明,敲击图像集上有一些尺寸小的标记点,对COLMAP的位姿估计影响微乎其微)
利用OWL-v2来检测上的像素坐标
,并通过3DGS预测标记点处深度
。最后利用针孔相机模型计算相机坐标系下3D敲击坐标
。
之后,为了在重建无标记的3D场景,所以只用图像信息I来重建,再用为视角,重新渲染纯净敲击图像集
。
最终数据集为多视角图像,纯净的重渲染无标记敲击图像
,敲击声音,3D敲击位置坐标。
数据集类别
15个场景,包括室内室外场景,并敲击了100多个物体,约2000个视听对。

2.2 视觉位置预测声音
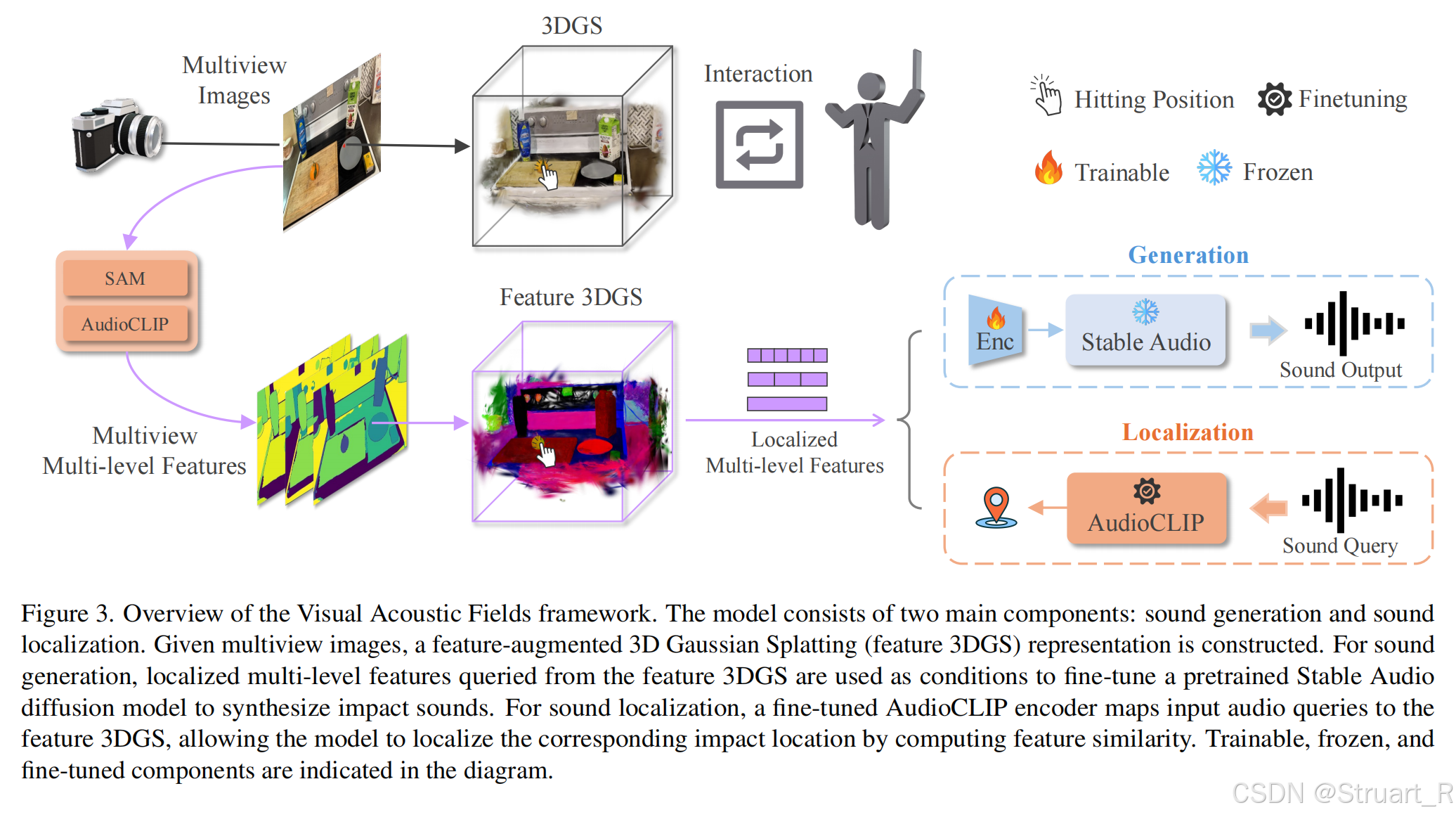
这一部分流程是,3D坐标->定位一个可见敲击视角->feature3DGS渲染特征图->SAM多尺度分割特征图->audioclip对齐到声音特征上,作为条件信息->融合条件,生成相应的声音。
具体来说,(1)输入敲击点3D坐标,先通过计算3D坐标与每个数据集中光心的距离与夹角,筛选可见的视角,并有限选择重渲染后的敲击图像视角。(2)用Feature 3DGS渲染该视角下的特征图。(3)根据特征图用SAM模型实现多层次的特征分割,得到三个尺度的掩码信息。(4)利用AudioCLiP视觉编码器映射为能够与音频对齐的特征向量。(5)将对齐的特征向量作为条件,融合到Stable Audio中来生成声音输出。
当然Stable Audio中没有这么多敲击声音,所以训练中对于以敲击声音为条件的数据集微调了250步。训练中用生成音频与GT音频的频谱损失作为监督。
2.3 根据声音进行空间定位
这一部分你可以理解为langsplat(开放词汇语义查询)的改进,他就是一个开放音频的语义查询,只不过用AudioCLIP替换文本编码器,重新生成每一个场景的语义3DGS。然后利用余弦相似度来进行语义查询。
二、360+X
1、概述
motivation:多数场景理解数据集(如UCF101、Kinetics)仅覆盖单一视角(如第一人称或固定视角),缺乏人类感知世界的多视角协同机制。另外当前的全景数据集(如KITTI-360)忽略音频与空间信息,而视听数据集(如AudioSet)缺乏方位音频与多视角对齐。
contribution:提出了首个全景多模态数据集360+X,包括全景,第三人称,双目、单目第一人称多视角。视频,多通道音频,双耳延时方位信息,GPS定位,场景文本描述多模态。模拟人类真实环境感知方式,通过跨模态互补提升场景理解全面性

2、方法
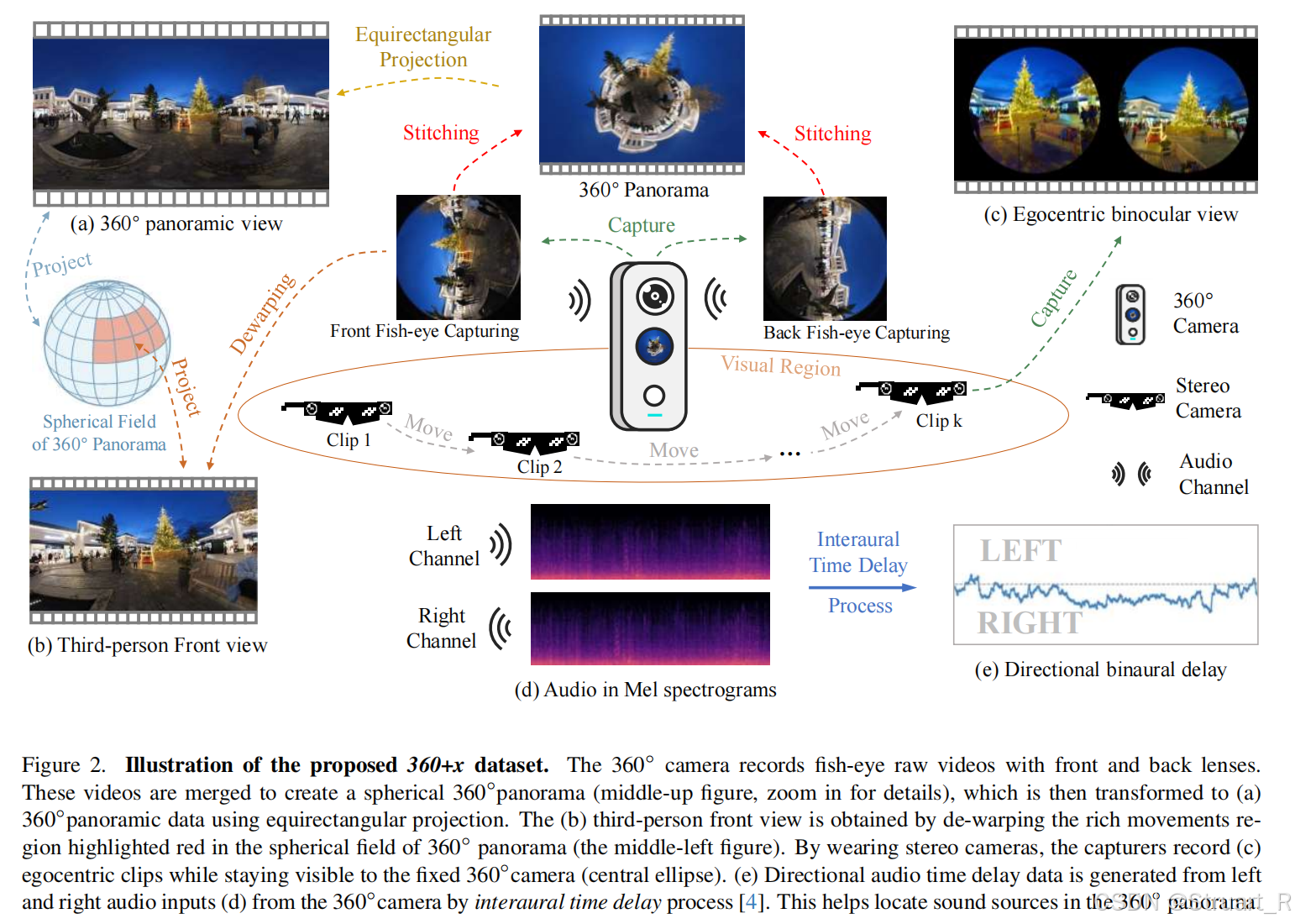
数据采集
-
全景视角:Insta360 One X2相机,双鱼眼镜头生成5760×2880分辨率视频,四麦克风采集方位音频
-
第一人称视角:Snapchat Spectacles 3眼镜,采集2432×1216分辨率双目视频
-
视频处理:鱼眼镜头原始数据→球面全景→等矩形投影→基于光流运动检测的前景区域提取
-
音频处理:通过双耳时间差(ITD) 计算声源方位,与360°视频空间对齐
-
时空对齐:设备近距离放置避免遮挡,时间戳同步多模态数据
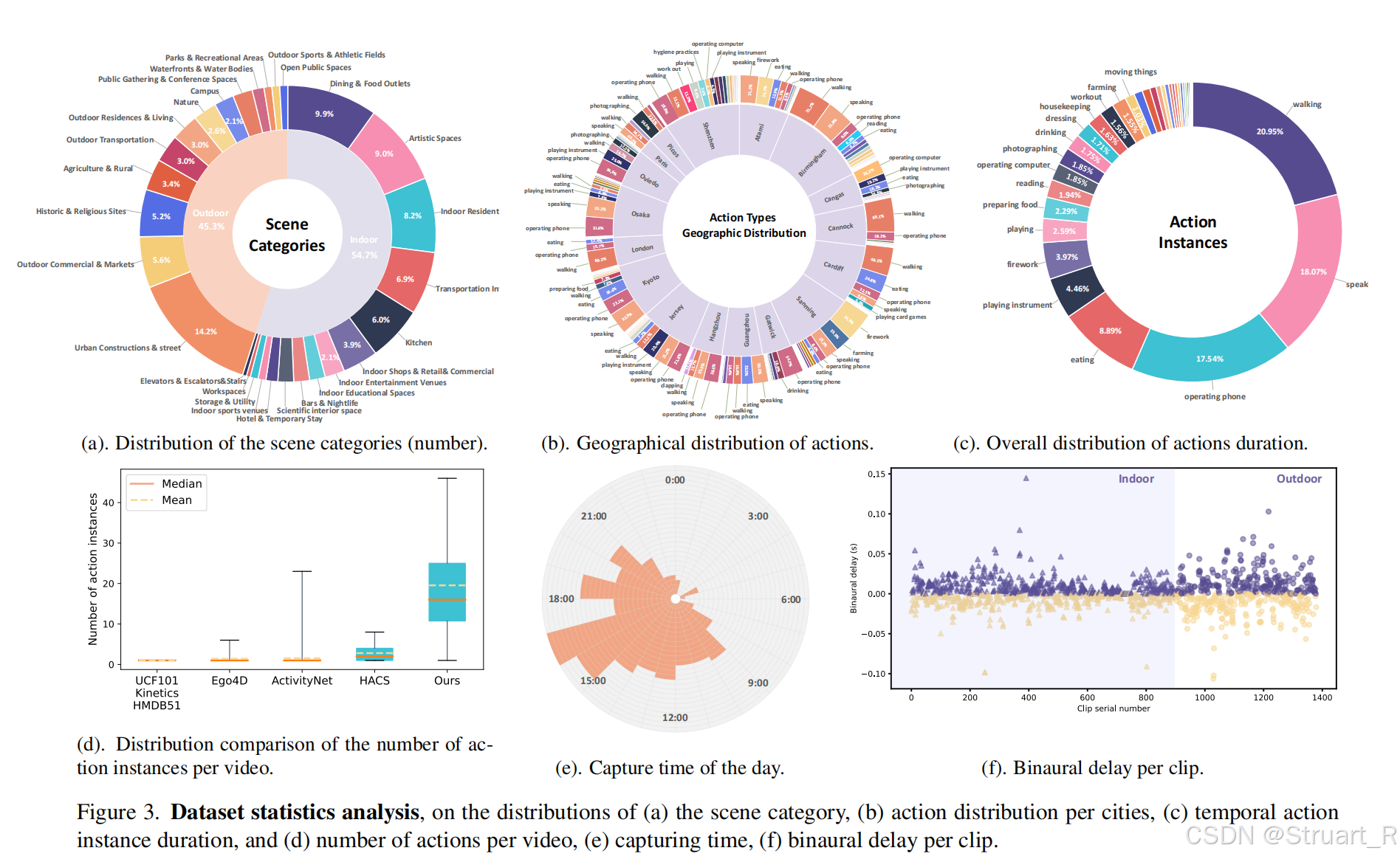
场景标注
覆盖28类场景(15室内+13室外),基于Places Database和语言模型筛选。采集于多国真实环境(中国、日本、欧洲等),包含不同天气/光照条件
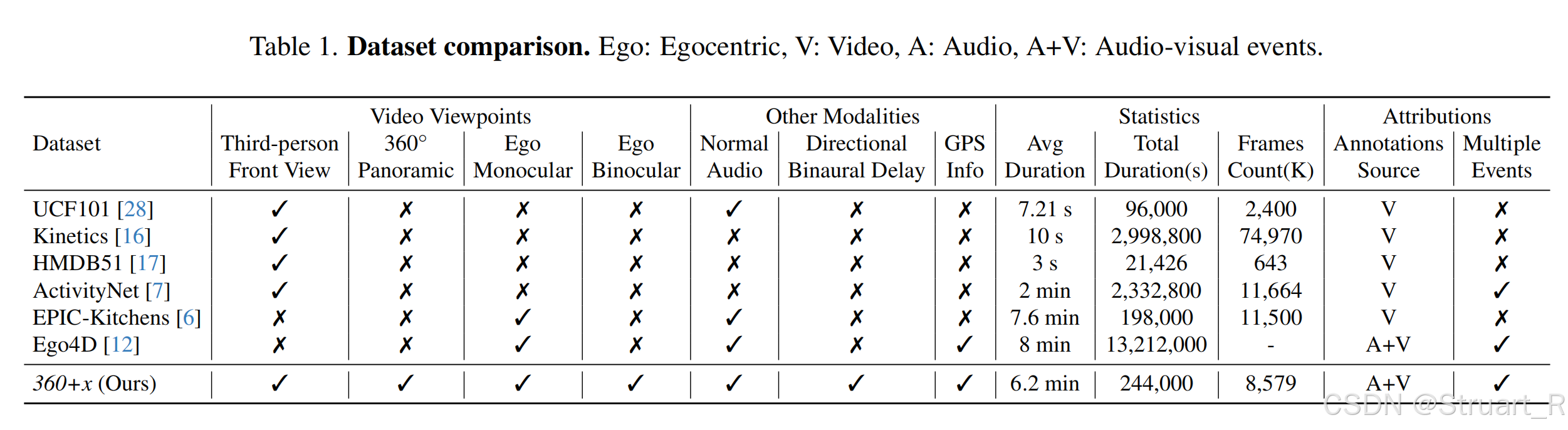
数据对比
应用方向
无死角环境建模,动态物体追踪
声音检索对应场景视频(辅助定位),文本定位视频
感觉用不太上。。
参考论文:
[2404.00989] 360+x: A Panoptic Multi-modal Scene Understanding Dataset
[2503.24270] Visual Acoustic Fields