C语言数据结构——详细讲解《二叉树与堆的基本概念》
C语言数据结构——详细讲解《二叉树与堆的基本概念》
- 前言
- 一、树的基础概念
- 1.1 为什么需要树?
- 1.2 树的定义与结构
- 1.3 树的核心术语
- 1.3 树的核心术语
- 1.4 树的表示方法(孩子兄弟表示法)
- 结构定义
- 为什么用孩子兄弟表示法?
- 1.5 树的实际应用场景
- 二、二叉树的概念与特性
- 2.1 为什么重点研究二叉树?
- 2.2 二叉树的定义与核心特点
- 2.3 特殊的二叉树
- 2.3.1 满二叉树
- 2.3.2 完全二叉树
- 2.4 二叉树的重要性质
- 三、二叉树的存储结构
- 3.1 顺序存储(数组存储)
- 原理
- 示例(完全二叉树的顺序存储)
- 3.2 链式存储(二叉链)
- 原理
- 结构定义(C语言)
- 示例(二叉链结构)
- 四、堆的概念与基础实现
- 4.1 堆是什么?
- 4.2 堆的定义与核心条件
- 4.3 堆的存储(数组顺序存储)
- 示例1:大根堆的数组存储
- 示例2:小根堆的数组存储
前言
- 在上一篇博客中,我们探讨了队列这种线性数据结构,而此前学习的栈也属于线性结构——它们的元素都遵循“一对一”的线性逻辑关系。但在实际场景中,很多数据需要“一对多”的层级关系描述(比如文件系统、部门组织架构),此时线性结构就显得力不从心。
- 今天,我们将进入非线性数据结构的世界,从最基础的“树”入手,逐步聚焦到应用最广泛的“二叉树”,最终讲解一种特殊的二叉树——“堆”。这三者层层递进,是后续学习高级数据结构(如红黑树、B+树)的核心基础。
我的个人主页,欢迎来阅读我的其他文章
https://blog.csdn.net/2402_83322742?spm=1011.2415.3001.5343
我的C语言数据结构专栏
欢迎来阅读指出不足
https://blog.csdn.net/2402_83322742/category_12830540.html?spm=1001.2014.3001.5482
一、树的基础概念
在学习二叉树前,我们必须先理解“树”的本质——它是所有层级结构数据的“通用模型”,而二叉树是树的“简化版”。
1.1 为什么需要树?
假设我们要存储“电脑文件系统”的结构:C盘下有用户和系统两个文件夹,用户下又有文档和图片……

- 如果用数组或链表(线性结构)存储,只能按“C盘→用户→文档→图片→系统”的顺序排列,无法体现“父子文件夹”的层级关系。而树的“一对多”结构,恰好能完美描述这种层级逻辑。
| 树的核心价值:解决“层级数据”的存储与访问问题,弥补线性结构在“一对多”关系中的不足。 |
1.2 树的定义与结构
树是由n(n≥0)个有限结点组成的具有层次关系的集合,满足以下规则:
- 有且仅有一个根结点(如文件系统的“C盘”),根结点没有前驱结点;
- 除根结点外,其余结点被分成
m(m>0)个互不相交的子集(如“用户”“系统”文件夹),每个子集都是一棵独立的“子树”; - 子树之间不能相交(否则就变成了“图”,而非树);
- 一棵有
N个结点的树,必有N-1条边(每个结点除根外,都只通过一条边连接父结点)。

1.3 树的核心术语
树的术语较多,下面我们详细讲解一下
1.3 树的核心术语
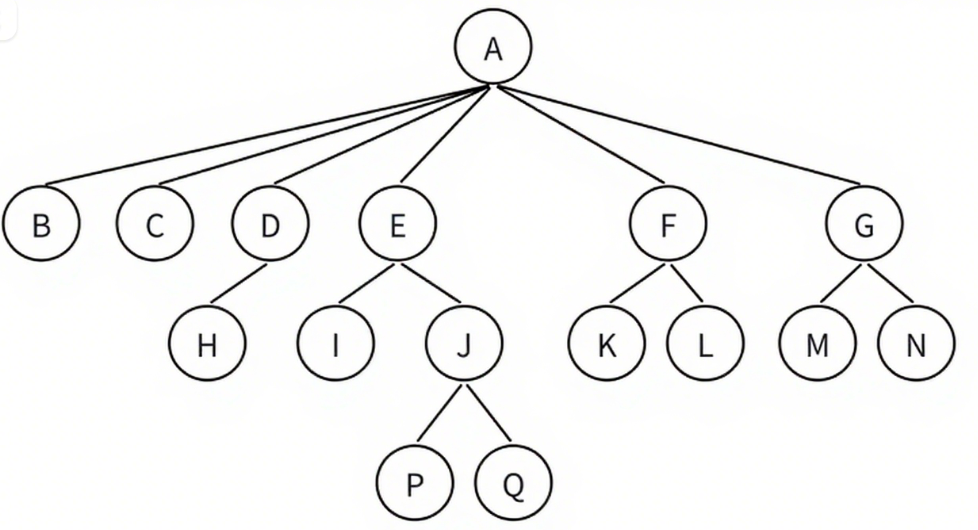
树的术语较多,且需结合具体结构理解,我们以图示的树(根为A,子节点包含B、C、D、E、F、G等)为例,详细讲解:
| 术语 | 定义 | 示例(基于图示树) |
|---|---|---|
| 父结点/双亲 | 含有直接子结点的结点,是子结点的直接上层结点 | A是B、C、D、E、F、G的父结点(A直接包含这6个子结点) |
| 子结点/孩子 | 被父结点直接包含的结点,是父结点的直接下层结点 | B、C、D、E、F、G是A的子结点 |
| 结点的度 | 结点拥有的直接子结点数量(仅统计 immediate child) | A的度为6(有B、C、D、E、F、G共6个直接子结点) |
| 树的度 | 树中所有结点的度的最大值 | 树的度为6(A的度最大,为6) |
| 叶子结点 | 度为0的结点(无任何直接子结点,是树的“最底层终端结点”) | B、C、H、K、L、M、N、P、Q(这些结点没有子结点) |
| 分支结点 | 度不为0的结点(非叶子结点,可继续延伸子树) | A、D、E、F、G、J(这些结点有直接子结点) |
| 兄弟结点 | 拥有相同父结点的结点 | B、C、D、E、F、G互为兄弟结点(它们的父结点都是A) |
| 结点的层次 | 从根开始计数,根为第1层,子结点为第2层,依此类推 | A在第1层;B、C在第2层;H、I在第3层;P、Q在第4层 |
| 树的高度/深度 | 树中结点的最大层次(从根到最底层叶子的最长路径的层数) | 树的高度为4(最底层结点P、Q在第4层) |
| 祖先 | 从根结点到该结点的路径上的所有结点 | P的祖先是A、E、J(路径:A→E→J→P) |
| 子孙 | 以该结点为根的子树中的所有结点(包括间接子结点) | E的子孙是I、J、P、Q(E的子树包含这些结点) |
| 森林 | m(m>0)棵互不相交的树的集合(多棵独立树的组合) | 若“以B为根的树”和“以C为根的树”相互独立,则它们组成森林 |
1.4 树的表示方法(孩子兄弟表示法)
树的存储需要同时保存“结点值”和“结点间的层次关系”,常用的是孩子兄弟表示法
结构定义
// 树的孩子兄弟表示法结点结构
typedef struct TreeNode {int data; // 结点存储的数据struct TreeNode* firstChild; // 指向该结点的“第一个子结点”(左起第一个)struct TreeNode* nextBrother; // 指向该结点的“下一个兄弟结点”(同一父结点的右侧兄弟)
} TreeNode;
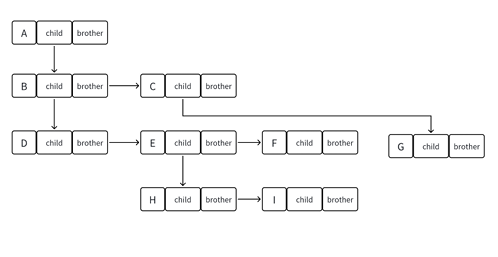
为什么用孩子兄弟表示法?
- 优点:只需两个指针(
firstChild和nextBrother),就能表示任意结构的树;且能将树“转化为二叉树”(把“兄弟关系”当作二叉树的“右子树”),后续可复用二叉树的操作逻辑。 - 示例:若结点B有子结点E、F,且B的兄弟是C,则
B->firstChild = E,E->nextBrother = F,B->nextBrother = C。
1.5 树的实际应用场景
- 文件系统:根目录(根结点)→ 文件夹(分支结点)→ 文件(叶子结点);
- 组织架构:CEO(根结点)→ 部门总监(分支结点)→ 员工(叶子结点);
- 数据库索引:B树、B+树(基于树结构实现高效查询)。
二、二叉树的概念与特性
树的结构灵活但复杂,而二叉树是树中最简单、最常用的类型——它限制了结点的度不超过2,大大降低了操作难度,且任意树都能转换为二叉树。
2.1 为什么重点研究二叉树?
既然树能表示任意层级关系,为什么还要专门学二叉树?答案是**“trade-off(权衡)”**:
- 树的结点度可以是任意值(如一个结点有100个子结点),导致操作逻辑(如遍历、插入)非常复杂;
- 二叉树限制“结点度≤2”,且子树有“左、右之分”(有序),操作逻辑统一,易于实现;
- 关键:任意树都能通过“孩子兄弟表示法”转换为二叉树,学会二叉树就相当于掌握了所有树的核心操作。
2.2 二叉树的定义与核心特点
二叉树是结点的有限集合,满足:
- 集合为空(空二叉树);
- 由一个根结点 + 一棵“左子树” + 一棵“右子树”组成,且左、右子树均为二叉树;
- 核心约束:
- 结点的度≤2(最多有2个孩子:左孩子、右孩子);
- 子树有“左右次序”(左子树和右子树颠倒后,是不同的二叉树)。
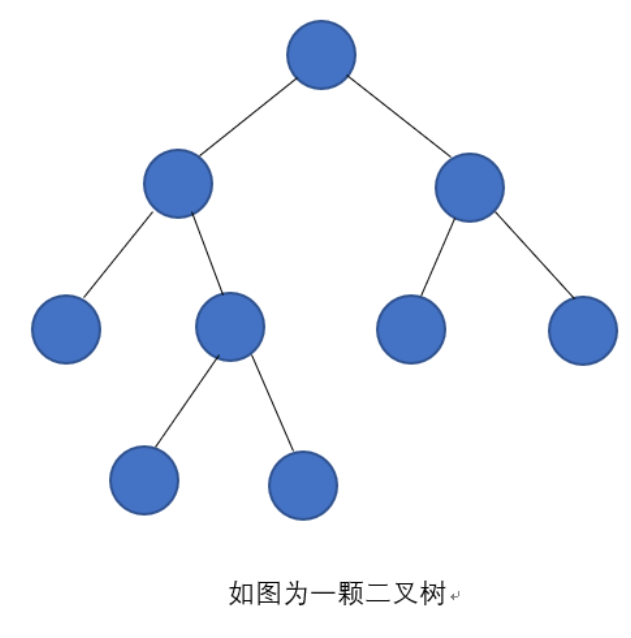
2.3 特殊的二叉树
二叉树中最常用的两种特殊类型是“满二叉树”和“完全二叉树”,后者是堆的基础。
2.3.1 满二叉树
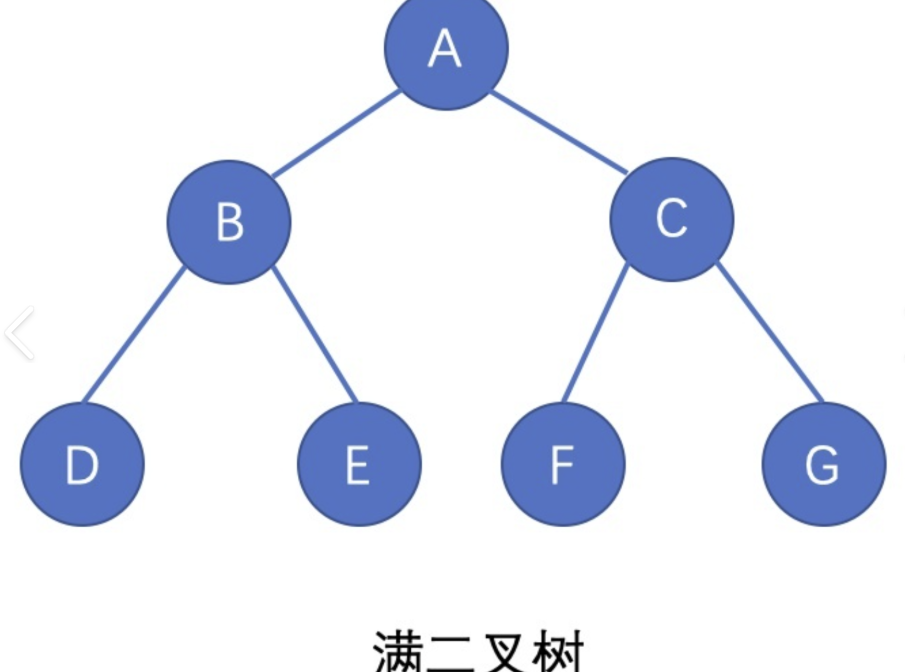
- 定义:每一层的结点数都达到最大值的二叉树(即第k层有2^(k-1)个结点)。
- 公式:若满二叉树的层数为h,则总结点数为
2^h - 1(等比数列求和:1+2+4+…+2^(h-1) = 2^h -1)。 - 示例:h=3的满二叉树,总结点数=2^3 -1=7(第1层1个,第2层2个,第3层4个)。
2.3.2 完全二叉树
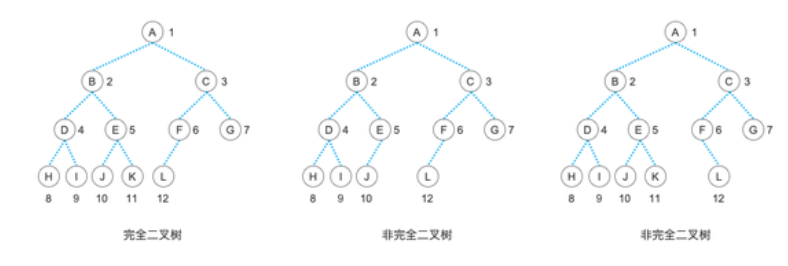
- 定义:深度为h、有n个结点的二叉树,若其结点与“深度为h的满二叉树”中编号1~n的结点一一对应(编号从根开始,从上到下、从左到右),则为完全二叉树。
- 核心特点:
- 叶子结点只能出现在最后两层;
- 最后一层的叶子结点必须从左到右连续排列(不能有“左边空、右边有”的情况);
- 满二叉树是“特殊的完全二叉树”(n=2^h -1时,完全二叉树就是满二叉树)。
| 关键区别:满二叉树要求“每一层都满”,完全二叉树只要求“最后一层左连续”——完全二叉树更灵活,且适合用数组存储(无空间浪费)。 |
2.4 二叉树的重要性质
以下性质基于“根结点层数为1”的规则,是后续堆操作的数学基础:
- 第i层最多结点数:若根为第1层,则第i层最多有
2^(i-1)个结点(如第1层1=2^0 ,第2层2=2^1, 第3层4=2^2); - 深度h的最大结点数:深度为h的二叉树,最多有
2^h -1个结点(即满二叉树的结点数公式); - 叶子结点与分支结点关系:对任意非空二叉树,若叶子结点数为n0,度为2的结点数为n2,则必有
n0 = n2 + 1(推导:总边数=总结点数-1,且边数= n11 + n22,总结点数= n0 + n1 + n2,联立得n0 = n2 +1); - 完全二叉树的父/子索引关系:若完全二叉树用数组存储(索引从0开始),则序号为i的结点:
- 父结点序号:
(i-1)/2(整数除法,如i=1的父结点是0,i=2的父结点是0); - 左孩子序号:
2*i + 1(若2*i+1 < 总结点数,则存在左孩子); - 右孩子序号:
2*i + 2(若2*i+2 < 总结点数,则存在右孩子)。
- 父结点序号:
三、二叉树的存储结构
二叉树有两种存储方式,分别对应不同的应用场景:
3.1 顺序存储(数组存储)
原理
用数组存储二叉树的结点,结点的位置(索引)由其在完全二叉树中的编号决定(参考“完全二叉树的父/子索引关系”)。
- 适合场景:完全二叉树(无空间浪费);
- 不适合场景:非完全二叉树(空结点需占用数组位置,空间利用率低)。
示例(完全二叉树的顺序存储)
若完全二叉树结点为[A, B, C, D, E, F](根为A,左子树B、D、E,右子树C、F),数组存储如下:
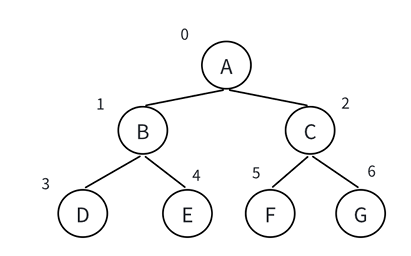
| 数组索引 | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| 结点值 | A | B | C | D | E | F |
- A(0)的左孩子是B(1=20+1),右孩子是C(2=20+2);
- B(1)的左孩子是D(3=21+1),右孩子是E(4=21+2);
- C(2)的左孩子是F(5=22+1),右孩子不存在(22+2=6 ≥ 总结点数6)。
3.2 链式存储(二叉链)
原理
用链表存储二叉树,每个结点包含“数据域”和两个“指针域”(分别指向左孩子和右孩子),称为“二叉链”。
- 适合场景:所有二叉树(尤其是非完全二叉树,无空间浪费,灵活);
- 缺点:无法像数组那样随机访问,需通过指针遍历。
结构定义(C语言)
// 二叉树的链式存储(二叉链)
typedef struct BinaryTreeNode {int data; // 结点数据struct BinaryTreeNode* leftChild; // 指向左孩子的指针struct BinaryTreeNode* rightChild; // 指向右孩子的指针
} BTNode;
示例(二叉链结构)
对于结点[A, B, C, D](A的左是B,右是C;B的左是D),二叉链的结构为:
A
├─ leftChild → B
│ ├─ leftChild → D
│ └─ rightChild → NULL
└─ rightChild → C├─ leftChild → NULL└─ rightChild → NULL
四、堆的概念与基础实现
堆是特殊的完全二叉树,也是二叉树顺序存储的典型应用(如优先队列、堆排序)
4.1 堆是什么?
我们已经有了完全二叉树,为什么还要定义“堆”?因为堆在“快速获取最大值/最小值”场景中效率极高——堆的根结点永远是“最大值(大堆)”或“最小值(小堆)”,无需遍历整个树就能获取极值。
4.2 堆的定义与核心条件
堆是满足以下两个条件的完全二叉树:
- 结构条件:堆必须是一棵完全二叉树(保证可以用数组顺序存储,无空间浪费);
- 值条件(堆序性):
- 大堆:每个父结点的值 ≥ 其左右子结点的值(根是最大值);
- 小堆:每个父结点的值 ≤ 其左右子结点的值(根是最小值)。
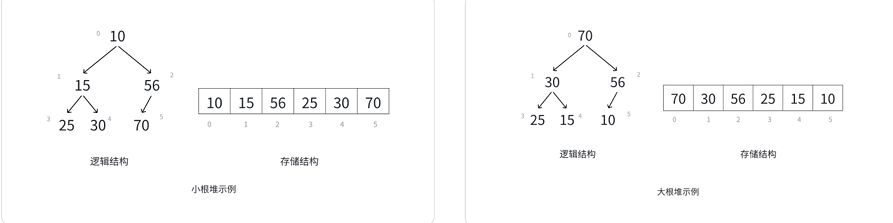
4.3 堆的存储(数组顺序存储)
堆是完全二叉树,因此用数组存储最高效(无需额外指针,仅通过索引即可推导父子关系)。存储规则与完全二叉树一致,核心依赖“父、左孩子、右孩子的索引推导”:
- 数组索引从
0开始; - 对于序号为
i的结点,可通过公式快速找到其亲属结点:- 父结点索引:
(i - 1) / 2(整数除法,向下取整); - 左孩子索引:
2 * i + 1(若计算结果< 堆的元素个数,则左孩子存在); - 右孩子索引:
2 * i + 2(若计算结果< 堆的元素个数,则右孩子存在)。
- 父结点索引:
示例1:大根堆的数组存储
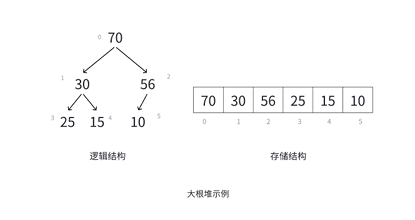
大根堆的逻辑结构:根结点为70,左子结点30,右子结点56;30的左子结点25、右子结点15;56的右子结点10。
其数组存储结构为 [70, 30, 56, 25, 15, 10](数组索引0~5对应元素),各结点的亲属关系推导如下:
| 数组索引 | 结点值 | 父结点(索引/值) | 左孩子(索引/值) | 右孩子(索引/值) |
|---|---|---|---|---|
| 0 | 70 | 无(根结点) | 2*0+1=1 / 30 | 2*0+2=2 / 56 |
| 1 | 30 | (1-1)/2=0 / 70 | 2*1+1=3 / 25 | 2*1+2=4 / 15 |
| 2 | 56 | (2-1)/2=0 / 70 | 2*2+1=5 / 10 | 无(2*2+2=6 ≥ 元素个数6) |
| 3 | 25 | (3-1)/2=1 / 30 | 无(2*3+1=7 ≥ 6) | 无(2*3+2=8 ≥ 6) |
| 4 | 15 | (4-1)/2=1 / 30 | 无(2*4+1=9 ≥ 6) | 无(2*4+2=10 ≥ 6) |
| 5 | 10 | (5-1)/2=2 / 56 | 无(2*5+1=11 ≥ 6) | 无(2*5+2=12 ≥ 6) |
示例2:小根堆的数组存储
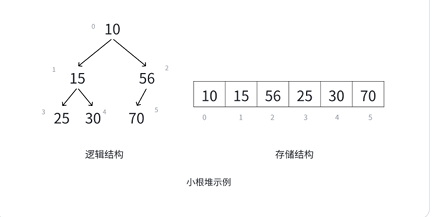
小根堆的逻辑结构:根结点为10,左子结点15,右子结点56;15的左子结点25、右子结点30;56的右子结点70。
其数组存储结构为 [10, 15, 56, 25, 30, 70](数组索引0~5对应元素),亲属关系推导更能体现“小根堆父结点≤子结点”的特性:
| 数组索引 | 结点值 | 父结点(索引/值) | 左孩子(索引/值) | 右孩子(索引/值) |
|---|---|---|---|---|
| 0 | 10 | 无(根结点) | 2*0+1=1 / 15 | 2*0+2=2 / 56 |
| 1 | 15 | (1-1)/2=0 / 10 | 2*1+1=3 / 25 | 2*1+2=4 / 30 |
| 2 | 56 | (2-1)/2=0 / 10 | 2*2+1=5 / 70 | 无(2*2+2=6 ≥ 6) |
| 3 | 25 | (3-1)/2=1 / 15 | 无(2*3+1=7 ≥ 6) | 无(2*3+2=8 ≥ 6) |
| 4 | 30 | (4-1)/2=1 / 15 | 无(2*4+1=9 ≥ 6) | 无(2*4+2=10 ≥ 6) |
| 5 | 70 | (5-1)/2=2 / 56 | 无(2*5+1=11 ≥ 6) | 无(2*5+2=12 ≥ 6) |
我的个人主页,欢迎来阅读我的其他文章
https://blog.csdn.net/2402_83322742?spm=1011.2415.3001.5343
我的C语言数据结构专栏
欢迎来阅读指出不足
https://blog.csdn.net/2402_83322742/category_12830540.html?spm=1001.2014.3001.5482
| 非常感谢您的阅读,喜欢的话记得三连哦 |
