UDP-Server(2)词典功能
简单说明
上一篇文章中,我们讲了echo-server,也就是第一版的udp-server代码,它基本上没有实现什么业务,我们就只是将客户端发送给服务器的数据传回给客户端,这回,我们将在原有的基础上引入词典功能。
我们的词典只是简单版本的词典,重要的是感受引入业务的过程。
代码展示
首先,我将几个必要的头文件代码展示出来,由于这几个头文件的代码与上一篇文章是一模一样的,所以我这里就不过多讲解了,我将核心放在我们业务处理上
网络地址类的封装 InetAddr.hpp
#pragma once#include <iostream> #include <string> #include <sys/types.h> #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h>// 封装网络地址类 class InetAddr { private:void ToHost(const struct sockaddr_in &addr){_port = ntohs(addr.sin_port);_ip = inet_ntoa(addr.sin_addr);}public:InetAddr(const struct sockaddr_in &addr): _addr(addr){ToHost(addr); // 将addr进行转换}std::string Ip(){return _ip;}uint16_t Port(){return _port;}~InetAddr(){}private:std::string _ip;uint16_t _port;struct sockaddr_in _addr; };日志类 Log.hpp
#pragma once#include <iostream> #include <string> #include <unistd.h> #include <sys/types.h> #include <ctime> #include <stdarg.h> #include <fstream> #include <string.h> #include <pthread.h>namespace log_ns {enum{DEBUG = 1,INFO,WARNING,ERROR,FATAL};std::string LevelToString(int level){switch (level){case DEBUG:return "DEBUG";case INFO:return "INFO";case WARNING:return "WARNING";case ERROR:return "ERROR";case FATAL:return "FATAL";default:return "UNKNOW";}}std::string GetCurrTime(){time_t now = time(nullptr);struct tm *curr_time = localtime(&now);char buffer[128];snprintf(buffer, sizeof(buffer), "%d-%02d-%02d %02d:%02d:%02d",curr_time->tm_year + 1900,curr_time->tm_mon + 1,curr_time->tm_mday,curr_time->tm_hour,curr_time->tm_min,curr_time->tm_sec);return buffer;}class logmessage{public:std::string _level;pid_t _id;std::string _filename;int _filenumber;std::string _curr_time;std::string _message_info;};#define SCREEN_TYPE 1#define FILE_TYPE 2const std::string glogfile = "./log.txt";pthread_mutex_t glock = PTHREAD_MUTEX_INITIALIZER;class Log{public:Log(const std::string &logfile = glogfile) : _logfile(logfile), _type(SCREEN_TYPE){}void Enable(int type){_type = type;}void FlushLogToScreen(const logmessage &lg){printf("[%s][%d][%s][%d][%s] %s",lg._level.c_str(),lg._id,lg._filename.c_str(),lg._filenumber,lg._curr_time.c_str(),lg._message_info.c_str());}void FlushLogToFile(const logmessage &lg){std::ofstream out(_logfile, std::ios::app);if (!out.is_open())return;char logtxt[2048];snprintf(logtxt, sizeof(logtxt), "[%s][%d][%s][%d][%s] %s",lg._level.c_str(),lg._id,lg._filename.c_str(),lg._filenumber,lg._curr_time.c_str(),lg._message_info.c_str());out.write(logtxt, strlen(logtxt));out.close();}void FlushLog(const logmessage &lg){pthread_mutex_lock(&glock);switch (_type){case SCREEN_TYPE:FlushLogToScreen(lg);break;case FILE_TYPE:FlushLogToFile(lg);break;}pthread_mutex_unlock(&glock);}void logMessage(std::string filename, int filenumber, int level, const char *format, ...){logmessage lg;lg._level = LevelToString(level);lg._id = getpid();lg._filename = filename;lg._filenumber = filenumber;lg._curr_time = GetCurrTime();va_list ap;va_start(ap, format);char log_info[1024];vsnprintf(log_info, sizeof(log_info), format, ap);va_end(ap);lg._message_info = log_info;// 打印出日志FlushLog(lg);}~Log(){}private:int _type;std::string _logfile;};Log lg;#define LOG(level, Format, ...) do {lg.logMessage(__FILE__, __LINE__, level, Format, ##__VA_ARGS__); }while (0)#define EnableScreen() do {lg.Enable(SCREEN_TYPE);}while(0)#define EnableFile() do {lg.Enable(FILE_TYPE);}while(0) }防拷贝类 nocopy.hpp
#pragma once// 防拷贝 class nocopy { public:nocopy() {}~nocopy() {}nocopy(const nocopy &) = delete;const nocopy &operator=(const nocopy &) = delete; };接下来就是我们的核心部分了:
我们先来说字典类Dict.hpp
#pragma once#include <iostream> #include <string> #include <fstream> #include <unistd.h> #include <unordered_map> #include "Log.hpp"using namespace log_ns;const static std::string sep = ": ";class Dict { private:void LoadDict(const std::string &path){std::ifstream in(path);if (!in.is_open()){LOG(FATAL, "open %s failed!\n", path.c_str());exit(1);}std::string line;while (std::getline(in, line)){LOG(DEBUG, "load info: %s ,success\n", line.c_str());if (line.empty())continue;auto pos = line.find(sep);if (pos == std::string::npos)continue;std::string key = line.substr(0, pos);if (key.empty())continue;std::string value = line.substr(pos + sep.size());if (value.empty())continue;_dict.insert(std::make_pair(key, value));}LOG(INFO, "load %s done\n", path.c_str());in.close();}public:Dict(const std::string &dict_path): _dict_path(dict_path){LoadDict(_dict_path);}std::string Translate(std::string word){if (word.empty())return "None";auto iter = _dict.find(word);if (iter == _dict.end())return "None";elsereturn iter->second;}~Dict(){}private:std::unordered_map<std::string, std::string> _dict;std::string _dict_path; };这个类就是我们的业务逻辑,它充当翻译部分的模块。那么,我们怎么实现翻译呢?想要实现翻译得先有翻译对照的文本吧,这里我们简单点就用文件形式来先模拟翻译的手段。
dict.txt文本文件
# 一、家庭生活 父亲: Father 母亲: Mother 儿子: Son 女儿: Daughter 丈夫: Husband 妻子: Wife 祖父: Grandfather 祖母: Grandmother 孙子: Grandson 孙女: Granddaughter 兄弟: Brother 姐妹: Sister 阿姨: Aunt 叔叔: Uncle 堂/表兄弟姐妹: Cousin 家: Home 卧室: Bedroom 客厅: Living room 厨房: Kitchen 卫生间: Bathroom 阳台: Balcony 地下室: Basement 家具: Furniture 床: Bed 沙发: Sofa 衣柜: Wardrobe 书桌: Desk 书架: Bookshelf 台灯: Desk lamp 窗帘: Curtain 地毯: Carpet 闹钟: Alarm clock 遥控器: Remote control 吸尘器: Vacuum cleaner 拖把: Mop 扫帚: Broom 垃圾桶: Trash can 清洁剂: Cleaner 肥皂: Soap 洗发水: Shampoo 牙膏: Toothpaste 毛巾: Towel 卫生纸: Toilet paper 洗衣篮: Laundry basket 。。。。。。。。。我总共填入了上百个单词的汉译英对照,我就展示一部分。至于为什么要展示这个文件呢?是因为我们要能够规定出一个协议,就是“:”这组符号,当用户输入一个中文要查对应的英文时,我们的服务器要以“:”为分割将找到的内容正确返回给客户端。
这条代码的作用也就是在这里。
我们的成员变量有这两位就够了,第一个哈希表结构体的变量是用来存我们的汉语跟对应英语的对照关系的,第二个变量是存放我们的要导入的字典文件地址。
构造这一块我们得使用带参构造,这是因为我们必须得知道我们的字典文件在哪,这是由我们的上层服务器去处理填入的。将地址初始化好之后我们就要加载字典了,这里我们专门将这个功能拿出来实现。
void LoadDict(const std::string &path){std::ifstream in(path);if (!in.is_open()){LOG(FATAL, "open %s failed!\n", path.c_str());exit(1);}std::string line;while (std::getline(in, line)){LOG(DEBUG, "load info: %s ,success\n", line.c_str());if (line.empty())continue;auto pos = line.find(sep);if (pos == std::string::npos)continue;std::string key = line.substr(0, pos);if (key.empty())continue;std::string value = line.substr(pos + sep.size());if (value.empty())continue;_dict.insert(std::make_pair(key, value));}LOG(INFO, "load %s done\n", path.c_str());in.close();}这里我们专门用C++的输入文件流来打开文件。这个代码大家可能见的少,我解释一下:
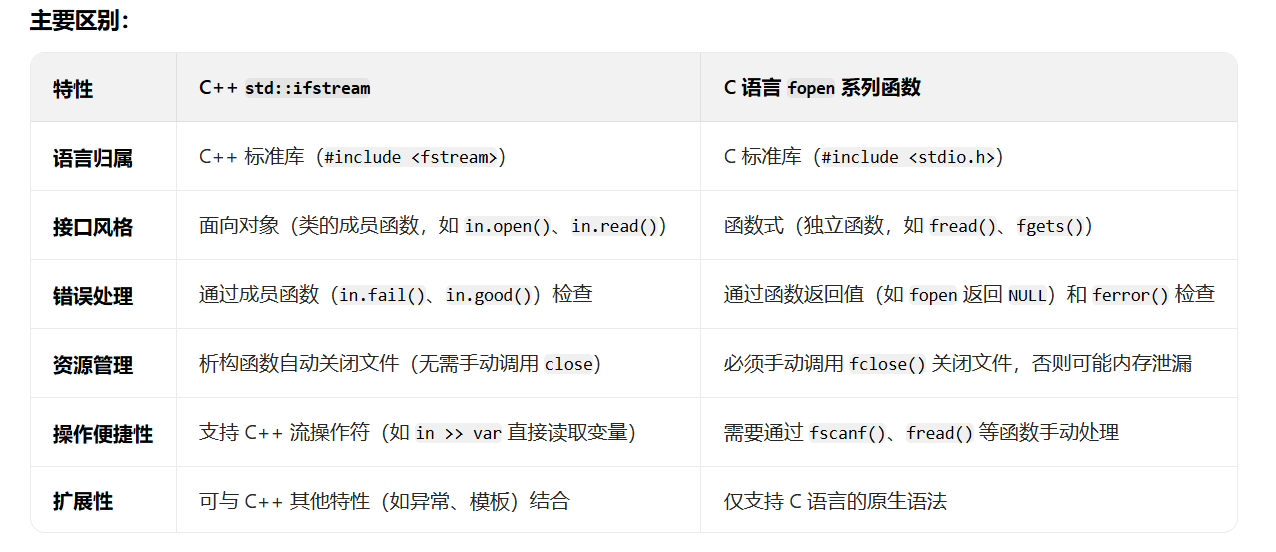
std::ifstream in(path);和 C 语言的fopen等文件操作在核心功能上是一致的,都是用于打开文件并进行读取操作,但它们分属不同的语言标准库,在使用方式和特性上有明显区别。相似之处:
核心功能一致:两者的根本目的都是打开指定路径的文件,并提供读取文件内容的能力。
std::ifstream是 C++ 标准库中用于输入文件流的类,默认以 “只读” 模式打开文件(类似 C 语言的"r"模式)。fopen是 C 语言标准库的函数,通过指定模式(如"r"表示只读)打开文件,返回FILE*指针用于后续操作。都需要处理文件路径:两者都需要传入文件路径(如
path)来指定要操作的文件。都可能失败:如果文件不存在、权限不足等,两者都会打开失败,需要检查错误状态。
我们回到代码讲解,由于我们的ifstream对象在填入地址的情况下会自动打开文件,所以这里我们只需要判断,如果打开失败就结束程序,成功就继续。接下来就是将字典加载到我们的哈希表里了,我们以行读取方式获取每一行,如果这一行为空行我们就跳过它,不做处理,如果不是空行我们就找我们的“:”标志,找不到说明这一行不是我们要找的信息,我们也跳过这一行信息,如果是,我们就提取汉字部分填入哈希表的键,将英语部分填入到我们的值,如果没有英语部分,说明这行信息也有问题,我们也跳过。
在加载完之后也来到了我们的翻译模块,这个就简单了,对照哈希表去找,找到就返回单词,找不到就返回none。
我们再来讲解我们的客户端部分 UdpClientMain.cc
我们的客户端程序只需要写一个源文件就可以了,因为客户端在我们本次的项目中只充当了一个发送用户写的数据,然后将服务器端发回的数据传回并打印就可以了。由于业务较简单,所以我们只需一个源文件就可以了。
#include <iostream> #include <string> #include <cstring> #include <unistd.h> #include <sys/types.h> #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h>// 客户端未来一定要知道服务器的IP地址和端口号 // ./udpclient 127.0.0.1 8888 int main(int argc, char *argv[]) {if (argc != 3){std::cerr << "Usage: " << argv[0] << "server-ip server-port" << std::endl;exit(0);}std::string serverip = argv[1];uint16_t serverport = std::stoi(argv[2]);int sockfd = ::socket(AF_INET, SOCK_DGRAM, 0);if (sockfd < 0){std::cerr << "create socket error" << std::endl;exit(1);}// client 的端口号,一般不让用户自己设定,而是让client OS随机选择?怎么选择,什么时候选择呢?// client 需要bind它自己的IP和端口,但是client不需要“显示”bind它自己的IP和端口// client 在首次向服务器发送数据的时候,OS会自动给client bind它自己的IP和端口struct sockaddr_in server;memset(&server, 0, sizeof(server));server.sin_family = AF_INET;server.sin_port = htons(serverport);server.sin_addr.s_addr = inet_addr(serverip.c_str());while (1){std::string line;std::cout << "Please Enter# ";std::getline(std::cin, line);int n = sendto(sockfd, line.c_str(), line.size(), 0, (struct sockaddr *)&server, sizeof(server));if (n > 0){struct sockaddr_in temp;socklen_t len = sizeof(temp);char buffer[1024];int m = recvfrom(sockfd, buffer, sizeof(buffer) - 1, 0, (struct sockaddr *)&temp, &len);if (m > 0){buffer[m] = 0;std::cout << buffer << std::endl;}else{std::cout << "recvfrom error" << std::endl;break;}}else{std::cout << "sendto error" << std::endl;break;}}::close(sockfd);return 0; }还是跟我们第一版本的udpserver一样,我们客户端未来一定要知道服务器的IP地址和端口号,所以我们要设置3个参数指令,如果用户少输了,我们就需要打印我们的参数格式提醒用户,如果没问题,我们就可以进行下一步了。
我们得先获得ip地址和端口号,这基本上是一个模板的编写操作,获取后,我们就需要创建sockfd了。
三个参数分别对应:
AF_INET:指定地址族为 IPv4(AF是 Address Family 的缩写)。如果需要 IPv6,可使用AF_INET6。SOCK_DGRAM:指定套接字类型为数据报套接字,对应UDP 协议(无连接、不可靠、面向数据报的通信)。如果需要 TCP 协议(面向连接、可靠),则使用SOCK_STREAM。0:指定协议。当type明确时(如SOCK_DGRAM只能对应 UDP),设为0表示让系统自动选择该类型对应的默认协议(此处会自动选择IPPROTO_UDP)。返回值
sockfd
- 函数执行成功时,返回一个非负整数(称为 “套接字描述符”,类似文件描述符),后续的网络操作(如绑定、发送、接收)都通过这个描述符进行。
- 失败时返回
-1,并设置全局变量errno表示错误原因(如权限不足、系统资源耗尽等)。在这里我们要不要像服务器端一样,自己设置端口号进行绑定呢?答案是不用的,因为我们的操作系统会自动随机分配给客户端一个端口号,记住区别,我们只是不需要手动设置端口号,但不代表我们的客户端sockfd不需要绑定端口号,我们的客户端跟服务器端一样都是需要绑定ip跟端口号的。当客户端首次像服务器端发送数据的时候,我们的操作系统就会自动绑定好ip跟端口号。
接下来我们就需要初始化一个 IPv4 地址结构体(
struct sockaddr_in),用于在网络编程中描述服务器的地址信息(IP 地址和端口号),为后续的socket绑定(bind)或连接(connect)操作做准备。首先声明结构体变量server,接着用memset将其所有字节清零,避免残留垃圾值影响后续操作;然后设置地址族为AF_INET(表示使用 IPv4 协议),确保与创建 socket 时的协议一致;再通过htons将主机字节序的端口号serverport转换为网络字节序(大端序),存入sin_port成员;最后用inet_addr将字符串形式的 IP 地址serverip转换为 32 位网络字节序整数,存入sin_addr.s_addr。初始化后的结构体可用于socket的绑定(bind)或连接(connect)等操作,是网络编程中描述服务器地址的标准方式。处理完这些先前条件之后,我们就可以开始我们的业务了,我们的客户端的功能是获取用户的数据,发送给服务器,再接收服务器的数据打印出来。逻辑有了,我们就可以开始写代码。我们这里采用按行获取用户填入的数据,再将数据发送给我们的服务器,sockaddr_in里面就包含了服务器端的地址信息,操作系统就会根据这个信息找到服务器。
如果发送成功,我们就可以接受数据,接收到了,我们就可以打印出来了。
接下来我们再来看看服务器端
UdpServer.hpp#pragma once#include <iostream> #include <unistd.h> #include <string> #include <cstring> #include <sys/types.h> #include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h>#include "nocopy.hpp" #include "Log.hpp" #include "InetAddr.hpp" #include <functional>using namespace log_ns; // 打开日志的命名空间static const int gsocketfd = -1; // default socket套接字文件描述符 static const uint16_t glocalport = 8888; // default 端口号enum {SOCKET_ERROR = 1,BIND_ERROR };using func_t = std::function<std::string(std::string)>;// UdpServer user("192.1.1.1",8888); // 一般服务器主要是用来进行网络数据读取和写入的。IO的。 // 服务器 IO逻辑 和 业务逻辑 解耦 class UdpServer : public nocopy { public:// UdpServer(const std::string &localip, uint16_t localport = glocalport)UdpServer(func_t func, uint16_t localport = glocalport): _func(func), _socketfd(gsocketfd), _localport(localport), _isrunning(false){}void InitServer(){// 1.创建socket文件_socketfd = ::socket(AF_INET, SOCK_DGRAM, 0); // AF_INET网络通信方式创建,SOCK_DGRAM udp协议if (_socketfd < 0){LOG(FATAL, "socket error\n");exit(SOCKET_ERROR);}LOG(DEBUG, "socket create success,_sockfd: %d\n", _socketfd);// 2.bindstruct sockaddr_in local;memset(&local, 0, sizeof(local));local.sin_family = AF_INET;local.sin_port = htons(_localport);// local.sin_addr.s_addr = inet_addr(_localip.c_str());//需要4字节、需要网络序列的iplocal.sin_addr.s_addr = INADDR_ANY; // 服务器端,进行任意ip地址绑定0int n = ::bind(_socketfd, (struct sockaddr *)&local, sizeof(local));if (n < 0){LOG(FATAL, "bind error\n");exit(BIND_ERROR);}LOG(DEBUG, "socket bind success\n");}void Start(){_isrunning = true;char inbuffer[1024];while (_isrunning){struct sockaddr_in peer;socklen_t len = sizeof(peer);ssize_t n = recvfrom(_socketfd, inbuffer, sizeof(inbuffer) - 1, 0, (struct sockaddr *)&peer, &len);if (n > 0){InetAddr addr(peer);inbuffer[n] = 0;std::cout << "[" << addr.Ip() << ":" << addr.Port() << "]#" << inbuffer << std::endl;std::string result = _func(inbuffer);sendto(_socketfd, result.c_str(), result.size(), 0, (struct sockaddr *)&peer, len);}else{std::cout << "recvfrom , error" << std::endl;}}}~UdpServer(){if (_socketfd > gsocketfd)::close(_socketfd);}private:int _socketfd; // 套接字fduint16_t _localport; // 端口号// std::string _localip; // ipbool _isrunning; // 服务端业务是否执行func_t _func; };我们先来理解头文件,因为我们的主逻辑都是靠头文件来实现,源文件只是进行了调用,因此我们先把这个核心部分讲好。
首先,我们得理解我们的服务器端是如何工作的,这点其实还是比较好理解的,我们的服务器充当的角色是:
- 能够接收客户端发来的数据
- 能够处理客户端发来的数据
- 能够发回客户端处理的数据
大致一看,我们不难发现,其实服务器端和客户端的大致逻辑是一样的,只不过多了一个业务处理的过程,那么我们该如何来进行处理呢?且听我娓娓道来。
首先,我们来研究成员变量,一个类的设计好坏与否与成员变量有很大的关系。那么我们需要哪些成员变量呢?首先,既然我们的程序是udp服务,那就是网络服务,我们就需要socketfd也就是套接字的文件描述符,我们还需要端口号和ip地址,但是这里我们会发现,我们的ip地址怎么会被注释掉呢?那是因为服务器跟客户端还是有一点区别的,我们的客户端是先发数据再接收,而发送数据是指定的,所以我们要指定ip地址,但是我们的服务器是先接收再发送数据,接收数据的时候我们并不关心具体是哪个客户端发送来的数据,换言之只要是个客户端拿到了我的ip地址都可以向我发送数据。所以这里我们并不需要ip这个成员变量,如何处理我后续会进行讲解。有了头两个成员变量我们算是能进行网络通信了,但是还不够,我们这一版本是带有业务的,所以我们需要用函数包装器将我们的业务功能带进来。具体是怎么做的,我们先不进行讲解,在讲源文件的时候大家就会知道了,我们这里就当他是我们的业务函数接口就行了。当然为了我们的逻辑性和安全性,我们在加一个isrunning来判断当前的业务是否在执行。
在开头我们先来设置几个初始值,这几个缺省参数可以帮助我们当客户端没传参数时不会以挂掉的形式反馈而是以报错误,打印警告等更好的方式来解决。
我们来几个枚举变量,当我们的程序可能会报错误时就可以使用我们的枚举变量,是代码更具有可读性。这里我们就只需要两个就够了,一个是socket套接字创建时失败,一个是绑定时失败。然后我们用函数包装器封装一下函数的参数类型。函数包装器可以使我们以后想换个业务功能时不用改代码,直接引用一下头文件就可以了。
构造函数需要我们将我们的四个成员变量都赋好值。
void InitServer(){// 1.创建socket文件_socketfd = ::socket(AF_INET, SOCK_DGRAM, 0); // AF_INET网络通信方式创建,SOCK_DGRAM udp协议if (_socketfd < 0){LOG(FATAL, "socket error\n");exit(SOCKET_ERROR);}LOG(DEBUG, "socket create success,_sockfd: %d\n", _socketfd);// 2.bindstruct sockaddr_in local;memset(&local, 0, sizeof(local));local.sin_family = AF_INET;local.sin_port = htons(_localport);// local.sin_addr.s_addr = inet_addr(_localip.c_str());//需要4字节、需要网络序列的iplocal.sin_addr.s_addr = INADDR_ANY; // 服务器端,进行任意ip地址绑定0int n = ::bind(_socketfd, (struct sockaddr *)&local, sizeof(local));if (n < 0){LOG(FATAL, "bind error\n");exit(BIND_ERROR);}LOG(DEBUG, "socket bind success\n");}初始化完成后就可以开始我们的服务器创建步骤了。创建过程我们分两步,第一步是创建我们的socket文件,第二步是绑定socketfd和服务器地址。
创建sockfd的操作跟我们的客户端创建socket是一样的,这里我就不赘述了。
绑定之前我们得先初始化我们的IPv4结构体,这一点跟我们的客户端也没有区别,唯一的区别就是赋值ip的时候我们使用的是INADDR_ANY,它的意思是进行任意ip地址绑定。绑定完成后我们的服务器构建工作就完成了。
void Start(){_isrunning = true;char inbuffer[1024];while (_isrunning){struct sockaddr_in peer;socklen_t len = sizeof(peer);ssize_t n = recvfrom(_socketfd, inbuffer, sizeof(inbuffer) - 1, 0, (struct sockaddr *)&peer, &len);if (n > 0){InetAddr addr(peer);inbuffer[n] = 0;std::cout << "[" << addr.Ip() << ":" << addr.Port() << "]#" << inbuffer << std::endl;std::string result = _func(inbuffer);sendto(_socketfd, result.c_str(), result.size(), 0, (struct sockaddr *)&peer, len);}else{std::cout << "recvfrom , error" << std::endl;}}}构建完后就是我们的开启服务器,当上层启动我们的服务器就代表业务开始了,我们的isrunning就设置为true,我们的服务器是先接收再发送,我们先创建一个IPv4结构体对象获取客户端的地址信息,然后调用我们的业务接口再将返回值原路发送回客户端就结束了。
我们的服务器要析构的时候就只需要判断我们的sockfd是否是有效的,有效就关闭,无效就不做处理。
最后我们再来看看我们的
UdpServerMain.cc#include "UdpServer.hpp" #include "Dict.hpp" #include <memory> // ./udpserver 8888 int main(int argc, char *argv[]) {// std::string ip = "127.0.0.1"; // 本主机 localhostif (argc != 2){std::cerr << "Usage: " << argv[0] << "local-port" << std::endl;exit(0);}uint16_t port = std::stoi(argv[1]);EnableScreen();Dict dict("./dict.txt");func_t translate = std::bind(&Dict::Translate, &dict, std::placeholders::_1);std::unique_ptr<UdpServer> usvr = std::make_unique<UdpServer>(translate, port);usvr->InitServer();usvr->Start();return 0; }这个源文件的作用就是调用我们的服务器类,我们首先接收命令行参数,这里我们只需要两个,一个运行源文件的命令,一个是端口号,至于为什么不需要ip地址我在讲服务器类的时候就已经讲的很清楚了。接收成功后我们将日志打印形式设置成输出到屏幕上,然后将我们的业务类也就是字典类初始化好,我们这里提前准备一个字典的文件,只需要将它的地址给到我们的字典类就可以了。然后我们要将我们的业务类里面的运行接口给到我们的服务器,这样才能使他们联动起来,这里我们会发现我用了一个bind,那么bind是什么呢?
通过
std::bind这个工具,把Dict类里的Translate成员函数,和具体的dict对象(的地址)绑定在一起,同时预留出一个参数位置(表示调用时需要传入这个参数),最终生成一个名叫translate的可调用对象(类型是func_t)。
简单说,后续只要直接调用translate并传入对应参数,就相当于用dict这个对象去调用它的Translate成员函数。为什么需要用
std::bind
核心原因是 类的非静态成员函数不能 “单独使用”,必须依赖具体的对象才能调用。
类的成员函数在底层会隐含一个指向 “调用对象” 的this指针参数 —— 也就是说,要调用Translate,必须明确是 “哪个Dict对象的Translate”。但很多场景(比如传递回调函数、给算法传处理逻辑)需要的是 “不依赖特定对象、拿过来就能用” 的可调用逻辑,std::bind就是用来解决这个矛盾的:它提前把 “要调用的成员函数” 和 “具体的调用对象” 绑定在一起,相当于固定了this指针,从而把成员函数转换成一个像普通函数一样的独立可调用对象。换言之,我们当然可以直接传递Dict类的对象,但是代码就不具有可塑性,它会依赖具体对象,如果我们想换一个接口使用参数和返回类型一样的业务,我们就需要改动我们代码的对应部分,到时候会相当麻烦,所以使用bind我们就可以做到轻松切换类似业务,只需稍微改动几行行代码足以。bind的作用是使我们的代码由具体转到抽象,减少对具体对象的依赖性。不使用
std::bind会怎么样这点其实我上述说明已经顺带讲了。
如果不用
std::bind,会面临两个关键问题:
- 无法直接传递成员函数作为参数:比如想把
Translate作为回调函数传给某个工具,直接传&Dict::Translate是行不通的 —— 它的类型是 “成员函数指针”,和普通函数 / 可调用对象的类型不兼容(因为缺了this指针对应的对象信息),编译器会报错。- 调用成员函数必须显式绑定对象,非常繁琐:即使拿到成员函数指针,调用时也必须手动指定对象(比如 “用
dict对象调用这个指针指向的函数”),语法复杂且不灵活,无法满足 “需要独立逻辑片段” 的场景(比如事件触发时自动执行,不需要手动关联对象)。bind的返回值是成员函数的返回值吗?
不是的。
std::bind的返回值不是成员函数的返回值,而是一个可调用对象(也称为 “绑定器”)—— 这个对象封装了 “要调用的函数 / 成员函数”、“关联的对象(针对成员函数)” 以及 “预绑定的参数”。只有当你调用这个由
bind生成的可调用对象时,它才会去执行被绑定的成员函数,此时的返回值才是该成员函数的返回值。举个例子:
假设Dict::Translate的返回值是std::string,那么:
std::bind(...)返回的translate是一个可调用对象(类型为func_t),它本身不是std::string;- 当你调用
translate("apple")时,这个对象会触发dict.Translate("apple")的执行,此时得到的结果(比如"苹果")才是Translate成员函数的返回值。简单说:
bind的返回值是 “准备好的调用逻辑”,而不是函数的执行结果;只有执行这个逻辑(调用该对象),才能得到成员函数的返回值。讲完bind之后,我们就可以初始化服务器了,我们将可调用对象和端口号传进去,构建服务器再启动服务器,我们的功能就完成了。
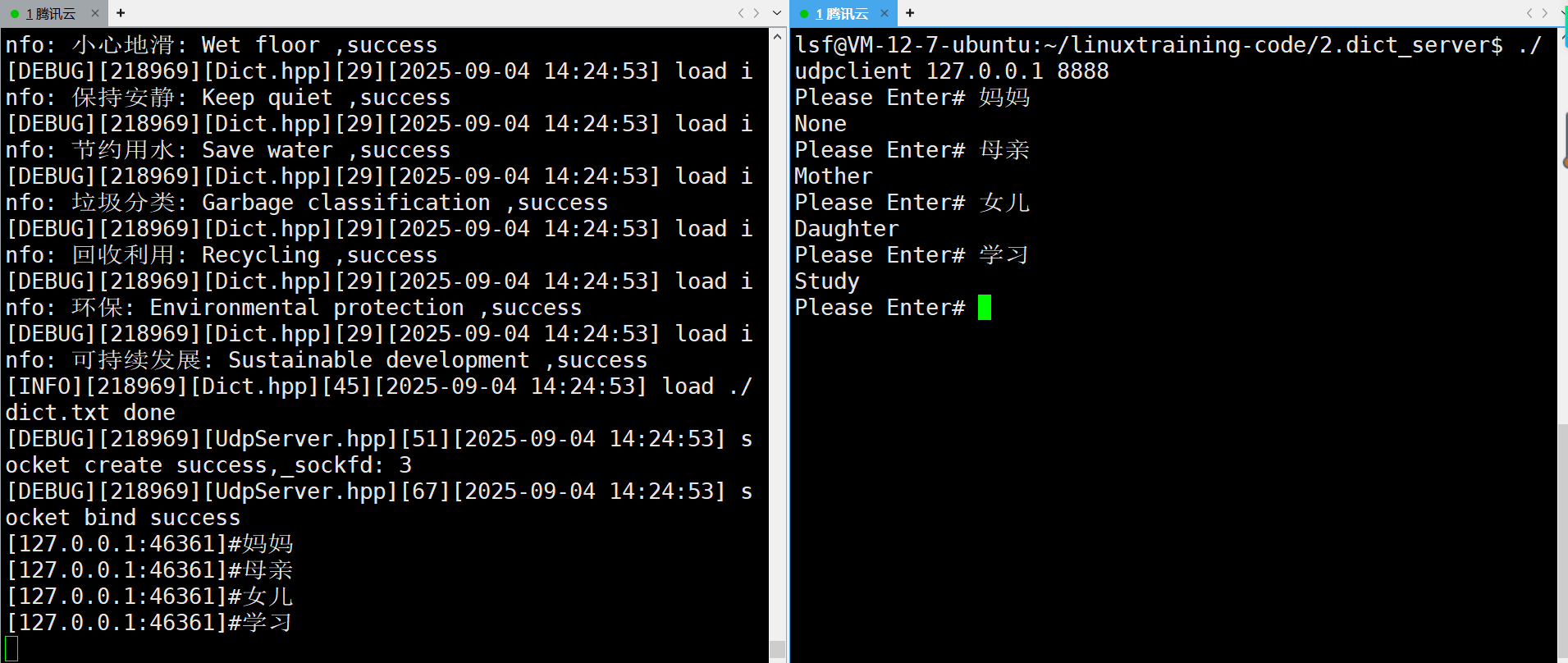
运行截图