探寻卓越:高级RAG技术、架构与实践深度解析
文章目录
- **1. 摘要:从朴素RAG到高阶智能问答的范式演进**
- **2. 引言:RAG架构的演进与核心挑战**
- **2.1 RAG:LLM 幻觉与知识更新的根本解法**
- **2.2 朴素RAG的致命缺陷与核心挑战**
- **2.3 高阶RAG:一个系统性的优化框架**
- **3. 第一部分:数据预处理与智能索引策略**
- **3.1 挑战:非结构化数据的摄取与解析难题**
- **3.2 精细化分块:从固定大小到语义与层级分块**
- **3.3 元数据增强与富上下文信息构建**
- **4. 第二部分:增强型检索机制与多重查询优化**
- **4.1 混合检索(Hybrid Search):融合稀疏与稠密检索的优势**
- **4.2 查询转换(Query Transformation):HyDE 与多重查询重写**
- **4.3 代理式RAG(Agentic RAG):自主决策与工具调用**
- **5. 第三部分:精炼、压缩与生成:提升答案质量的关键环节**
- **5.1 基于LLM的后置重排序(Re-ranking):精准过滤噪音**
- **5.2 上下文压缩(Contextual Compression):精炼核心信息**
- **5.3 从压缩到生成:精炼上下文的价值**
- **6. 第四部分:项目实战:构建一个可学习的高级RAG管道**
- **6.1 项目架构与核心组件概览**
- **6.2 代码实践:环境配置与数据准备**
- **6.3 代码实践:数据索引与混合检索**
- **6.4 代码实践:后置重排序与上下文压缩**
- **6.5 综合演示与效果评估**
- **6.6 项目实战:基于LlamaIndex的更深入技术实践**
- **6.6.1 精细化分块与富上下文构建:层级索引与自动合并**
- **6.6.2 查询转换:HyDE与多重查询重写**
- **6.6.3 元数据增强:自动化信息提取**
- **7. 结论与未来展望**
- **7.1 高阶RAG技术总结:一个多维度的系统性工程**
- **7.2 展望:从RAG到自适应知识引擎的未来**
1. 摘要:从朴素RAG到高阶智能问答的范式演进
检索增强生成(RAG)作为一种行之有效的技术范式,通过引入外部知识库,有效缓解了大型语言模型(LLM)固有的幻觉(Hallucination)及知识时效性问题。然而,在面对实际生产环境中的复杂挑战时,基础的“朴素RAG”(Naive RAG)架构因其固有的局限性而力有不逮,例如难以处理复杂查询、检索召回率低下、以及答案准确性不足等。本文旨在系统性地解构这些挑战,并提出一个全面的“高级RAG”框架,覆盖从数据预处理、增强型检索到精炼后处理的整个技术栈。
本文不仅将深入剖析混合检索、重排序、上下文压缩等前沿技术原理,更将提供一个端到端的项目实战案例,使用主流开源框架构建一个生产级的、可学习的高级RAG管道。其核心价值在于,为AI工程师和研究员提供一份既有理论深度又具实践价值的指南,旨在通过系统性的工程优化,将RAG系统的问答能力从“可用”推向“卓越”,最终实现更准确、更可信赖的智能问答体验。
2. 引言:RAG架构的演进与核心挑战
2.1 RAG:LLM 幻觉与知识更新的根本解法
大型语言模型在知识生成和推理方面展现出非凡的能力,但它们也存在固有的局限性。首先,LLM的知识是静态的,受限于其训练数据的截止日期,无法获取最新信息。其次,LLM可能产生“幻觉”,即生成看似合理但事实上错误或虚构的内容。
RAG技术提供了一种优雅的解决方案。其核心理念是将LLM的“参数化知识”(Parametric Knowledge,即模型权重中固有的知识)与“非参数化知识”(Non-Parametric Knowledge,即外部知识库中的实时数据)相结合。这种方法使LLM能够在生成答案之前,先从外部权威数据源检索相关信息,并将其作为上下文输入给模型。这种动态检索机制不仅确保了信息的新鲜度,还将LLM的输出“接地”(grounding)于可验证的事实,从而显著减少幻觉的发生。
与从头训练或微调LLM来注入新知识相比,RAG具备显著优势。微调成本高昂,且难以频繁进行以应对快速变化的信息,而RAG只需更新其外部知识库即可。此外,RAG的输出通常能够提供引用的来源,这大大增强了答案的可信赖度和可追溯性,使其在医疗、法律和金融等对准确性要求极高的领域尤为关键。
2.2 朴素RAG的致命缺陷与核心挑战
尽管RAG理念强大,但在实际应用中,简单的“朴素RAG”架构常常暴露出其固有的脆弱性。一个典型的朴素RAG流程包括:将文档分块、生成向量嵌入并存入向量数据库,然后在查询时进行向量相似度搜索,最后将检索到的文档作为上下文输入给LLM。这个看似简单的管道,在现实世界中面临诸多挑战:
- “Garbage In, Garbage Out”(输入垃圾,输出垃圾):RAG系统的性能在很大程度上取决于其知识库的质量。如果知识库包含过时、不准确或带有偏见的信息,系统就会自信地给出错误的答案。正如医疗领域的旧数据或金融领域的过时法规,都可能导致严重的后果。此外,处理非结构化数据,如PDF、图表、表格或图片,是另一个巨大挑战。传统的文本解析器往往会忽略这些关键的非文本数据,导致RAG系统对内容的理解是不完整或不准确的。
- 分块噩梦(Chunking Nightmare):文档分块是RAG流程中的基础步骤,但也是一个“噩梦”。分块尺寸过小,会导致关键的上下文信息被切断,使得单个分块无法提供完整的语义。反之,分块尺寸过大,则会引入大量与查询无关的噪音,稀释了相关信息,降低了检索的精准度 。
- 检索噩梦(Retrieval Nightmares):
- 语义与关键词的割裂:单纯的向量相似度搜索虽然能捕捉语义,但往往无法处理用户查询和文档之间存在的“语言鸿沟”。例如,用户查询“远程工作”,但文档中只使用“远程办公”,向量搜索可能会失败。此外,对于包含特定关键词或数字的精确查询,纯粹的语义搜索也可能表现不佳。
- 上下文的丢失:传统的分块策略常常“破坏了上下文”。当用户提出需要跨越多个文档或分块才能进行综合推理的复杂查询时,朴素RAG由于其分块的独立性,无法将这些零散的信息碎片整合起来,从而导致答案不完整或不准确。
2.3 高阶RAG:一个系统性的优化框架
为应对朴素RAG的局限性,一个更高级、更智能的RAG框架应运而生。高阶RAG并非简单的线性管道,而是一个从数据处理到答案生成的全链路系统性工程,它包含多步精炼、多模态处理和智能决策的复杂框架 。
这种框架的核心思想是:通过在管道的每个关键环节引入高级技术,来解决上游的固有问题,从而确保下游的LLM能够接收到最干净、最相关、最精炼的上下文。以下是高阶RAG的技术全景图,它将作为本报告的贯穿主线:
图1: 高阶RAG技术全景图。一个从数据预处理到后处理的端到端系统,旨在通过多维度优化来提升问答质量。
3. 第一部分:数据预处理与智能索引策略
3.1 挑战:非结构化数据的摄取与解析难题
RAG系统的成功始于其数据。朴素RAG的失败并非始于检索,而是源于最上游的“数据摄取”阶段。正如"Garbage In, Garbage Out"所言,一个无法正确解析多媒体或非结构化数据的系统,其后续任何环节的优化都将是徒劳的。
大多数企业知识库并非纯文本,而是包含多种格式的非结构化数据,如PDF、PowerPoint演示文稿、Word文档、甚至图片和图表 。这些文件格式通常包含复杂的布局、格式化文本(如标题、粗体、列表)和关键的非文本数据。传统的文本解析器在处理这些文件时,往往会忽略或错误处理这些关键元素。例如,一份财务报告中的条形图可能直观地展示了销售趋势,而法律文档中的手写批注则可能包含关键的补充条款。一个仅处理文本的RAG系统会完全忽视这些视觉数据,从而导致对文档的理解不完整,最终生成不准确或片面的回答。
3.2 精细化分块:从固定大小到语义与层级分块
固定大小的分块策略(例如,按500个字符或100个token切分)是朴素RAG中最常见的做法。这种方法的缺陷是显而易见的:它经常在句子或段落的中间切断文本,破坏了内容的语义连贯性,使得每个分块都变得支离破碎、缺乏语境 。
为了解决这个问题,高级RAG引入了更智能的分块策略:
- 语义分块(Semantic Chunking):这种方法不依赖于固定大小的规则,而是根据文本的内在语义结构进行切分。例如,根据段落边界、章节标题或主题转换点进行分块 。这样可以确保每个分块都是一个自包含、有意义的单元,从而更好地保留上下文信息 。
- 层级分块(Hierarchical Chunking):这是一种更复杂的策略,旨在重建文档的层级结构。它将文档划分为不同粒度的分块,例如从粗粒度的章节到中等粒度的段落,再到细粒度的句子。在索引时,这些不同粒度的分块会被存储并保留其父子关系。这种层级结构为后续的“合并检索”(Auto-Merging Retrieval)奠定了基础,即在检索到多个细粒度分块后,可以自动“合并”到其包含丰富上下文的父分块中,从而提供更完整的语境 。
图2:分块策略对比
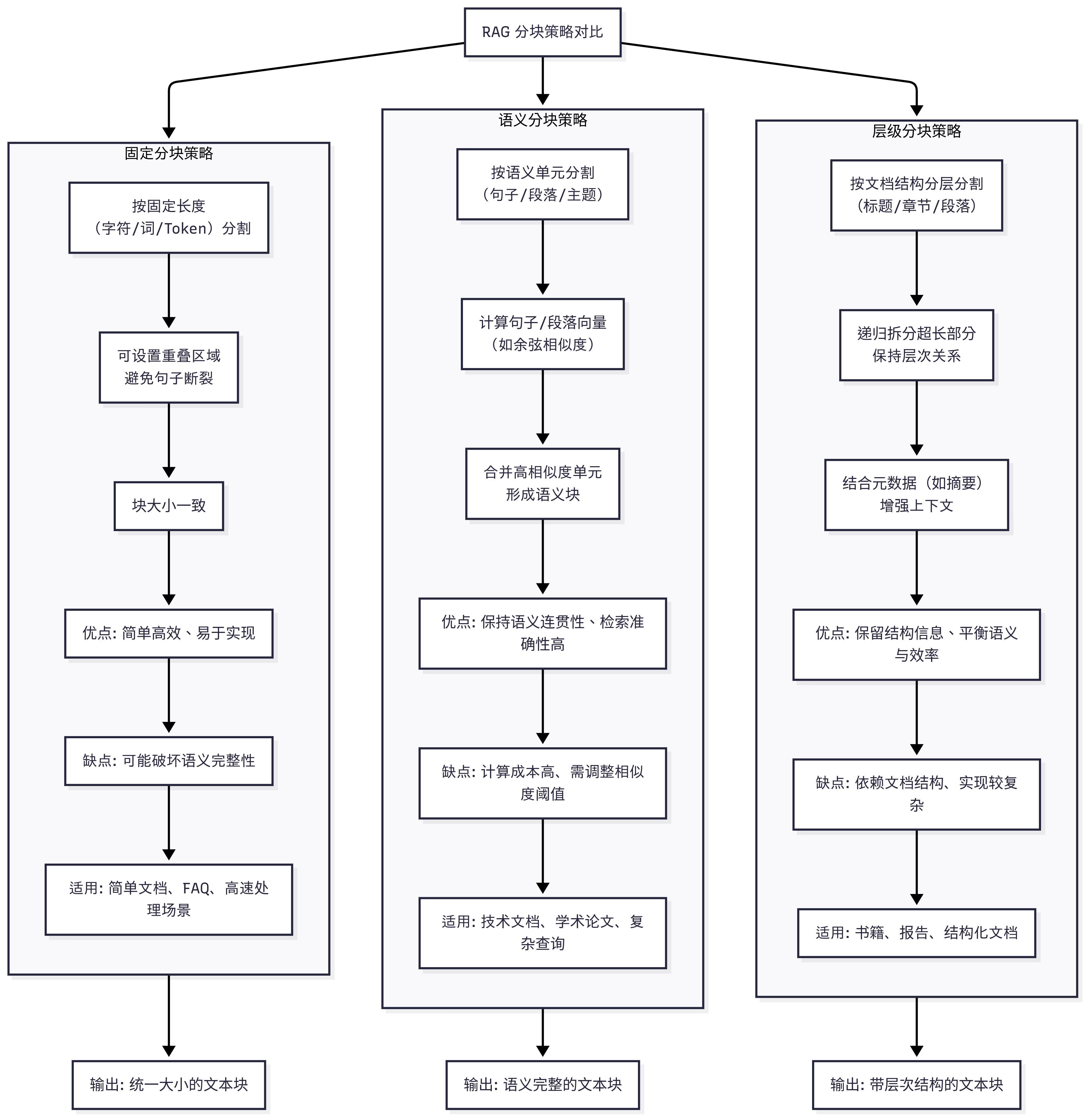
图2: 三种分块策略的对比。固定分块可能在任意位置切断,而语义和层级分块则能更好地保留内容的完整性。
3.3 元数据增强与富上下文信息构建
在文档索引阶段,仅仅分块是不够的,还需要通过元数据增强和上下文构建来丰富每个分块的语境。
- 元数据增强:为每个分块添加元数据,如文档ID、页码、作者、创建日期、章节标题或源链接等,这是一种简单而高效的策略。这些元数据在检索时可以作为强大的过滤器,帮助系统精准定位信息 。此外,这些元数据本身也能为LLM提供额外的语境,帮助其生成更具可信度和可追溯性的答案 。
- 富上下文(Contextual Retrieval):该技术的核心理念是利用一个专门的LLM,为每个分块生成一个简短的、概括性的上下文描述,并将其作为前缀添加到分块内容中 。例如,对于一份复杂的学术论文,即使单个段落本身晦涩难懂,但通过为其添加一个由LLM生成的概括性描述,检索系统可以更准确地捕捉到其核心含义。这一过程将原本需要在生成时才能完成的复杂上下文理解任务,前置到了索引阶段,这是一种架构上的解耦和任务的重新分配,提高了整个系统的效率和准确性 。
这种前置处理打破了传统RAG的因果链:糟糕的文档解析 → 无效的分块 → 劣质的向量嵌入 → 检索系统召回错误或不完整的上下文 → LLM生成错误答案。高级RAG的第一步就是要从源头解决问题,确保在进入检索阶段之前,知识库中的每个信息单元都是结构化、高质量且富含语境的。
4. 第二部分:增强型检索机制与多重查询优化
4.1 混合检索(Hybrid Search):融合稀疏与稠密检索的优势
单一的检索方式无法满足复杂多样的用户查询。纯粹的向量搜索擅长捕捉语义,但在处理包含特定实体、专有名词或数字的精确查询时表现不佳。而传统的关键词搜索(如BM25)则正好相反,它擅长精确匹配,但无法理解同义词或相似概念。
混合检索通过将这两种方法的优势结合起来,实现了更全面、更鲁棒的检索能力 1。其工作流如下:
- 并行检索:当用户提交查询时,系统同时进行两种检索。
- 稠密检索(Dense Retrieval):将查询转换为高维向量,并在向量数据库中进行相似度搜索。
- 稀疏检索(Sparse Retrieval):利用BM25等关键词算法,进行传统的全文检索。
- 结果融合:将两种检索方法返回的文档集进行合并。
- 智能排序:使用一种融合算法(如Reciprocal Rank Fusion, RRF)对合并后的文档进行重新排序 。RRF能够公平地结合不同检索方法的结果,并将最相关的文档置于顶部,从而确保了召回的全面性和排序的精准性 。
这种方法本质上是在解决用户与文档之间的语义不对称问题,确保无论用户是使用口语化的自然语言还是精确的关键词,系统都能召回最相关的文档。
图3:混合检索工作流
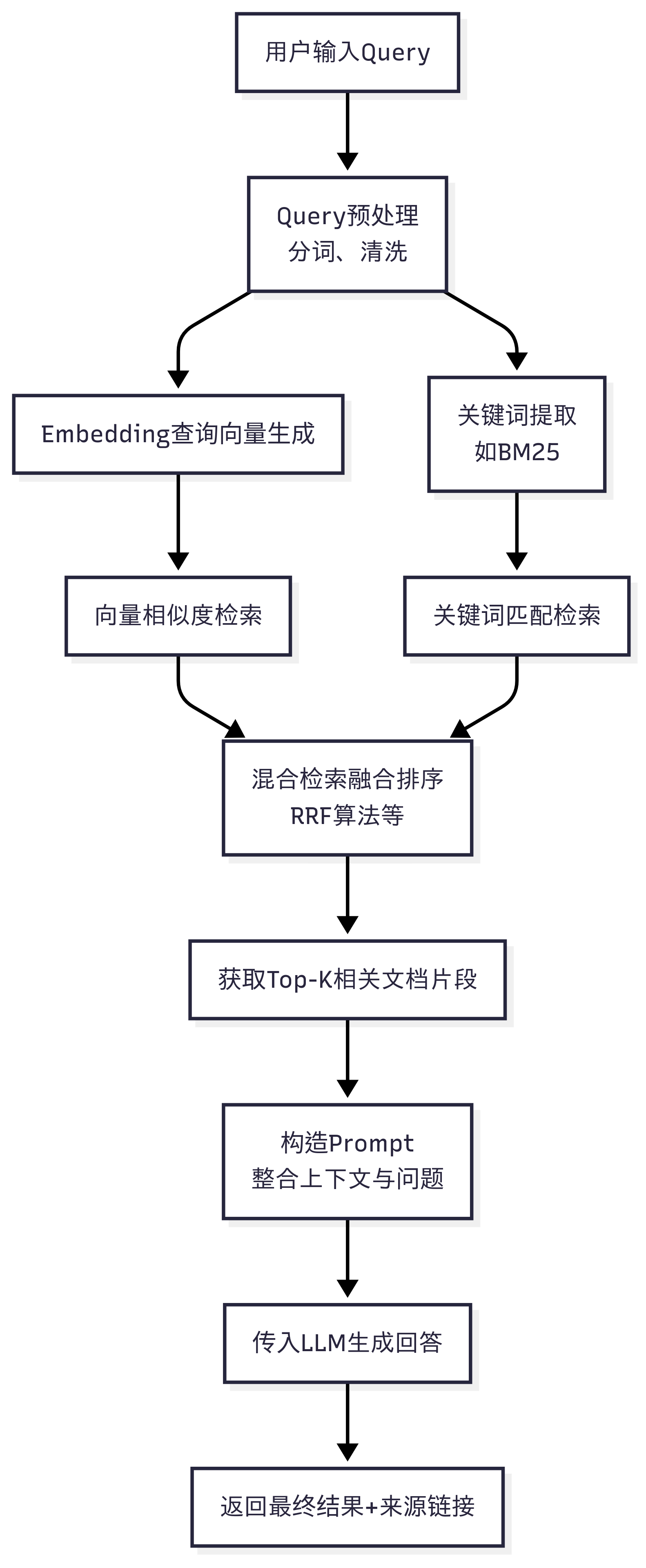
图3: 混合检索的工作流。展示了查询如何同时通过稀疏和稠密检索路径,并最终通过RRF进行融合。
4.2 查询转换(Query Transformation):HyDE 与多重查询重写
用户查询通常简短而模糊,与知识库中详细的文档内容存在意图不对称(Query-Document Asymmetry)。为了解决这一问题,高级RAG采用查询转换技术来优化检索过程。
- HyDE(Hypothetical Document Embeddings):这一技术的原理是,首先使用一个LLM根据用户查询生成一个“假设性答案”或“虚拟文档”。这个虚拟文档虽然不一定准确,但它包含了LLM对查询意图的理解,其嵌入向量更接近于真实文档的语义。然后,系统对这个虚拟文档生成向量嵌入,并使用它而非原始查询进行检索。这种方法能够显著提升检索精度,特别是在处理抽象或意图不明的查询时表现优异。
- 多重查询重写(Multi-Query Rewriting):这种方法的核心在于将一个模糊的查询(如“什么是向量数据库?”)重写为多个更精确、更具体的子查询(例如:“向量数据库的定义”、“向量数据库的用例”、“向量数据库与传统数据库的区别”)。然后,系统并行执行所有这些子查询的检索,并将所有结果合并。这种方法通过扩大检索的范围,有效提高了召回率,降低了因查询措辞不当而错过关键信息的风险 。
4.3 代理式RAG(Agentic RAG):自主决策与工具调用
传统的RAG是一个固定的、被动的线性管道。而代理式RAG则代表了一种根本性的范式转变,它将RAG与LLM驱动的“智能体”(Agent)相结合。智能体不再是简单的信息检索器,而是一个能够根据查询的复杂性自主决策、规划和执行任务的“大脑”。 代理式RAG的工作流如下:
- 用户查询:智能体接收用户查询。
- 规划与推理:智能体分析查询,并决定最合适的处理方式。例如,如果查询包含数学计算,它会调用计算器工具;如果查询需要最新事实,它会调用Wikipedia工具;如果查询需要从内部知识库获取信息,它会调用文档检索器。
- 工具调用:智能体调用选定的工具执行任务。工具返回的结果会再次输入给智能体,进行多步骤的“行动”(Acting)和“反思”(Self-Correction)。
- 生成答案:智能体最终根据工具返回的所有信息,综合生成最终的答案。
这种架构的出现,标志着RAG从一个“数据管道”向“决策引擎”的根本性转变。它不再局限于单一的文档检索,而是能够主动进行多步骤的复杂推理和任务分解,从而处理传统RAG框架无法应对的复杂问题。
5. 第三部分:精炼、压缩与生成:提升答案质量的关键环节
5.1 基于LLM的后置重排序(Re-ranking):精准过滤噪音
即使是高级检索,也可能返回大量相关但并非最优的文档。将所有这些文档都直接塞给LLM,会增加噪音,导致LLM“信息过载”而难以专注于核心信息。
后置重排序作为一种关键的后处理步骤,旨在解决这一问题 。其原理是:对检索器返回的初步结果集(例如前20个文档)进行二次精炼和排序。重排序器通常是一个更小、更快的模型(如跨编码器Cross-encoder或专门的LLM),它对每一个“查询-文档”对进行更细粒度的相关性评分 。例如,一个好的重排序器能够识别出包含核心答案的某个文档片段,并将其从第15位提升到第1位。通过这种方式,重排序器确保LLM最终看到的是最相关、最优质的上下文,从而显著提升答案的准确性和质量 。
5.2 上下文压缩(Contextual Compression):精炼核心信息
即使经过重排序,文档块中仍可能包含大量与查询无关的冗余信息。这些冗余信息不仅会增加LLM的输入Token数,导致API成本上升,还会“稀释”LLM的注意力 。上下文压缩技术旨在去除这些噪音,只保留对生成答案至关重要的信息。
- 硬压缩(Hard Compression):这类方法直接对文档内容进行修改。最常见的技术包括文档摘要(Summarization)和信息提取(Extraction)。文档摘要利用LLM或专门的模型将检索到的文档片段总结成核心要点 。而信息提取则更进一步,根据查询意图,从文档中精准提取出关键实体、数字或句子 。
- 软压缩(Soft Compression):这是一类更前沿的研究方向,其目标是在不改变文本表面结构的前提下,实现高密度的信息压缩。例如,PISCO和CASC等研究利用特殊训练的LLM,将长文档压缩成高密度的向量表示或“记忆Token”(Memory Tokens)。这种方法在保持信息量的同时,极大地减少了Token数量,实现了数倍甚至数十倍的压缩率,显著降低了推理成本和延迟 。
图4:上下文压缩流程
图4: 上下文压缩流程。展示了从原始文档到精炼上下文的每一步,包括重排序和内容提取。
5.3 从压缩到生成:精炼上下文的价值
后处理技术(重排序和上下文压缩)是RAG的“治本”方案,它们解决了LLM生成端面临的“信息过载”问题。重排序确保LLM看到的是最相关的文档,而上下文压缩确保LLM看到的文档是最精炼的。
这一系列精炼操作带来了多重价值:
- 降低成本:直接减少LLM的输入Token数,显著降低基于API调用的大型RAG系统的运营成本 。
- 降低延迟:处理更少的Token意味着更快的生成速度,这对于追求实时问答的用户体验至关重要 。
- 提升准确性:减少上下文中的噪音,帮助LLM将注意力集中在最关键的信息上,从而降低因“信息过载”导致的幻觉和错误 。
这种精炼流程揭示了高级RAG的内在逻辑:检索(提升召回)→ 重排序(提升排序精度)→ 压缩(降低噪音与成本)→ 生成(基于干净的上下文给出准确答案)。这是一个螺旋式上升的优化闭环,确保了整个系统在准确性、效率和成本之间达到最佳平衡。
6. 第四部分:项目实战:构建一个可学习的高级RAG管道
本节将综合前面讨论的所有高级技术,构建一个完整的RAG管道。我们将使用主流的LangChain框架,结合开源模型和向量数据库。
6.1 项目架构与核心组件概览
本实战项目将采用混合检索和重排序的组合,来构建一个高性能的RAG管道。
- 核心技术栈:
- 管道编排:LangChain
- 文档分块:RecursiveCharacterTextSplitter
- 嵌入模型:BAAI/bge-base-en-v1.5
- 向量数据库:FAISS(用于稠密检索)
- 稀疏检索:BM25Retriever
- 检索融合:EnsembleRetriever
- 后置重排序:CohereRerank 或 BAAI/bge-reranker-base
- 大型语言模型:HuggingFaceH4/zephyr-7b-alpha
6.2 代码实践:环境配置与数据准备
首先,我们需要安装所有必要的依赖库,并准备我们的数据集。
# 安装依赖
!pip install -q langchain sentence-transformers rank_bm25 faiss-cpu cohere-rerank huggingface_hub# 导入依赖库
import os
from getpass import getpass
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import HuggingFaceInferenceAPIEmbeddings# 假设你的数据集位于/content/drive/MyDrive/Tech_news_dataset/dataset_news/
# 你也可以替换为自己的文档目录
dataset_folder_path = './dataset_news/'
documents =# 检查目录是否存在
if not os.path.exists(dataset_folder_path): print(f"警告:数据集目录 {dataset_folder_path} 不存在。请确保你已上传数据。")
else: for file in os.listdir(dataset_folder_path): loader = TextLoader(os.path.join(dataset_folder_path, file)) documents.extend(loader.load())# 文档分块
text_splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=50)
text_splits = text_splitter.split_documents(documents)# 打印分块信息
print(f"原始文档数: {len(documents)}")
print(f"分块后文档数: {len(text_splits)}")
if text_splits: print(f"第一个分块内容:\n{text_splits.page_content[:200]}...")
6.3 代码实践:数据索引与混合检索
接下来,我们将使用FAISS和BM25分别建立稠密和稀疏索引,并使用EnsembleRetriever将它们融合。
#... 承接上文代码...
from langchain.vectorstores import FAISS
from langchain.retrievers import BM25Retriever, EnsembleRetriever# 1. 设置Hugging Face API密钥
# 请通过 getpass() 安全输入你的API密钥,或将其设置为环境变量
os.environ = getpass("输入Hugging Face API Token:")# 2. 初始化嵌入模型
embeddings = HuggingFaceInferenceAPIEmbeddings( model_name='BAAI/bge-base-en-v1.5'
)# 3. 稠密嵌入与向量库索引
vectorstore = FAISS.from_documents(text_splits, embeddings)
vector_retriever = vectorstore.as_retriever(search_kwargs={"k": 5})# 4. 稀疏检索器
keyword_retriever = BM25Retriever.from_documents(text_splits)
keyword_retriever.k = 5# 5. 混合检索(EnsembleRetriever)
ensemble_retriever = EnsembleRetriever( retrievers=[vector_retriever, keyword_retriever], weights=[0.5, 0.5] # 调整权重来平衡两种检索方式
)# 测试混合检索效果
query = "How many cafes were closed in 2004 in China?"
docs = ensemble_retriever.get_relevant_documents(query)print("\n混合检索结果(前5个文档):")
for i, doc in enumerate(docs[:5]): print(f"--- 文档 {i+1} ---") print(f"{doc.page_content[:150]}...")
6.4 代码实践:后置重排序与上下文压缩
现在,我们将在检索结果之上集成重排序器,进一步提升上下文质量。我们将使用CohereRerank,并将其与ContextualCompressionRetriever结合。
#... 承接上文代码...
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import CohereRerank# 1. 设置Cohere API密钥
os.environ = getpass("输入Cohere API Token:")# 2. 初始化重排序器
compressor = CohereRerank(top_n=3)# 3. 构建上下文压缩检索器
compression_retriever = ContextualCompressionRetriever( base_compressor=compressor, base_retriever=ensemble_retriever # 传入混合检索器作为基础检索器
)# 测试重排序后的结果
compressed_docs = compression_retriever.get_relevant_documents(query)print("\n重排序与压缩后的结果(前3个文档):")
for i, doc in enumerate(compressed_docs): print(f"--- 文档 {i+1} ---") print(f"{doc.page_content[:150]}...")
6.5 综合演示与效果评估
最后,我们将所有组件集成到完整的RAG链中,并使用一个开源LLM进行问答。
#... 承接上文代码...
from langchain.llms import HuggingFaceHub
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough# 初始化开源LLM模型
# 请确保你的Hugging Face账号有权限访问HuggingFaceH4/zephyr-7b-alpha
llm = HuggingFaceHub( repo_id='HuggingFaceH4/zephyr-7b-alpha', model_kwargs={"temperature": 0.5, "max_new_tokens": 512}
)# 定义RAG提示模板
template = """
<|system|>
你是一名专业的AI助手,必须严格遵循以下规则:
1. 仅使用提供的CONTEXT中的信息来回答问题。严禁使用外部知识或内部记忆。
2. 如果CONTEXT中的信息不足以完整回答问题,请明确回答“根据提供的资料,我没有找到足够的信息来回答这个问题”。
3. 如果CONTEXT中的信息完全无关,请直接说“我不知道”。
4. 回答要力求准确、简洁、客观。
5. 在回答中,可以引用CONTEXT中的关键信息。CONTEXT: {context}
</s>
<|user|>
{query}
</s>
<|assistant|>
"""
prompt = ChatPromptTemplate.from_template(template)
output_parser = StrOutputParser()# 构建完整的RAG链
rag_chain = ( {"context": compression_retriever, "query": RunnablePassthrough()}| prompt
| llm
| output_parser
)# 运行问答链
print("\n--- 完整问答演示 ---")
final_query = "What is Zephyr AI?"
response = rag_chain.invoke(final_query)
print(f"用户查询: {final_query}")
print(f"AI助手回答: {response}")
6.6 项目实战:基于LlamaIndex的更深入技术实践
为了更全面地展示前文讨论的高级RAG技术,本节将使用另一个主流框架LlamaIndex进行深入的实战演练。LlamaIndex以其强大的数据摄取、索引和查询转换能力而闻名,非常适合演示这些复杂的预处理和检索优化技术 。
6.6.1 精细化分块与富上下文构建:层级索引与自动合并
传统的固定分块策略容易破坏文档上下文,导致检索效果不佳 。LlamaIndex的HierarchicalNodeParser则通过创建不同粒度的文档节点(例如,大章节、小段落、句子),来保留文档的内在结构 。更重要的是,其AutoMergingRetriever能够智能地将检索到的多个小节点“合并”成其包含更丰富上下文的父节点,从而为LLM提供更全面的语境 。
# 安装LlamaIndex及其依赖
!pip install -q llama-index PyMuPDF pandasimport os
from llama_index.core import Document
from llama_index.core.node_parser import HierarchicalNodeParser, get_leaf_nodes
from llama_index.core.storage.docstore import SimpleDocumentStore
from llama_index.core import VectorStoreIndex, StorageContext
from llama_index.core.retrievers import AutoMergingRetriever
from llama_index.core.query_engine import RetrieverQueryEngine# 1. 模拟加载文档(这里使用简单文本代替PDF)
documents =
doc_text = "\n\n".join([d.get_content() for d in documents])
docs =# 2. 创建层级节点解析器
# 定义不同粒度的分块尺寸,例如:2048、512、128
# 这将创建三个层级的节点,每个小节点都与其父节点关联
node_parser = HierarchicalNodeParser.from_defaults( chunk_sizes=
)
nodes = node_parser.get_nodes_from_documents(docs)
leaf_nodes = get_leaf_nodes(nodes)print(f"层级节点总数: {len(nodes)}")
print(f"叶子节点(最小粒度)总数: {len(leaf_nodes)}")
print("n--- 最小粒度节点示例 ---")
print(leaf_nodes.get_content()[:200] + "...")# 3. 将节点存入文档存储
docstore = SimpleDocumentStore()
docstore.add_documents(nodes)
storage_context = StorageContext.from_defaults(docstore=docstore)# 4. 创建自动合并索引和检索器
base_index = VectorStoreIndex( leaf_nodes, storage_context=storage_context
)# AutoMergingRetriever将首先检索小节点,然后合并为更大的父节点
retriever = AutoMergingRetriever( base_retriever=base_index.as_retriever(similarity_top_k=6), storage_context=storage_context, verbose=True
)# 5. 构建查询引擎并测试
query_engine = RetrieverQueryEngine.from_args(retriever)
query_str = "What is the primary benefit of advanced RAG and how does it deal with document structure?"
response = query_engine.query(query_str)print("\n--- 自动合并检索器响应 ---")
print(response)
6.6.2 查询转换:HyDE与多重查询重写
为了解决用户查询与文档内容之间的“语义不对称”问题,我们可以对原始查询进行转换,以更准确地捕捉用户意图 。
- HyDE (Hypothetical Document Embeddings): HyDE通过生成一个“假设性答案”来作为检索的依据,而不是直接使用原始查询 2。由于这个假设性答案在语义上更接近于真实的文档,因此能够大幅提升检索准确性。
#... 承接上文代码...
from llama_index.core.indices.query.query_transform import HyDEQueryTransform
from llama_index.core.query_engine import TransformQueryEngine# 1. 定义HyDE查询转换器
# 它会使用LLM根据用户查询生成一个假设性答案
hyde = HyDEQueryTransform(include_original=True)# 2. 构建包含HyDE的查询引擎
# 这里的index可以是任意索引,例如我们之前创建的base_index
hyde_query_engine = base_index.as_query_engine()
hyde_query_engine = TransformQueryEngine(hyde_query_engine, query_transform=hyde)# 3. 运行查询并观察效果
query_str = "Explain the advantages of RAG in a comprehensive way"
response = hyde_query_engine.query(query_str)
print("\n--- HyDE查询转换后响应 ---")
print(response)
- 多重查询重写 (Multi-Query Rewriting): 这种技术旨在将一个模糊的查询分解成多个更具体的子查询,并对每个子查询执行检索,最终合并所有结果 7。这可以有效增加召回率,降低错过相关信息的风险。
#... 承接上文代码...
from llama_index.core import PromptTemplate
from llama_index.llms.openai import OpenAI # 需要配置OpenAI API Key# 1. 定义一个LLM来生成多重查询
# llm = OpenAI(model="gpt-3.5-turbo")# 2. 定义一个提示模板来指导LLM进行查询重写
query_gen_str = """
你是一个有用的助手,能根据一个输入查询生成多个搜索查询。
请生成 {num_queries} 个与以下查询相关的搜索查询,每个查询占一行。
查询: {query}
查询列表:
"""
query_gen_prompt = PromptTemplate(query_gen_str)# 3. 定义一个函数来生成查询列表
def generate_queries(query: str, llm, num_queries: int = 4): response = llm.predict( query_gen_prompt, num_queries=num_queries, query=query ) queries = response.split("\n") queries_str = "\n".join(queries) print(f"生成的查询列表:\n{queries_str}") return queries # 4. 测试多重查询生成
query = "What is RAG?"
generated_queries = generate_queries(query, llm)
# 接下来,你可以对这个列表中的每个查询并行执行检索,并合并结果。
6.6.3 元数据增强:自动化信息提取
通过为文档分块添加丰富的元数据,我们可以极大地提升检索的精准度和灵活性 。 LlamaIndex的IngestionPipeline允许我们使用各种Extractor模块,自动化地从文档中提取有价值的信息,如标题、摘要、关键词等 。
#... 承接上文代码...
from llama_index.core.ingestion import IngestionPipeline
from llama_index.core.extractors import TitleExtractor, SummaryExtractor, KeywordExtractor, QuestionsAnsweredExtractor
from llama_index.core.node_parser import SentenceSplitter# 1. 定义文档预处理的流水线
# 包括分句、标题提取、摘要提取、关键词提取等
# 注意:这些提取器内部通常会调用LLM,因此会产生API调用费用
transformations =, llm=llm), KeywordExtractor(keywords=10, llm=llm), QuestionsAnsweredExtractor(questions=3, llm=llm),
]pipeline = IngestionPipeline(transformations=transformations)# 2. 运行流水线,对文档进行处理
nodes = pipeline.run(documents=documents)# 3. 打印第一个节点的元数据以进行验证
print("\n--- 第一个节点的元数据 ---")
print(nodes.metadata)# 4. 将处理后的节点存入索引
# augmented_index = VectorStoreIndex(nodes)
# 现在你的索引中的每个节点都包含了丰富的元数据
通过这个示例,我们看到每个节点不再只是简单的文本块,而是包含了由LLM自动生成的摘要、关键词和可回答问题等信息。这些元数据在检索时可以被用作强大的过滤器,显著提升召回的精确性 。
7. 结论与未来展望
7.1 高阶RAG技术总结:一个多维度的系统性工程
本报告详细解构了从朴素RAG到高阶RAG的演进路径,并强调了高阶RAG是一个横跨数据预处理、检索和后处理三个关键环节的系统性工程。其核心逻辑是打破传统的单一线性管道,通过在每个环节引入先进技术来解决固有挑战。下表总结了两种范式的根本区别:
| 维度 | 朴素RAG | 高级RAG |
|---|---|---|
| 数据摄取 | 仅处理纯文本,忽略非文本数据 | 能够处理多模态数据,如图片、表格和图表 |
| 分块策略 | 固定大小分块,易破坏上下文 | 语义/层级分块,确保每个分块都是有意义的单元 |
| 检索方法 | 单一的向量相似度搜索 | 混合检索(向量+关键词),融合稀疏与稠密优势 |
| 查询处理 | 直接使用用户查询 | 查询转换(HyDE、多重重写),解决查询意图不对称 |
| 后处理 | 无后处理环节 | 重排序与上下文压缩,精炼检索结果 |
| 核心挑战 | 幻觉、召回率低、答案不准确 | 处理复杂查询、应对信息过载 |
| 核心优势 | 易于实现、快速搭建 | 高可控性、高准确性、处理复杂问题 |
7.2 展望:从RAG到自适应知识引擎的未来
RAG的未来发展远不止于当前的技术优化。随着研究的深入,RAG正从一个“固定框架”演变为一个能够自主学习和适应的“知识引擎”。
- 多模态RAG(Multimodal RAG):未来的RAG系统将不再局限于文本,而是能够从图像、音频和视频等多模态数据中检索和综合信息。例如,能够根据用户对一张医疗图像的描述,检索相关的诊断报告或医学文献。
- 自适应RAG(Adaptive RAG):未来的RAG系统将不再是预设的流程,而是能够根据用户查询类型、上下文和用户反馈动态调整其工作流。例如,对于简单的、事实性的查询,它会选择快速的检索路径;而对于复杂、需要多步推理的查询,它则会启动代理式RAG,进行多步骤的规划和工具调用。这种自适应能力将使RAG系统更加高效、灵活和智能。