DeepSeek R1大模型微调实战-llama-factory的模型下载与训练
文章目录
- 概要
- 1.下载模型
- 2.llama factory 训练模型
- 2.1 模型微调
- 2.2 模型评估
- 2.3 模型对话
- 2.4 导出模型
- 3.硬件选择
概要
LLaMA Factory 是一个简单易用且高效的大型语言模型训练与微调平台。通过它,用户可以在无需编写任何代码的前提下,在本地完成上百种预训练模型的微调。
1.下载模型
在LLaMA Factory页面中,选择了模型后,可能是因为网络原因,会导致加载模型失败,这种情况可以通过把模型自己下载后,然后把模型路径改为本地模型的路径,来解决。
在模型平台上下载模型,比如Hugging Face (https://huggingface.co)
或者采用modelscope,我这里采用modelscope。
pip install modelscopemodelscope download --model deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B --local_dir /home/model/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
# 执行上述指令后,模型参数被下载至:/home/model/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B文件夹。[root@VM-0-9-tencentos DeepSeek-R1-Distill-Qwen-1.5B]# pwd
/home/model/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B
[root@VM-0-9-tencentos DeepSeek-R1-Distill-Qwen-1.5B]# ls -hl
total 3.4G
-rw-r--r-- 1 root root 679 Sep 3 17:16 config.json
-rw-r--r-- 1 root root 73 Sep 3 17:16 configuration.json
drwxr-xr-x 2 root root 27 Sep 3 17:16 figures
-rw-r--r-- 1 root root 181 Sep 3 17:16 generation_config.json
-rw-r--r-- 1 root root 1.1K Sep 3 17:16 LICENSE
-rw-r--r-- 1 root root 3.4G Sep 3 17:20 model.safetensors
-rw-r--r-- 1 root root 16K Sep 3 17:16 README.md
-rw-r--r-- 1 root root 3.0K Sep 3 17:16 tokenizer_config.json
-rw-r--r-- 1 root root 6.8M Sep 3 17:16 tokenizer.json
[root@VM-0-9-tencentos DeepSeek-R1-Distill-Qwen-1.5B]# 2.llama factory 训练模型
2.1 模型微调
在图形化UI界面设置模型名称、模型路径和数据集,这里我以LLama-Factory中自带的多模态数据集“mllm_demo”数据集为例:
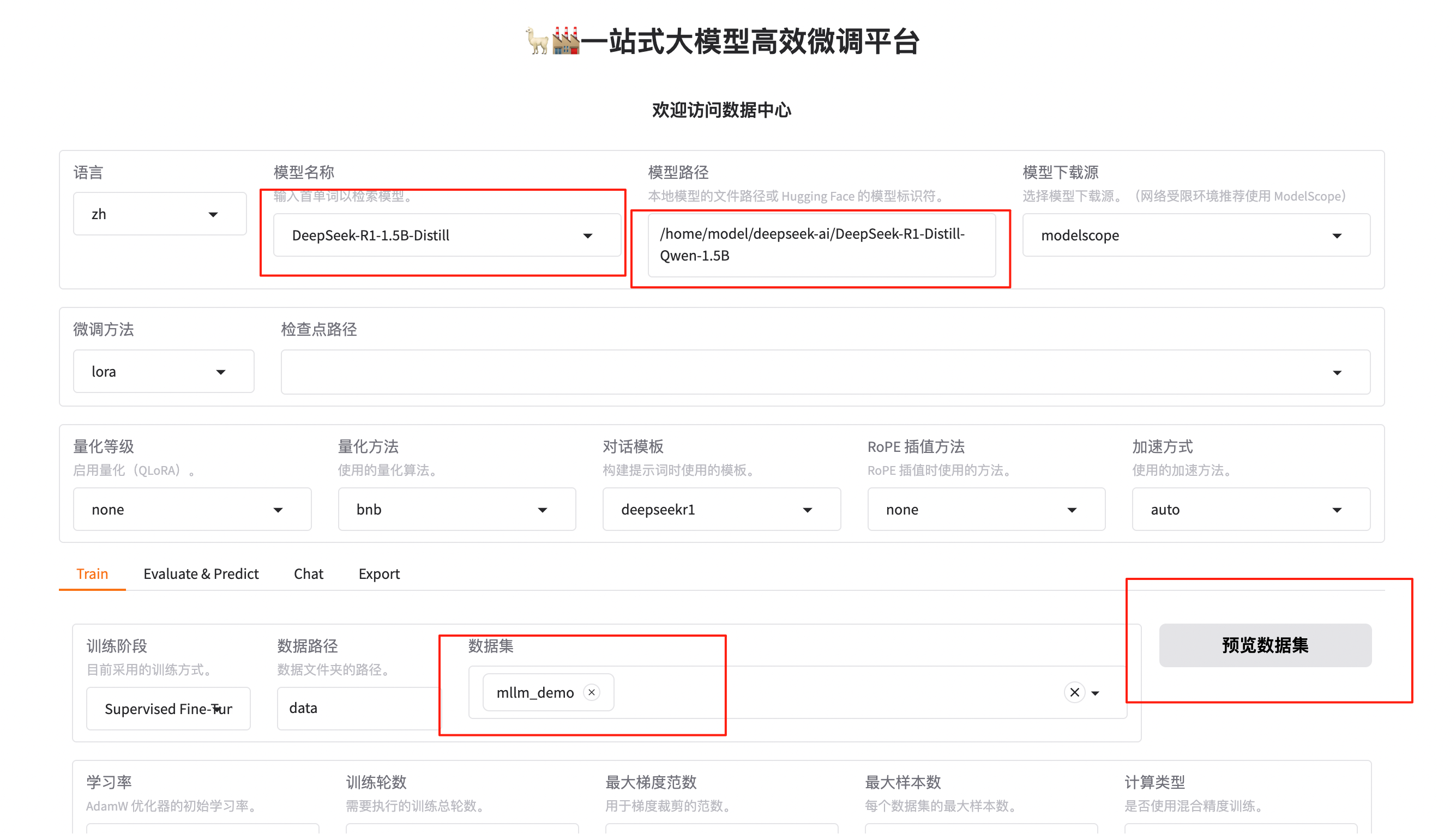
可以选择预览数据集,预览数据结构:

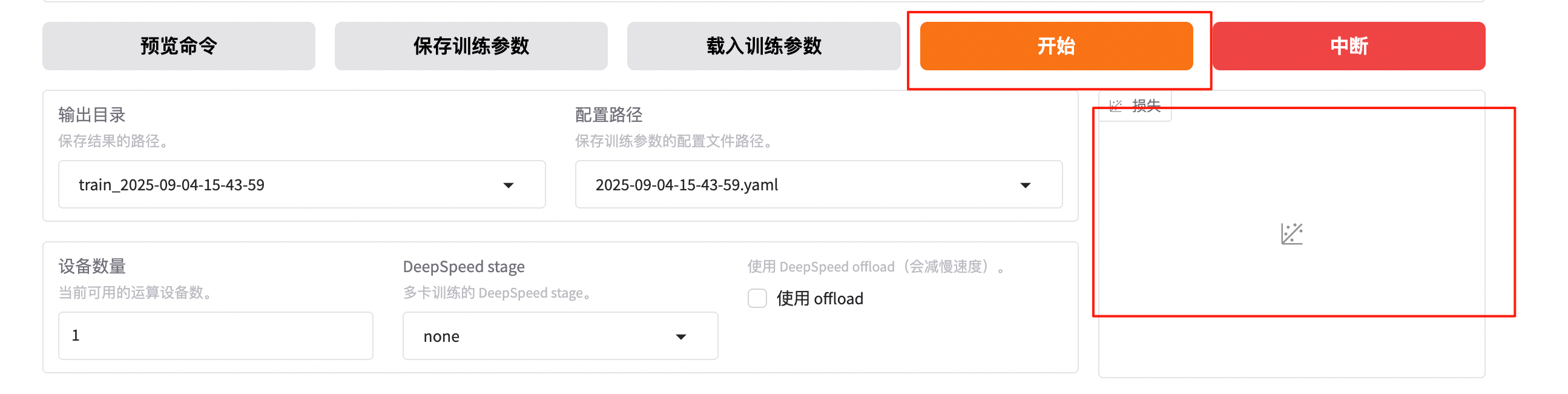
可以选择预览命令查看模型训练的实际指令,输出目录可以选择默认以时间戳命名的路径,确认没问题后点“开始”即可开始训练.训练时,在右下角可以实时查看loss下降的曲线,非常直观和方便.
2.2 模型评估
-
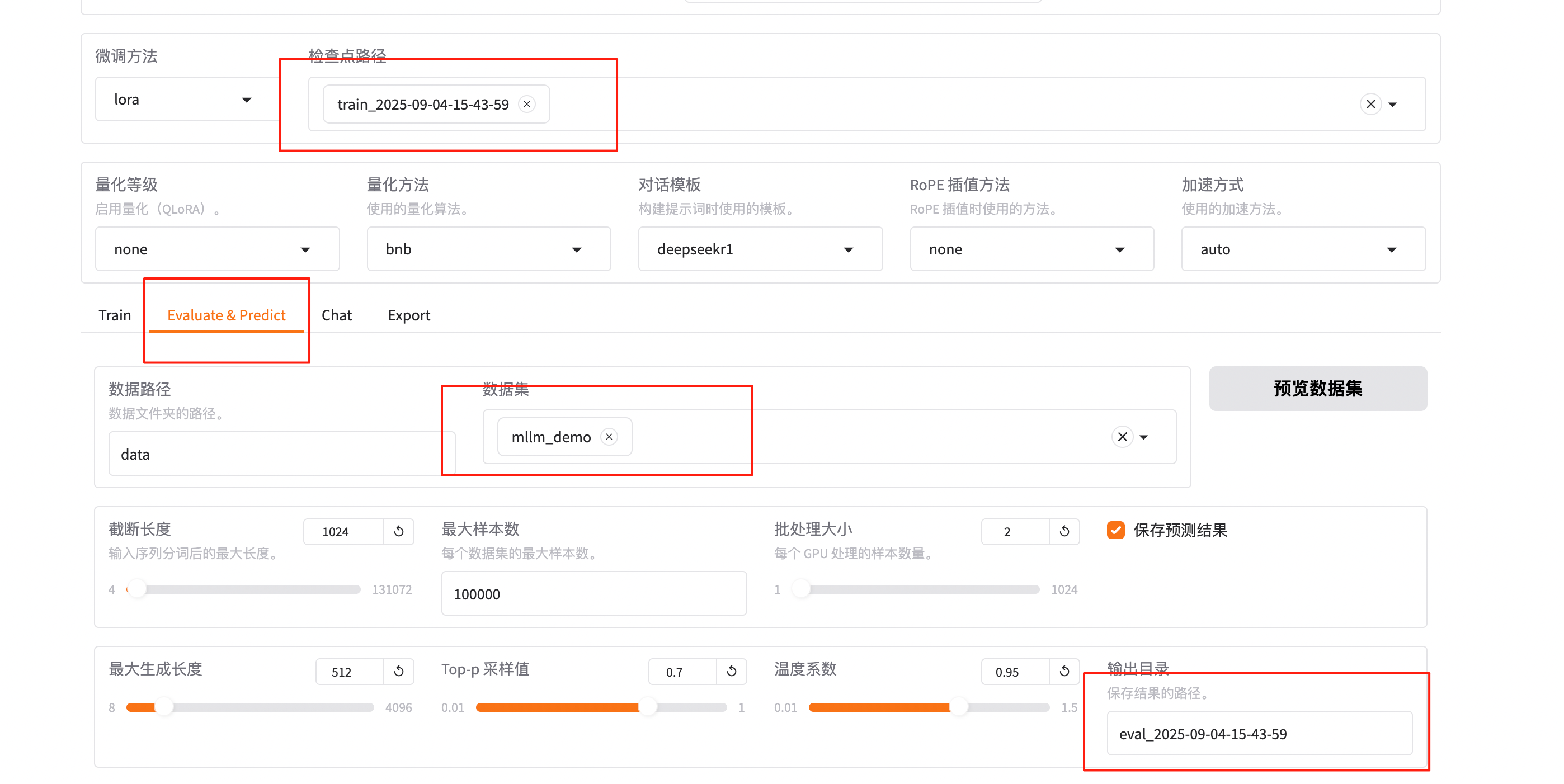
模型微调完成后,检查点路径下拉选择train_2025-09-04-15-43-59。
-
在Evaluate&Predict页签中,数据集选择mllm_demo(验证集)评估模型,并将输出目录修改为eval_2025-09-04-15-43-59,模型评估结果将会保存在该目录中。
-
单击开始,启动模型评估。模型评估大约需要5分钟,评估完成后会在界面上显示验证集的分数。其中,ROUGE分数衡量了模型输出答案(predict)和验证集中的标准答案(label)的相似度,ROUGE分数越高代表模型学习得越好。

2.3 模型对话
训练好以后可以设置检查点路径等参数:
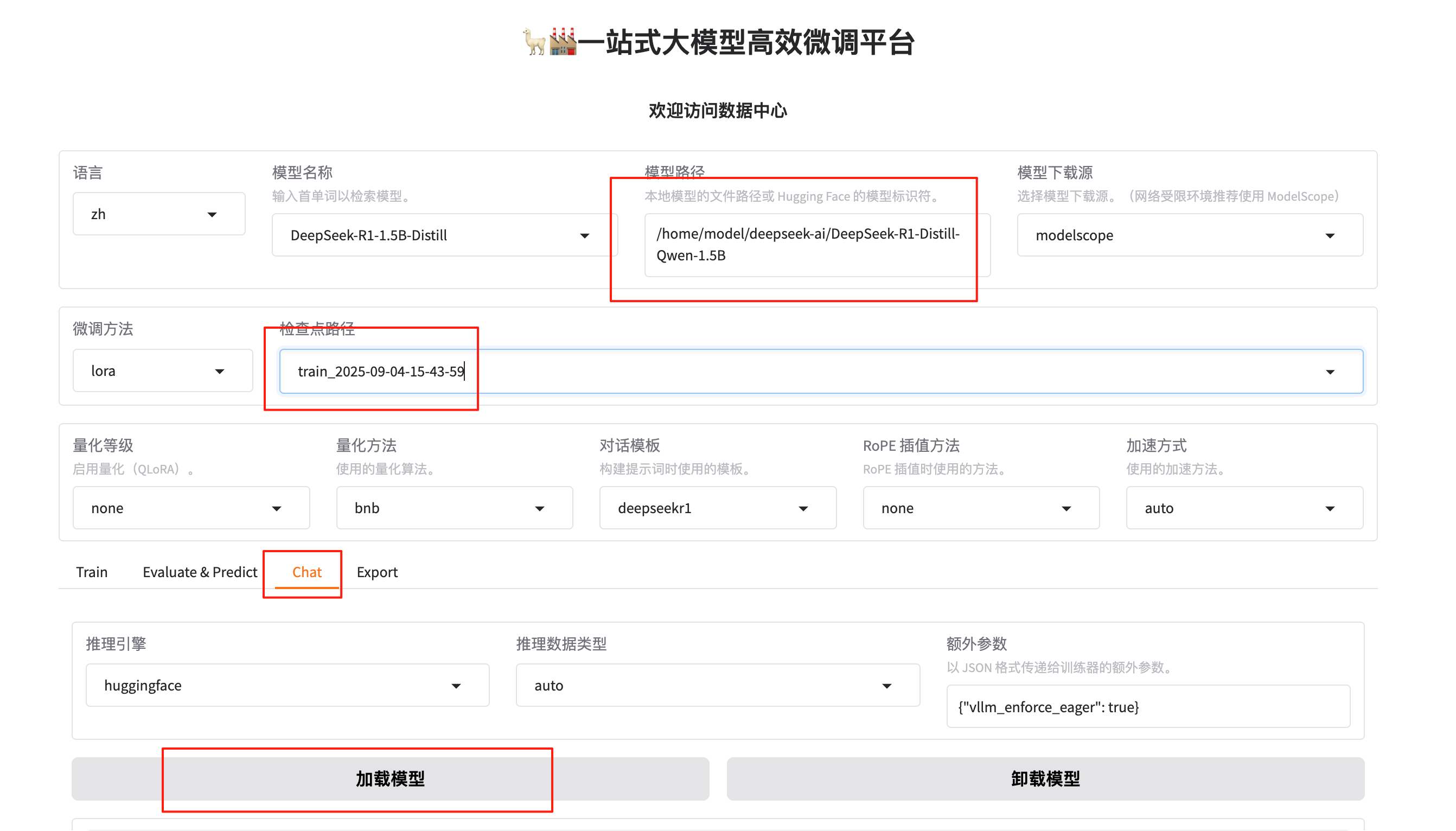
点击加载模型,在页面底部的对话框输入想要和模型对话的内容,单击提交,即可发送消息。发送后模型会逐字生成回答,从回答中可以发现模型学习到了数据集中的内容,能够恰当地模仿目标角色的语气进行对话。
单击卸载模型和取消检查点路径,然后单击加载模型,即可与微调前的原始模型聊天。你会发现提出同样的问题,回答结果是不一样的。
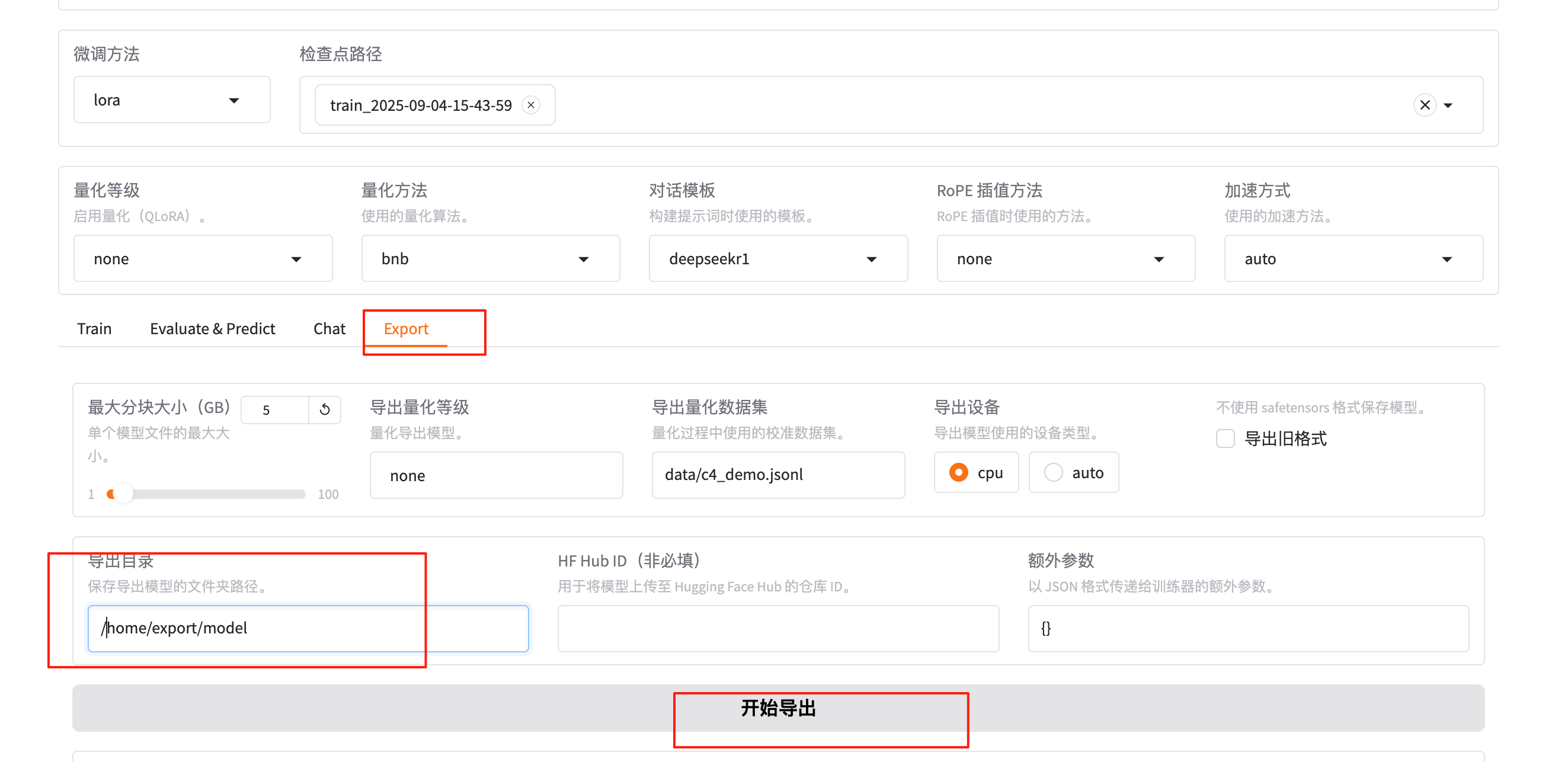
2.4 导出模型
训练完成后,可以融合lora参数,导出作为一个新的模型。新的训练好的模型参数结构和原来的模型(例如DeepSeek-R1-1.5B-Distill)结构一致。新的模型加载后,可以开始新的对话。
3.硬件选择
可以采用第三方平台或者接口实现DeepSeek会话,这里采用本地部署开源大模型。下面列出了不同大小的DeepSeek模型对应的显存和内存需求。请根据你的显卡配置和MacOS系统的内存选择合适的模型。
| 模型大小 | 显存需求(FP16 推理) | 显存需求(INT8 推理) | 推荐显卡 | MacOS 需要的 RAM |
|---|---|---|---|---|
| 1.5b | 3GB | 2GB | RTX 2060/MacGPU 可运行 | 8GB |
| 7b | 14GB | 10GB | RTX 3060 12GB/4070 Ti | 16GB |
| 8b | 16GB | 12GB | RTX 4070/MacGPU 高效运行 | 16GB |
| 14b | 28GB | 20GB | RTX 4090/A100-40G | 32GB |
| 32b | 64GB | 48GB | A100-80G/2xRTX4090 | 64GB |
如果电脑的显存不够用,可以通过量化来减少对显存的需求。量化就是把模型的参数从较高的精度(比如32位)转换为较低的精度(比如8位),这样可以节省显存空间,让你的电脑能够运行更大的模型。举个例子,如果你的电脑显存是8GB,而你想使用7b参数的模型,但显存不足,那么通过量化处理后,你就可以在不增加硬件的情况下,使用这个大模型。
如果你不确定自己是否需要量化,可以参考下面的显卡显存列表来判断自己电脑的显存是否足够运行所需的模型。
| 显存大小 | 显卡型号 |
|---|---|
| 3GB | GTX 1060 3GB |
| 4GB | GTX 1050 Ti |
| 6GB | GTX 1060 6GB, RTX 2060 6GB, RTX 3050 (6GB) |
| 8GB | GTX 1080, GTX 1070 Ti, RTX 2080 SUPER, RTX 2080, RTX 2070 SUPER, RTX 2070, RTX 2060, RTX 2060 SUPER, RTX 3070, RTX 3070 Ti, RTX 3060 Ti, RTX 3060 (8GB), RTX 3050 (8GB), RTX 4080, RTX 4060 Ti, RTX 4060, RTX 5070 |
| 11GB | GTX 1080 Ti, RTX 2080 Ti |
| 12GB | GRTX 2060 12GB, RTX 3060 (12GB), RTX 4070 Ti SUPER, RTX 4070, RTX 5070 Ti |
| 16GB | RTX 4060 Ti 16GB, RTX 5080 |
| 24GB | RTX 3090 Ti, RTX 3090, RTX 4080, RTX 4090 |
| 32GB | RTX 5090 |
以上就是在 CentOS 上模型下载与训练的基本步骤。如果你遇到任何问题,可以查看 LLaMA Factory 的 GitHub 仓库中的文档或寻求社区的帮助。