数据结构——顺序表和单向链表(2)
目录
前言
一、单向链表
1、基本概念
2、单向链表的设计
(1)节点设计
(2)初始化空单向链表
(3)、初始化数据节点
(4)数据节点
(5)判断链表是否为空
(6)遍历链表
(7)删除数据
(8)销毁整个链表
(9)修改数据
前言
在软件的世界里,程序 = 数据结构 + 算法。这句广为流传的名言,深刻地揭示了数据结构的核心地位。它是我们组织、存储和管理数据的艺术,是构建高效、稳定应用程序的基石。而在众多数据结构中,线性表作为最基础、最常用的一种,其重要性不言而喻。
顺序表和单向链表,正是线性表两种最经典的实现方式。它们如同“一体两面”,代表了计算机中两种最根本的物理存储思想:连续的空间与离散的空间。
顺序表凭借其底层连续的物理结构,带来了无与伦比的随机访问性能,仿佛一本页码清晰的书籍,我们可以根据目录瞬间翻到任何一页。然而,这种连续性的代价便是在中间进行插入或删除时,可能引发大规模的“数据搬迁”,效率堪忧。
单向链表则巧妙地利用指针,将离散的内存空间“串联”起来。它牺牲了随机访问的能力,换来了在任意位置高效插入与删除的灵活性,如同一条环环相扣的链条,只需改变节点的指向,即可轻松完成结构的调整。
理解二者的内在原理、优缺点以及适用场景,是每一位开发者内功修炼的必经之路。这不仅是为了应对面试官的考问,更是为了在未来的开发中,能够根据实际需求,做出最合理的技术选型,写出性能更优、更优雅的代码。
一、单向链表
1、基本概念
概念:
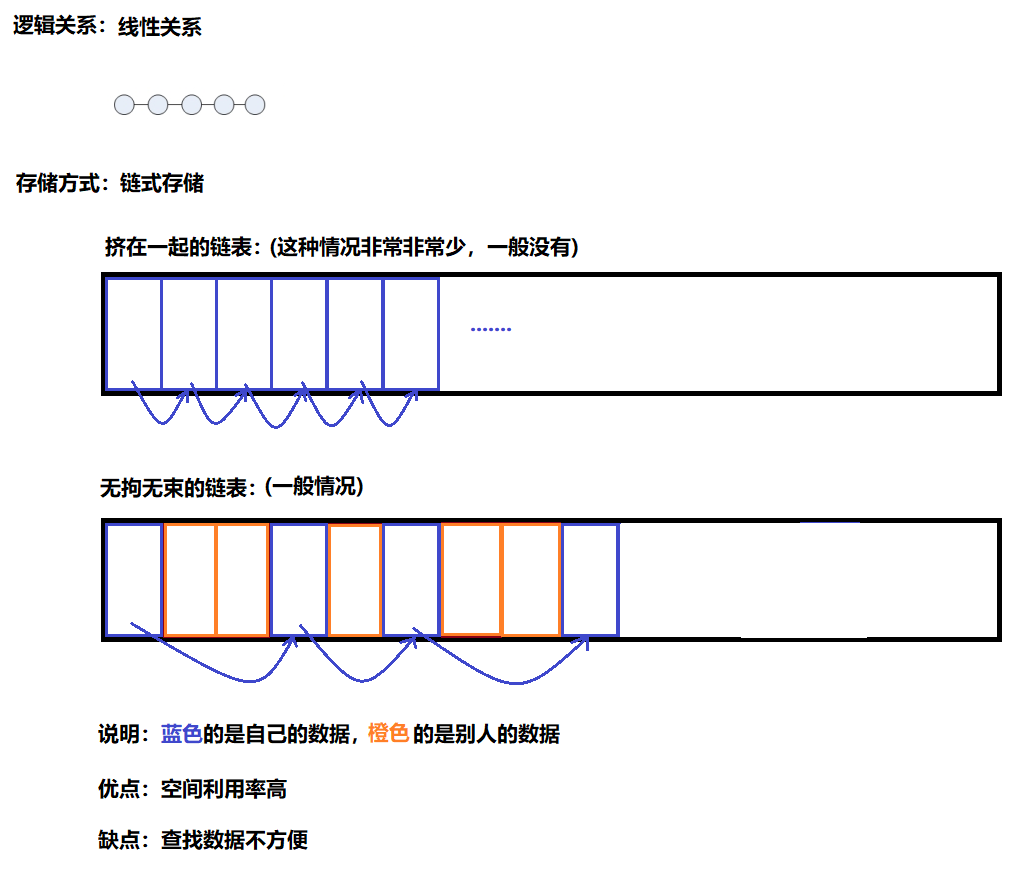
链式存储的线性表,简称链表(线性关系+链式存储)
图解:
说明:
既然顺序存储中的数据因为挤在一起而导致需要成片移动,那很容易想到的解决方案是将数据离散的存储在不同的内存块中,然后用指针将它们串起来,这种朴素的思路所形成的链式线性表,就是所谓链表(单向链表(单向循环链表)、双向链表(双向循环链表))
2、单向链表的设计
1、节点设计 2、初始化空单向链表(初始化头节点) 3、初始化数据节点 4、增删查改单向链表// 前提:判断链表是否为空a、增:头插法、尾插法b、查:遍历链表c、删:删除链表中的某个数据、销毁整个链表d、改:修改链表中的某个数据(1)节点设计
说明:
单向链表节点包含两个域,一个数据域一个指针域,数据域存放用户的数据,指针域指向本节点或指向相邻下一个节点。
typedef struct node {// 数据域int data; // 指针域struct node* next_p; // 指向相邻的下一个节点的指针}node_t, *node_p;(2)初始化空单向链表
概念:
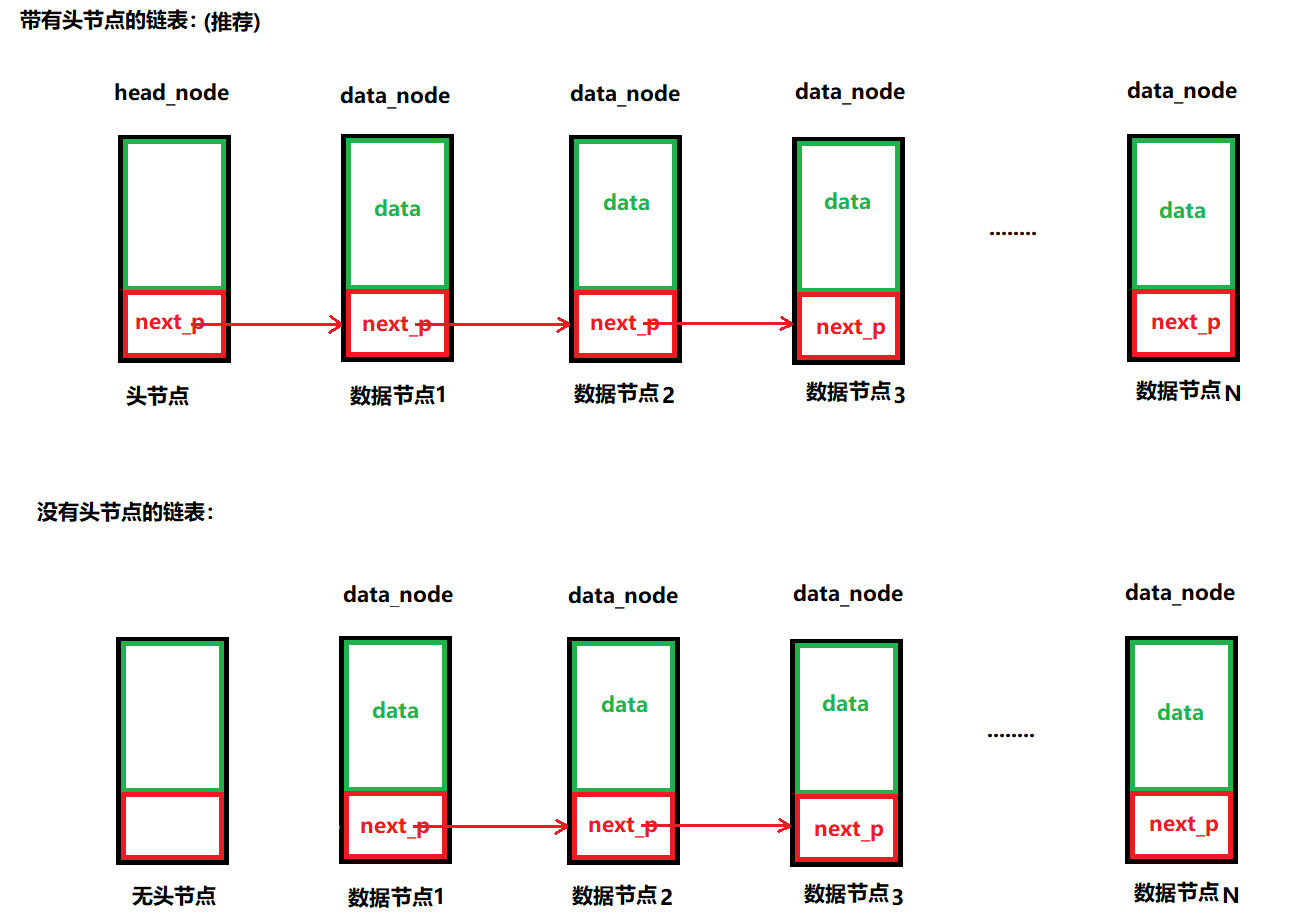
首先链表有两种常见的形式,一种是带有所谓的头节点的,一种是不带头节点的,所谓的头节点是不存放有效数据的节点,仅仅用来方便操作
图解:
注意:
头节点head_node是可选的,为了方便某些操作,建议大家有头节点好一些
头节点的指针:head_node的next_p
说明:
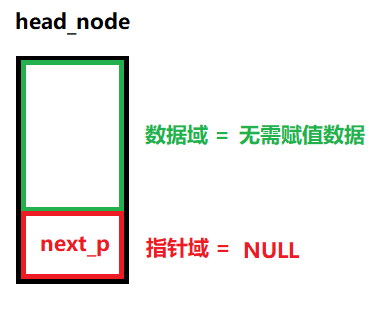
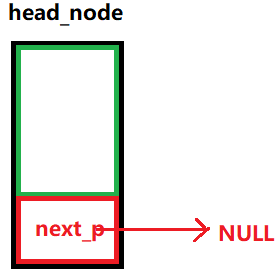
由于头节点不存放有效数据的,因此如果空链表中带有头节点,那么头指针(head_node的next_p)将永远不变,这会给以后的链表操作带来些许便捷
图解:
示例代码:
/*** @brief 初始化空单向链表(初始化头节点)* @note None* @param None* @retval 成功:返回指向这个头节点的指针* 失败:返回NULL */ node_p LINK_LIST_InitHeadNode(void) {// 1、给头节点申请一个内存空间(堆内存)node_p p = malloc(sizeof(node_t));bzero(p, sizeof(node_t));// 2、将头节点的next_p指针指向NULLif ( p!= NULL){// 数据域// 指针域p->next_p = NULL; // 防止指针乱指}else{return NULL;}// 3、成功返回头节点return p; }(3)、初始化数据节点
说明:
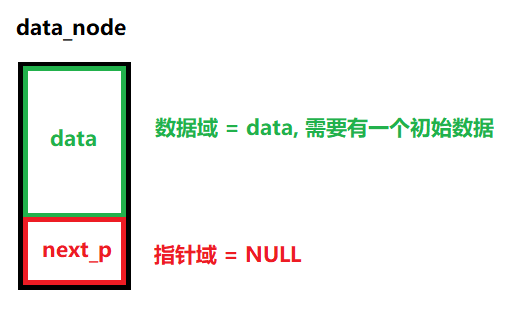
数据节点
图解:
示例代码:
/*** @brief 初始化数据节点* @note None* @param data:数据节点中的数据* @retval 成功:返回指向这个数据节点的指针* 失败:返回NULL */ node_p LINK_LIST_InitDataNode(int data) {// 1、给数据节点申请一个内存空间(堆内存)node_p p = malloc(sizeof(node_t));bzero(p, sizeof(node_t));// 2、将数据节点的next_p指针指向NULL,并且将传进来的数据对此节点的数据进行赋值if ( p != NULL){// 数据域p->data = data; // 数据赋值// 指针域p->next_p = NULL; // 防止指针乱指}else{return NULL;}// 3、成功返回数据节点return p;}(4)数据节点
说明:
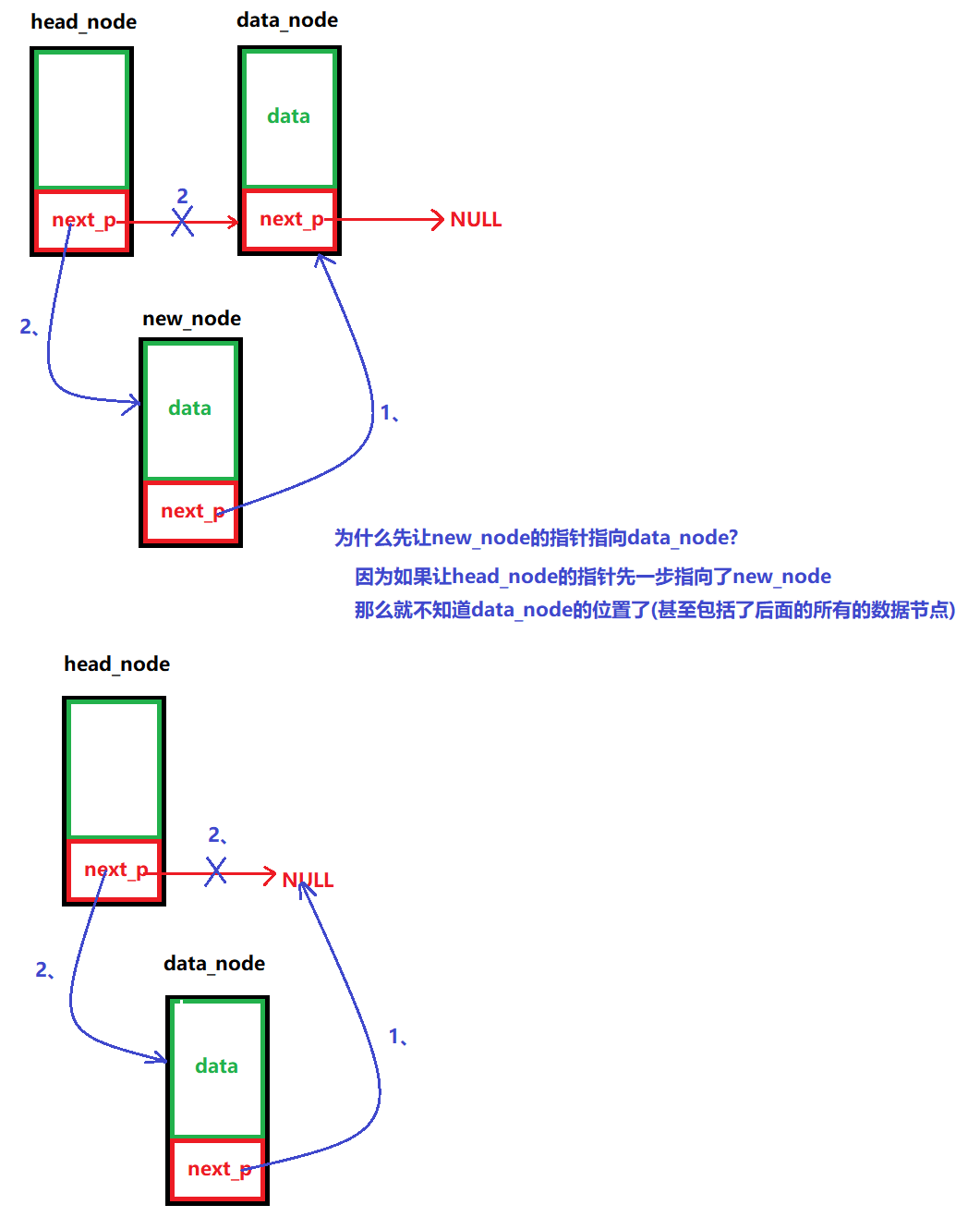
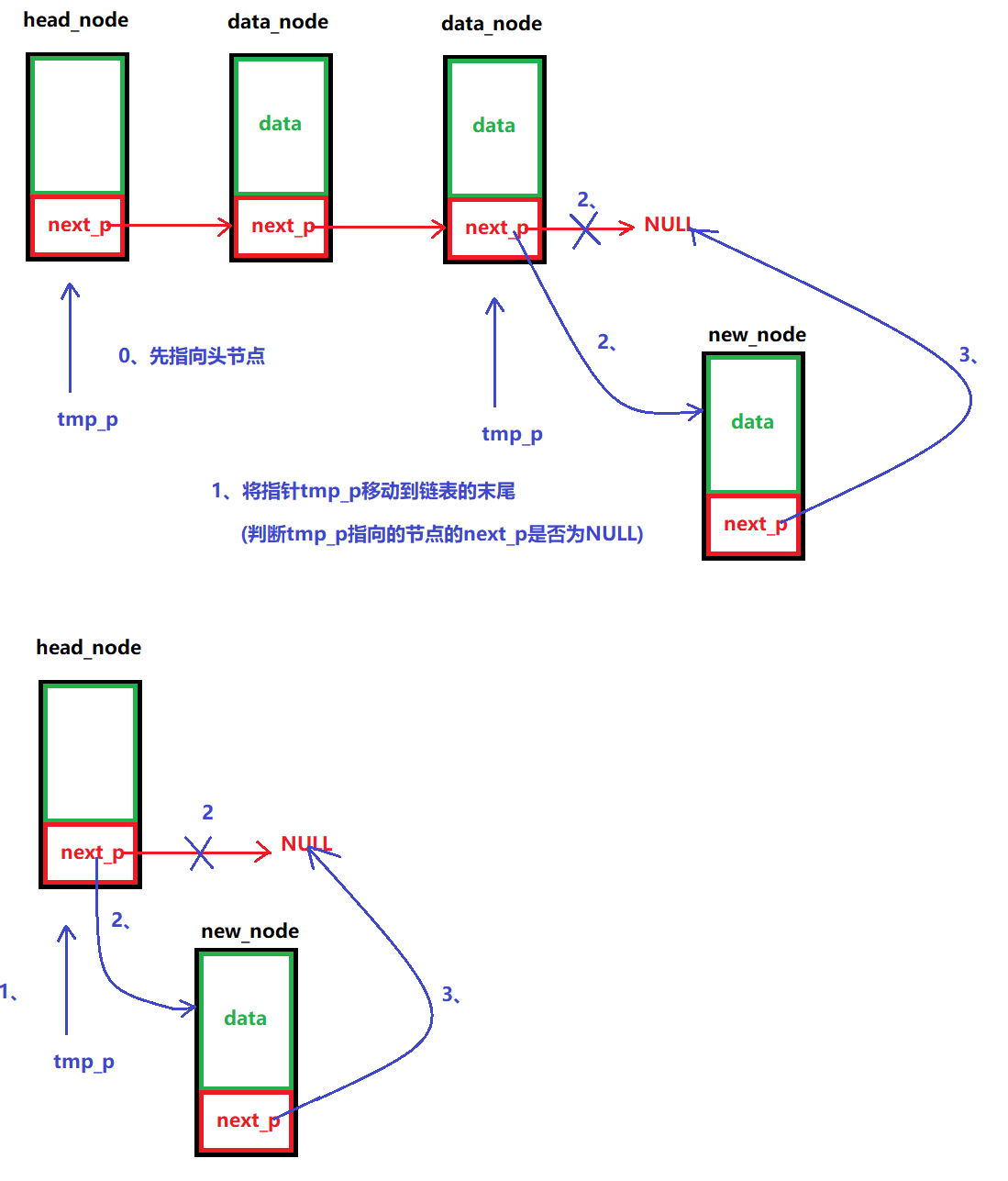
将数据节点插入到链表中,一种头插法(链表中的头节点的后面插进去),一种尾插法(链表中的最后一个节点后面插入进去)
图解:
头插法:
尾插法:
示例代码:
/*** @brief 插入数据(头插法)* @note None* @param head_node:头节点* new_node: 要插入的数据节点* @retval None */ void LINK_LIST_InsertHeadDataNode(node_p head_node, node_p new_node) {// 1、先让new_node里面的next_p指向data_node (head_node->next_p里面有data_node的地址)new_node->next_p = head_node->next_p;// 2、再让head_node里面的next_p指向new_nodehead_node->next_p = new_node; }/*** @brief 插入数据(尾插法)* @note None* @param head_node:头节点 * new_node: 要插入的数据节点* @retval None */ void LINK_LIST_TailInsertDataNode(node_p head_node, node_p new_node) {// 1、设置一个中间指针,将指针指向单向链表的末尾节点node_p tmp_p = NULL;for (tmp_p = head_node; tmp_p->next_p != NULL; tmp_p = tmp_p->next_p);// 2、让tmp_p的next_p指向新节点tmp_p->next_p = new_node;// 3、再让new_node的next_p指向NULLnew_node->next_p = NULL; }(5)判断链表是否为空
说明:
如果头节点的next_p指向的是NULL,那么就可以证明这个链表是空的
图解:
示例代码:
/*** @brief 判断链表是否为空* @note None* @param head_node:头节点 * @retval 如果链表为空:返回true* 如果链表非空:返回false */ bool LINK_LIST_IfEmpty(node_p head_node) {return head_node->next_p == NULL; }(6)遍历链表
说明:
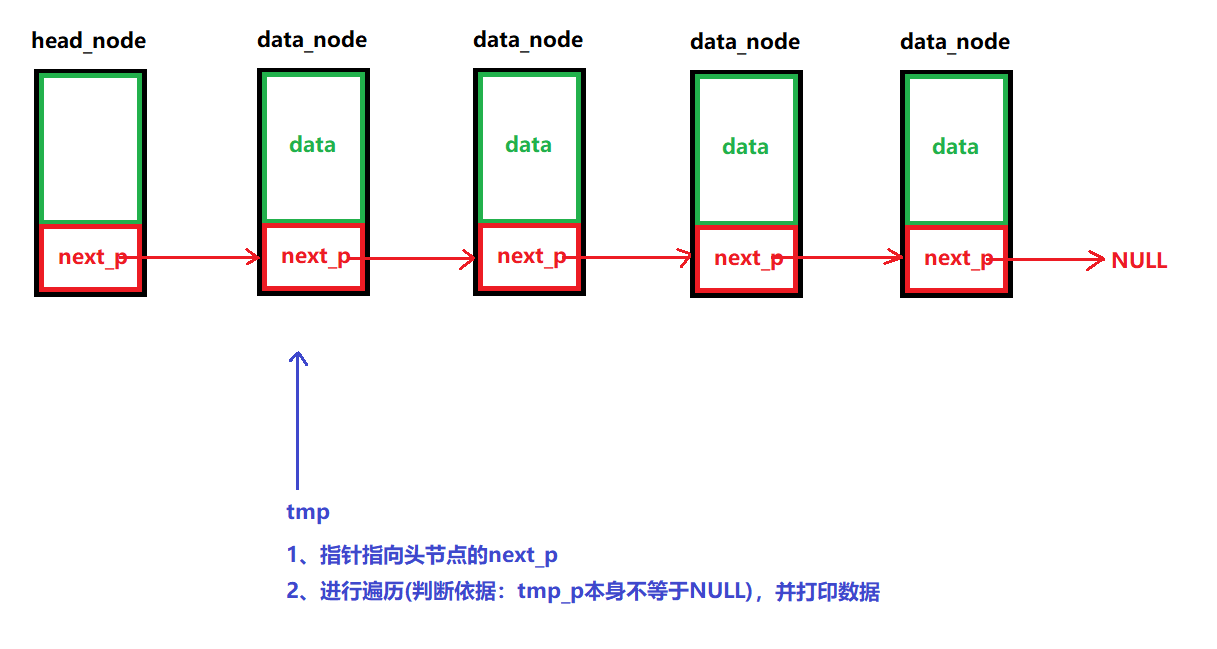
遍历整个链表,并逐个打印里面的数据
图解:
示例代码:
/*** @brief 遍历整个链表并打印出里面的数据* @note None* @param head_node:头节点 * @retval 成功:返回0* 失败:返回-1 */ int LINK_LIST_ShowListData(node_p head_node) {// 1、判断链表是否为空,是的话,返回-1if (LINK_LIST_IfEmpty(head_node))return -1;// 2、遍历整个链表,并逐个打印里面的数据node_p tmp_p = NULL;int i = 0;printf("======================链表中的数据==========================\n");for ( tmp_p = head_node->next_p; tmp_p!=NULL; tmp_p=tmp_p->next_p){printf("链表中的第%d的节点, 数据为: %d\n", i, tmp_p->data);i++;}printf("===========================================================\n");// 3、成功返回0return 0; }(7)删除数据
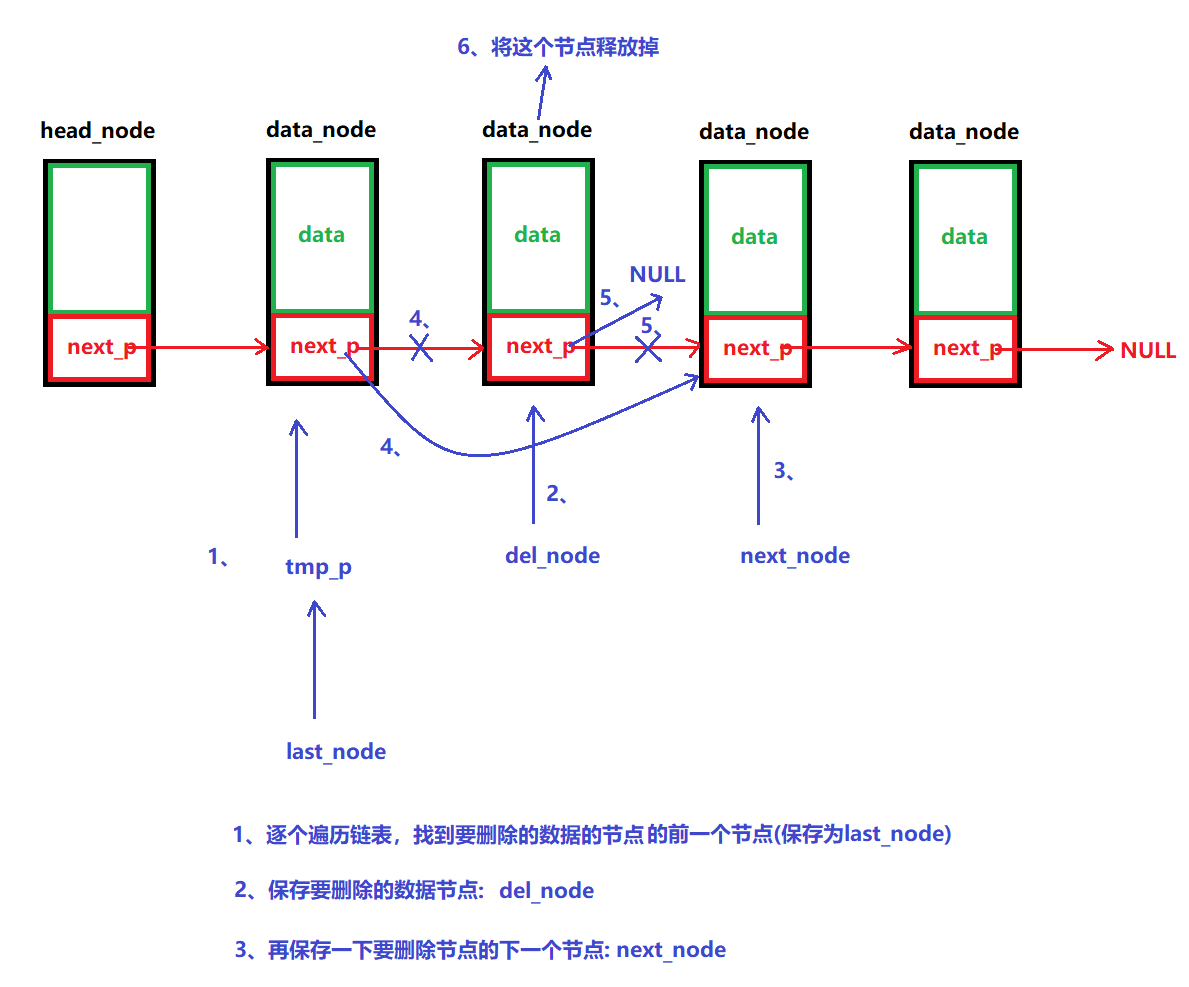
说明:
根据数据来删除链表中的节点
图解:
示例代码:
/*** @brief 删除数据* @note 根据数据的值找到链表中的节点,并将其删除* @param head_node:头节点 * del_data: 要删除的数据 * @retval 成功:返回0* 失败:返回-1 */ int LINK_LIST_DelDataNode(node_p head_node, int del_data) {// 1、判断链表是否为空,是的话,返回-1if (LINK_LIST_IfEmpty(head_node))return -1;// 2、移动到要删除的节点数据那里去node_p tmp_p = NULL;node_p last_node = NULL;node_p del_node = NULL;node_p next_node = NULL;// a、从头到尾遍历一遍,找到要删除的数据for (tmp_p = head_node; tmp_p->next_p!=NULL; tmp_p=tmp_p->next_p){// b、判断要删除的数据if ( (tmp_p->next_p->data) == del_data){// c、保存删除数据的上一个节点和下一个节点、及删除节点last_node = tmp_p;del_node = tmp_p->next_p;next_node = del_node->next_p; break;}}// 3、绕过原链表要删除的节点last_node->next_p = next_node;del_node->next_p = NULL;// 4、释放要删除节点的资源free(del_node);// 5、成功返回0return 0;}(8)销毁整个链表
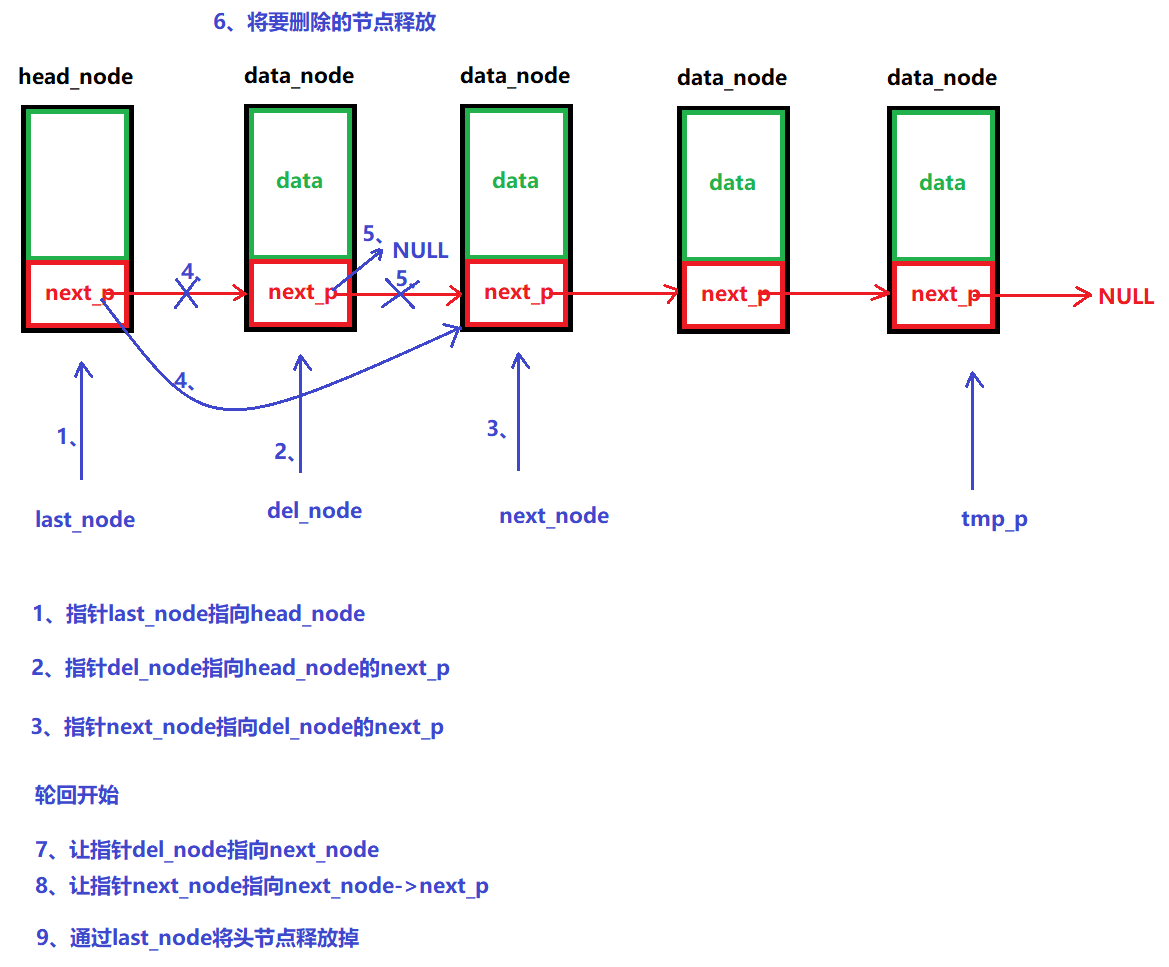
说明:
从头节点开始,将其后面的数据节点一个个删除,最后再删除头节点本身
图解:
示例代码:
/*** @brief 销毁链表* @note None* @param head_node:头节点 * @retval None */ void LINK_LIST_UnInit(node_p head_node) {// 1、如果链表为空,那么直接释放头节点空间即可if (LINK_LIST_IfEmpty(head_node)){free(head_node);return;}// 2、node_p tmp_p = NULL; // 遍历node_p last_node = head_node;node_p del_node = head_node->next_p;node_p next_node = del_node->next_p;int num = 0;// 如果链表只有一个数据节点if (next_node == NULL){last_node->next_p = next_node;free(del_node);}// 否则else{for (tmp_p = head_node; tmp_p->next_p!=NULL; tmp_p=tmp_p->next_p){// a、删除节点并释放其内存last_node->next_p = next_node;free(del_node);printf("num == %d\n", num);num++;// b、轮回继续del_node = next_node;next_node = next_node->next_p;}// 少删除了一个节点数据last_node->next_p = next_node;free(del_node);}// 3、释放头节点free(head_node); }(9)修改数据
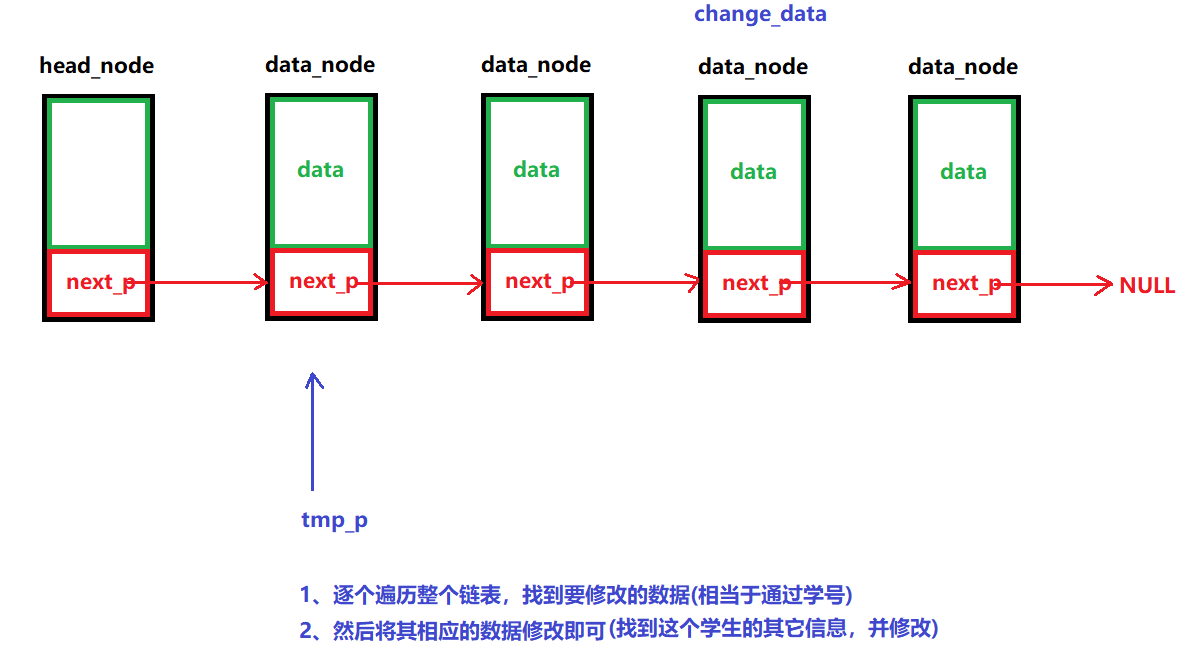
说明:
通过数据值,找到链表中的节点,并修改里面的数据
图解:
示例代码:
/*** @brief 修改数据* @note 根据数据的值来找到链表中的节点,对里面的数据进行修改* @param head_node: 头节点 * data: 要修改的数据* change_data:修改的数据* @retval 成功:返回0* 失败:返回-1 */ int LINK_LIST_ChangeNodeData(node_p head_node, int data, int change_data) {// 1、如果链表为空,那么直接释放头节点空间即可if (LINK_LIST_IfEmpty(head_node))return -1;// 2、遍历整个链表,找到数据的节点,并修该节点的相应的数据node_p tmp_p = NULL;// a、遍历所有可能for (tmp_p = head_node->next_p; tmp_p!=NULL; tmp_p=tmp_p->next_p){// b、找到要修改的数据if ((tmp_p->data) == data) // 根据学号{tmp_p->data = change_data; // 修改这个学生的其它信息break;} }// 3、成功返回0return 0; }