# Shell 文本处理三剑客:awk、sed 与常用小工具详解
文章目录
- 一、awk:文本分析工具
- 1. 概述
- 2. 工作原理
- 3. 基本语法
- 4. 常用内置变量
- 5. 实战示例
- ① 打印指定列
- ② 条件过滤
- ③ 统计行数
- ④ 使用 BEGIN 和 END
- 二、sed:流编辑器
- 1. 概述
- 2. 工作原理
- 3. 常用选项
- 4. 常用命令
- 5. 实战示例
- ① 替换文本
- ② 删除行
- ③ 插入内容
- ④ 提取IP地址
- 三、常用文本处理小工具
- 1. cut:按列截取
- 2. sort:排序
- 3. uniq:去重(需先排序)
- 4. tr:字符替换/删除
- 四、生产环境综合应用
- 1. SS
- 五、总结对比
一、awk:文本分析工具
1. 概述
AWK 是一种强大的文本处理语言,适用于扫描、过滤、统计和格式化文本输出。其名称来源于三位创始人姓氏的首字母:Alfred Aho、Peter Weinberger 和 Brian Kernighan。
2. 工作原理
- 逐行读取输入(文件、管道或标准输入)
- 按指定分隔符(默认为空格或制表符)分割每行为多个字段
- 根据模式匹配执行相应动作
- 支持变量、条件判断、循环等编程结构
3. 基本语法
awk [选项] '模式 { 动作 }' 文件
4. 常用内置变量
| 变量 | 说明 |
|---|---|
$0 | 当前整行内容 |
$1, $2… | 第1、2…个字段 |
NF | 当前行的字段数 |
NR | 当前行号 |
FS | 输入字段分隔符(默认空格) |
OFS | 输出字段分隔符(默认空格) |
FILENAME | 当前文件名 |
5. 实战示例
① 打印指定列
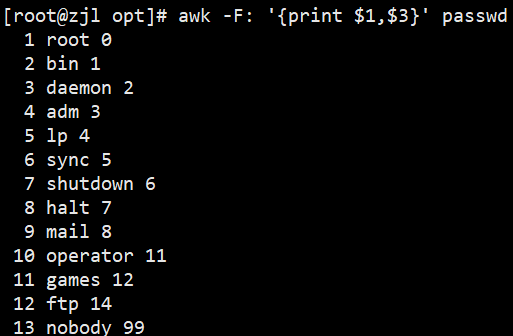
awk -F: '{print $1,$3}' /etc/passwd # 以冒号分隔,输出第1和第3列
② 条件过滤
awk -F: '$3 >= 1000 {print $1}' /etc/passwd # 输出UID≥1000的用户名

③ 统计行数
awk 'END{print NR}' /etc/passwd # 打印总行数

④ 使用 BEGIN 和 END
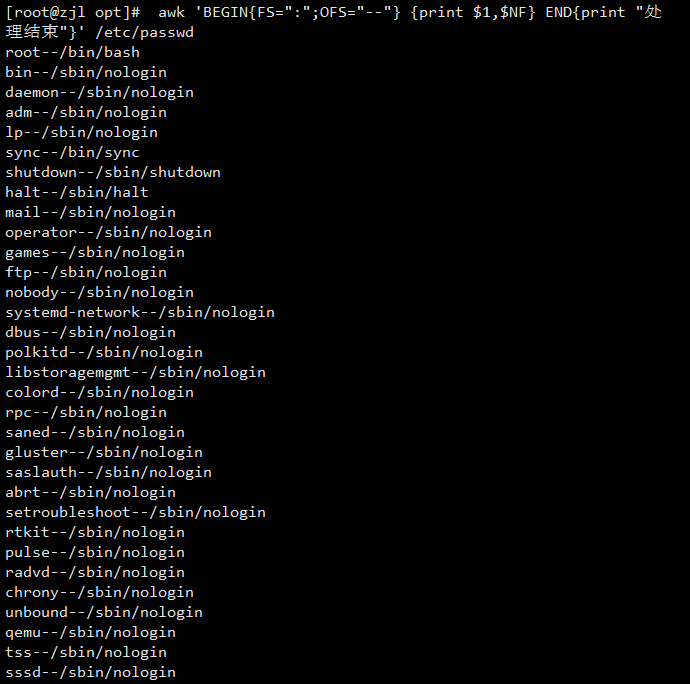
awk 'BEGIN{FS=":";OFS="--"} {print $1,$NF} END{print "处理结束"}' /etc/passwd
二、sed:流编辑器
1. 概述
sed 用于对文本进行流式编辑,支持查找、替换、删除、插入等操作,适用于自动化脚本和批量处理。
2. 工作原理
- 逐行读取文本到模式空间(pattern space)
- 按脚本指令处理文本
- 将结果输出到标准输出
- 默认不修改原文件(除非使用
-i选项)
3. 常用选项
| 选项 | 说明 |
|---|---|
-n | 禁止默认输出 |
-e | 执行多条命令 |
-f | 从文件读取命令 |
-i | 直接修改原文件 |
-r | 使用扩展正则表达式 |
4. 常用命令
| 命令 | 说明 |
|---|---|
s | 替换 |
d | 删除 |
p | 打印 |
a | 在行后插入 |
i | 在行前插入 |
c | 替换整行 |
5. 实战示例
① 替换文本
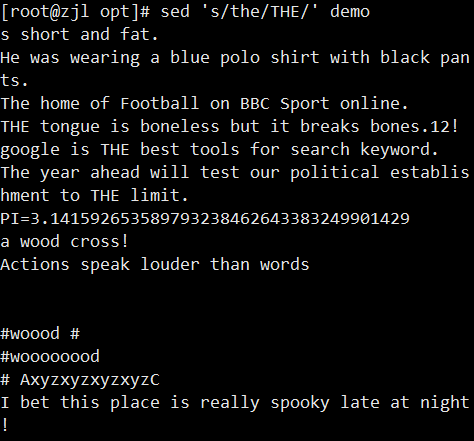
sed 's/old/new/g' file.txt # 全局替换
sed -i 's/old/new/g' file.txt # 直接修改原文件
② 删除行
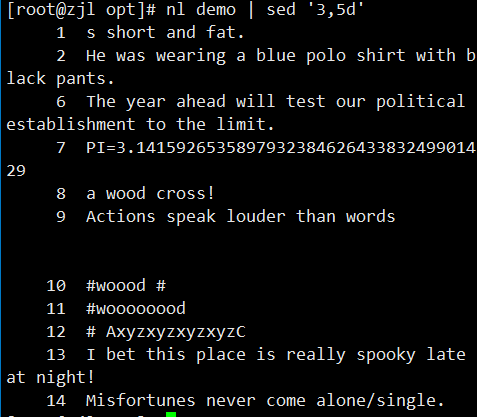
sed '1,5d' file.txt # 删除1~5行
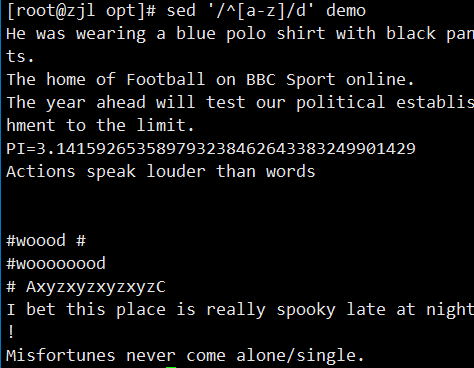
sed '/pattern/d' file.txt # 删除匹配行
③ 插入内容
sed '3a\插入的内容' file.txt # 在第3行后插入
sed '/pattern/i\插入的内容' file.txt # 在匹配行前插入
④ 提取IP地址
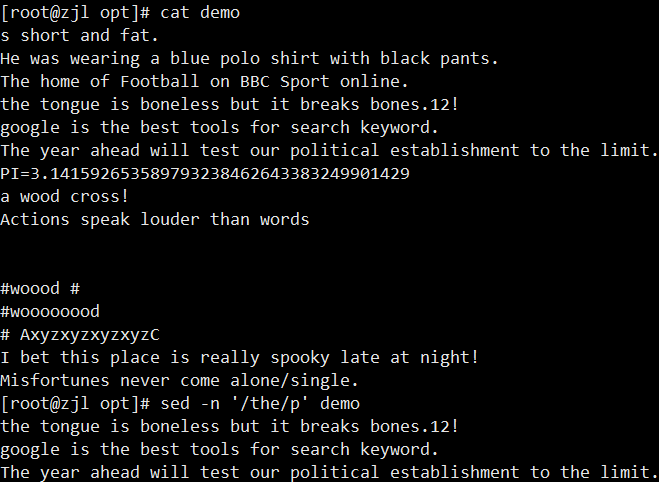
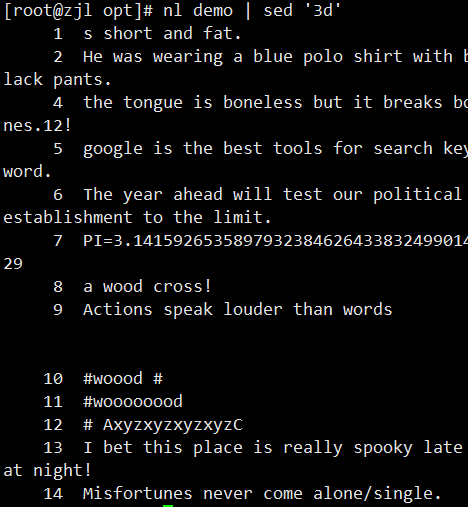
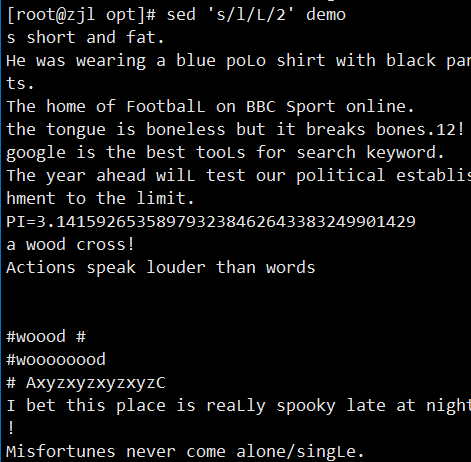
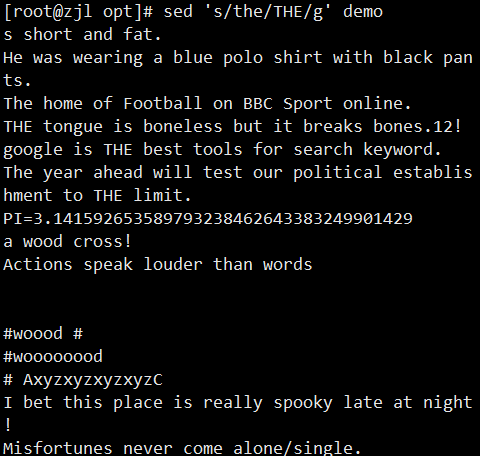
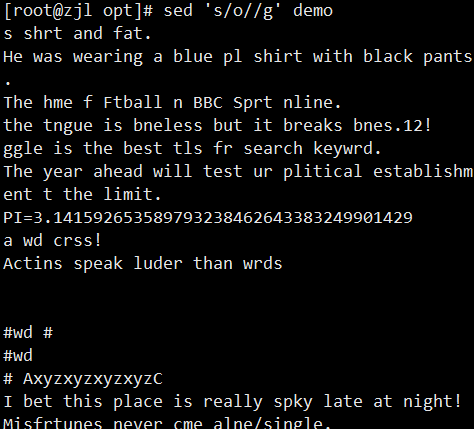
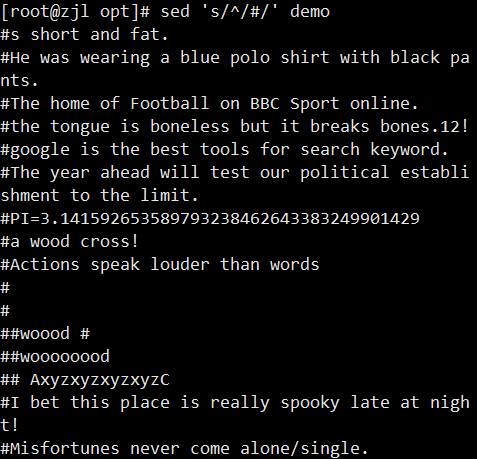
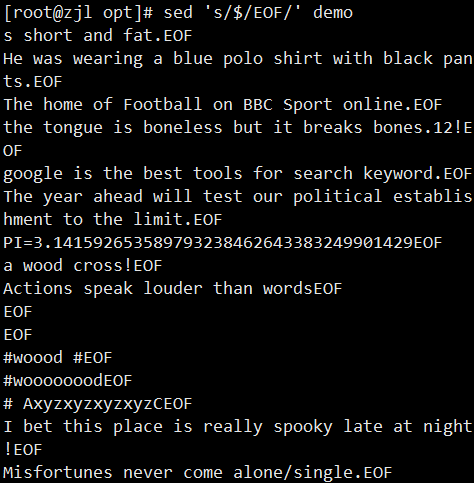
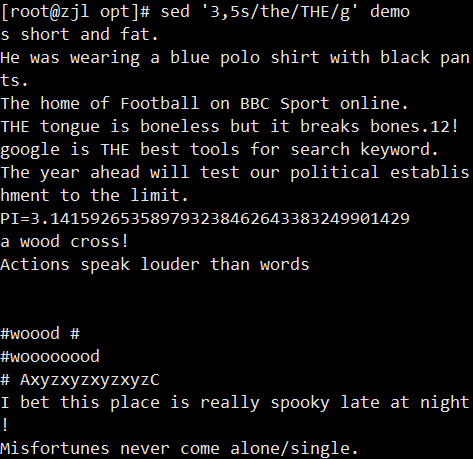
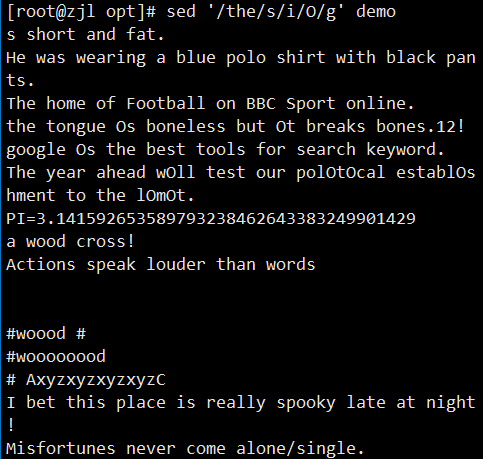
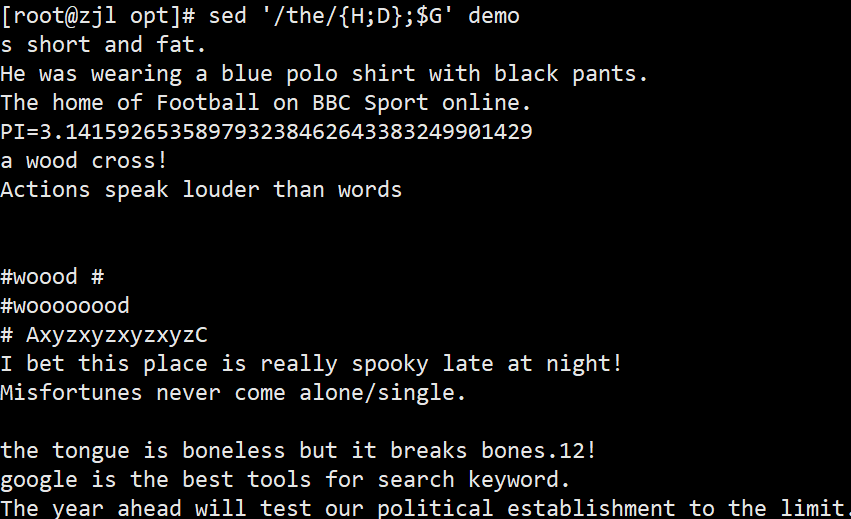
ifconfig ens33 | sed -rn '2s/.*inet ([0-9.]+).*/\1/p'
案例:





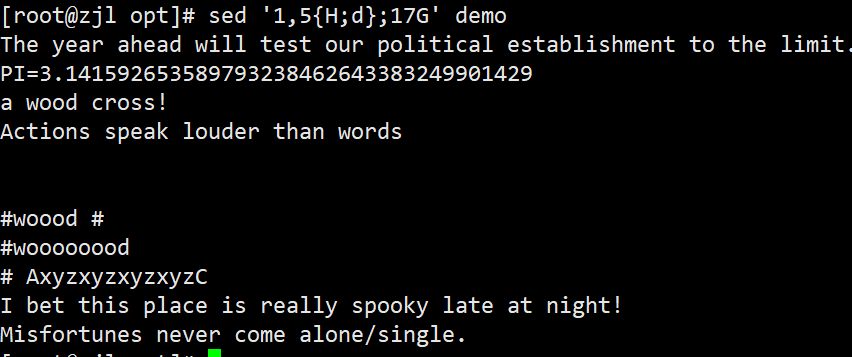
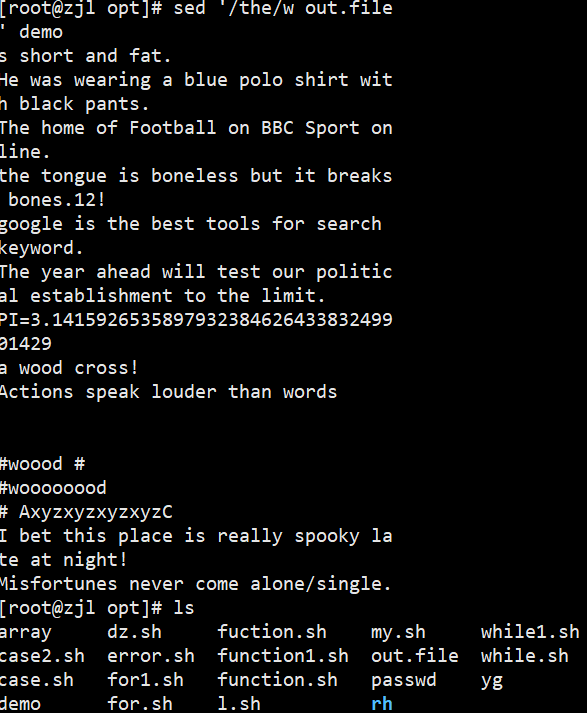
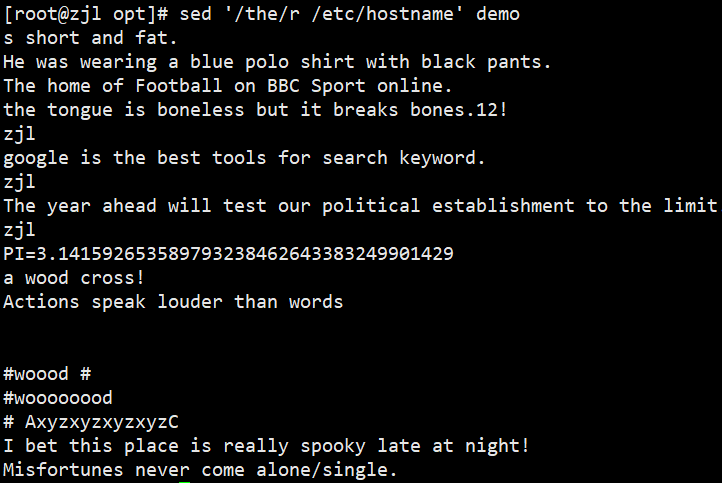
三、常用文本处理小工具
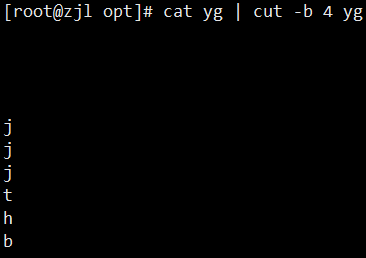
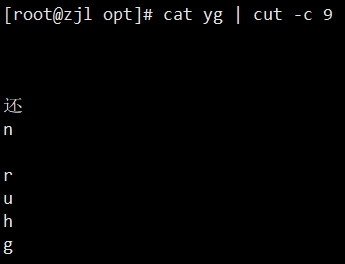
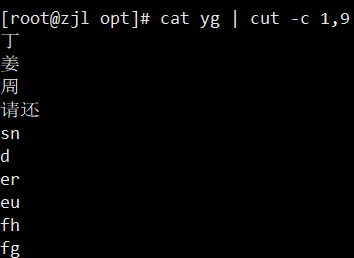
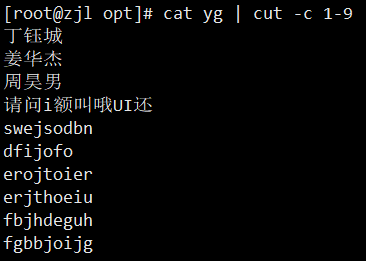
1. cut:按列截取
- `-b`:按字节截取
- `-c`:按字符截取(中文推荐用 `-c`)
- `-d`:指定分隔符(默认 TAB)
- `-f`:指定字段(需配合 `-d`)
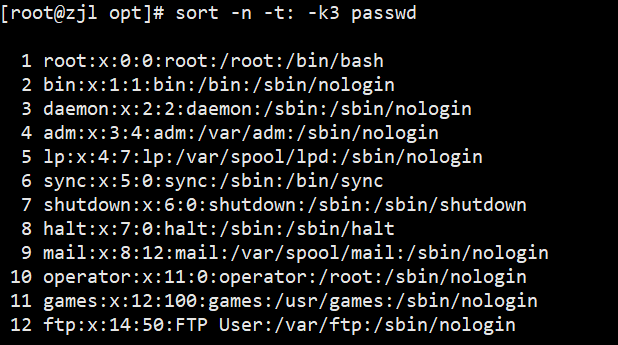
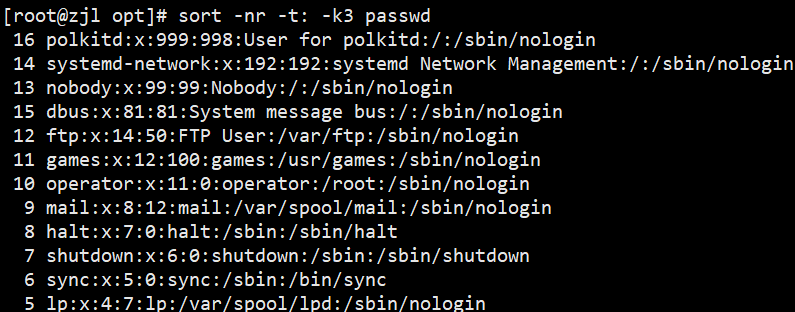
2. sort:排序
-t:指定分隔符-k:指定排序字段-n:按数值排序(默认是字典序)-r:降序-u:去重(等价于uniq)-o:输出到文件
sort passwd.txt # 按第一列升序
sort -n -t: -k3 passwd.txt # 以冒号分隔,按第3列数值升序
sort -nr -t: -k3 passwd.txt # 第3列数值降序
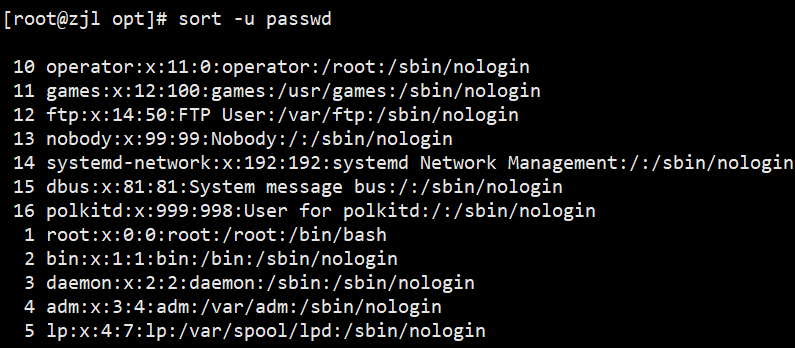
sort -u passwd.txt # 去重
sort -nr -t: -k3 passwd.txt -o out.txt # 排序结果保存
3. uniq:去重(需先排序)
-c:对重复的行进行计数-d:只显示重复行-u:只显示唯一行
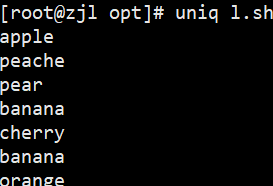
uniq fruit.txt # 去掉相邻重复行
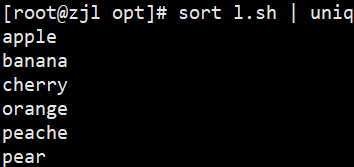
sort fruit.txt | uniq # 全局去重
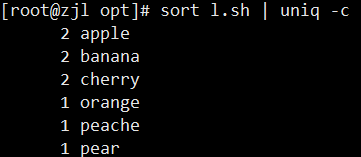
sort fruit.txt | uniq -c # 统计每行出现次数
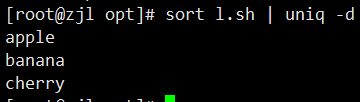
sort fruit.txt | uniq -d # 只显示重复行
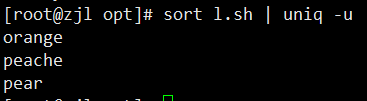
sort fruit.txt | uniq -u # 只显示不重复行
或者这样写 cat fruit.txt | sort | uniq -u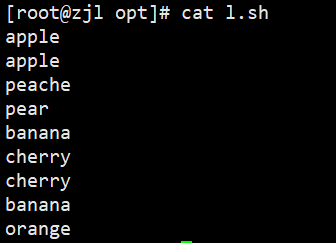
4. tr:字符替换/删除
-d:删除字符-s:压缩重复字符,只保留一个
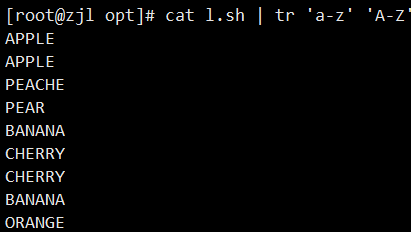
tr 'a-z' 'A-Z' < l.sh # 小写转大写
或cat l.sh | tr 'a-z' 'A-Z'
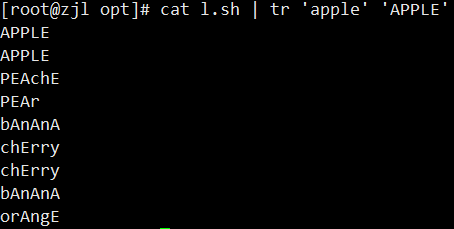
cat fruit | tr 'apple' 'APPLE' #替换是一一对应的字母的替换
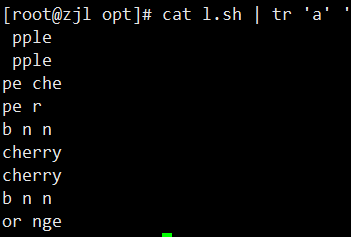
cat l.sh | tr 'a' ' ' #把替换的字符用单引号引起来,包括特殊字
cat l.sh | tr 'apple' 'star' #a替换成s,p替换成a,le替换成r
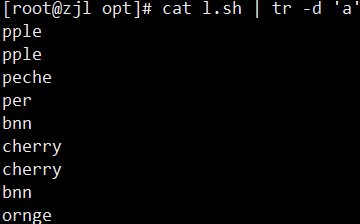
tr 'a' '/' < l.sh # 替换 a -> / 多个字符替换成一个tr -d 'a' < l.sh # 删除所有 a
tr -d '\n' < l.sh # 删除换行符
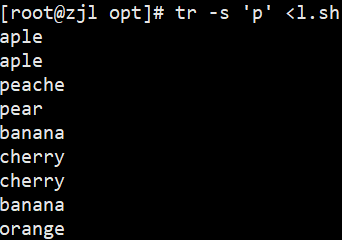
tr -s 'p' < l.sh # 连续 p 压缩成一个

四、生产环境综合应用
1. SS
ss -nt | tr -s " " | cut -d " " -f5 | cut -d: -f1 | sort | uniq -c #统计当前连接主机数
ss -nta | grep -v '^State' | cut -d" " -f1 | sort | uniq -c #统计当前主机连接状态
who | awk '{print $1}' | uniq #查看当前用户
last | awk '{print $1}' | sort | uniq | grep -v "^$" | grep -v wtmp #查看登录过的用户




五、总结对比
| 工具 | 适用场景 | 特点 |
|---|---|---|
awk | 复杂字段处理、统计、格式化输出 | 支持编程结构,功能强大 |
sed | 流式编辑、替换、删除、插入 | 轻量高效,适合批量处理 |
cut | 按列截取 | 简单快捷,适合固定格式 |
sort | 排序 | 支持数值和字典序 |
uniq | 去重(需先排序) | 只能处理相邻重复行 |
tr | 字符替换、删除、压缩 | 只能处理单个字符 |
如有疑问或进一步需求,欢迎在评论区留言!