黑马头条面试重点业务
bootstrap和nacos的配置中心和application.yaml的关系是什么?
bootstrap.yml的配置决定了应用如何连接到 Nacos 配置中心,是应用与 Nacos 配置中心建立联系的基础;Nacos 配置中心提供了集中化、动态化的配置管理方式,应用启动时会从 Nacos 获取配置,并结合application.yml中的本地配置,最终确定应用运行时使用的完整配置 。在实际应用中,通常会将一些通用的、需要动态调整的配置放在 Nacos 配置中心,而将一些相对固定的、本地化的配置放在application.yml中。
bootstrap:
bootstrap.yml(或bootstrap.properties)文件的加载优先级高于application.yml。这是因为bootstrap主要用于加载应用的一些基础配置,比如应用名、服务注册与发现的相关配置、连接配置中心的配置等,这些配置是应用启动时就需要确定的关键信息,要先于application.yml加载。
配置中心:
- 集中管理配置:Nacos 是一个动态服务发现、配置管理和服务管理平台,作为配置中心时,它可以集中管理所有应用的配置信息。开发人员可以在 Nacos 的控制台方便地对配置进行增删改查操作,不同环境(如开发、测试、生产)的配置可以分开管理。
- 配置动态更新:应用从 Nacos 配置中心获取配置后,当 Nacos 上的配置发生变化时,应用能够实时感知并动态更新配置,无需重启应用。这一特性对于需要频繁调整配置的场景非常实用,比如调整数据库连接参数、限流规则等。
- 配置加载流程:应用在启动时,根据
bootstrap.yml中配置的 Nacos 相关信息连接到 Nacos 配置中心,然后按照一定的规则(如根据应用名、环境等)获取对应的配置文件内容,并将其加载到应用中,覆盖或补充应用本地的配置。
application.yaml 配置文件:
- 应用本地配置:
application.yml用于配置应用的本地信息,它包含了应用在运行过程中需要的一些配置项,比如数据库连接信息、缓存配置、自定义参数等。如果没有从配置中心获取到对应的配置,就会使用application.yml中的配置;如果配置中心有相关配置,则会优先使用配置中心的配置 。
三者的优先级关系:
┌─────────────────────────────────────────────────────────────────────┐│ ││ 应用启动 ││ │├─────────────────────────────────────────────────────────────────────┤│ ││ 加载bootstrap.yml/bootstrap.properties文件 ││ │├─────────────────────────────────────────────────────────────────────┤│ ││ 根据bootstrap配置连接Nacos配置中心,获取配置 ││ │├─────────────────────────────────────────────────────────────────────┤│ ││ 加载application.yml/application.properties文件 ││ │├─────────────────────────────────────────────────────────────────────┤│ ││ 根据spring.profiles.active配置,加载对应的application-${profile}.yml ││ │├─────────────────────────────────────────────────────────────────────┤│ ││ Nacos配置中心配置覆盖相同配置项(如果有) ││ │├─────────────────────────────────────────────────────────────────────┤│ ││ application-${profile}.yml配置覆盖application.yml中相同配置项 ││ │├─────────────────────────────────────────────────────────────────────┤│ ││ 应用使用最终合并后的配置启动 ││ │└─────────────────────────────────────────────────────────────────────┘发布文章业务
别看就只是一个发布文章,但是真正的梳理起来还是挺绕的,需要确定好对象是如何转换的,以及确定好文章草稿和发布要完成的不同业务。
1.首先明确好发请求的数据json是怎么样的:
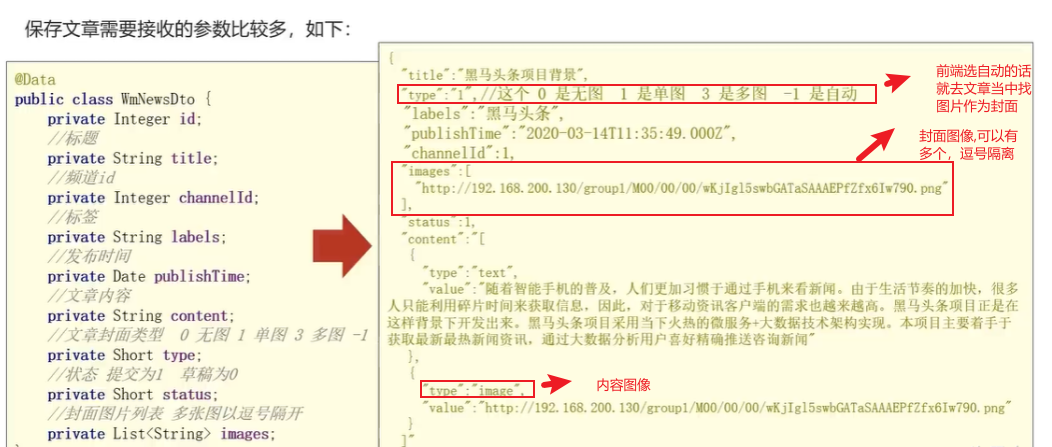
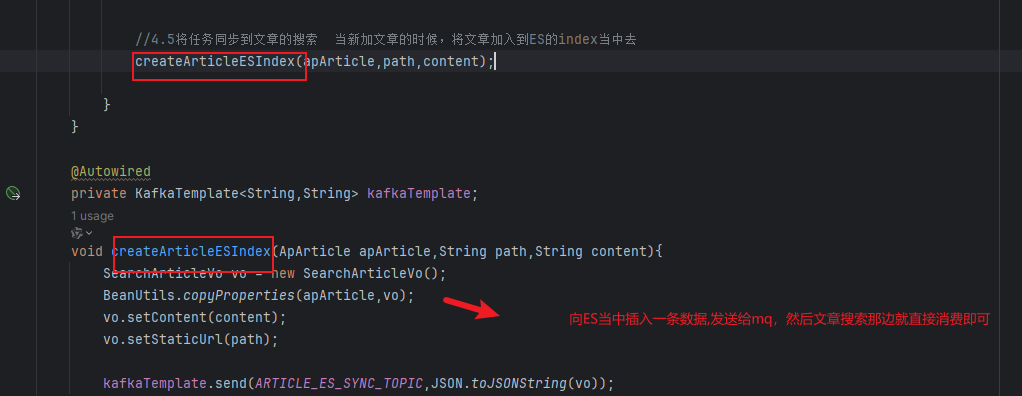
核心代码就是如下的,难以理解的就是为什么草稿的时候不需要进行图片和数据库当中素材进行对应,因为你要发布了才会进行校验有一下你的照片是不是在我的素材库当中,如果说你都不在那么就是不合法的,而且需要将文章和素材关联起来。点二点就是关于如果说设置的自动类型。就会根据你的内容里面的图片数量去处理封面的情况,当内容当中的image大于3就多图模式以此类推,而这些都是在发布的时候才需要做的事情,在草稿阶段只需要将数据读取出来就即可。
延迟队列解决精准时间发布文章
该业务是比较复杂的业务,也是在面试当中可以和面试官重点吹牛的业务,因为此业务涉及道了数据库,定时任务,redis的list和zset,根据业务的不同从而进行刷新。
核心的业务流程是如下的:
 首先是要确定有几个模块,第一个模块就是一个wemedia模块,该模块在文章发布业务建立了素材和图片的关系之后的最后就会去调用保存定时任务,第二个模块就是open-fegin模块,该模块定义好shedule要对外提供的接口,然后shedule去实现即可,其他模块都继承了open-fegin模块的依赖,这样就完美的实现了模块间的调用,而shedule模块里面的业务就主要是处理上述图片当中的关系的,包括存到数据库,然后定时刷新到zset或list当中。
首先是要确定有几个模块,第一个模块就是一个wemedia模块,该模块在文章发布业务建立了素材和图片的关系之后的最后就会去调用保存定时任务,第二个模块就是open-fegin模块,该模块定义好shedule要对外提供的接口,然后shedule去实现即可,其他模块都继承了open-fegin模块的依赖,这样就完美的实现了模块间的调用,而shedule模块里面的业务就主要是处理上述图片当中的关系的,包括存到数据库,然后定时刷新到zset或list当中。
该模块的核心业务在于shedule:
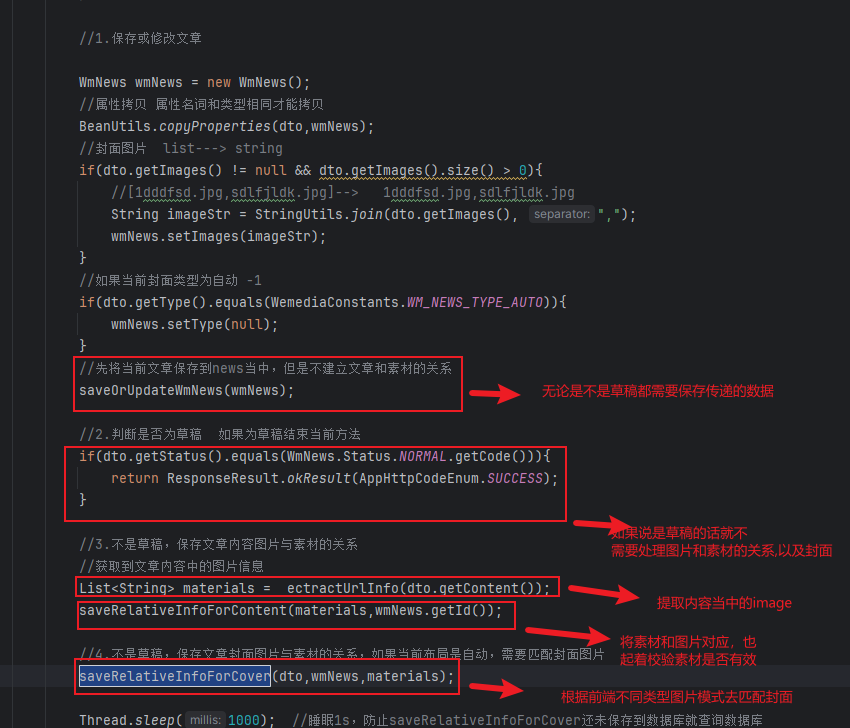
新增task方法,该方法在保存文章的时候,即验证完素材和图片的时候,最后会将该发布文章任务加入上述过程当中(因为后续需要审核+发布到手机app)。此步骤就是加入到任务数据库,如果说当前任务的执行时间在当前之间之前那么就是不是定时的任务,直接加入到list即可(addTaskToCache的逻辑。)
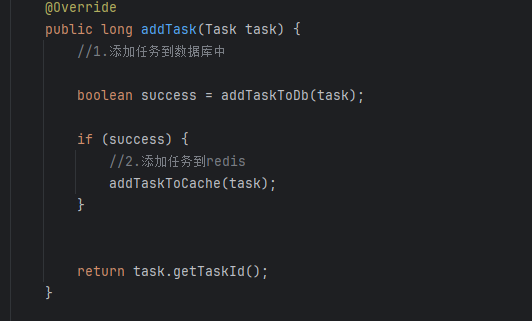
还有一个核心方法:
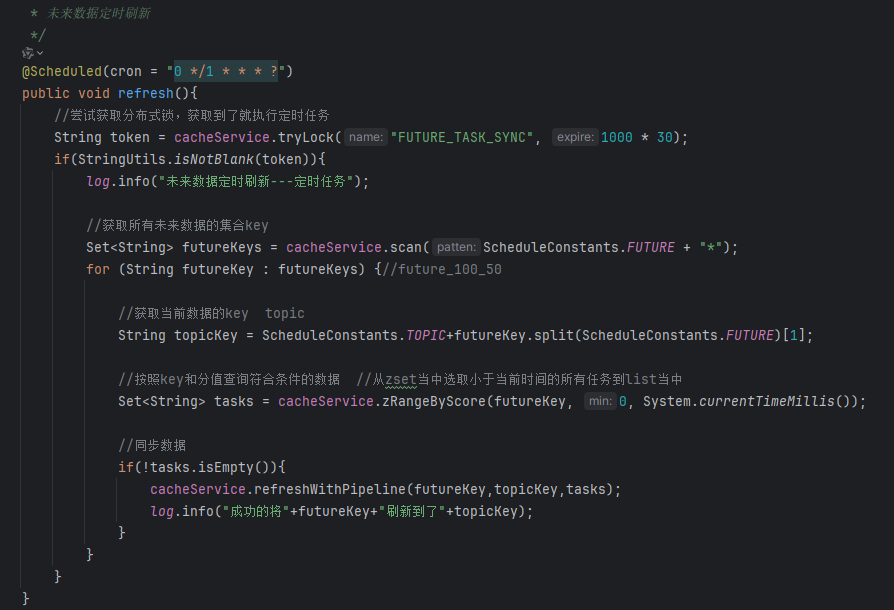
该方法就是将zset当中的task同步到list的核心逻辑,查询key为futrue开头的所有任务,然后找到任务执行时间在0-当前时间,查询到的这些任务久直接加入到List当中。
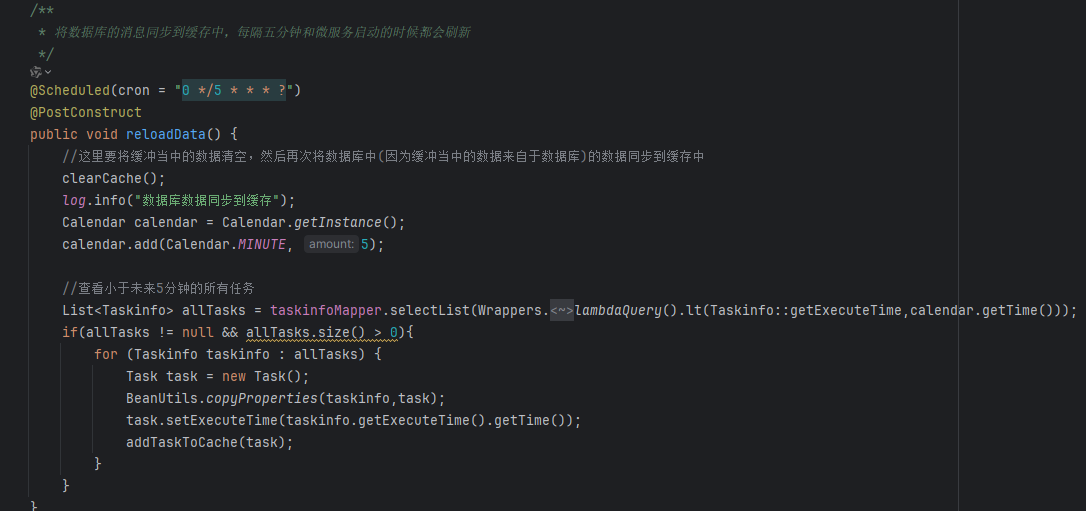
该方法是将数据库的数据,小于某一时间值的所有数据,同步到list当中。
为什么要设置zset和list两个数据类型以及task为什么要先保存到数据库?
ZSet + List:通过 “分层存储” 和 “定时转移”,实现延迟任务的高效调度,兼顾 “未来任务的有序管理” 和 “当前任务的快速消费”。
保存到数据库当中实现了对任务的持久化。
文章发布和文章实现异步解耦
这一点也是可以重点说明的,因为这一点的业务串联起来很复杂,框框的说,业务说的越熟练管面试官听不听得懂。
接着上面的精准发布文章的后文就是,在管理端发布文章的时候,最后会调用shedule模块的addTask方法,而该方法又抽取出来了,并且加上了异步操作,这就是关键,因为现实的业务就是,你发布一个文章他的审核,和发布是不需要马上就完成的,所以说基于这个特点,那么我就把他的任务加到task任务当中作为一个异步的操作,减少了发布文章的等待时间。
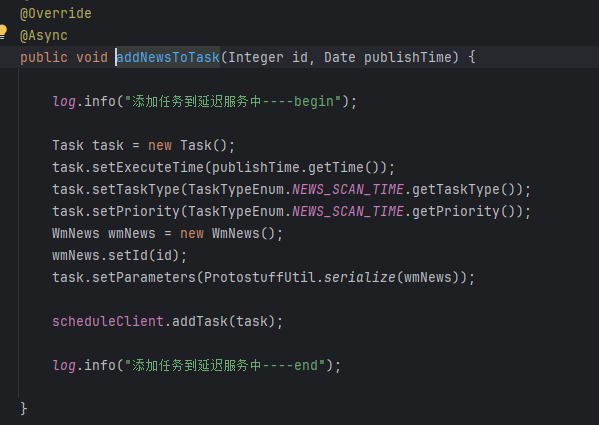
消费任务:
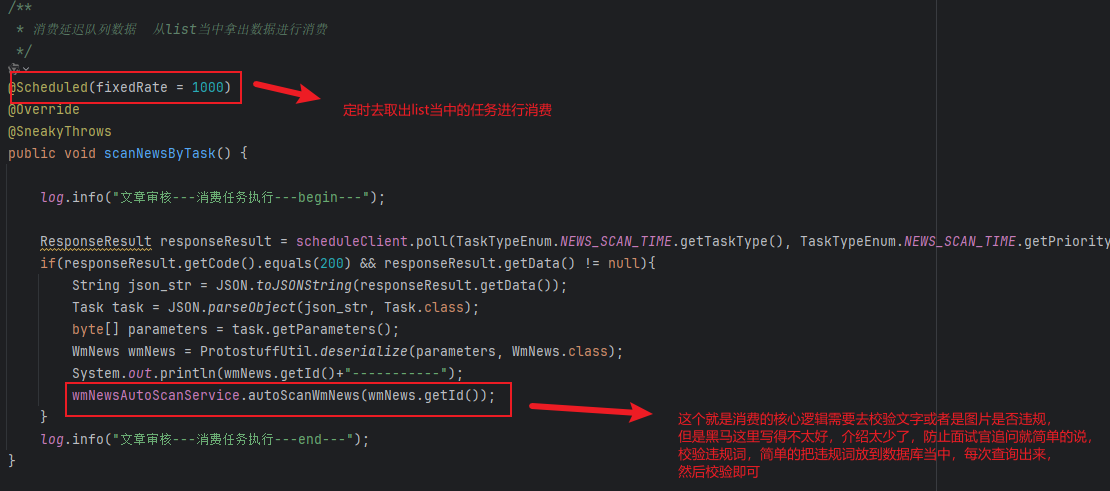
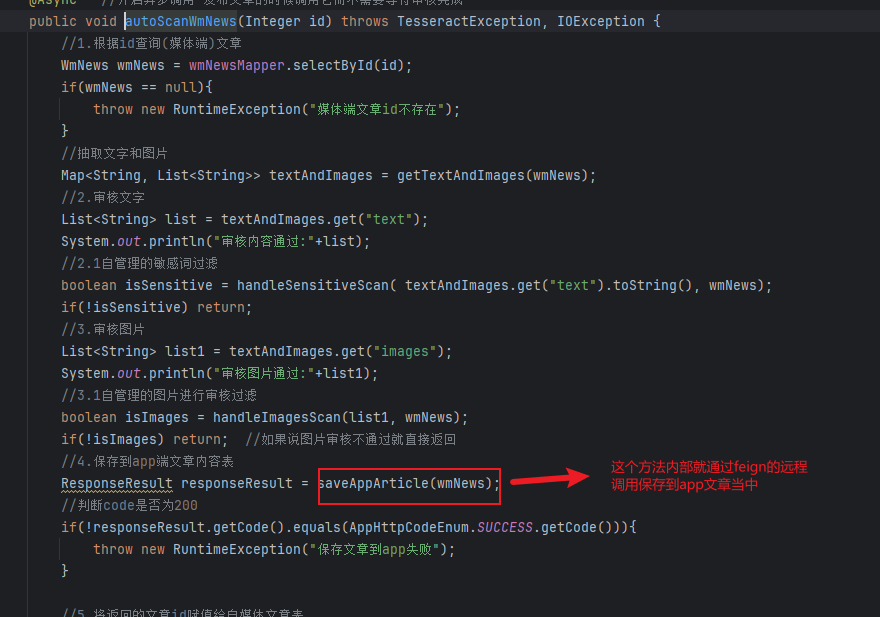
autoScanWmNews的核心也就是审核完之后就去调用保存文字的api
feign远程调用如何调用其他模块的api
首先我们要知道feign其实就是一个发请求的方法和HTTP类似,只不过他帮我们封装起来了然后去发罢了。
1.首先明确该模块肯定会被其他模块引入的(因为feign其实就是定义请求的形式的,比如说你在apifox当中构造一个请求一样)
举个例子实际上的feign的配置是如下的:
就完美的构造了一个请求出来了
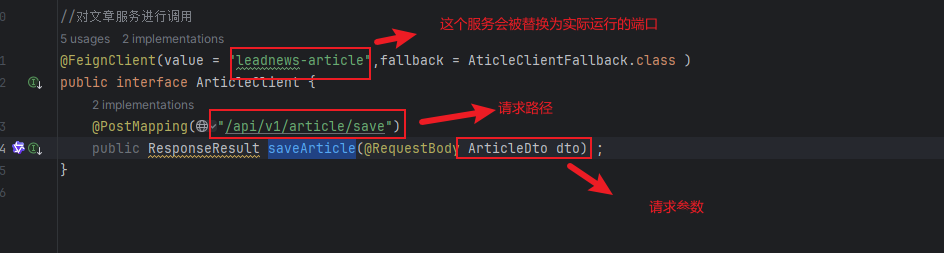
总结:feign只是构造请求的,实际要被调用的方法,哪个模块需要被调用,把对应的方法提供出来即可,然后因为和fegin配置得一样的,所以说可以实现其他模块调用。
使用RabbitMQ进行文章上下架功能
这里黑马头条使用的是kafka,但是他用得特别的浅,就是一个topic模式,一个生产者发送消息,消费者去监听,完全可以使用rabbitMQ,然后关于mq的八股再熟悉一下,那么在面试官面前你就可以吹牛我熟悉mq了。可以说是为了用技术而用技术的操作了。
生产者去发送消息指定key即可,然后还要指定为direct的路由器,因为topic就是特殊的direct类型的队列。
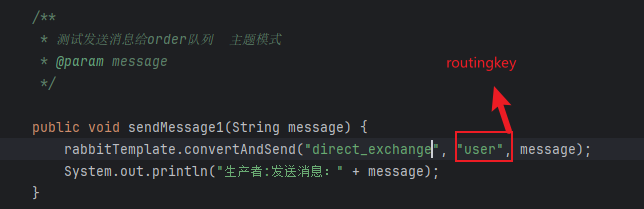
消费者要配置好,监听的交换机和队列,以及routingkey即可。

头条当中实现的原理:
当然使用的是kafka。
使用ES实现对文章的关键词查询
关于ES的基本使用可以去看我的主页的文章,使用Java如何去操作ES。
ES基本使用教程
ES的作用就是用来查询某个关键词是否在某个字段当中存在的,他的原理是将field(mysql的colum)组成一个倒排索引,即词条和文档id的对应关系,查询的时候会先去查询词条,然后取出对应的文档id,再去查询文档,这样就能根据关键词去查询出文档来了。而且效率还很高。
下面的代码就是本项目当中对ES的核心了,其实无非就是ES当中的query,from和size即分页,和hignlight高亮的配置罢了,要理清楚下面的代码,下面代码就是一个ES的纯查询操作。
/*** ES文章分页搜索** @param userSearchDto* @return*/@Overridepublic ResponseResult search(UserSearchDto userSearchDto) throws IOException {//1.检查查询条件if(userSearchDto==null|| StringUtils.isEmpty(userSearchDto.getSearchWords())){return ResponseResult.errorResult(AppHttpCodeEnum.PARAM_INVALID);}//1.1异步调用将查询关键词保存到mongoDb当中//异步调用 保存搜索记录 登录了并且查询首页ApUser user= AppThrealLocalUtil.getUser();if(user != null && userSearchDto.getFromIndex() == 0){apUserSearchService.insert(userSearchDto.getSearchWords(), user.getId());}//2.设置查询条件SearchRequest searchRequest = new SearchRequest("app_info_article");//这个builder是用于存放条件的SearchSourceBuilder searchSourceBuilder = searchRequest.source();BoolQueryBuilder boolQueryBuilder=new BoolQueryBuilder(); //当有连个查询条件的时候就需要用 BoolQueryBuilder//2.1根据title和content关键词分词后进行查询QueryStringQueryBuilder stringQueryBuilder = QueryBuilders.queryStringQuery(userSearchDto.getSearchWords()).field("title").field("content");boolQueryBuilder.must(stringQueryBuilder);//2.2查询小于minDate的数据 即实现滚动的分页查询RangeQueryBuilder publishTime = QueryBuilders.rangeQuery("publishTime").lt(userSearchDto.getMinBehotTime().getTime());boolQueryBuilder.filter(publishTime);//2.3分页查询 即取出条数searchSourceBuilder.from(0); //查询出来的第0条就是要开始返回的数据searchSourceBuilder.size(userSearchDto.getPageSize());//2.4按照发布时间顺序倒序searchSourceBuilder.sort("publishTime", SortOrder.DESC);//2.5设置高亮的titleHighlightBuilder highlightBuilder = new HighlightBuilder();highlightBuilder.field("title");highlightBuilder.preTags("<font style='color: red; font-size: inherit;'>");highlightBuilder.postTags("</font>");searchSourceBuilder.highlighter(highlightBuilder);searchSourceBuilder.query(boolQueryBuilder);searchRequest.source(searchSourceBuilder);SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);//3.封装结果返回//这里的数据就是所有查询出来的要返回的数据 但是高亮字段还需要自己进行填充SearchHit[] hits = searchResponse.getHits().getHits();List<Map> list=new ArrayList<>();for (SearchHit hit : hits) {String json=hit.getSourceAsString(); //获取命中的文章内容Map map= JSON.parseObject(json,Map.class);if(hit.getHighlightFields()!=null&&hit.getHighlightFields().size()>0){//存在高亮字段 getFragments表示的是获取所有匹配上的字段Text[] titles = hit.getHighlightFields().get("title").getFragments();String title = StringUtils.join(titles, ",");//将高亮的title加入mapmap.put("h_title",title);}else {//没有高亮字段 原始标题map.put("h_title",map.get("title"));}list.add(map);}return ResponseResult.okResult(list);}这张图就很明显的将上述语法总结出来了(文的文章里面有),最外层其实就是一个source,即source包括了query,from,size,sort等等,都是在构建一个如此的查询语句罢了。

使用ES来查询的时候,最重要的就是构造出searchRequest,然后获取到searchRequest的source,这个source最核心的地方就在于去构造query,分页,高亮,等等。而创建这些的都是通过某某builder实现的。
这里还有一个业务就是在保存到app文章的时候,使用kafka去将这个新文章插入到ES当中。
如下就是在最终保存文章的时候还需要插入到ES当中的操作。