MiniCPM-V 4.5 模型解析
模型介绍
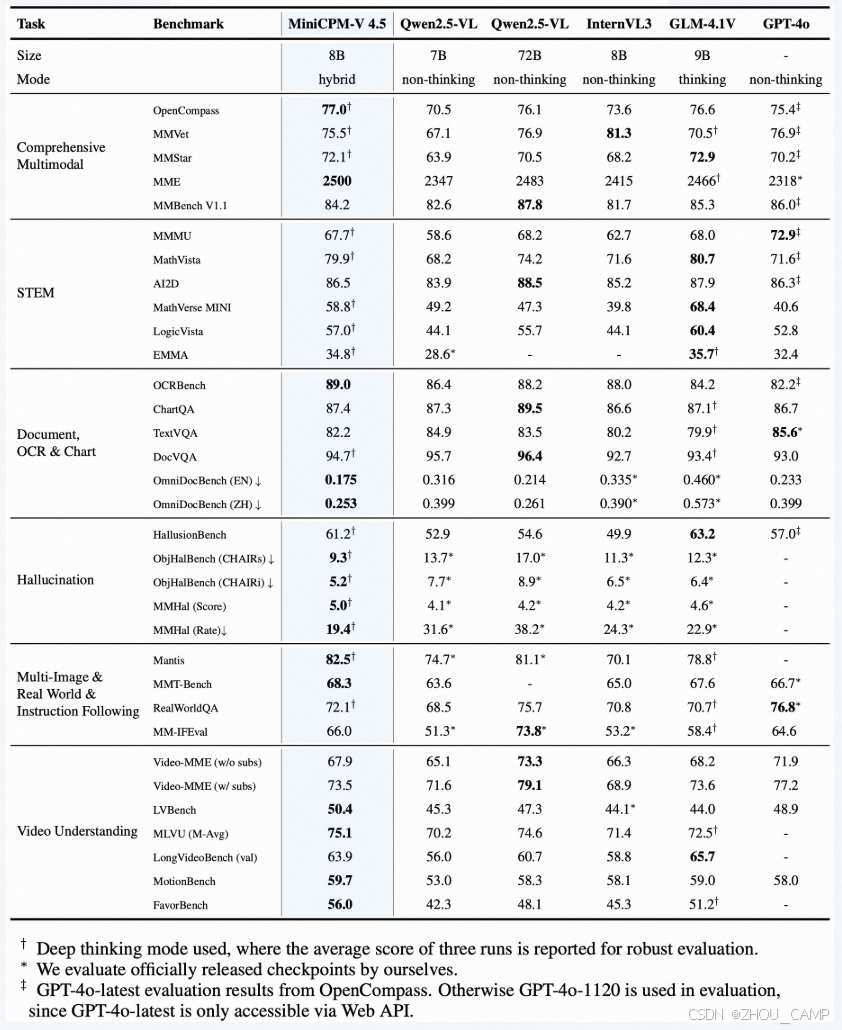
MiniCPM-V 4.5 是 MiniCPM-V 系列最新推出的多模态大模型,具备领先的视觉-语言理解与生成能力。该模型基于 Qwen3-8B 和 SigLIP2-400M 构建,总参数量为 8B,在多项权威评测中表现卓越。在 OpenCompass 综合评估中平均得分达 77.0,超越了包括 GPT-4o-latest、Gemini 2.0 Pro 等主流闭源模型,以及参数量更大的开源模型(如 Qwen2.5-VL 72B),成为 30B 参数以下性能最强的多模态语言模型之一。
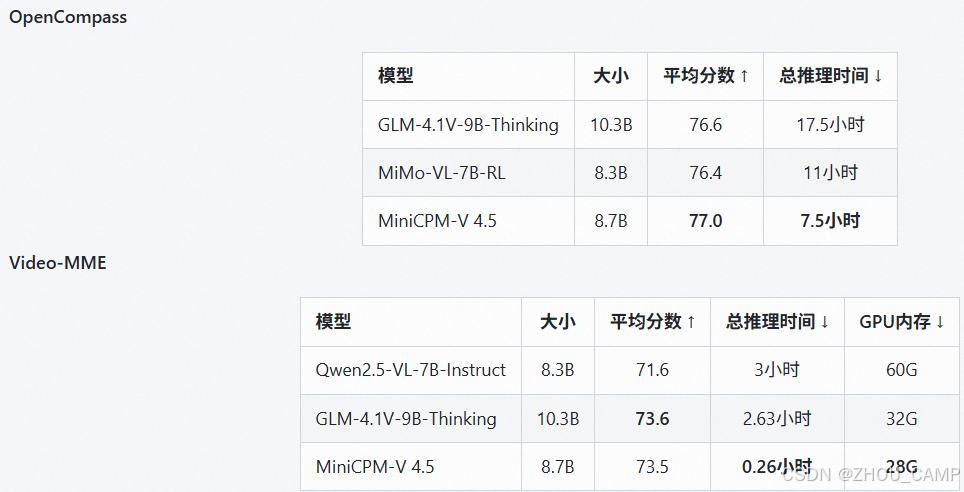
MiniCPM-V 4.5 在视频理解方面实现重大突破,借助创新的统一3D重采样器,可高效处理高帧率与长视频内容,实现高达96倍的视频 token 压缩率。该能力使其在 Video-MME、LVBench 等视频理解任务中达到最先进水平,同时保持较低的推理成本。
模型支持“快速/深度”双模式推理,用户可根据任务复杂度灵活切换,兼顾效率与性能。此外,MiniCPM-V 4.5 继承了 LLaVA-UHD 架构优势,可处理分辨率高达 1344×1344 像素的图像,在 OCR、文档解析等任务中表现突出,在 OCR Bench 和 OmniDocBench 上的性能甚至超过 GPT-4o-latest 和 Gemini 2.5。模型还具备多语言支持(超过30种语言)、可信行为增强等特性。
MiniCPM-V 4.5 提供丰富的部署方式,支持本地 CPU 推理(llama.cpp、ollama)、多种量化格式(int4/GGUF/AWQ),并可借助 SGLang、vLLM 实现高吞吐推理,也支持通过 Transformers 和 LLaMA-Factory 进行微调。用户还可体验本地 WebUI 演示、iOS 端优化应用及在线服务器演示,开箱即用,灵活高效。
模型性能
推理效率
模型加载
import torch
from PIL import Image
from modelscope import AutoModel, AutoTokenizertorch.manual_seed(100)model = AutoModel.from_pretrained('OpenBMB/MiniCPM-V-4_5', trust_remote_code=True,attn_implementation='sdpa', torch_dtype=torch.bfloat16)
model = model.eval().cuda()
tokenizer = AutoTokenizer.from_pretrained('OpenBMB/MiniCPM-V-4_5', trust_remote_code=True)2025-09-03 16:54:48,126 - modelscope - INFO - Got 1 files, start to download ...
Downloading [README.md]: 100%|██████████| 24.2k/24.2k [00:00<00:00, 36.2kB/s]
Processing 1 items: 100%|██████████| 1.00/1.00 [00:00<00:00, 1.43it/s]
2025-09-03 16:54:48,835 - modelscope - INFO - Download model 'OpenBMB/MiniCPM-V-4_5' successfully.
Loading checkpoint shards: 100%|██████████| 4/4 [00:00<00:00, 18.10it/s]
模型结构
model
MiniCPMV((llm): Qwen3ForCausalLM((model): Qwen3Model((embed_tokens): Embedding(151748, 4096)(layers): ModuleList((0-35): 36 x Qwen3DecoderLayer((self_attn): Qwen3Attention((q_proj): Linear(in_features=4096, out_features=4096, bias=False)(k_proj): Linear(in_features=4096, out_features=1024, bias=False)(v_proj): Linear(in_features=4096, out_features=1024, bias=False)(o_proj): Linear(in_features=4096, out_features=4096, bias=False)(q_norm): Qwen3RMSNorm((128,), eps=1e-06)(k_norm): Qwen3RMSNorm((128,), eps=1e-06))(mlp): Qwen3MLP((gate_proj): Linear(in_features=4096, out_features=12288, bias=False)(up_proj): Linear(in_features=4096, out_features=12288, bias=False)(down_proj): Linear(in_features=12288, out_features=4096, bias=False)(act_fn): SiLU())(input_layernorm): Qwen3RMSNorm((4096,), eps=1e-06)(post_attention_layernorm): Qwen3RMSNorm((4096,), eps=1e-06)))(norm): Qwen3RMSNorm((4096,), eps=1e-06)(rotary_emb): Qwen3RotaryEmbedding())(lm_head): Linear(in_features=4096, out_features=151748, bias=False))(vpm): SiglipVisionTransformer((embeddings): SiglipVisionEmbeddings((patch_embedding): Conv2d(3, 1152, kernel_size=(14, 14), stride=(14, 14), padding=valid)(position_embedding): Embedding(4900, 1152))(encoder): SiglipEncoder((layers): ModuleList((0-26): 27 x SiglipEncoderLayer((self_attn): SiglipAttention((k_proj): Linear(in_features=1152, out_features=1152, bias=True)(v_proj): Linear(in_features=1152, out_features=1152, bias=True)(q_proj): Linear(in_features=1152, out_features=1152, bias=True)(out_proj): Linear(in_features=1152, out_features=1152, bias=True))(layer_norm1): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)(mlp): SiglipMLP((activation_fn): PytorchGELUTanh()(fc1): Linear(in_features=1152, out_features=4304, bias=True)(fc2): Linear(in_features=4304, out_features=1152, bias=True))(layer_norm2): LayerNorm((1152,), eps=1e-06, elementwise_affine=True))))(post_layernorm): LayerNorm((1152,), eps=1e-06, elementwise_affine=True))(resampler): Resampler((kv_proj): Linear(in_features=1152, out_features=4096, bias=False)(attn): MultiheadAttention((out_proj): NonDynamicallyQuantizableLinear(in_features=4096, out_features=4096, bias=True))(ln_q): LayerNorm((4096,), eps=1e-06, elementwise_affine=True)(ln_kv): LayerNorm((4096,), eps=1e-06, elementwise_affine=True)(ln_post): LayerNorm((4096,), eps=1e-06, elementwise_affine=True))
)
模型配置
model.config
MiniCPMVConfig {"architectures": ["MiniCPMV"],"attention_bias": false,"attention_dropout": 0.0,"auto_map": {"AutoConfig": "configuration_minicpm.MiniCPMVConfig","AutoModel": "modeling_minicpmv.MiniCPMV","AutoModelForCausalLM": "modeling_minicpmv.MiniCPMV"},"batch_3d_resampler": true,"batch_vision_input": true,"bos_token_id": 151643,"drop_vision_last_layer": false,"eos_token_id": 151645,"head_dim": 128,"hidden_act": "silu","hidden_size": 4096,"image_size": 448,"initializer_range": 0.02,"intermediate_size": 12288,"layer_types": ["full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention","full_attention"],"max_position_embeddings": 40960,"max_window_layers": 36,"model_type": "minicpmv","num_attention_heads": 32,"num_hidden_layers": 36,"num_key_value_heads": 8,"patch_size": 14,"query_num": 64,"rms_norm_eps": 1e-06,"rope_scaling": null,"rope_theta": 1000000,"slice_config": {"max_slice_nums": 9,"model_type": "minicpmv","patch_size": 14,"scale_resolution": 448},"slice_mode": true,"sliding_window": null,"tie_word_embeddings": false,"torch_dtype": "bfloat16","transformers_version": "4.55.2","use_cache": true,"use_image_id": true,"use_sliding_window": false,"version": 4.5,"vision_batch_size": 16,"vision_config": {"attention_dropout": 0.0,"hidden_act": "gelu_pytorch_tanh","hidden_size": 1152,"image_size": 980,"intermediate_size": 4304,"layer_norm_eps": 1e-06,"model_type": "siglip_vision_model","num_attention_heads": 16,"num_channels": 3,"num_hidden_layers": 27,"patch_size": 14},"vocab_size": 151748
}
模型调用

image = Image.open('image.png').convert('RGB')enable_thinking=False # If `enable_thinking=True`, the thinking mode is enabled.
stream=True # If `stream=True`, the answer is string# First round chat
question = "text in the image?"
msgs = [{'role': 'user', 'content': [image, question]}]answer = model.chat(msgs=msgs,tokenizer=tokenizer,enable_thinking=enable_thinking,stream=True
)generated_text = ""
for new_text in answer:generated_text += new_textprint(new_text, flush=True, end='')
Here is the text from the image:When it comes to retailing industry, we often remind the both part of realistic store and internet shopping. Both of them are all have its pros and cons, but according the picture, we can find out both of the internet sales counting and its profit are all grown up every years between twenty eighteen to twenty twenty one. The years internet rate began with twenty eighteen only 10.3%, next year 14.8% and the next 20.3%, finally finished in twenty twenty one up to 24.5%. The sales profit also began with twenty eighteen only 25.17 million, next year 28.93, and the next 34.56, finally finished in twenty twenty one up to 43.03. Therefore, we can find out the internet shopping is grown up between the four years. Beside 2019, I according my observed, more of my friends change to internet shopping because of COVID-19. All above results provided the picture is to realistic. In my opinion, shopping on the internet can save many times to me, so I also do it when I
# Second round chat, pass history context of multi-turn conversation
msgs.append({"role": "assistant", "content": [generated_text]})
msgs.append({"role": "user", "content": ["keep going."]})answer = model.chat(msgs=msgs,tokenizer=tokenizer,stream=True
)generated_text = ""
for new_text in answer:generated_text += new_textprint(new_text, flush=True, end='')
Sure! Here is the rest of the text from the image:need. In my opinion, shopping on the internet can save many times to me, so I also do it when I want to buy something.Let me know if you need any more help with this or anything else!