博客系统的测试
1.项目的测试背景
在互联网高速发展的当下,博客作为个人表达、知识分享与交流的重要平台,深受广大用户青睐。随着用户对博客系统的使用需求日益增长,以及系统功能的不断丰富和完善,确保博客系统稳定、高效、准确地运行变得至关重要。
传统的人工测试方式,在面对博客系统众多的功能模块(如登录、博客首页展示、博客详情查看、博客编辑发布等)以及复杂的使用场景(不同登录状态下的操作、各种异常输入情况等)时,存在效率低下、测试覆盖不全面、易受人为因素影响等问题。为了提升博客系统的测试质量与效率,保障用户拥有良好的使用体验,对博客系统进行自动化测试就成为了必然选择。通过设计涵盖登录界面、博客首页、博客详情页、博客编辑页等关键模块及各类使用场景的自动化测试用例,能够更快速、精准地发现系统潜在的问题。
2.测试目标及测试任务概括
2.1测试用例的设计
我们知道测试用例的设计一般要从6个方面去设计,分别为:功能测试,界面测试,性能测试,易用性测试,安全测试,兼容性测试,我们这里进行一些重要的测试。
2.2测试用例的思维导图
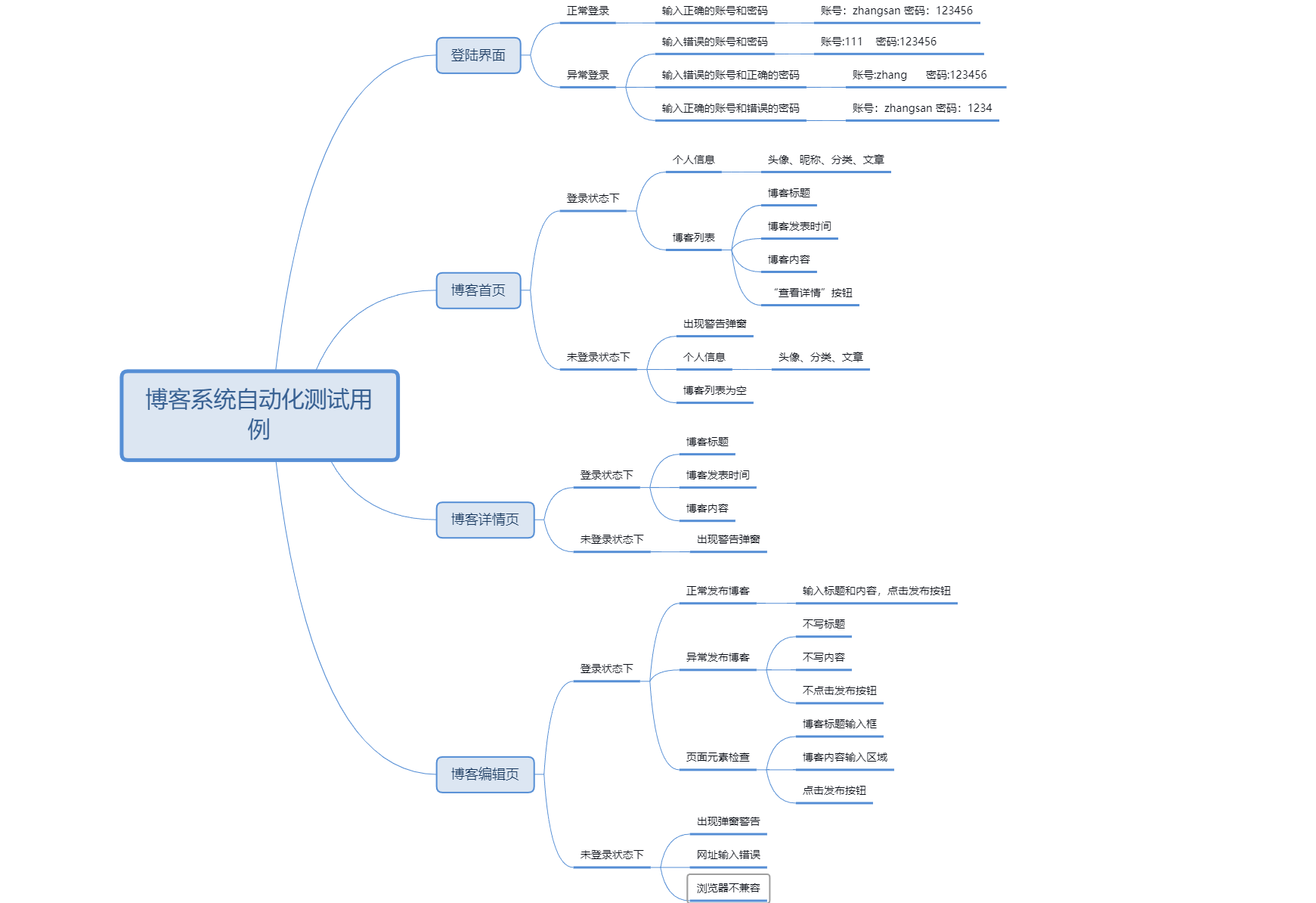
2.3登录页面测试
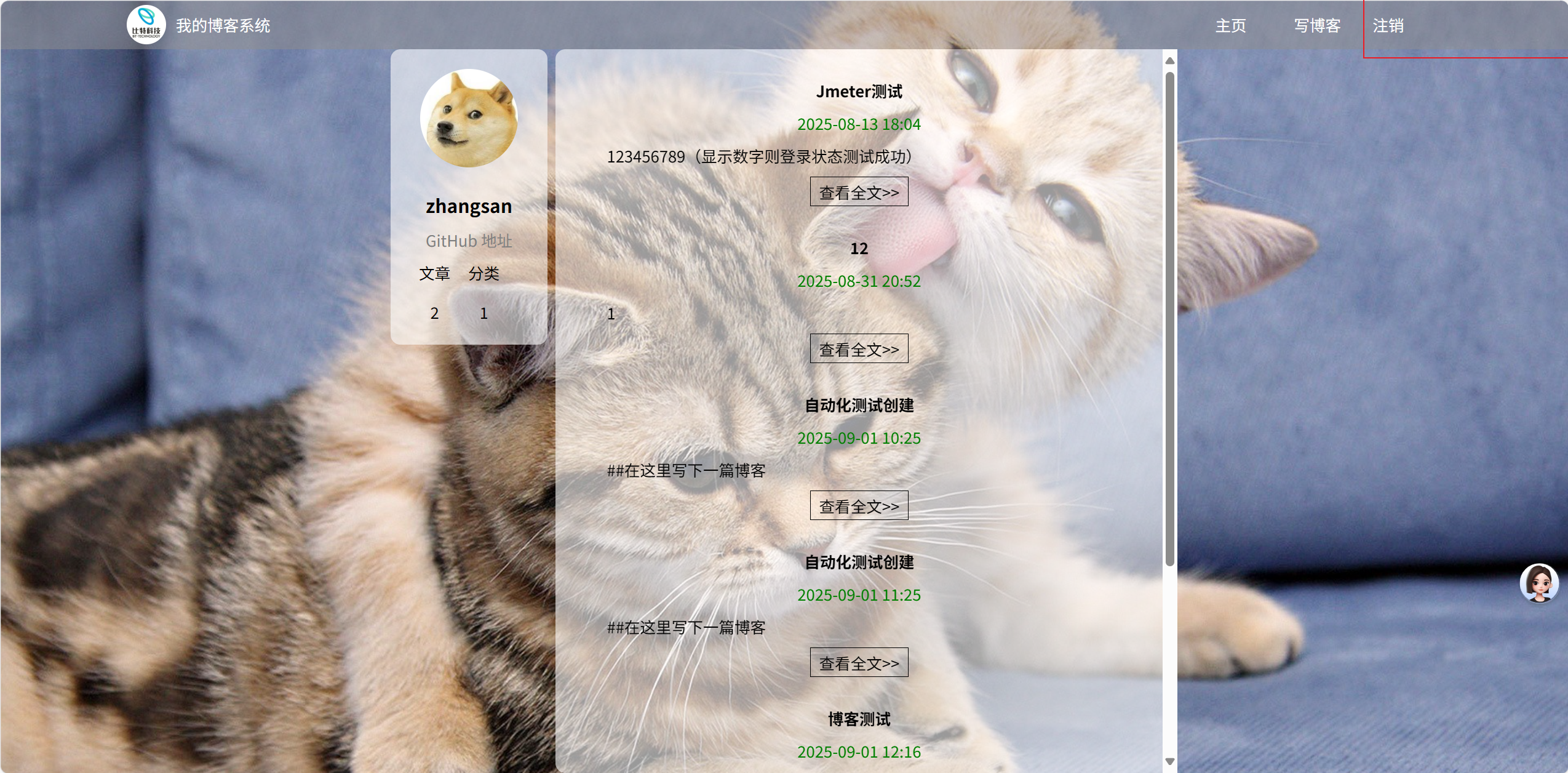
(1)登陆界面展示

(2)登录页面输入正确的账号密码
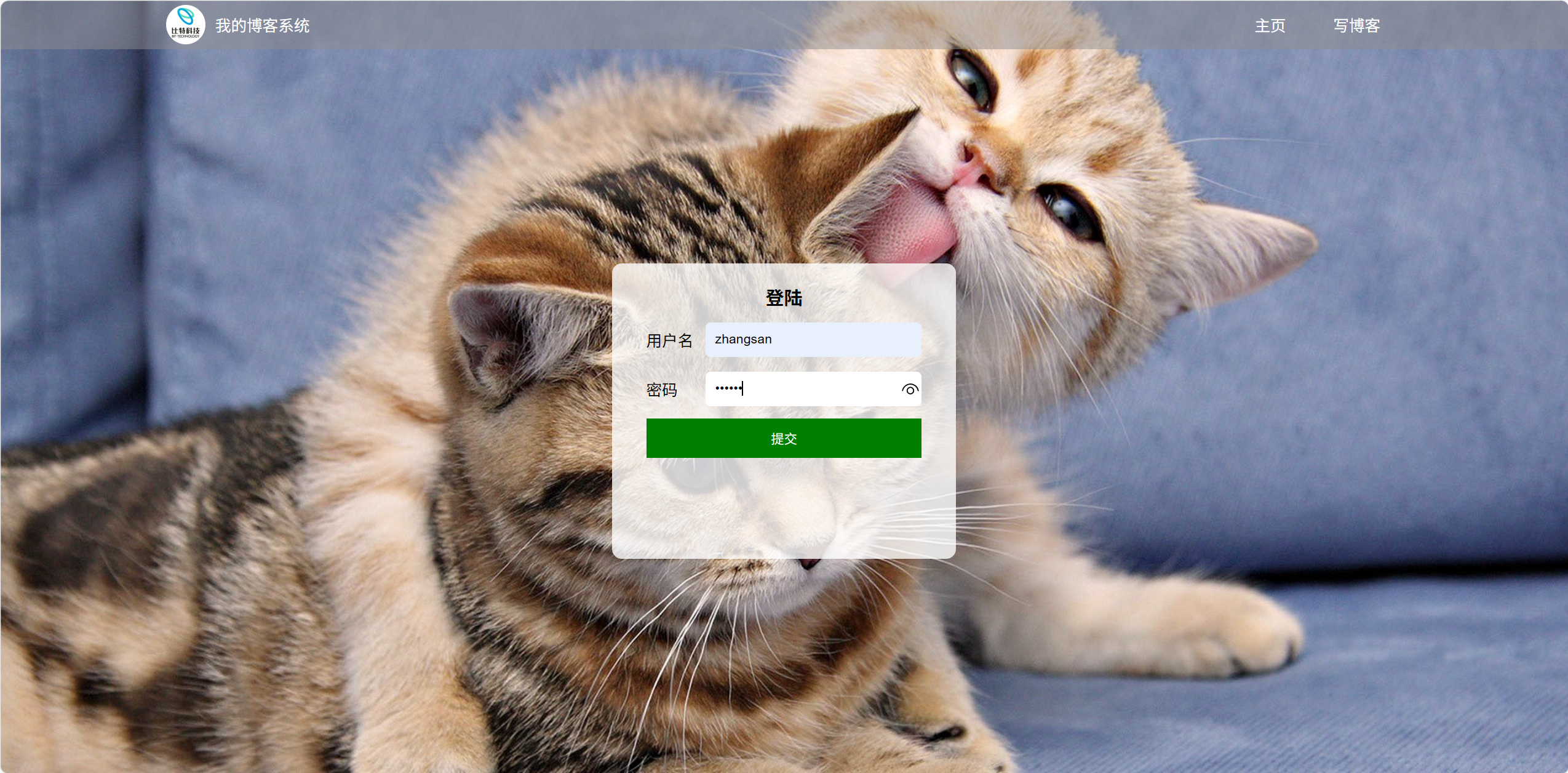
预期效果为跳入博客列表页
效果展示

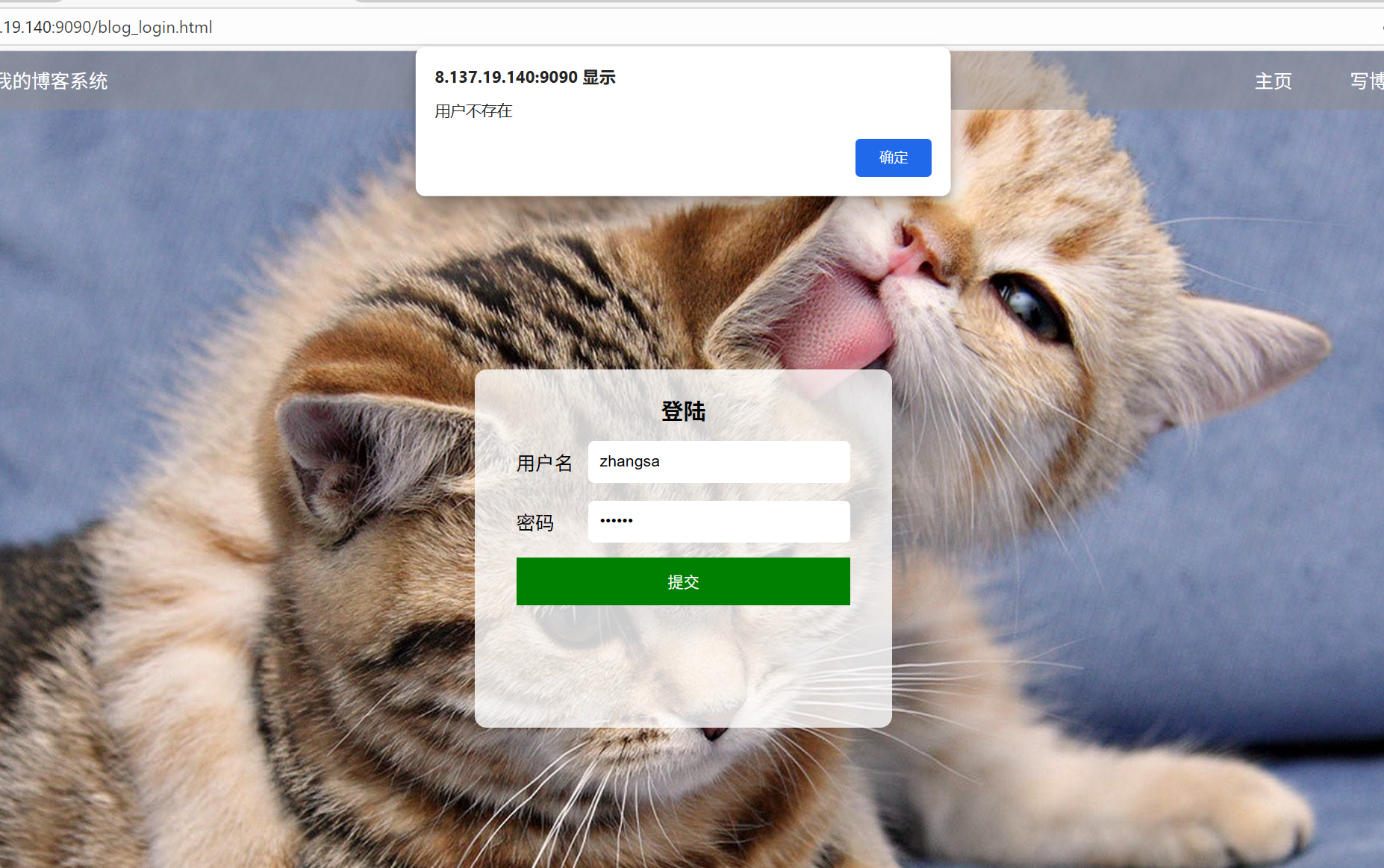
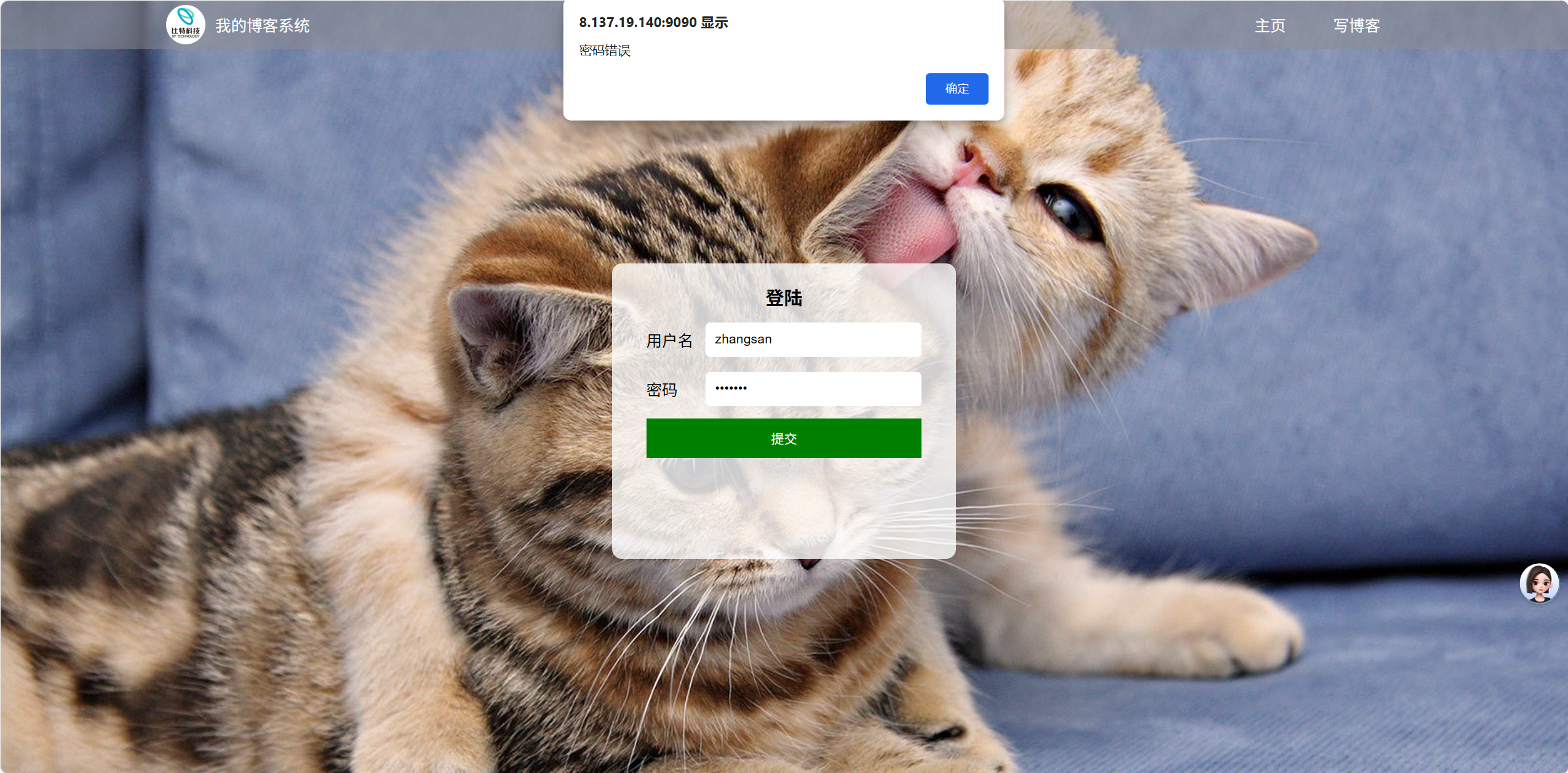
(3)登录页面输入正确的账号错误的密码或正确的密码错误的账号
效果展示
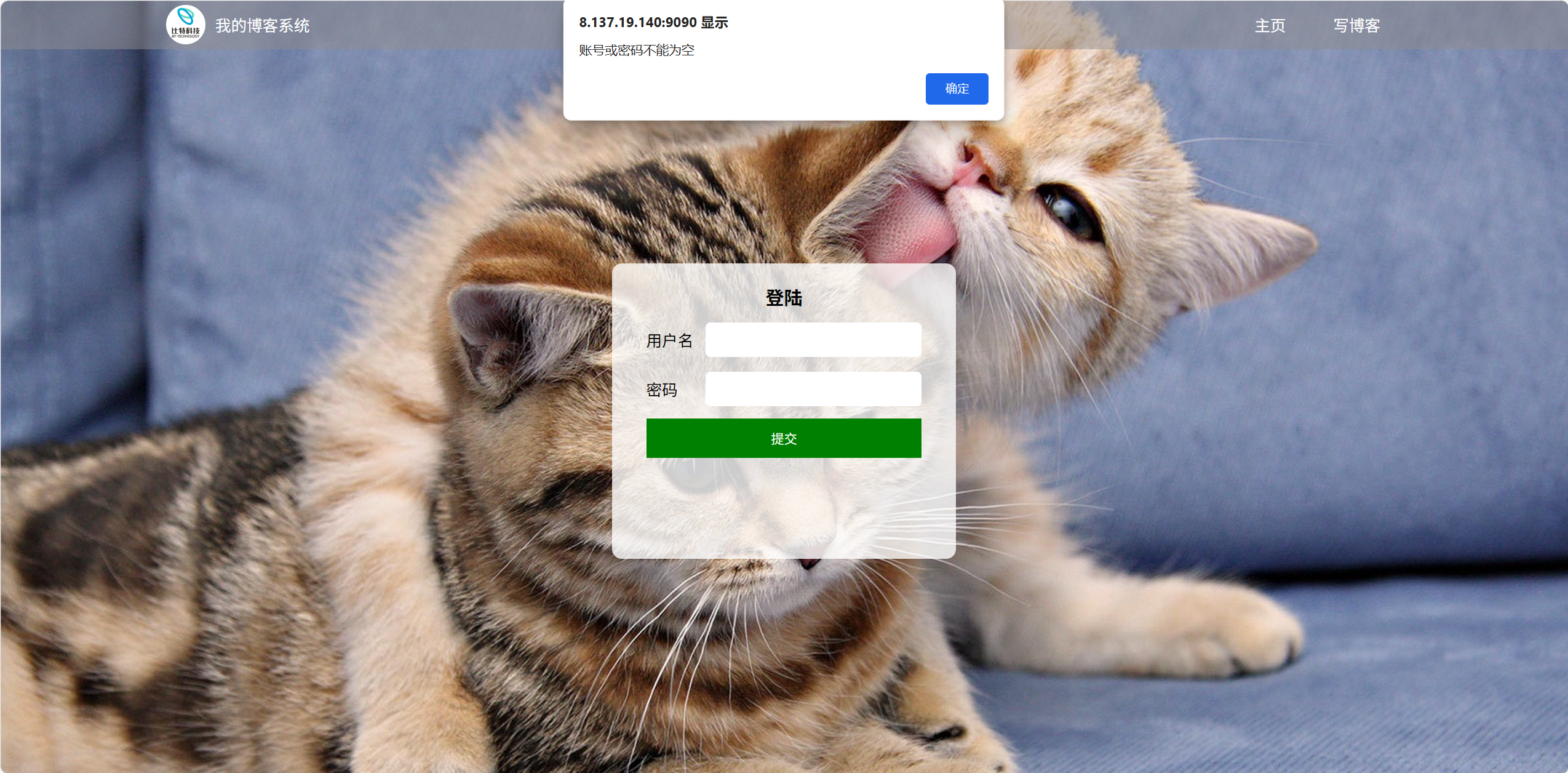
(4)输入空的账号和密码
效果展示
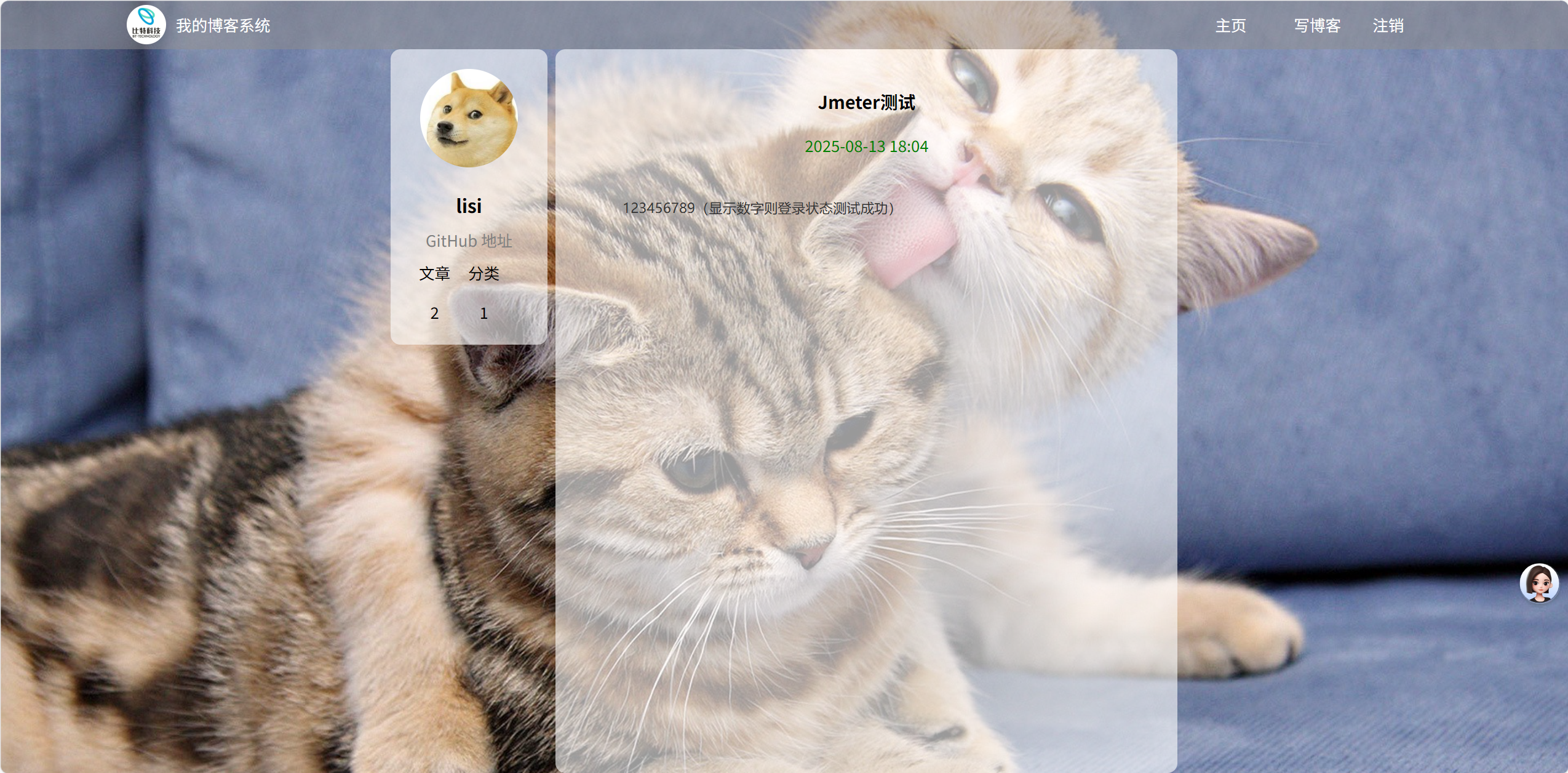
2.4登录列表页的测试
前提:当输入正确的密码账号时才会跳进列表页
(a)列表页的点击展示(发布博客时)
2.5博客详情页的测试
展示
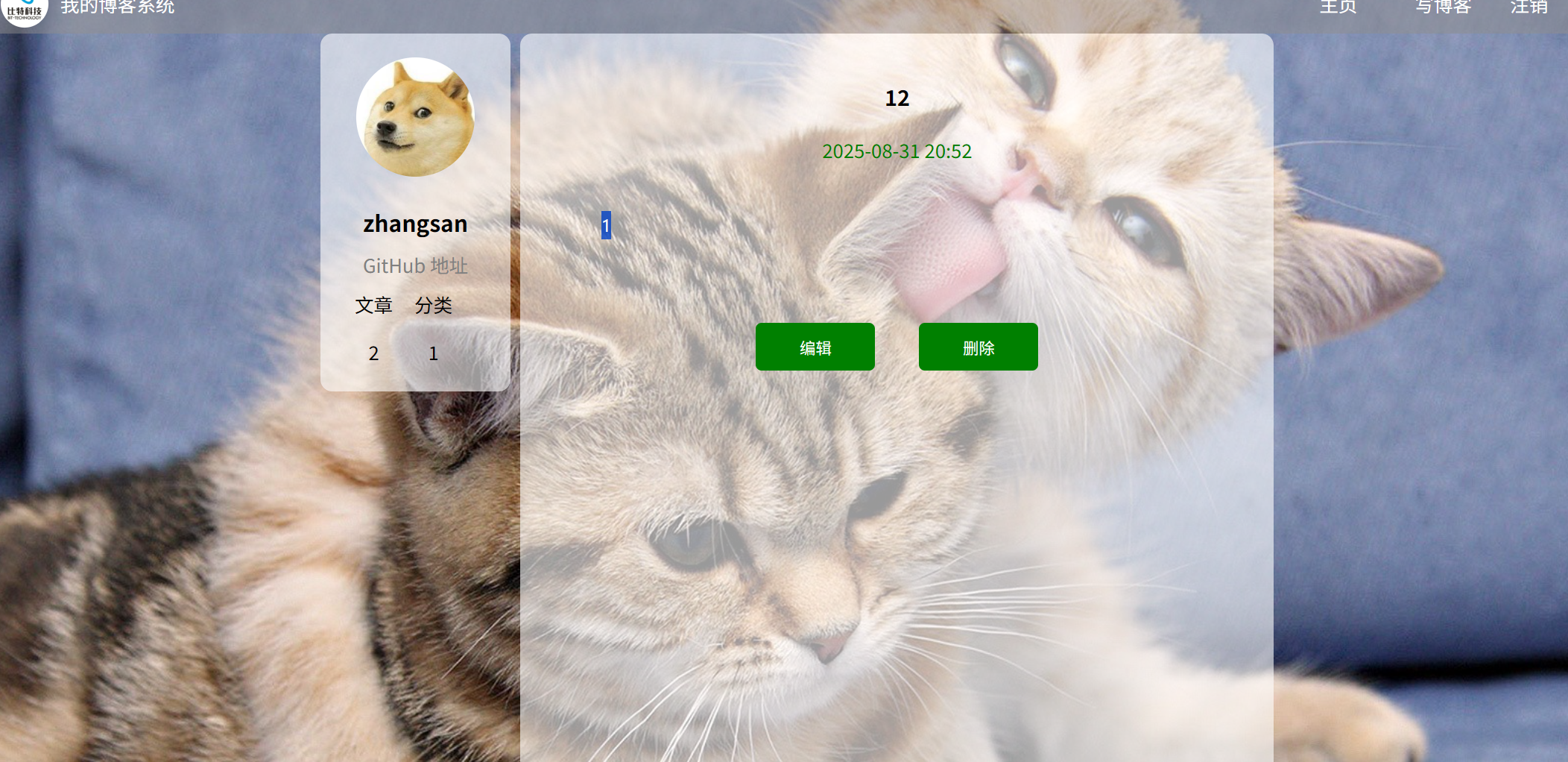
如果查看的文章是当前用户自己发布的,那么当前用户对这篇文章的权限是:读,写,修改,删除等,如果查看的文章是其他用户发布的,那么当前用户对文章的权限只能是只读,且文章中含有编辑,删除,写文章等一系列的操作。
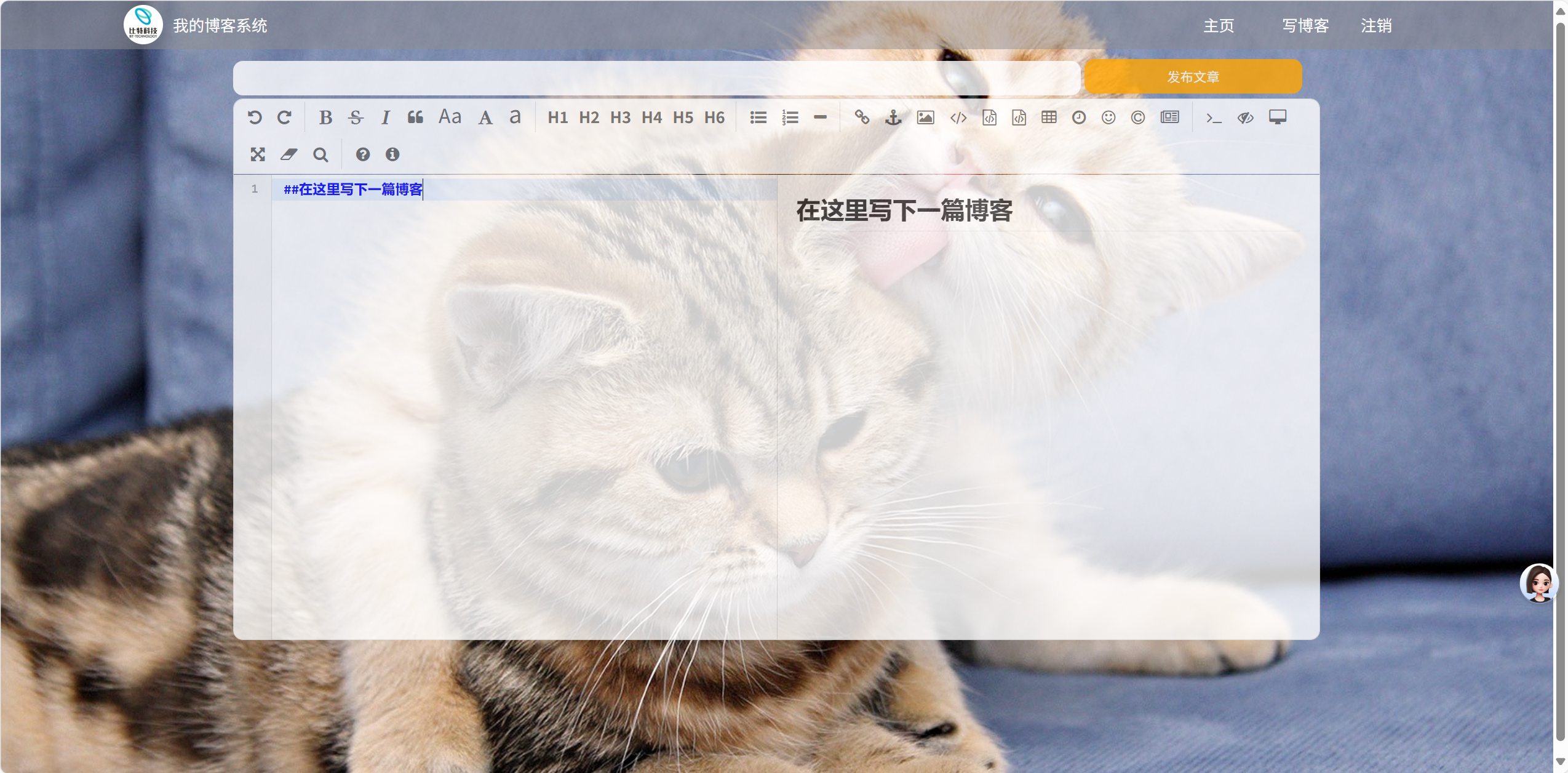
2.6博客编辑页面的测试
在博客编辑页面中,点击写博客博客编辑页面,此时可以进行新博客的写入操作。且含有多种操作.发布博客,删除等等……
详情展示
2.7博客退出功能的测试
在博客右上角点击注销按钮即可成功退出,下次登录需要重新输入账号密码。
页面展示
3.用pycharm实现Selenium实现Web自动化测试
在进行自动化测试之前,我们需要安装两个插件
web驱动
程序想要打开web浏览器就需要安装web驱动(即WebDriver),WebDriver 以本地化方式驱动浏览
器。WebDriver Manager是⼀个开源的命令行工具,它可以⾃动下载和安装适用于不同浏览器的
WebDriver。通过使用WebDriver Manager,我们可以确保浏览器驱动版本始终与浏览器版本保持⼀
致,从而避免因版本不匹配而导致的各种问题。
selenium库
selenium是⼀个web自动化测试工具,selenium中提供了丰富的方法供给使用者进行web自动化测
试
3.1新建项目
我们先打开pycharm,选择新建项目
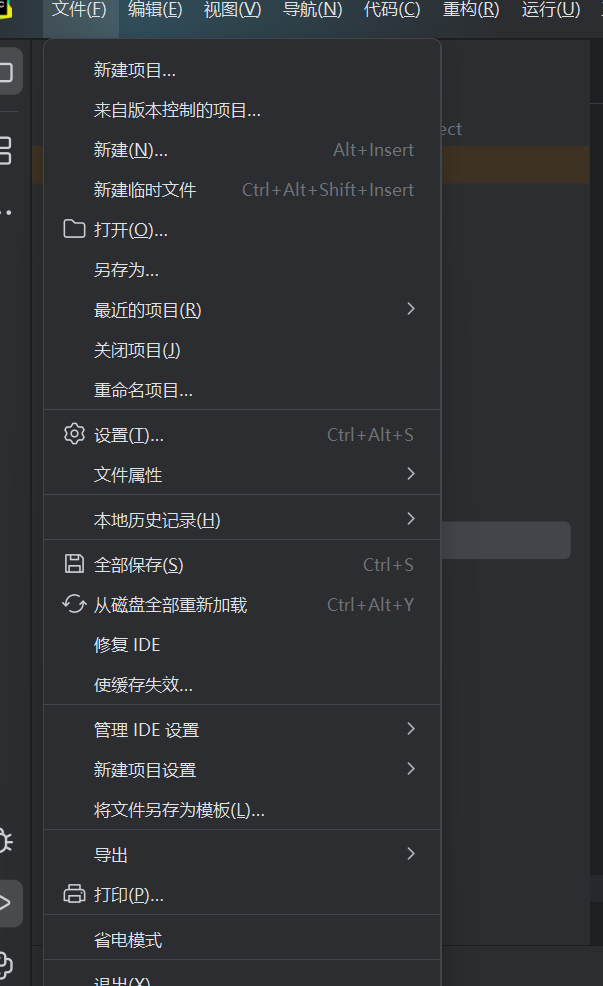
给我们要测试的项目取个名字,放到可以找到的文件夹,接着点击创建。
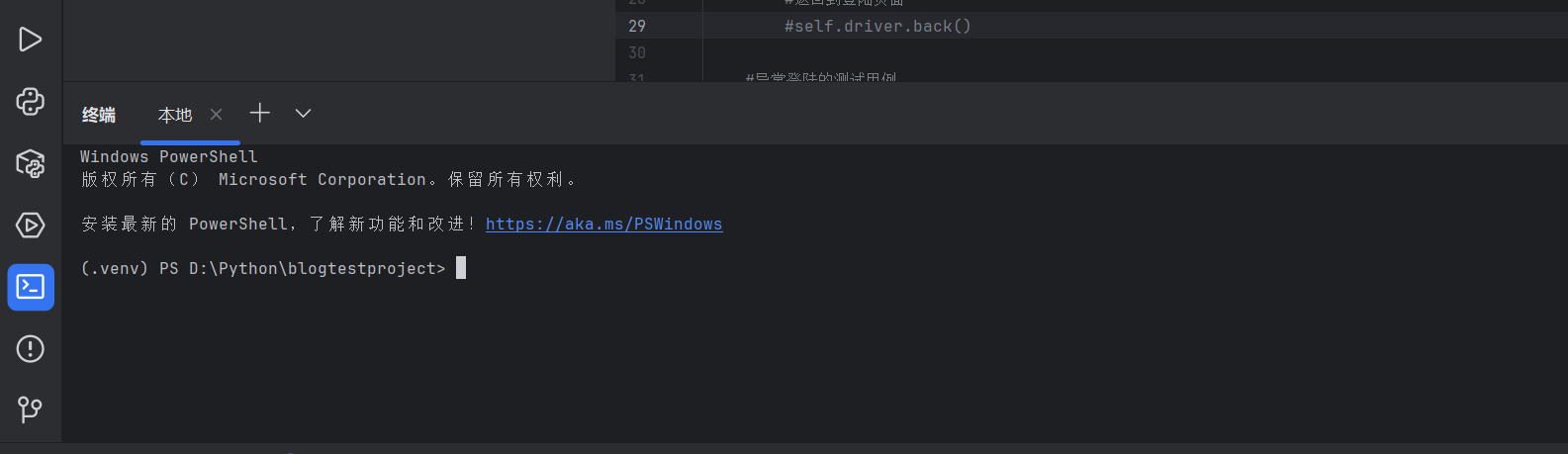
进入我们创建的项目以后点击终端,在终端里面分别输入pip install webdriver-manager和pip install selenium==4.0.0耐心等待安装过程,等到全部安装好以后,我们打开设置,点击python解释器,查看我们安装的插件是否成功安装。
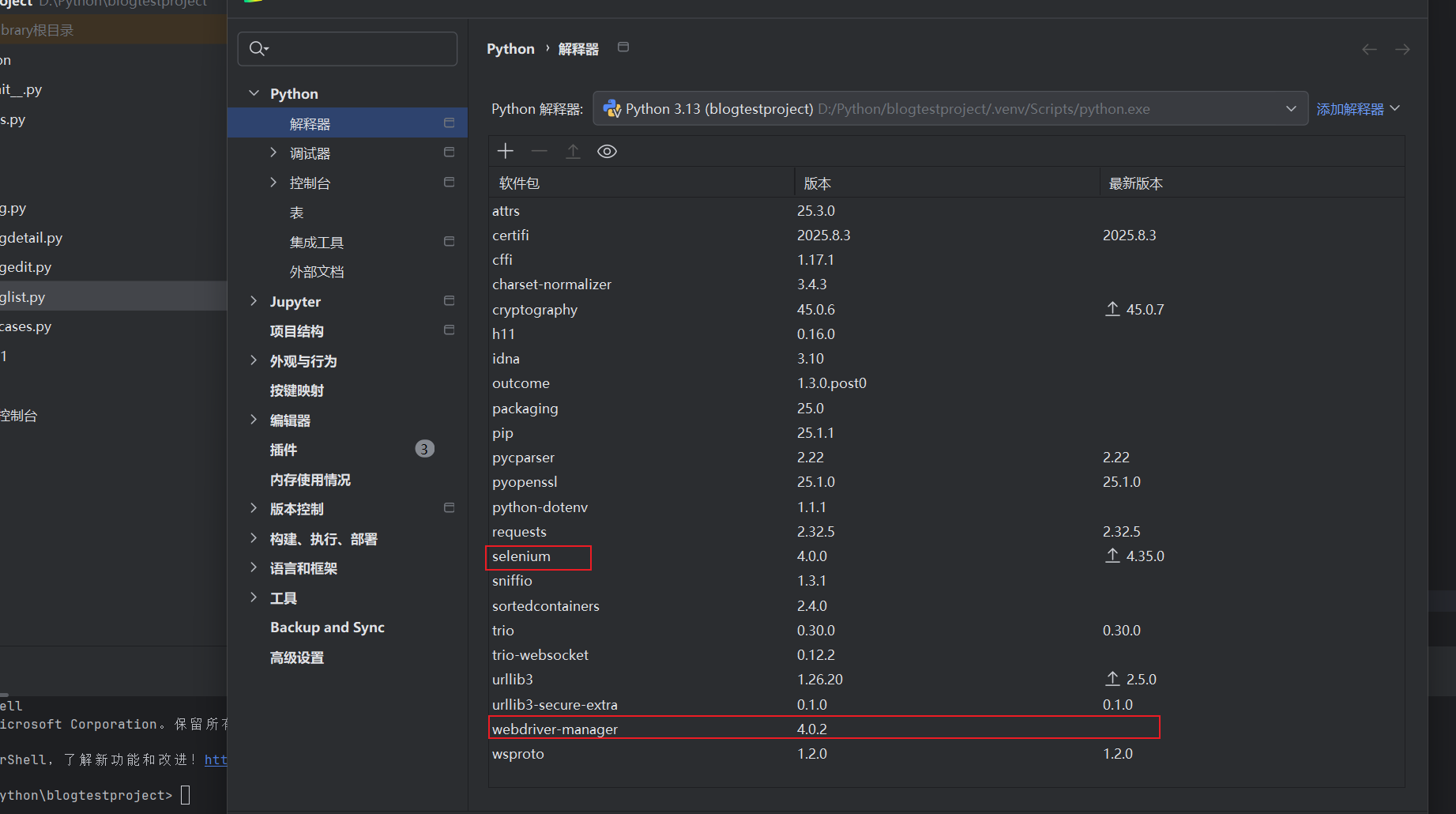
到这里我们就可以写自动化测试代码了。
3.2参照测试用例,编写自动化代码
博客页面有5个接口分别是:博客首页,博客登录页,博客列表页,博客详情页,博客编辑页,我们对这5个页面都要去创建驱动对象,通过驱动对象去get页面的url去访问,会出现大量重复代码,我们可以把相同代码放到一个文件下,把所有接口放到一个文件下。
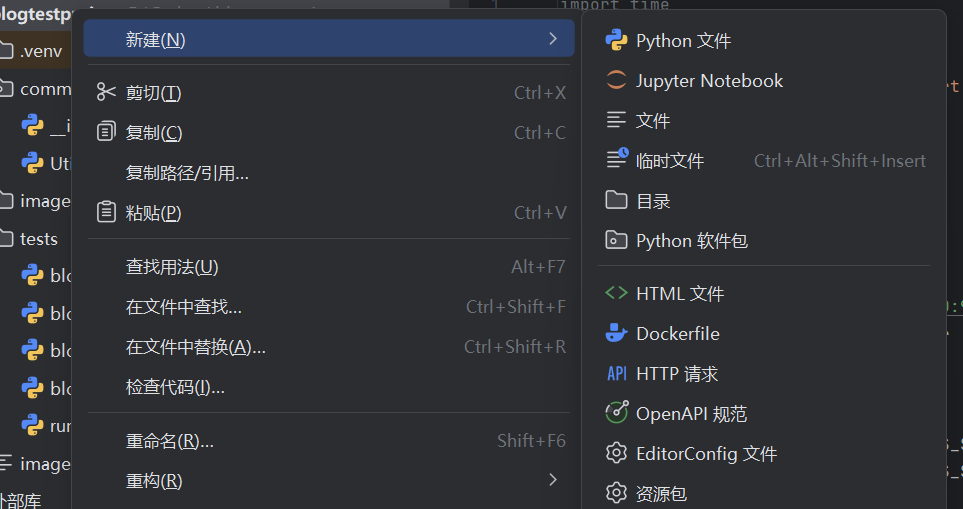
新建两个python软件包,将接口文件放在一起,打开浏览器文件与截图功能放在一起。

下图是创建好的示例
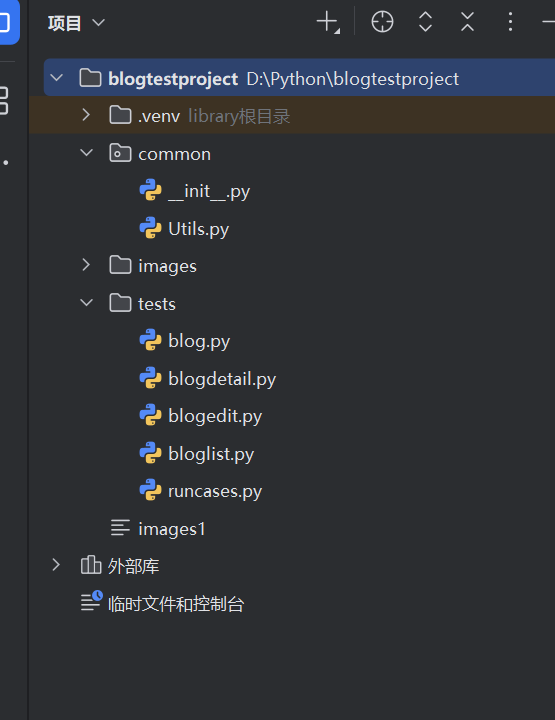
我们先配置浏览器驱动文件,即utils文件
import datetime
import os.path
import sys#1打开浏览器-驱动管理
from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.service import Service
from selenium.webdriver.edge.options import Options
from selenium.webdriver.support.wait import WebDriverWait
from webdriver_manager.microsoft import EdgeChromiumDriverManagerclass Driver:driver = ""def __init__(self):# EdgeDriver 路径edge_driver_path = r"D:\Edge\msedgedriver.exe"# 创建 Service 对象service = Service(edge_driver_path)# 创建 EdgeOptionsoptions = Options()options.add_argument("--remote-allow-origins=*")# 创建 WebDriver 对象self.driver = webdriver.Edge(service=service, options=options)def getScreeShot(self):#创建屏幕截图dirname = datetime.datetime.now().strftime("%Y-%m-%d")#判断dirname文件夹是否已经存在,若不存在则创建文件夹# ../images/2024-05-08if not os.path.exists("../images/"+dirname):#当前路径是否存在os.mkdir("../images/"+dirname)filename = sys._getframe().f_back.f_code.co_name+"-"+datetime.datetime.now().strftime("%Y-%m-%d-%H%M%S")+".png"self.driver.save_screenshot("../images/"+dirname+"/"+filename)#拼接名字BlogDriver = Driver()
在类成员中,我们创立了两个变量和两个函数,两个变量分别是url和driver,两个函数分别是电脑上edge浏览器自动化所需的驱动的配置,与截图功能的配置。驱动可以在https://developer.microsoft.com/en-us/microsoft-edge/tools/webdriver?form=MA13LH#downloads
这个网址中下载,需要注意的是版本号一定要仔细看准。
博客登录页
import time
from time import sleepfrom selenium.webdriver.common.by import Byfrom common.Utils import BlogDriverclass BlogLogin:url = ""driver = ""def __init__(self):self.url = "http://8.137.19.140:9090/blog_login.html"self.driver = BlogDriver.driverself.driver.get(self.url)#成功登陆的测试用例def LoginSucTest(self):self.driver.find_element(By.CSS_SELECTOR, "#username").clear()self.driver.find_element(By.CSS_SELECTOR, "#password").clear()self.driver.find_element(By.CSS_SELECTOR,"#username").send_keys("zhangsan")self.driver.find_element(By.CSS_SELECTOR,"#password").send_keys("123456")self.driver.find_element(By.CSS_SELECTOR,"#submit").click()sleep(2)#能够找到博客首页用户的昵称.self.driver.find_element(By.CSS_SELECTOR,"body > div.container > div.left > div > h3")#添加屏幕截图BlogDriver.getScreeShot()#返回到登陆页面#self.driver.back()#异常登陆的测试用例def LoginFailTest(self):#若连续多次的send_keys则会出现关键词拼接,而不是替换。若要替换需要先clearself.driver.find_element(By.CSS_SELECTOR, "#username").clear()self.driver.find_element(By.CSS_SELECTOR, "#password").clear()self.driver.find_element(By.CSS_SELECTOR, "#username").send_keys("zhangsan")#错误的密码self.driver.find_element(By.CSS_SELECTOR, "#password").send_keys("123")self.driver.find_element(By.CSS_SELECTOR, "#submit").click()#添加屏幕截图BlogDriver.getScreeShot()#点击确认按钮alert=self.driver.switch_to.alertalert.accept()在博客登录页里面,实现了两个测试用例,分别是正确的账号,密码即成功登录。正确的账号错误的密码,即登陆失败。
博客列表页
import time
from time import sleepfrom selenium.webdriver.common.by import Byfrom common.Utils import BlogDriver
#博客首页测试用例
class BlogList:url = ""driver = ""def __init__(self):self.url = "http://8.137.19.140:9090/blog_list.html"self.driver = BlogDriver.driverself.driver.get(self.url)#测试首页(登录情况下)def ListTestByLogin(self):time.sleep(1)#测试博客标题是否存在self.driver.find_element(By.XPATH,"/html/body/div[2]/div[2]/div[1]/div[1]")#测试博客内容是否存在self.driver.find_element(By.XPATH,"/html/body/div[2]/div[2]/div[1]/div[3]")#测试按钮是否存在self.driver.find_element(By.XPATH,"/html/body/div[2]/div[2]/div[1]/a")#个人信息-检查昵称是否存在self.driver.find_element(By.XPATH,"/html/body/div[2]/div[1]/div/h3")#添加屏幕截图BlogDriver.getScreeShot()在博客列表页中,我们在登录的前提下,进行列表页元素的查找。这里我使用的选择器是Xpath。那么我们该如何去验证代码是否正确呢,在当前文件下创建类的对象用它来调用我们写的函数,可以吗?显然是错误的,博客列表页的前提是登录,我们登录页面在另一个文件。所以我们需要单独创立一个文件来运行所有的文件代码,通过导入包的方式。
runcase
from time import sleepfrom tests import blog
from tests import bloglist
from tests import blogdetail
from tests import blogedit
from common.Utils import BlogDriverif __name__ == "__main__":blog.BlogLogin().LoginFailTest()blog.BlogLogin().LoginSucTest()#登陆成功之后就可以调用博客首页测试首页的用例sleep(2)bloglist.BlogList().ListTestByLogin()#测试登录状态下的博客详情页blogdetail.BlogDeail().DetailTestByLogin()#博客编辑页面blogedit.BlogEdit().EditSucTestByLogin()#指定浏览器的退出BlogDriver.driver.quit()
博客编辑
import time
from time import sleepfrom selenium.webdriver.common.by import Byfrom common.Utils import BlogDriver# 测试博客编辑页面
class BlogEdit:url = ""driver = ""def __init__(self):self.url = "http://8.137.19.140:9090/blog_edit.html"self.driver = BlogDriver.driverself.driver.get(self.url)# 正确发布博客(登陆状态下)def EditSucTestByLogin(self):self.driver.find_element(By.CSS_SELECTOR, "#title").send_keys("自动化测试创建")# 找到编辑区域,输入关键#菜单栏无法元素无法定位#博客系统编辑区域默认情况下就不为空,可以暂不处理#直接点击发布按钮来发布博客self.driver.find_element(By.CSS_SELECTOR,"#submit").click()sleep(10)actual=self.driver.find_element(By.CSS_SELECTOR,"body > div.container > div.right > div:nth-child(5) > div.title").textassert actual == "自动化测试创建"#屏幕截图BlogDriver.getScreeShot()
博客编辑页面中我们测试了在登陆状态下能否正确的发布一篇博客。
博客详情页
from selenium.webdriver.common.by import Byfrom common.Utils import BlogDriver
#测试博客详情页
class BlogDeail:url = ""driver = ""def __init__(self):self.url = "http://8.137.19.140:9090/blog_detail.html?blogId=158477"self.driver = BlogDriver.driverself.driver.get(self.url)#登陆状态下博客详情页的测试def DetailTestByLogin(self):#检查标题self.driver.find_element(By.CSS_SELECTOR,"body > div.container > div.right > div > div.title")#检查时间self.driver.find_element(By.CSS_SELECTOR,"body > div.container > div.right > div > div.date")#检查内容self.driver.find_element(By.CSS_SELECTOR,"#detail")#屏幕截图BlogDriver.getScreeShot()
上述测试的基本步骤都是先将浏览器驱动对象导入进来,创建类对象,写入变量url,driver等变量,在创立测试函数。其中创立截图文件的目的是为了更好的发现问题,更加精确的去发现问题。
4 自动化测试与手动测试的区别
- 自动化测试:能够快速、批量地执行大量测试用例,尤其适合重复性测试场景。例如,对一个电商网站的购物车功能进行多轮回归测试,自动化测试可以在短时间内模拟多次添加商品、修改数量、结算等操作,极大地提高测试效率。并且可以 24 小时不间断运行,在夜间等非工作时间执行测试任务。
- 手动测试:执行速度相对较慢,每一个测试步骤都需要测试人员手动操作,容易受到疲劳、注意力等因素影响。对于大规模测试用例集,手动测试耗时较长,难以在短时间内完成多次重复测试。
5 利用jmeter软件对博客系统进行性能测试
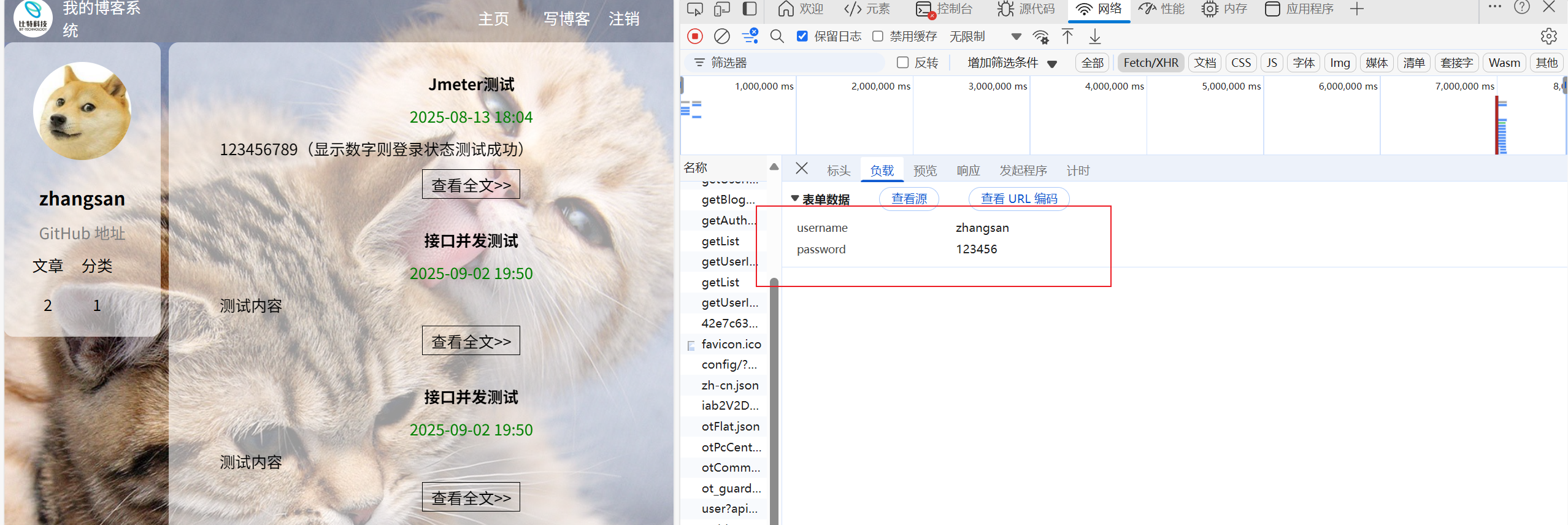
在博客系统页面的开发者工具中我们点击网络选项,在这里我们可以看到url和这个接口所自带的一些参数。
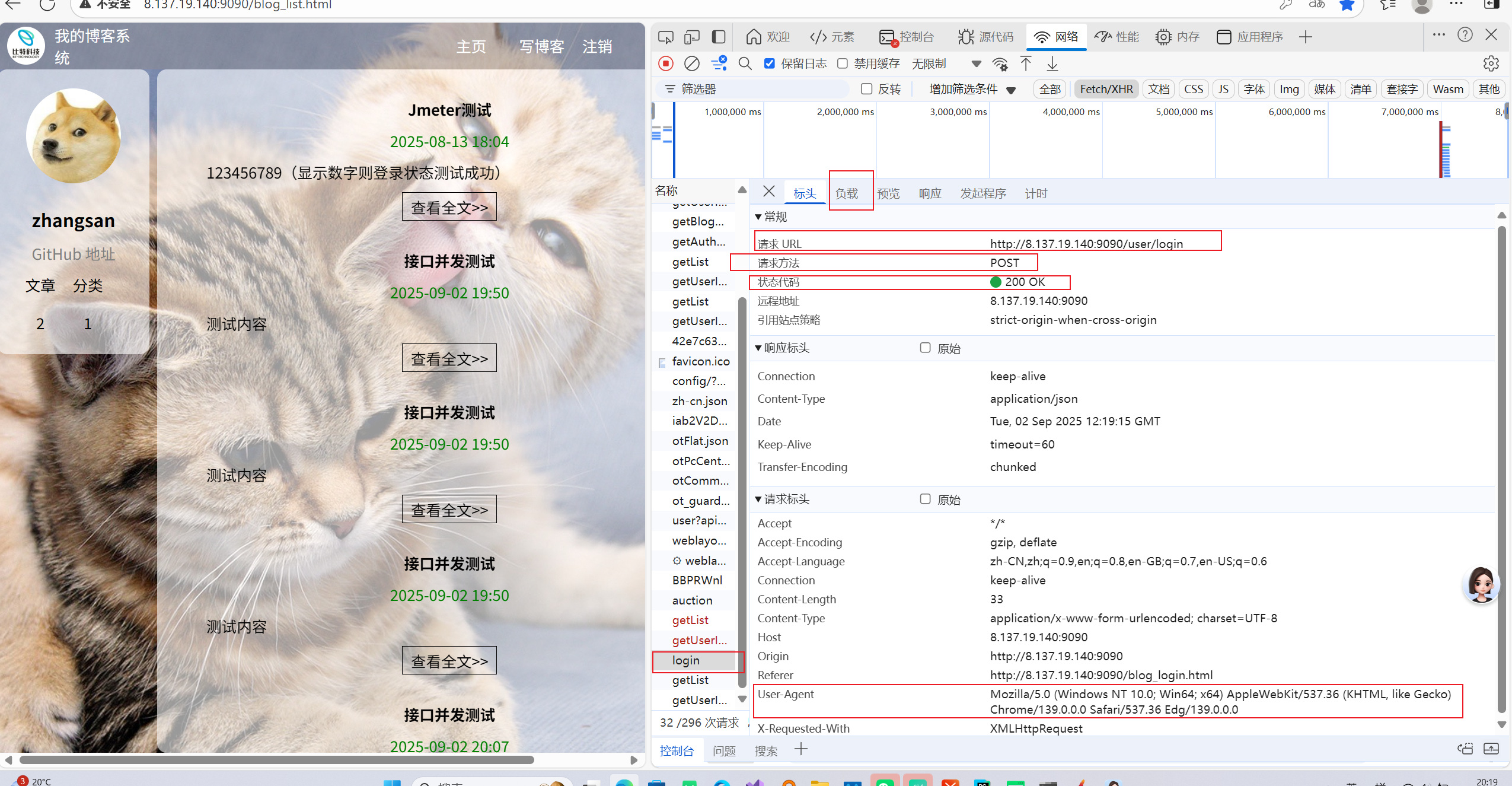
这都是些比较重要的信息,例如:该接口请求方法为post,200K表示该接口成功运行,user-agent表示这一次登录的用户凭证。在负载里面我们可以看见该接口的参数。
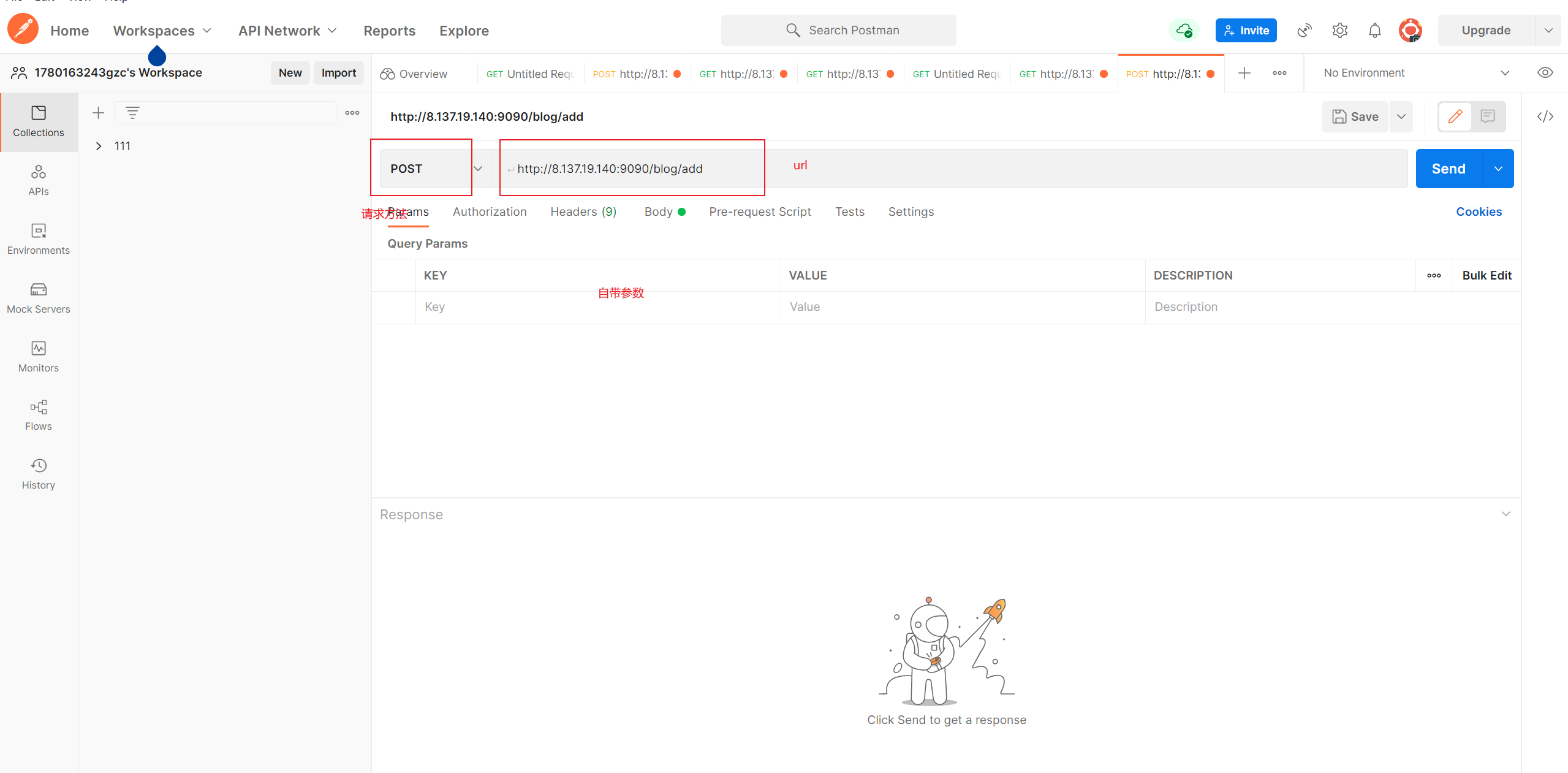
在进行性能测试之前,我们可以现有postman来进行简单验证,可以更详细的看到该接口的返回数据。
点击send按钮即可看见该接口所返回的一系列数据。
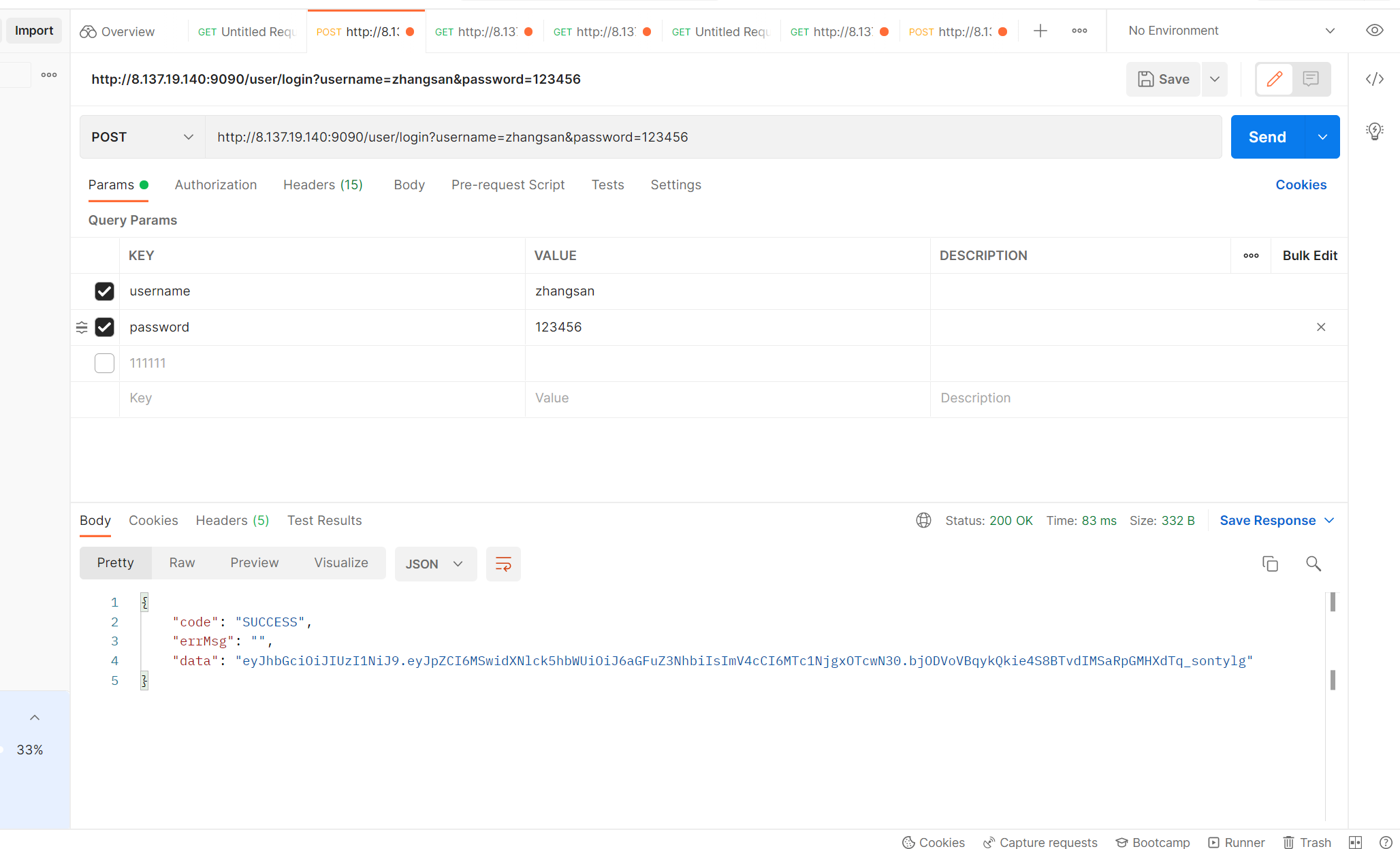
状态码,错误信息,返回数据等等……
5.1 jmter的简单测试
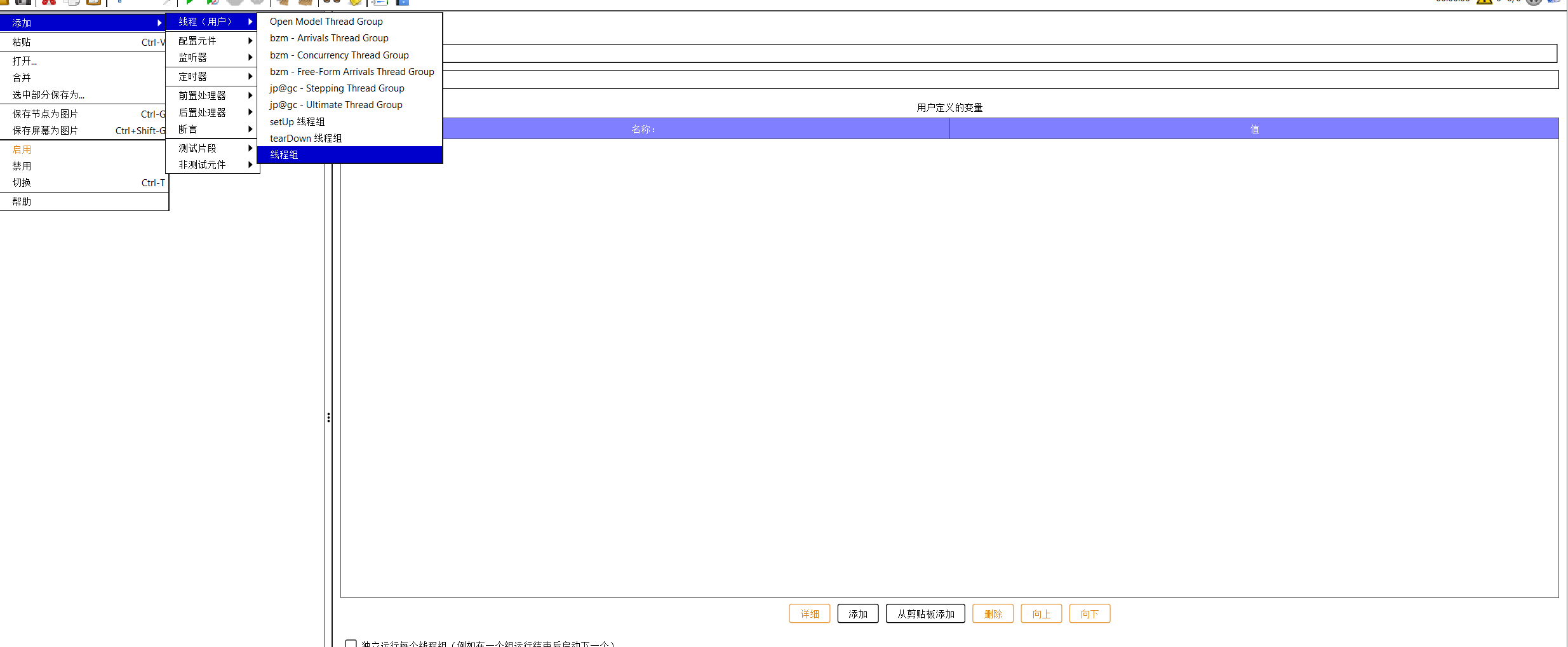
我们添加线程组

所谓线程数就是虚拟用户实际请求的次数,请求多少次,时间为测试运行的时间,循环次数即可以循环请求。
接下来我们添加http请求
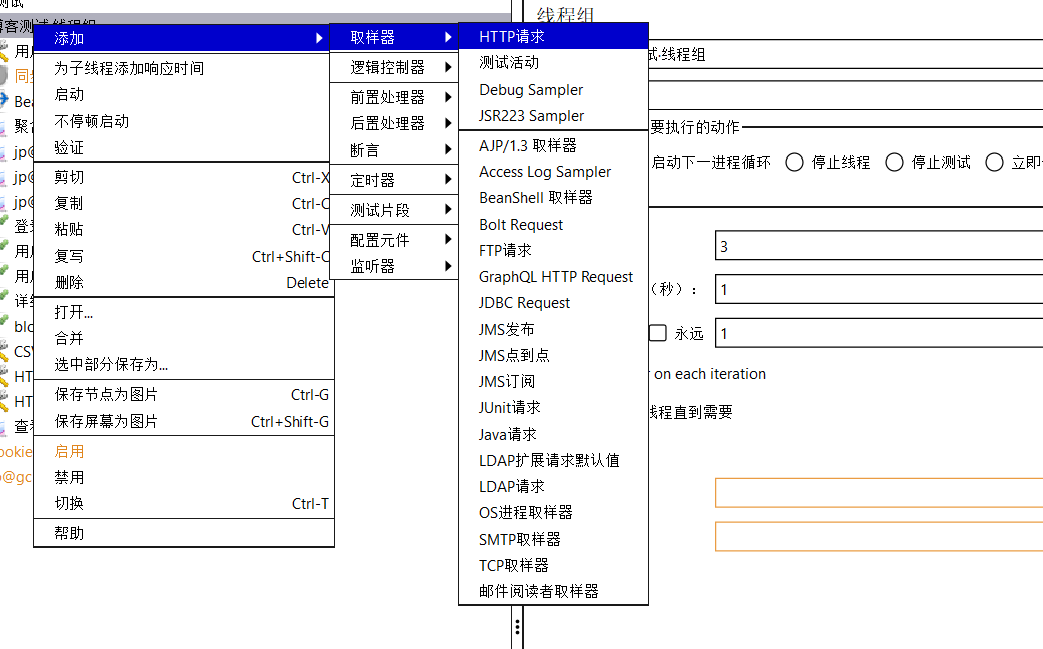
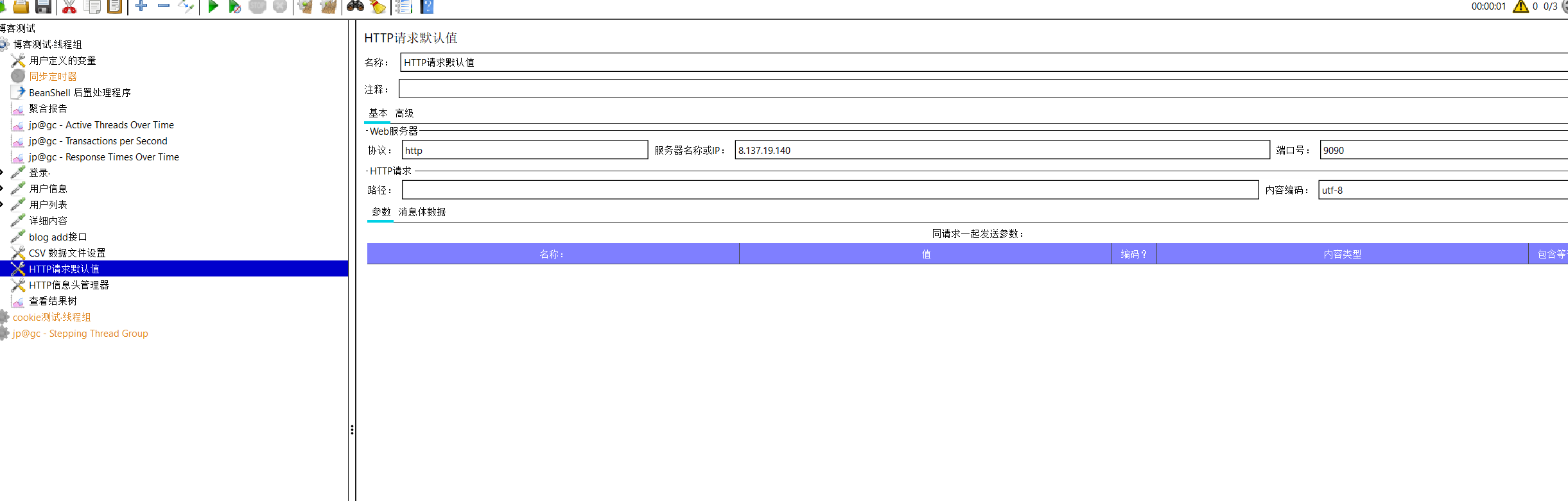
我们要添加最少5个,因为同一个系统中协议,服务器名称或IP,端口号是不会发生变化的。所以我们可以添加一个http默认值
我们将所有参数添加完成后,添加查看结果树。在这我们可以看见接口的状态。运行之后我们发现了401报错,经过与postman与网页中开发者功能一一对比,我们发现用户登录凭证我们并没有加上,这是登录时才会有的东西,所以我们想可不可以将登录接口的返回数据中的登录凭证加入其他接口的请求数据里。而jmeter中JSON提取器恰好可以做到。
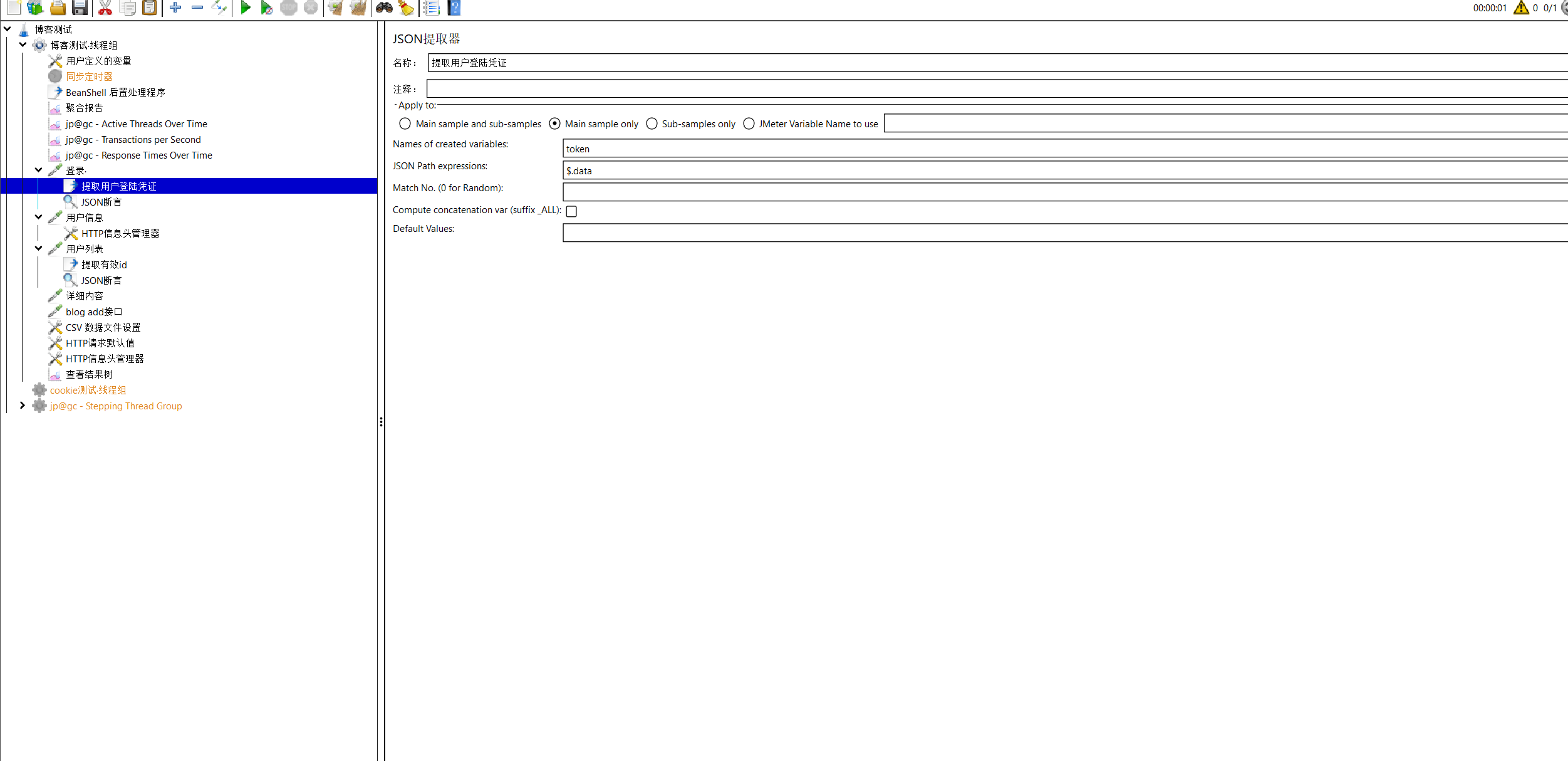
我们这样配置以后即将用户登录凭证提取到了变量token中,怎样将其加进去呢?我们还需要一个功能,即http信息头管理,
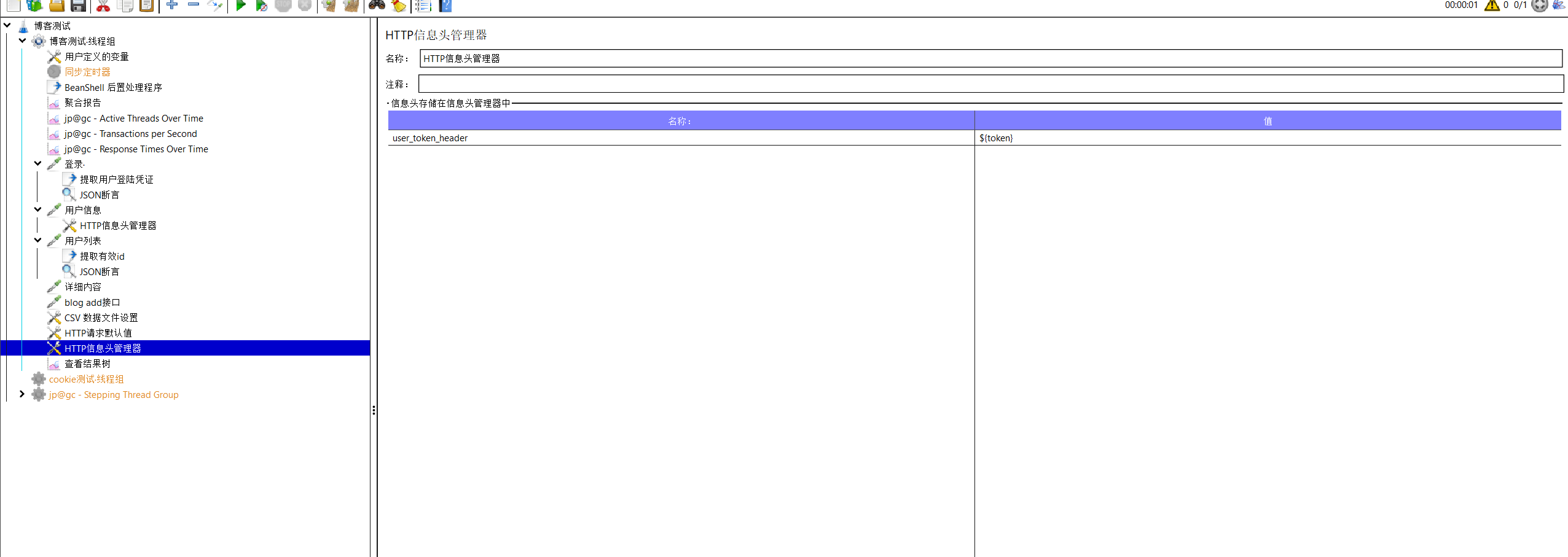
注意它的作用域实在全局,所以所有的接口都可以享受到其的功能。再次运行我们又发现博客详情页的id总是不变的,这显然不符合事实,我们利用json提取器将用户列表的id提取出来,将它作为变量拼接到用户详情页的后面。
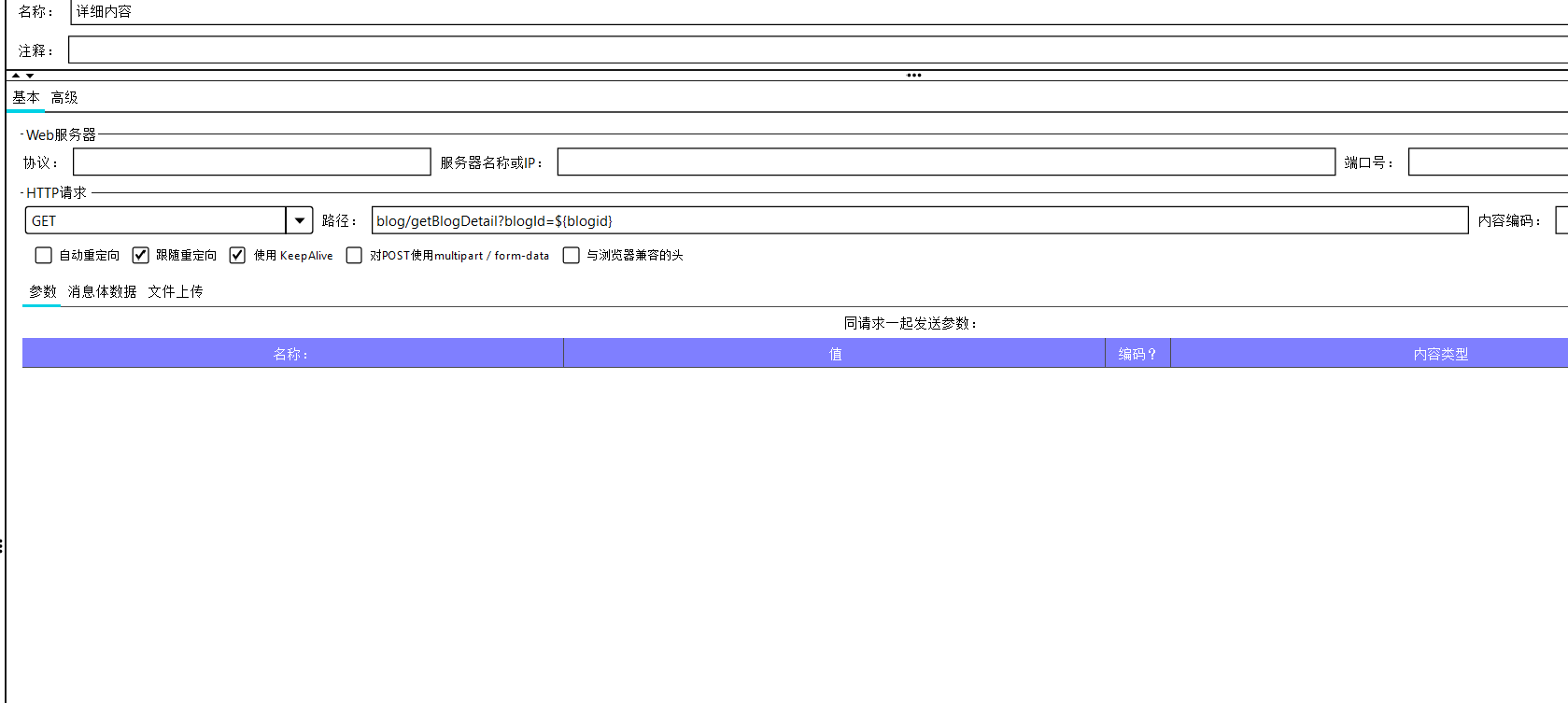
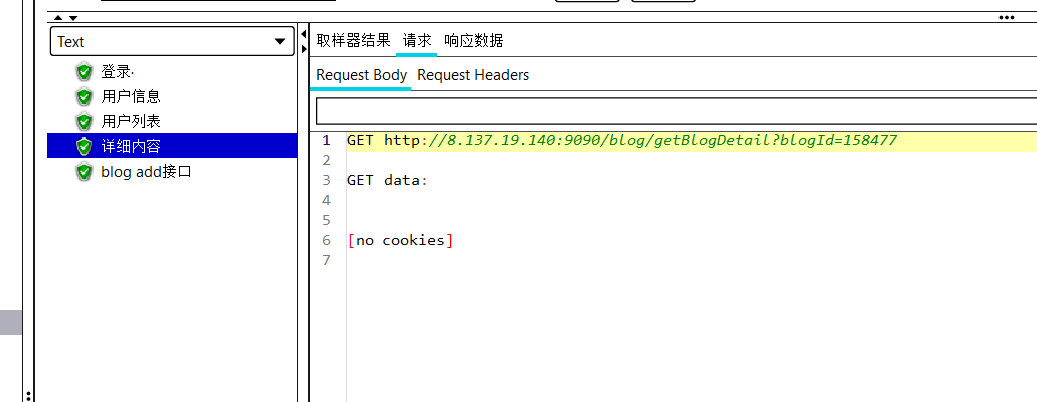
在测试运行时还发现add发送接口始终运行错误,在与postman,网页开发者对比以后发现
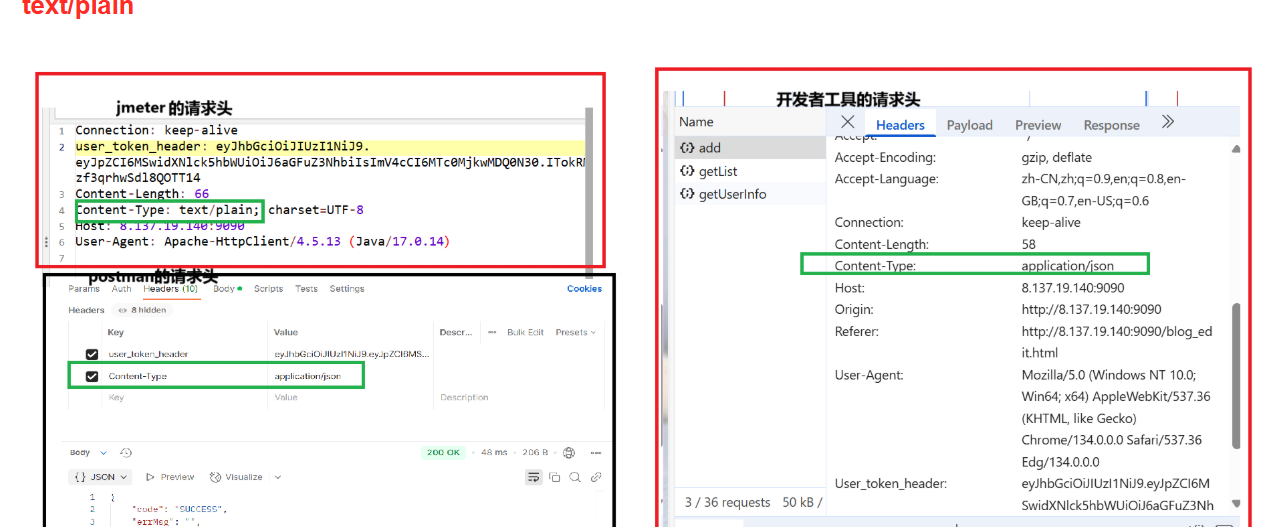
我们可以看到开发者工具上面和postman的content-Type:是application/json,而jmeter的content-Type:是text/plain。所以我们给他的子类添加一个http信息头管理器,来改变它的content-type。
已经知道,登录系统不止有一个登录账号,密码。而我们这样测试每次都是一样的用户,该如何去解决呢?我们可以利用csv数据文件设置来实现。
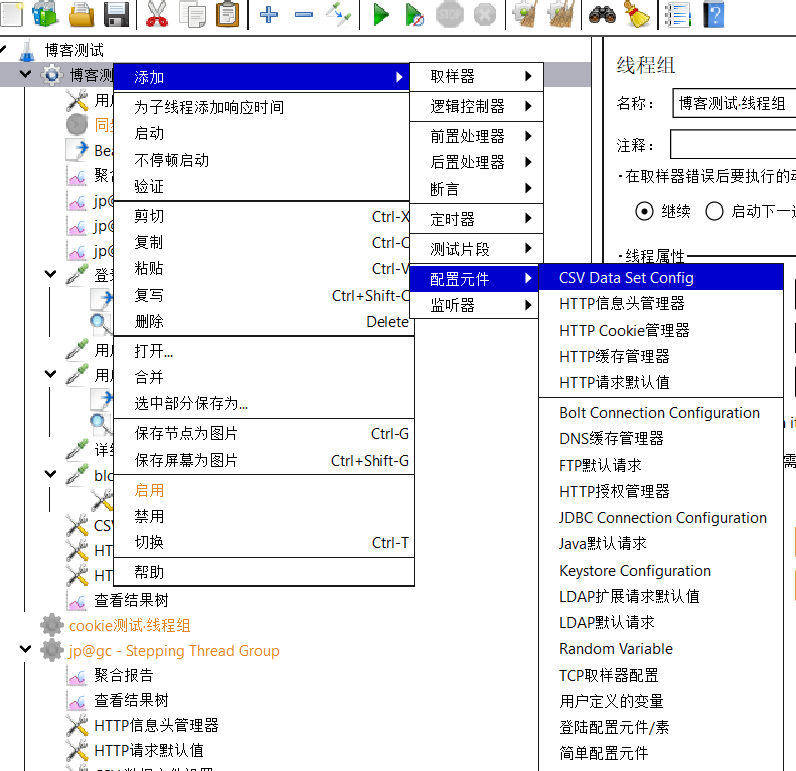

• 文件名:填写csv文件的路径。建议使用绝对路径。
• 文件编码:UTF-8
• 变量名称:从csv数据文件中读起的数据需要保存到的变量名。有多个变量时用逗号分隔。
• 是否忽略首行:是否从csv数据文件第一行开始读取。
• 分隔符:要求与csv数据文件中多列的分隔符⼀致。
• 遇到文件结束符再次循环:若选择为True当数据不够的时候会从头取。若选择False,则需要勾选
下面的配置,遇到文件结束符停⽌线程,这里如果不勾选,请求将会报错。
将工作表里面的所有账号密码提取出来且放到两个变量后,我们改变登录接口的两个参数。
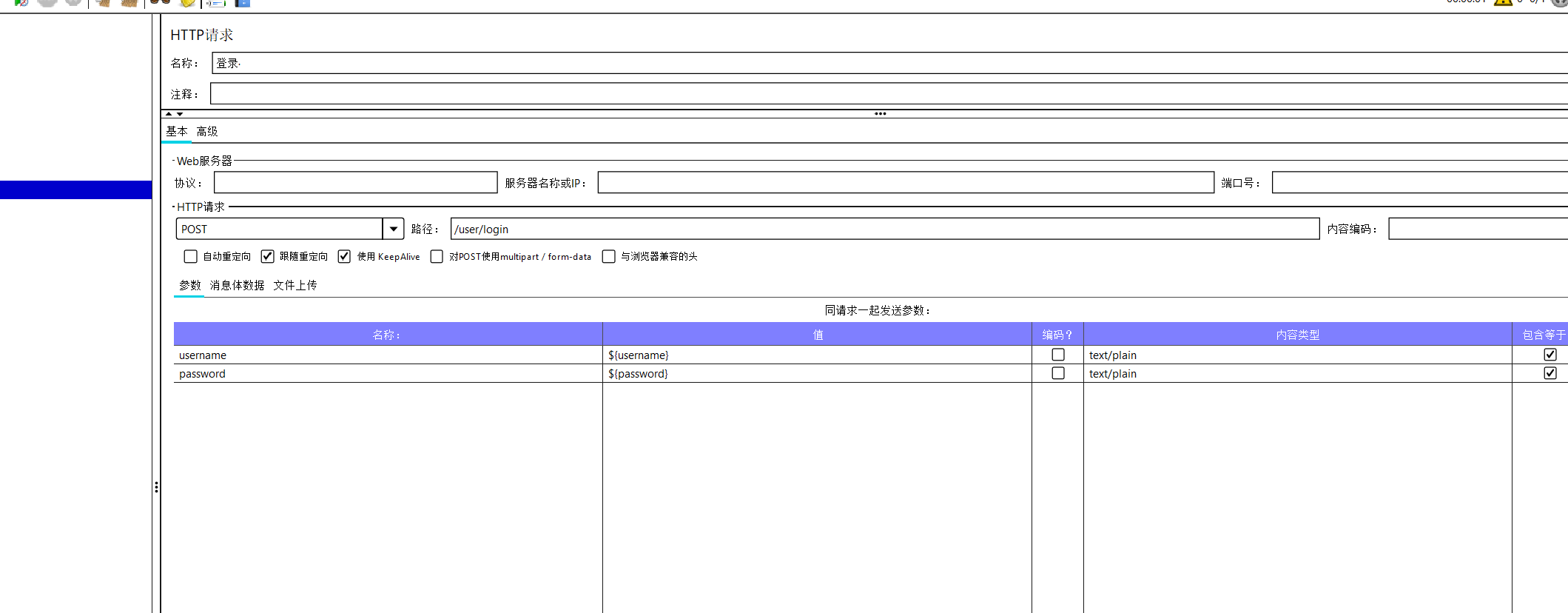
性能测试的几个小插件。用来测量吞吐量和响应时间和梯度压测的一些重要测量值。
为什么要添加梯度压测线程组呢?因为我们的线程数量是慢慢增加的,比如我们要测试服务器的最大承载能力:是先加100的线程,观察一段时间,服务器没有问题,再继续往上增加线程的数量,一上来就给很大,可以直接给服务器整奔溃。
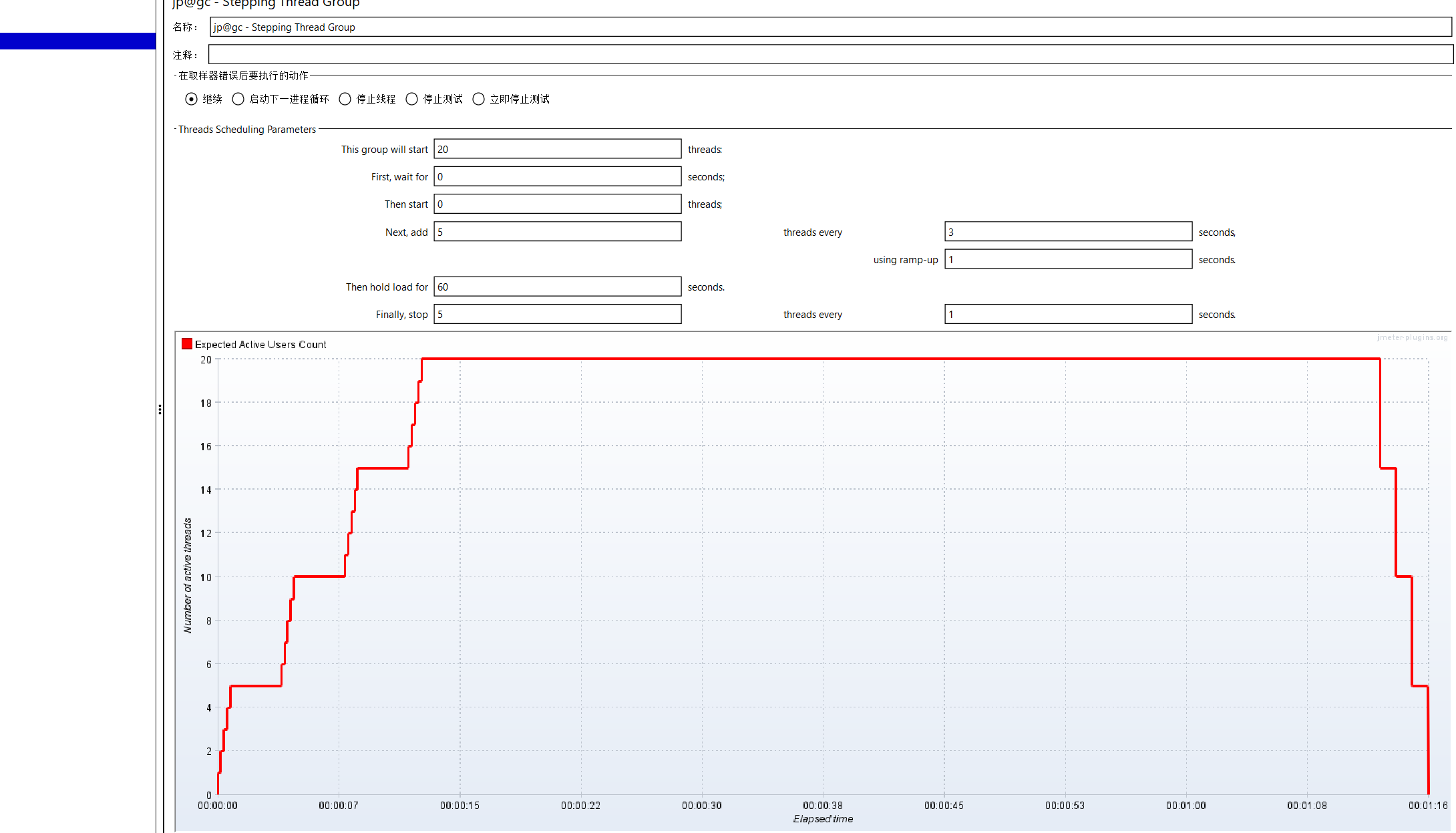
This group willstart:启动多少个线程,同线程组中的线程数
First wait for:等待多少秒才开始压测,⼀般默认为0
Then start:⼀开始有多少个线程数,⼀般默认为0
Next,add:下⼀次增加多少个线程数
threads every:当前运行多长时间后再次启动线程,即每一次线程启动完成之后的的持续时间;
using ramp-up:启动线程的时间;若设置为5秒,表示每次启动线程都持续5秒
thenhold loadfor:线程全部启动完之后持续运性多长时间
finally,stop/threadsevery:多长时间释放多少个线程;若设置为5个和1秒,表示持续负载结束之后
每1秒钟释放5个线程
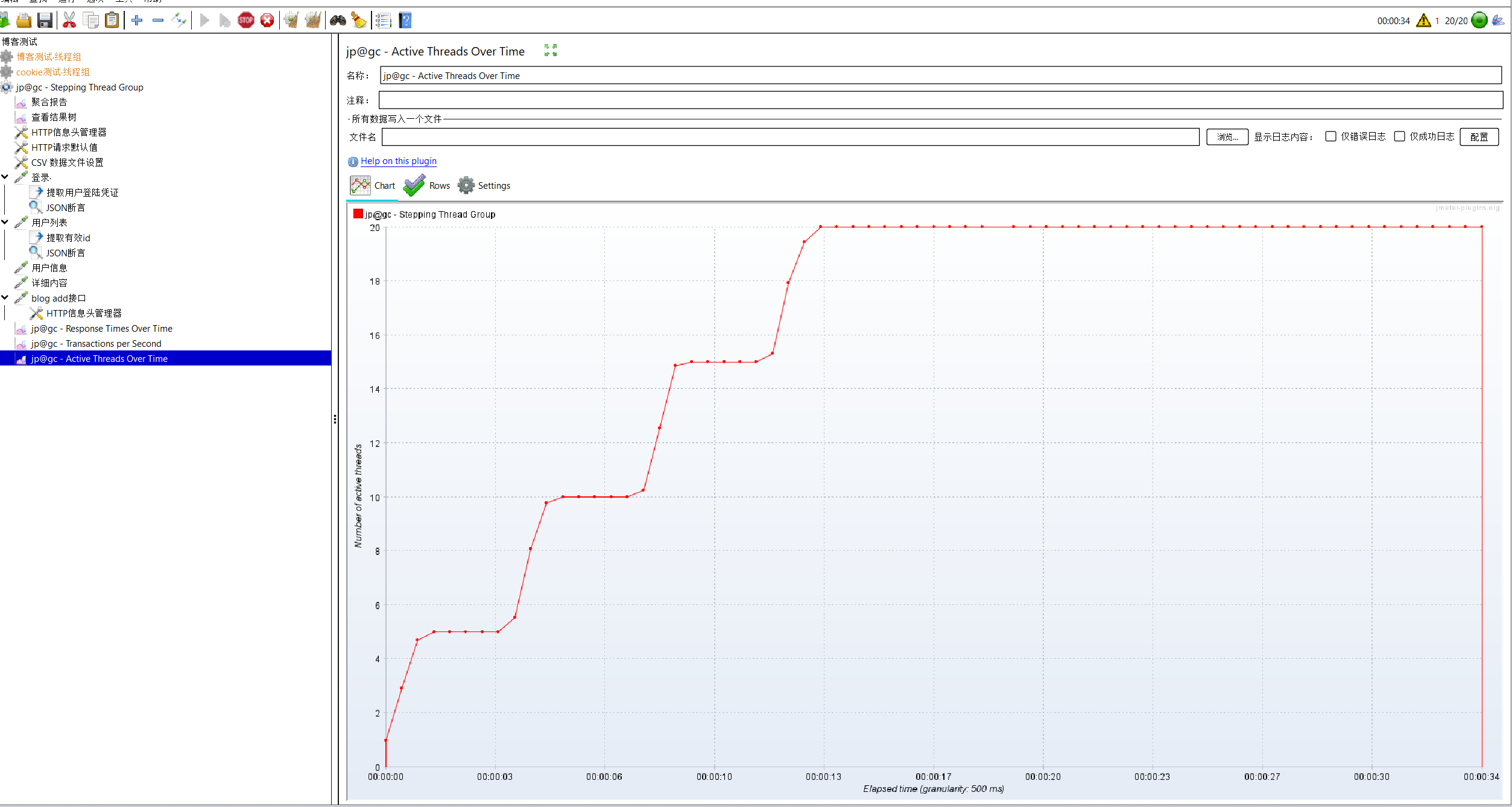
5-2查看活跃线程数量
响应时间
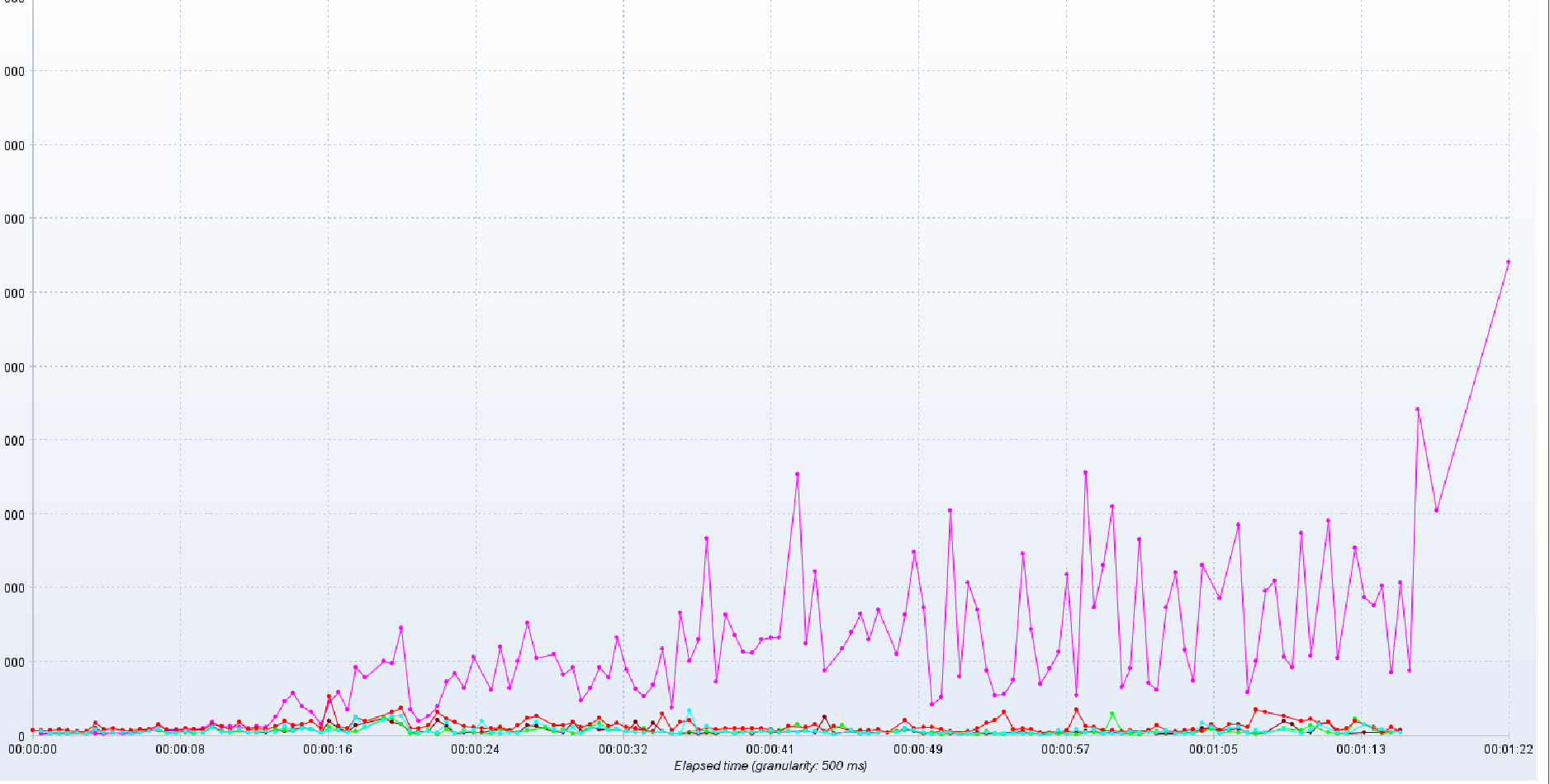
吞吐量
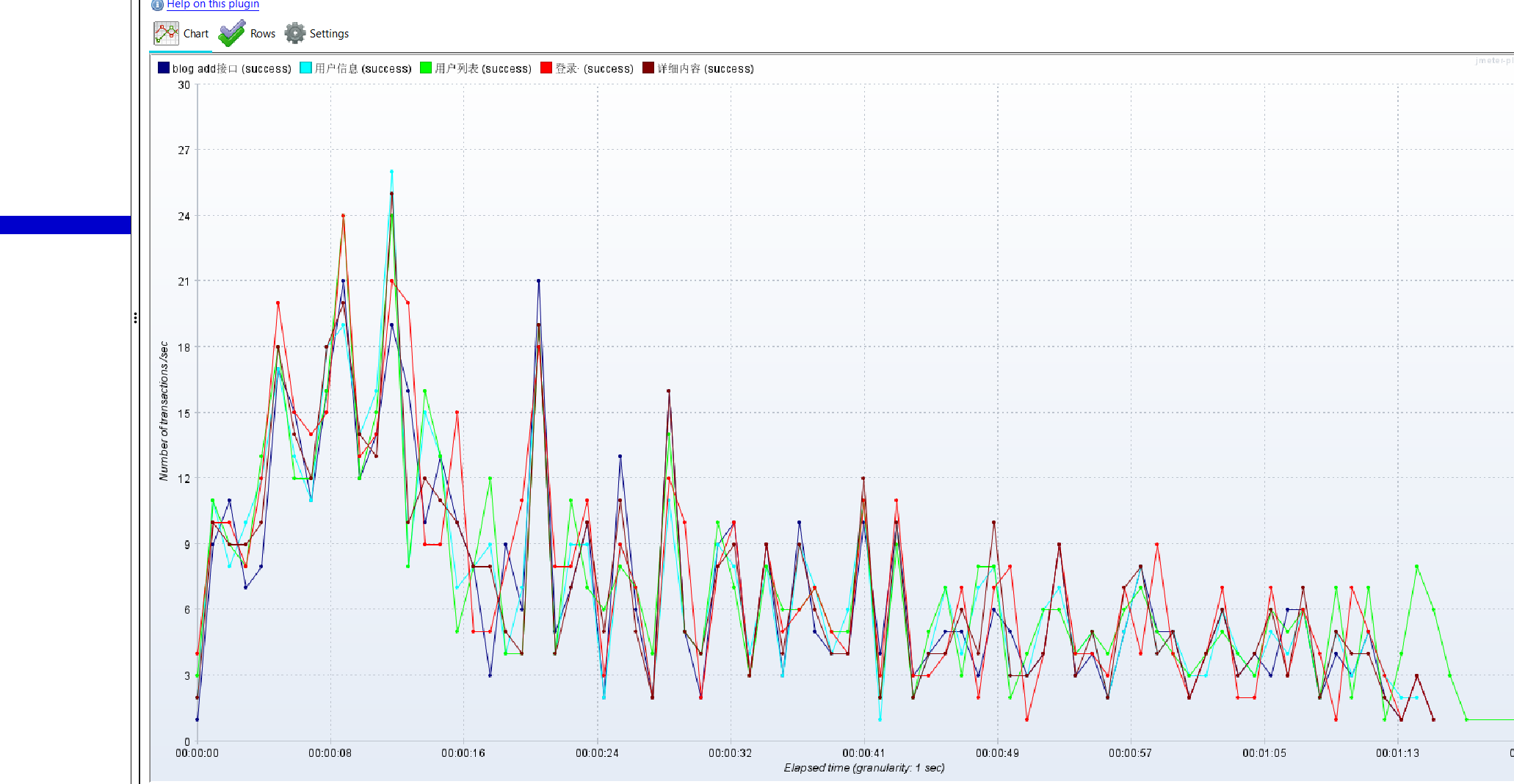
我们添加聚合报告,可以看清楚请求了多少次。

不难看出,
- 用户列表的运行时间明显比其他接口长的多,所以这个接口是有问题的。
- 吞吐量和响应时间的关系,响应时间增加了,服务器就有了压力,这个时间服务器处理的并发数量是有限的,所以吞吐量就降低了。
6 生成测试报告
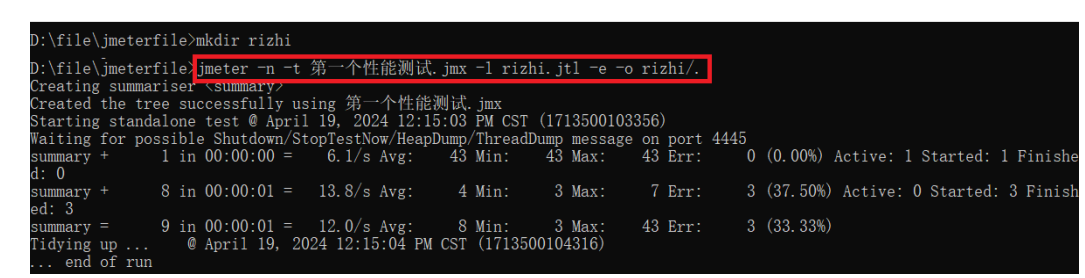
在cmd下找到jmeter的存储位置,输入上述代码。得先在路径下自己创建一个rizhi文件夹!
Jmeter -n -t 脚本⽂件 -l ⽇志⽂件 -e -o ⽬录
-n : 无图形化运行
-t : 被运行的脚本
-l : 将运行信息写入日志文件,后缀为 jtl 的日志文件
-e : 生成测试报告
-o : 指定报告输出目录
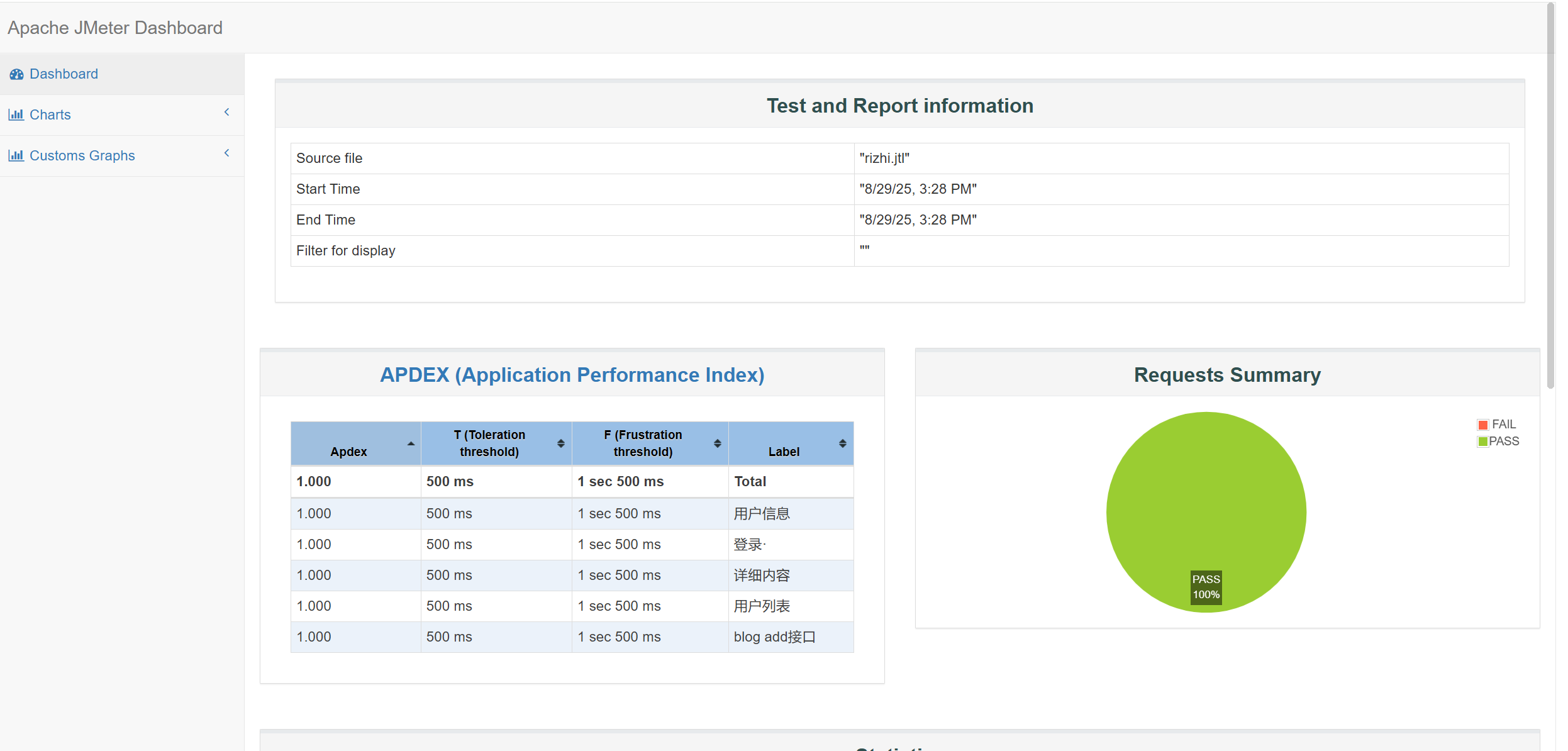
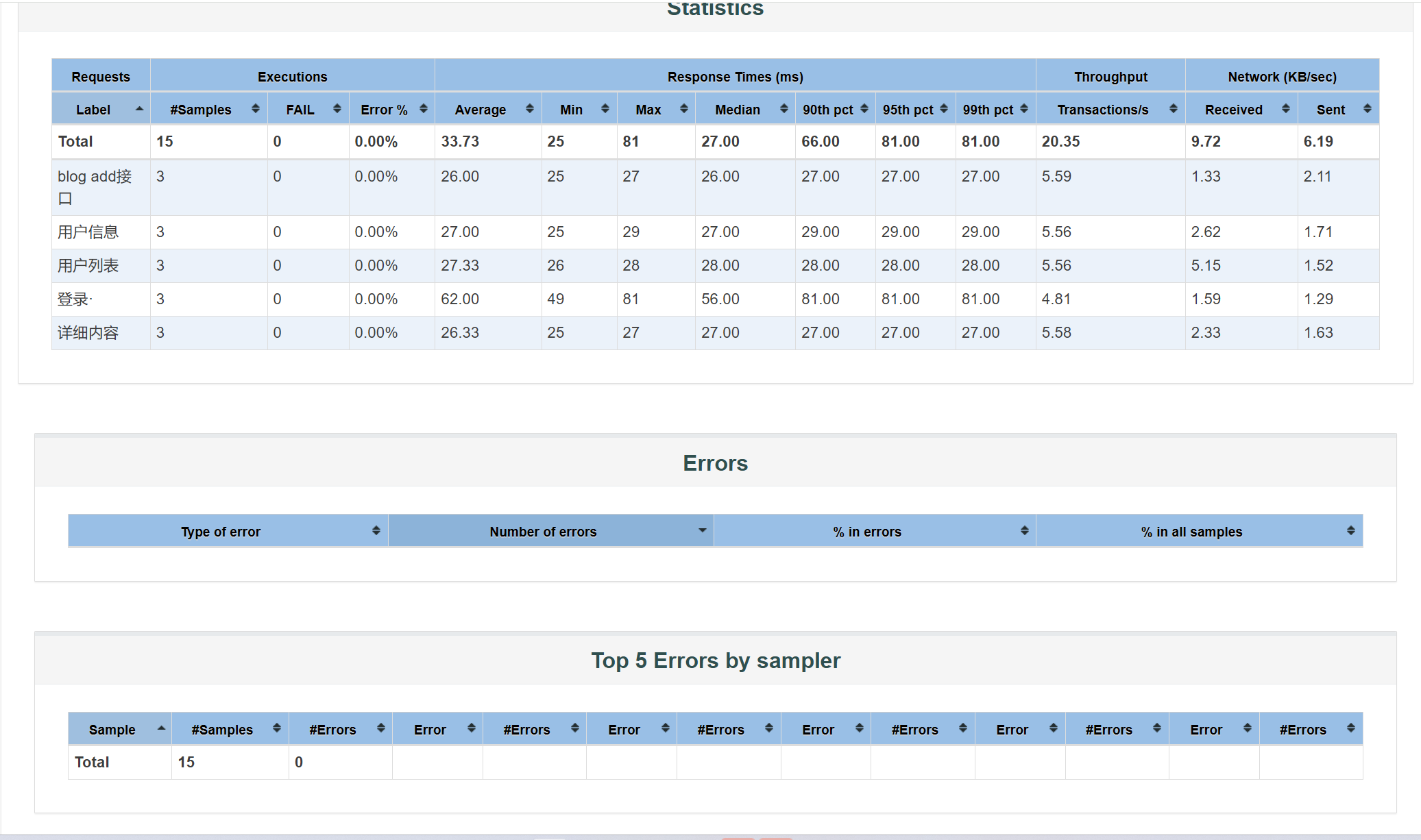
至此已测试完毕。