Redis分层缓存
我们来深入浅出地详细讲解 Redis 分层缓存的知识。这是一个非常重要且实用的高性能架构设计模式。
一、核心思想:用“空间”换“时间”,用“成本”换“性能”
想象一下图书馆的藏书架构:
你的书桌(本地缓存):放着你正在看和马上要看的几本书。取用速度极快(纳秒级),但空间极小。
图书馆的开架阅览室(Redis):放着大家最常借的热门书籍。取用速度很快(毫秒级),空间较大。
图书馆的地下书库(数据库MySQL):放着所有的书籍。取用速度很慢(磁盘I/O,毫秒到秒级),空间极大。
你要找一本书时,会按照 书桌 -> 阅览室 -> 地下书库 的顺序去找。这样,绝大部分时间你都能在前两步就找到书,效率最高。只有极少数的冷门书籍才需要去书库翻找。
这就是分层缓存的核心思想:将数据存储在不同性能和成本的“层”中,让尽可能多的请求被最快、最便宜的层所响应。
二、经典的三层缓存架构
你听说的“三层”,通常指的是下图所示的经典架构:本地缓存 -> 分布式缓存(Redis) -> 数据库。这是一种从快到慢、从贵到廉的排列。
图表
代码
下面我们来详细拆解每一层。
第1层:本地缓存 (Local Cache)
是什么? 存储在应用程序进程的内存中。每个服务器实例都有自己的本地缓存,彼此不共享。
技术选型:
C++/Golang可以用std::map/sync.Map;Java可以用Caffeine,Guava Cache;JavaScript可以用lru-cache等。特点:
速度极快:直接读内存,无网络开销,纳秒/微秒级响应。
容量极小:受单机内存限制,只能存储极少量的热点中的热点数据。
非分布式:缓存数据不在多实例间同步,可能造成短暂的数据不一致。
适用场景:
极端热点的数据(如某个爆款商品的详情)。
几乎不变的数据(如系统配置、字典项)。
可容忍一定时间不一致的数据。
第2层:分布式缓存 (Distributed Cache - Redis)
是什么? 独立的、网络式的缓存服务,所有应用程序实例都访问同一个Redis集群。
技术选型:Redis、Memcached。
特点:
速度快:内存存储,但有网络开销,亚毫秒/毫秒级响应。
容量大:独立集群,容量可扩展(可达TB级),能存储大量的热点数据。
分布式:数据集中存储,保证所有应用实例看到的缓存数据是一致的。
适用场景:
绝大部分热点数据(如用户信息、会话、商品列表、排行榜)。
需要共享的缓存数据。
需要利用Redis丰富数据结构(如Set、ZSet、Hash)的场景。
第3层:数据库 (Database)
是什么? 数据的最终落地存储,数据的唯一真相来源。
技术选型:MySQL、PostgreSQL、MongoDB等。
特点:
速度慢:数据存储在磁盘,毫秒/秒级响应(即使有数据库自身缓存,也慢于Redis)。
容量极大:磁盘存储,容量可轻松扩展(可达PB级),存储全量数据。
持久化与一致性:通过事务、日志等机制保证数据的强一致性和持久化。
适用场景:
数据的持久化存储。
复杂的查询和事务操作。
缓存未命中时的数据兜底。
三、数据访问流程(回种流程)
结合上面的流程图,我们来看一次完整的缓存读取流程,这被称为 “回种”:
请求到达:用户请求获取用户ID=1的信息。
检查本地缓存:应用先检查自己的本地内存中是否有
user:1的数据。如果有(缓存命中):直接返回数据,流程结束。(最快路径)
检查Redis:如果本地缓存没有,就发起一个网络请求,问Redis:“你有
user:1吗?”如果有(缓存命中):
将数据返回给应用。
应用同时把这份数据存一份到自己的本地缓存中(并设置一个较短的过期时间,比如5分钟),以便后续请求能走更快的第一层。然后返回数据。
查询数据库:如果Redis也没有(这被称为缓存穿透),应用只能去查询数据库。
从数据库的
user表中查询ID=1的用户信息。
回种缓存:
回种Redis:应用从数据库拿到数据后,首先将其写入Redis(并设置一个合理的过期时间,比如30分钟)。这样下一个请求来就能在第二层命中。
回种本地缓存:同时,也会把数据放入本地缓存(设置更短的过期时间,比如5分钟)。
返回数据:最终,数据返回给用户。
这个流程确保了:热数据会逐渐被“提升”到更快的缓存层中。
四、分层缓存的核心优势
极致性能:99% 的请求可能由本地缓存和Redis处理,响应速度极快,数据库压力极小。
高可用性与伸缩性:
即使Redis短暂宕机,应用还能依靠本地缓存支撑一部分流量,不至于数据库立刻被击垮。
可以通过增加应用实例和Redis节点来水平扩展系统的整体吞吐量。
成本效益:用昂贵的内存存储最热的数据,用廉价的磁盘存储全量数据,实现了成本和性能的最佳平衡。
五、在聊天服务器项目中的具体应用
在你的聊天服务器中,可以这样设计:
| 数据类型 | 本地缓存 (L1) | Redis (L2) | 数据库 (L3) | 说明 |
|---|---|---|---|---|
| 用户信息 | √ (短时间) | √ (较长时间) | √ (永久) | 用户登录后,其信息可缓存在本地和Redis |
| 好友列表 | √ (短时间) | √ (较长时间) | √ (永久) | 关系变化不频繁,适合缓存 |
| 群组成员 | √ (短时间) | √ (较长时间) | √ (永久) | 同上 |
| 群聊消息 | × | √ (短时间) | √ (永久) | 消息量大,通常只放Redis做短暂缓存 |
| 离线消息 | × | √ (临时) | √ (永久) | 发出后存Redis,被收取后删除,并持久化到DB |
| 会话状态 | √ | √ | × | 用户连接在哪台服务器上,这类状态信息非常适合用Redis共享 |
举例:获取用户信息
cpp
// 伪代码
User getUserInfo(int userId) {// 1. 检查本地缓存User user = localCache.get(userId);if (user != null) {return user;}// 2. 检查Redisuser = redis.get("user:" + std::to_string(userId));if (user != null) {// 回种到本地缓存localCache.set(userId, user, LOCAL_TTL);return user;}// 3. 查询数据库user = db.query("SELECT * FROM users WHERE id = ?", userId);if (user != null) {// 回种到Redis和本地缓存redis.setex("user:" + std::to_string(userId), REDIS_TTL, user);localCache.set(userId, user, LOCAL_TTL);}return user;
}六、必须注意的挑战与解决方案
分层缓存很强大,但也引入了复杂性: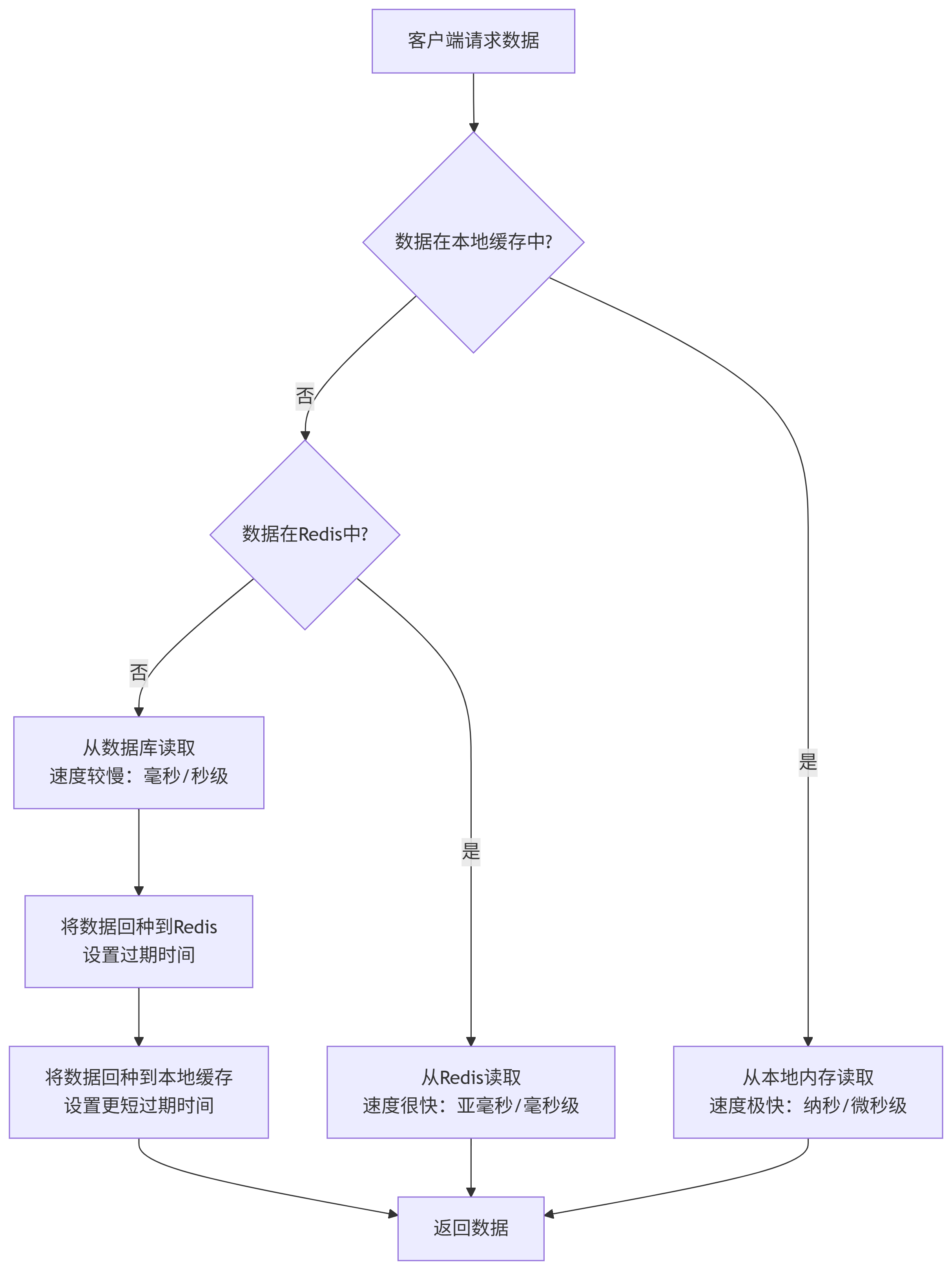
缓存穿透:请求一个数据库中根本不存在的数据,导致请求每次都穿透缓存打到数据库。
解决方案:对于不存在的数据,也在缓存中设置一个空值(如
NULL)并设置一个很短的过期时间。
缓存击穿:某个极端热点数据过期时,大量请求同时涌来,瞬间击穿缓存到数据库。
解决方案:使用互斥锁。第一个请求发现缓存过期时,加锁去数据库加载数据,其他请求等待锁释放后直接从缓存读取。
缓存雪崩:同一时刻大量缓存键同时过期,导致所有请求都打到数据库。
解决方案:给缓存过期时间加上一个随机值(如基础30分钟 + 随机0-5分钟),避免同时过期。
数据不一致:数据库数据更新后,缓存中的数据还是旧的。
解决方案:
先更新数据库,再删除缓存。这是最常用的策略。
通过消息队列进行异步更新,确保最终一致性。
为缓存设置较短的过期时间,到期后自动重新加载。
总结
Redis分层缓存(尤其是L1/L2/L3架构)是构建高性能、高可用应用的基石技术。它通过将数据分级存储,巧妙地平衡了速度、容量和成本。
其核心精髓在于:
L1 本地缓存:解决速度问题,应对极致热点。
L2 Redis:解决容量和共享问题,应对主要热点。
L3 数据库:解决持久化和全量数据问题,是数据的最终保障。
理解和运用好这套架构,你的聊天服务器性能将得到质的飞跃。