Hysplit大气传输和污染扩散-轨迹聚合标准20%30%用途
1、HYSPLIT轨迹聚合中的百分比标准
在HYSPLIT模型中,轨迹聚合(Trajectory Clustering)用于将大量轨迹按相似性分组,20%和30%是常见的聚合阈值标准,反映轨迹间的空间相似度要求。
2、20%和30%的具体含义
这两个百分比代表轨迹聚合算法中允许的最大空间差异阈值。具体计算基于轨迹之间的空间距离标准差(或均方根距离):
- 20%阈值:要求轨迹组内各轨迹间的空间差异不超过整体轨迹样本空间分布标准差的20%,聚合条件更严格,生成的组数更多。
- 30%阈值:允许更大的空间差异(标准差的30%),聚合条件更宽松,生成的组数较少但每组轨迹更分散。
3、阈值选择的影响
20%标准
适用于需要高精度分析的场景(如污染源精确定位),轨迹分组更细,能识别更局部的传输路径,但可能增加计算量。30%标准
适合大尺度分析(如区域传输模式研究),减少组数以突出主要传输路径,可能忽略部分细节但增强整体规律的可视化。
4、个人理解
1)App默认使用30%参数。
2)官方文档:
View possible final number of clusters. Typically a pairing of "different" clusters is indicated by a 30% change in the percent change in total spatial variance (see Step 2, Display plot). Run lists the possible final cluster numbers. If the 30% criterion does not identify any, the 20% criterion may be chosen. The maximum is arbitrarily set to 20 clusters。(查看可能的最终聚类数量。通常,“不同”聚类的配对由总空间方差变化百分比中30%的变化表示(参见步骤2,显示图表)。运行列表显示可能的最终聚类数量。如果30%的标准未识别出任何结果,可选择20%的标准。最大聚类数默认设置为20个。)
也就是说默认使用30%来选择聚类数量,如果没有数量结果,则使用20%再算一次重新选择。
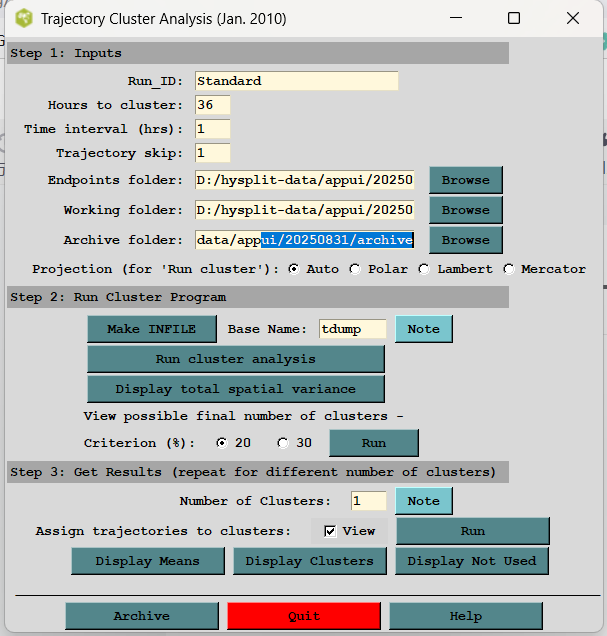
5、聚类数量读取Java代码
private List<NcDataEntry> readTsvFile(String filePath) {List<NcDataEntry> dataEntries = new ArrayList<>();try (BufferedReader br = new BufferedReader(new FileReader(filePath))) {String line;while ((line = br.readLine()) != null) {// 分割一个或多个空白字符String[] parts = line.trim().split("\\s+");if (parts.length >= 2) {try {int nc = Integer.parseInt(parts[0]);double tsv = Double.parseDouble(parts[1]);dataEntries.add(new NcDataEntry(nc, tsv));} catch (NumberFormatException e) {// 忽略无法解析为数字的行System.err.println("忽略无法解析的行: " + line);}}}} catch (IOException ex) {throw new FileOptionException("读取文件时出错: " + ex.getMessage());}return dataEntries;}
import lombok.Data;@Data
public class NcDataEntry {private int nc;private double tsv;public NcDataEntry(int nc, double tsv) {this.nc = nc;this.tsv = tsv;}
}