AntSK知识库多格式导入技术深度解析:从文档到智能,一站式知识管理的技术奇迹
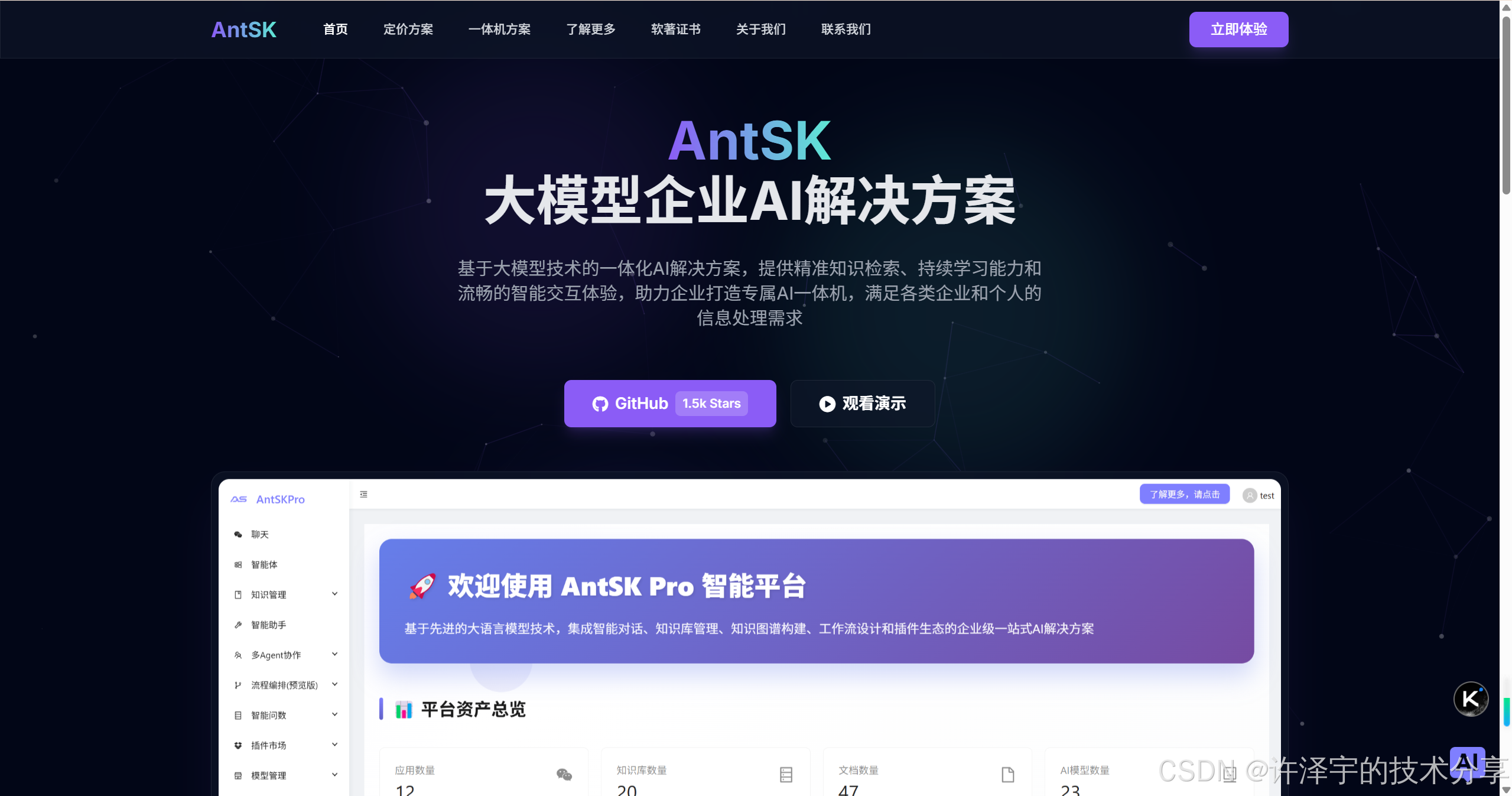
"知识就是力量,而如何高效地管理和导入知识,则是现代AI系统的核心竞争力。" —— 在这个信息爆炸的时代,AntSK以其独特的多格式导入技术,为我们展示了什么叫做"技术改变世界"。
🎯 引言:当知识遇上技术的火花
想象一下,你面前有一堆杂乱无章的文档:Word文件、PDF报告、Excel表格、音频录音、图片截图...传统的做法是什么?一个个手动整理?复制粘贴?那简直是在用石器时代的工具处理信息时代的问题!
AntSK知识库系统就像是一位"全能管家",不仅能够"消化"各种格式的文档,还能智能地理解、切分、索引这些内容。今天,我们就来深入剖析这个技术奇迹背后的秘密。
🏗️ 架构设计:多格式导入的技术基石
核心设计理念
AntSK的多格式导入系统采用了"统一接口,差异化处理"的设计哲学。就像一个高级餐厅的厨师,无论你给他什么食材,他都能做出美味的菜肴,但处理每种食材的方法却截然不同。
// 统一的导入任务DTO
public class ImportKMSTaskDTO
{public ImportType ImportType { get; set; } // 导入类型public string KmsId { get; set; } // 知识库IDpublic string Text { get; set; } // 文本内容public string FilePath { get; set; } // 文件路径public string FileName { get; set; } // 文件名public bool IsQA { get; set; } // 是否QA切分public string AudioModelId { get; set; } // 音频模型ID
}
这个DTO就像是一张"万能通行证",无论什么类型的内容,都能通过这个统一的接口进入系统。这种设计的巧妙之处在于:
-
统一性:所有导入操作都使用相同的API端点
-
扩展性:新增导入类型只需扩展ImportType枚举
-
灵活性:不同类型的导入可以携带不同的参数
导入类型全景图
AntSK支持的导入类型可以说是"应有尽有":
public enum ImportType
{Text, // 文本导入File, // 文件导入Url, // URL导入Excel, // Excel导入Audio, // 音频导入Media // 媒体导入
}
每种类型都有其独特的处理逻辑,就像不同的"专科医生",各司其职,术业有专攻。
📝 文本导入:最基础却最重要的功能
技术实现分析
文本导入看似简单,实则蕴含着深刻的技术思考。让我们看看AntSK是如何处理的:
private async Task TextHandleOk(MouseEventArgs e)
{try{var result = await _httpService.PostAsync(NavigationManager.BaseUri + "api/KMS/ImportKMSTask", new ImportKMSTaskDTO(){ImportType = ImportType.Text,KmsId = KmsId,Text = textModel.Text,IsQA = textModel.IsQA});await InitData(_searchKey);_textVisible = false;textModel.Text = "";await InvokeAsync(StateHasChanged);_ = _message.Info("加入队列,进入后台处理中!", 2);}catch (Exception ex){Log.Error(ex.Message + " ---- " + ex.StackTrace);}
}
这段代码虽然简洁,但包含了几个重要的设计思想:
-
异步处理:使用async/await确保UI不会被阻塞
-
错误处理:完善的异常捕获和日志记录
-
状态管理:及时更新UI状态和清理临时数据
-
用户反馈:通过消息提示告知用户操作状态
切分模式的智慧
AntSK提供了两种文本切分模式:
1. 直接切分模式
这种模式就像用"菜刀"切菜,简单粗暴但有效:
-
按照固定长度或段落进行切分
-
适合结构化程度较低的文本
-
处理速度快,资源消耗少
2. QA切分模式
这种模式更像是用"手术刀",精准而智能:
-
基于问答对的形式进行切分
-
适合FAQ、知识问答等结构化内容
-
能够更好地保持语义完整性
<Radio RadioButton Value="false">直接切分</Radio>
<Radio RadioButton Value="true">QA切分</Radio>
这种设计让用户可以根据内容特点选择最适合的处理方式,体现了"因材施教"的智慧。
🔗 URL导入:网络内容的智能抓取
技术挑战与解决方案
URL导入功能面临的挑战可不少:
-
网页结构千差万别
-
动态内容加载
-
反爬虫机制
-
内容提取的准确性
AntSK的解决方案体现了工程师的智慧:
private async Task UrlHandleOk(MouseEventArgs e)
{try{var result = await _httpService.PostAsync(NavigationManager.BaseUri + "api/KMS/ImportKMSTask", new ImportKMSTaskDTO(){ImportType = ImportType.Url,KmsId = KmsId,Text = urlModel.Url,IsQA = urlModel.IsQA});// ... 后续处理}catch (Exception ex){Log.Error(ex.Message + " ---- " + ex.StackTrace);}
}
智能内容提取
URL导入的核心在于内容提取算法,虽然我们看不到具体实现,但可以推测其可能采用的技术:
-
DOM解析:使用类似HtmlAgilityPack的库解析HTML结构
-
内容识别:通过启发式算法识别主要内容区域
-
去噪处理:移除广告、导航等无关内容
-
格式标准化:将提取的内容转换为统一格式
📁 文件导入:多格式文档的统一处理
支持格式的广度
AntSK支持的文件格式可谓"包罗万象":
<Upload Name="files" Accept=".txt,.docx,.pdf,.md,.xlsx,.ppt,.jpeg,.jpg,.png,.tiff,.bmp,.gif,.svg,.webp"Multiple="true"ShowUploadList="false"FileList="iKMService.FileList"OnChange="OnFileChange">
这个Accept属性就像是一张"入场券清单",告诉我们AntSK能够处理哪些类型的文件。从文本文档到图片,从表格到演示文稿,几乎涵盖了日常工作中的所有文件类型。
三种处理模式的技术深度
AntSK为文件导入提供了三种处理模式,每种都有其独特的技术特点:
1. 直接切分模式
if (_processingMode == ProcessingMode.Direct)
{// 传统的直接处理方式var result = await _httpService.PostAsync(/* ... */, new ImportKMSTaskDTO(){ImportType = ImportType.File,IsQA = false});
}
2. QA切分模式
if (_processingMode == ProcessingMode.QA)
{// QA格式的智能切分var result = await _httpService.PostAsync(/* ... */, new ImportKMSTaskDTO(){ImportType = ImportType.File,IsQA = true});
}
3. 智能预处理模式(技术亮点)
这是AntSK的技术创新之处:
if (_processingMode == ProcessingMode.SmartPreprocess)
{await ProcessDocumentsWithPreview();
}
智能预处理模式的工作流程:
-
格式检查:验证文件是否支持智能预处理
-
文档转换:将文档转换为Markdown格式
-
智能切分:按照文档结构(如标题)进行切分
-
预览展示:让用户预览处理结果
-
图片解析:可选的OCR或多模态图片解析
-
确认导入:用户确认后正式导入
智能预处理的技术实现
让我们深入看看智能预处理的核心逻辑:
private async Task ProcessDocumentsWithPreview()
{// 检查智能预处理功能是否可用if (!IsSmartPreprocessingAvailable){_ = _message?.Warning("智能预处理功能不可用,请检查服务配置", 3);return;}// 检查文件格式支持if (!_documentConversionService.IsSupportedFormat(firstFile.FileName)){// 回退到传统处理方式// ...}// 文档转换var conversionResult = await _documentConversionService.ConvertToMarkdownAsync(fullFilePath, firstFile.FileName);// 智能切分var chunks = _documentConversionService.SplitMarkdownByHeaders(conversionResult.Markdown, firstFile.FileName);// 创建预处理结果_currentPreprocessResult = new DocumentPreprocessResult{ConversionResult = conversionResult,Chunks = chunks};
}
这段代码展现了几个重要的设计原则:
-
优雅降级:当智能预处理不可用时,自动回退到传统方式
-
格式适配:不同格式的文档使用不同的转换策略
-
结构化处理:按照文档的逻辑结构进行切分
-
用户体验:提供预览功能,让用户掌控处理过程
🎵 音频导入:语音转文本的技术魅力
音频处理的技术挑战
音频导入是AntSK的一个技术亮点,它需要解决几个关键问题:
-
格式兼容性:支持多种音频格式(mp3, wav, m4a, flac, aac, ogg)
-
语音识别准确性:将语音准确转换为文本
-
语言支持:支持多种语言的语音识别
-
噪音处理:处理音频中的背景噪音
private async Task AudioHandleOk(MouseEventArgs e)
{try{foreach (var item in iKMService.FileList){var result = await _httpService.PostAsync(NavigationManager.BaseUri + "api/KMS/ImportKMSTask", new ImportKMSTaskDTO(){ImportType = ImportType.Audio,KmsId = KmsId,FilePath = item.Response,FileName = item.FileName,AudioModelId = km.AudioModelID // 关键:指定音频模型});}// ...}catch (Exception ex){Log.Error(ex.Message + " ---- " + ex.StackTrace);}
}
音频模型的选择策略
注意到代码中的AudioModelId = km.AudioModelID,这表明AntSK支持多种音频识别模型。这种设计的好处是:
-
灵活性:可以根据音频特点选择最适合的模型
-
准确性:不同模型在不同场景下的表现可能差异很大
-
扩展性:可以轻松集成新的音频识别服务
📊 Excel导入:结构化数据的智能处理
QA格式的巧妙设计
Excel导入专门针对QA(问答)格式进行了优化:
private async Task ExcelHandleOk(MouseEventArgs e)
{try{foreach (var item in iKMService.FileList){var result = await _httpService.PostAsync(NavigationManager.BaseUri + "api/KMS/ImportKMSTask", new ImportKMSTaskDTO(){ImportType = ImportType.Excel,KmsId = KmsId,FilePath = item.Response,FileName = item.FileName,IsQA = false // Excel默认不需要QA切分,因为本身就是QA格式});}// ...}catch (Exception ex){Log.Error(ex.Message + " ---- " + ex.StackTrace);}
}
模板化导入的用户体验
前端界面提供了模板下载功能:
<p>请按照QA格式上传Excel文件,<Button Type="@ButtonType.Link" OnClick="DownloadTemplate">点击下载模板</Button>
</p>
这种设计体现了"授人以鱼不如授人以渔"的理念,不仅提供功能,还教会用户如何正确使用。
🖼️ 媒体导入:多模态内容的智能理解
媒体内容的处理策略
媒体导入功能展现了AntSK对多模态内容的理解能力:
private async Task MediaHandleOk(MouseEventArgs e)
{try{var result = await _httpService.PostAsync(NavigationManager.BaseUri + "api/KMS/ImportKMSTask", new ImportKMSTaskDTO(){ImportType = ImportType.Text, // 注意:媒体最终以文本形式存储KmsId = KmsId,Text = mediaModel.Text,IsQA = false});// ...}catch (Exception ex){Log.Error(ex.Message + " ---- " + ex.StackTrace);}
}
有趣的是,媒体导入最终使用的是ImportType.Text,这说明系统将媒体内容转换为了文本描述。这种设计的优势:
-
统一存储:所有内容最终都以文本形式存储和检索
-
语义理解:通过文本描述,AI可以更好地理解媒体内容
-
检索效率:文本检索比多媒体检索更高效
🧠 智能预处理:技术创新的集大成者
图片解析的双重策略
AntSK的智能预处理功能提供了两种图片解析方式:
1. OCR解析
if (parsingType == ImageParsingType.OCR && !_imageParsingService.IsOCRAvailable)
{_ = _message.Warning("OCR功能不可用,请检查服务配置", 3);return;
}
2. 多模态解析
if (parsingType == ImageParsingType.Multimodal && !_imageParsingService.IsMultimodalAvailable)
{_ = _message.Warning("多模态功能不可用,请检查服务配置", 3);return;
}
这种双重策略的设计思路:
-
OCR解析:适合文字密集的图片,如扫描文档、截图等
-
多模态解析:适合复杂图片,如图表、照片等,能够理解图片的语义内容
预处理流程的用户体验设计
private async Task ConfirmImportPreprocessedDocument()
{if (_currentPreprocessResult == null || !_currentPreprocessResult.CanImport){_ = _message.Warning("没有可导入的内容", 2);return;}// 确定要导入的内容:如果进行了图片解析,使用解析后的内容,否则使用原始内容var contentToImport = !string.IsNullOrEmpty(_currentPreprocessResult.ProcessedMarkdown)? _currentPreprocessResult.ProcessedMarkdown: _currentPreprocessResult.ConversionResult.Markdown;// 以Text类型导入var result = await _httpService.PostAsync(/* ... */, new ImportKMSTaskDTO(){ImportType = ImportType.Text,KmsId = KmsId,Text = contentToImport,IsQA = false // 已经按标题切分,不再需要QA处理});
}
这段代码体现了几个重要的设计思想:
-
智能选择:自动选择最优的内容版本
-
状态检查:确保只有可导入的内容才能被导入
-
处理优化:已经智能切分的内容不再需要额外的QA处理
🔄 异步处理与状态管理:用户体验的技术保障
异步处理的设计哲学
AntSK的所有导入操作都采用了异步处理模式,这不是偶然的技术选择,而是深思熟虑的设计决策:
// 每个导入操作都会显示这样的消息
_ = _message.Info("加入队列,进入后台处理中!", 2);
这种设计的好处:
-
响应性:UI永远不会被阻塞
-
可扩展性:可以处理大量并发导入请求
-
容错性:单个导入失败不会影响其他操作
-
用户体验:用户可以继续进行其他操作
状态管理的精妙设计
// 状态更新的标准模式
await InitData(_searchKey); // 刷新数据
_fileVisible = false; // 关闭对话框
iKMService.FileList.Clear(); // 清理临时数据
await InvokeAsync(StateHasChanged); // 强制重新渲染
这四行代码看似简单,实则包含了状态管理的精髓:
-
数据同步:确保显示的数据是最新的
-
界面控制:及时关闭不需要的界面元素
-
内存管理:清理不再需要的临时数据
-
视图更新:强制Blazor重新渲染组件
🛡️ 错误处理与日志记录:系统稳定性的基石
统一的错误处理模式
AntSK采用了统一的错误处理模式:
try
{// 业务逻辑
}
catch (Exception ex)
{Log.Error(ex.Message + " ---- " + ex.StackTrace);_ = _message.Error($"操作失败: {ex.Message}", 5);
}
finally
{// 清理工作_isLoading = false;StateHasChanged();
}
这种模式的优势:
-
完整性:捕获所有可能的异常
-
可追踪性:详细的日志记录便于问题定位
-
用户友好:向用户显示友好的错误信息
-
资源管理:确保资源得到正确释放
日志记录的技术细节
Log.Error(ex.Message + " ---- " + ex.StackTrace);
这行代码虽然简单,但体现了日志记录的最佳实践:
-
错误信息:记录具体的错误描述
-
调用栈:记录完整的调用栈,便于定位问题
-
分隔符:使用统一的分隔符便于日志解析
🎨 用户界面设计:技术与美学的完美结合
模态框的设计哲学
AntSK使用了大量的模态框来组织不同的导入功能:
<Modal Title="文本导入" Visible="_textVisible" OnOk="TextHandleOk" OnCancel="TextHandleCancel"ConfirmLoading="_textConfirmLoading"><!-- 内容 -->
</Modal>
这种设计的优势:
-
功能隔离:每种导入方式都有独立的界面
-
空间利用:不会让主界面过于拥挤
-
用户引导:模态框能够引导用户完成特定操作
-
状态管理:每个模态框都有独立的状态
响应式设计的考虑
<Row Gutter="16"><Col Span="12"><!-- 左侧内容 --></Col><Col Span="12"><!-- 右侧内容 --></Col>
</Row>
AntSK使用了Ant Design的栅格系统,确保界面在不同屏幕尺寸下都能良好显示。
🚀 性能优化:大规模数据处理的技术挑战
文件上传的优化策略
<Upload Name="files" Multiple="true"ShowUploadList="false"FileList="iKMService.FileList"OnChange="OnFileChange">
这里的几个关键配置:
-
**Multiple="true"**:支持批量上传,提高效率
-
**ShowUploadList="false"**:隐藏默认的文件列表,使用自定义界面
-
FileList绑定:使用服务管理文件列表,便于状态共享
内存管理的细节
iKMService.FileList.Clear(); // 及时清理文件列表
_currentPreprocessResult = null; // 清理预处理结果
这些看似简单的清理操作,实际上对系统性能有重要影响:
-
防止内存泄漏
-
减少垃圾回收压力
-
提高系统响应速度
🔮 技术趋势与未来展望
当前技术栈的优势
AntSK的技术选择体现了对现代Web开发趋势的准确把握:
-
Blazor框架:微软的全栈C#解决方案,统一前后端开发语言
-
Ant Design Blazor:成熟的UI组件库,提供一致的用户体验
-
异步编程:充分利用.NET的异步特性,提高系统性能
-
依赖注入:现代化的架构设计,提高代码的可测试性和可维护性
未来可能的技术演进
基于当前的技术架构,AntSK未来可能在以下方面进行演进:
1. AI能力的深度集成
-
更智能的内容理解:集成更先进的NLP模型
-
自动化标签生成:基于内容自动生成标签和分类
-
智能推荐:基于用户行为推荐相关内容
2. 多模态处理能力的增强
-
视频内容解析:提取视频中的关键信息
-
音频情感分析:分析音频中的情感色彩
-
图表智能识别:自动识别和解析各种图表
3. 分布式处理架构
-
微服务化:将不同的导入功能拆分为独立的微服务
-
容器化部署:使用Docker等容器技术提高部署效率
-
云原生架构:充分利用云计算的弹性和可扩展性
4. 实时协作功能
-
多用户协作:支持多用户同时编辑和管理知识库
-
版本控制:提供类似Git的版本管理功能
-
实时同步:使用SignalR等技术实现实时数据同步
💡 最佳实践与开发建议
代码组织的最佳实践
从AntSK的代码结构中,我们可以学到几个重要的最佳实践:
1. 职责分离
// 每个导入类型都有独立的处理方法
private async Task TextHandleOk(MouseEventArgs e) { /* ... */ }
private async Task FileHandleOk(MouseEventArgs e) { /* ... */ }
private async Task AudioHandleOk(MouseEventArgs e) { /* ... */ }
2. 统一的错误处理
// 所有方法都使用相同的错误处理模式
try { /* 业务逻辑 */ }
catch (Exception ex) { Log.Error(/* ... */); }
3. 状态管理的一致性
// 统一的状态更新模式
await InitData(_searchKey);
_modalVisible = false;
fileList.Clear();
await InvokeAsync(StateHasChanged);
性能优化建议
1. 异步操作的正确使用
// 正确:使用ConfigureAwait(false)避免死锁
var result = await _httpService.PostAsync(/* ... */).ConfigureAwait(false);// 正确:批量操作使用Task.WhenAll
var tasks = fileList.Select(file => ProcessFileAsync(file));
await Task.WhenAll(tasks);
2. 内存管理
// 及时释放大对象
using var stream = new MemoryStream(largeData);
// 使用完毕后自动释放
3. 缓存策略
// 对频繁访问的数据进行缓存
if (_cache.TryGetValue(key, out var cachedValue))return cachedValue;
用户体验优化建议
1. 加载状态的管理
// 显示加载状态
_isLoading = true;
StateHasChanged();try
{// 执行操作
}
finally
{_isLoading = false;StateHasChanged();
}
2. 错误信息的友好化
// 向用户显示友好的错误信息
_ = _message.Error($"文件上传失败,请检查文件格式是否正确", 5);
3. 操作反馈的及时性
// 及时给用户反馈
_ = _message.Info("文件正在处理中,请稍候...", 2);
🎯 实际应用场景分析
企业知识管理场景
在企业环境中,AntSK的多格式导入功能可以应用于:
1. 文档数字化
-
历史文档迁移:将纸质文档扫描后通过OCR导入
-
多格式整合:统一管理Word、PDF、Excel等不同格式的文档
-
版本控制:跟踪文档的修改历史
2. 会议记录管理
-
音频转录:将会议录音自动转换为文字记录
-
多媒体整合:结合音频、图片、文档形成完整的会议记录
-
智能摘要:自动生成会议要点和行动项
3. 培训资料管理
-
多媒体课件:整合视频、音频、文档等培训材料
-
知识图谱构建:基于导入的内容构建知识关系网络
-
个性化推荐:根据员工角色推荐相关培训内容
教育行业应用
1. 教学资源整合
-
课件管理:统一管理PPT、PDF、视频等教学资源
-
作业批改:通过OCR识别手写作业内容
-
学习轨迹跟踪:记录学生的学习过程和成果
2. 科研文献管理
-
论文导入:批量导入PDF格式的学术论文
-
引用分析:分析文献之间的引用关系
-
知识发现:从大量文献中发现新的研究方向
医疗健康领域
1. 病历管理
-
电子病历:将纸质病历数字化
-
影像报告:整合CT、MRI等影像资料
-
诊疗知识库:构建疾病诊疗知识体系
2. 医学研究
-
临床数据:整合各种格式的临床研究数据
-
文献综述:自动分析和总结医学文献
-
药物信息:管理药物说明书和研究报告
🔧 技术实现的深度剖析
文档转换技术的核心原理
1. PDF解析技术
PDF文档的解析是一个复杂的技术挑战:
// 伪代码:PDF解析的基本流程
public async Task<string> ParsePdfAsync(string filePath)
{using var document = PdfDocument.Open(filePath);var textBuilder = new StringBuilder();foreach (var page in document.GetPages()){// 提取文本内容var text = page.Text;textBuilder.AppendLine(text);// 处理图片内容var images = page.GetImages();foreach (var image in images){var ocrResult = await _ocrService.RecognizeAsync(image);textBuilder.AppendLine(ocrResult);}}return textBuilder.ToString();
}
2. Word文档处理
Word文档的处理需要考虑复杂的格式信息:
// 伪代码:Word文档解析
public async Task<MarkdownResult> ConvertWordToMarkdownAsync(string filePath)
{using var document = WordprocessingDocument.Open(filePath, false);var body = document.MainDocumentPart.Document.Body;var markdownBuilder = new StringBuilder();var images = new List<ImageInfo>();foreach (var element in body.Elements()){switch (element){case Paragraph paragraph:var text = ConvertParagraphToMarkdown(paragraph);markdownBuilder.AppendLine(text);break;case Table table:var tableMarkdown = ConvertTableToMarkdown(table);markdownBuilder.AppendLine(tableMarkdown);break;// 处理其他元素...}}return new MarkdownResult{Markdown = markdownBuilder.ToString(),Images = images};
}
智能切分算法的设计思路
1. 基于标题的层次化切分
public List<DocumentChunk> SplitMarkdownByHeaders(string markdown, string fileName)
{var lines = markdown.Split('\n');var chunks = new List<DocumentChunk>();var currentChunk = new StringBuilder();var currentLevel = 0;var chunkIndex = 0;foreach (var line in lines){if (IsHeader(line)){// 保存当前块if (currentChunk.Length > 0){chunks.Add(new DocumentChunk{Content = currentChunk.ToString(),Index = chunkIndex++,Level = currentLevel,FileName = fileName});currentChunk.Clear();}// 开始新块currentLevel = GetHeaderLevel(line);currentChunk.AppendLine(line);}else{currentChunk.AppendLine(line);}}// 处理最后一个块if (currentChunk.Length > 0){chunks.Add(new DocumentChunk{Content = currentChunk.ToString(),Index = chunkIndex,Level = currentLevel,FileName = fileName});}return chunks;
}
2. 语义相关性切分
public async Task<List<DocumentChunk>> SplitBySemanticAsync(string text)
{var sentences = SplitIntoSentences(text);var embeddings = await GetEmbeddingsAsync(sentences);var chunks = new List<DocumentChunk>();var currentChunk = new List<string>();var currentEmbedding = embeddings[0];for (int i = 1; i < sentences.Count; i++){var similarity = CalculateCosineSimilarity(currentEmbedding, embeddings[i]);if (similarity < SIMILARITY_THRESHOLD){// 相似度低,开始新块chunks.Add(CreateChunk(currentChunk));currentChunk.Clear();currentEmbedding = embeddings[i];}currentChunk.Add(sentences[i]);}return chunks;
}
多模态内容理解技术
1. 图像内容分析
public async Task<ImageAnalysisResult> AnalyzeImageAsync(byte[] imageData, ImageParsingType type)
{switch (type){case ImageParsingType.OCR:return await PerformOCRAsync(imageData);case ImageParsingType.Multimodal:return await PerformMultimodalAnalysisAsync(imageData);default:throw new ArgumentException("Unsupported parsing type");}
}private async Task<ImageAnalysisResult> PerformMultimodalAnalysisAsync(byte[] imageData)
{// 使用多模态AI模型分析图像var prompt = "请描述这张图片的内容,包括主要对象、场景、文字信息等";var response = await _multimodalAI.AnalyzeImageAsync(imageData, prompt);return new ImageAnalysisResult{Description = response.Description,Objects = response.DetectedObjects,Text = response.ExtractedText,Confidence = response.Confidence};
}
2. 音频内容处理
public async Task<AudioTranscriptionResult> TranscribeAudioAsync(string audioFilePath, string modelId)
{// 音频预处理var processedAudio = await PreprocessAudioAsync(audioFilePath);// 语音识别var transcription = await _speechService.TranscribeAsync(processedAudio, modelId);// 后处理var cleanedText = CleanTranscriptionText(transcription.Text);return new AudioTranscriptionResult{Text = cleanedText,Confidence = transcription.Confidence,Duration = transcription.Duration,Language = transcription.DetectedLanguage};
}private async Task<byte[]> PreprocessAudioAsync(string audioFilePath)
{// 音频格式转换// 噪音降低// 音量标准化// 采样率调整return processedAudioData;
}
🎨 用户界面设计的技术细节
响应式布局的实现
@* 使用Ant Design的响应式栅格系统 *@
<Row Gutter="16"><Col Xs="24" Sm="24" Md="12" Lg="8" Xl="6"><Card Title="文本导入" Size="small"><Button Type="primary" OnClick="TextShowModal"><Icon Type="file-text" /> 导入文本</Button></Card></Col><Col Xs="24" Sm="24" Md="12" Lg="8" Xl="6"><Card Title="文件导入" Size="small"><Button Type="primary" OnClick="FileShowModal"><Icon Type="file" /> 导入文件</Button></Card></Col>@* 更多导入选项... *@
</Row>
动态加载状态的管理
<Modal Title="@GetModalTitle()" Visible="_fileVisible" OnOk="FileHandleOk" OnCancel="FileHandleCancel"ConfirmLoading="_fileConfirmLoading"Width="800">@if (_fileConfirmLoading){<div class="loading-container"><Spin Size="large" Tip="正在处理文档..."><div class="loading-content"><Progress Percent="_processingProgress" Status="@(_processingProgress == 100 ? "success" : "active")" /><p>@_processingStatus</p></div></Spin></div>}else{@* 正常的上传界面 *@<Upload Name="files" Accept="@GetAcceptedFileTypes()"Multiple="true"ShowUploadList="false"FileList="iKMService.FileList"OnChange="OnFileChange"><div class="upload-area"><Icon Type="cloud-upload" Style="font-size: 48px; color: #1890ff;" /><p>点击或拖拽文件到此区域上传</p><p class="upload-hint">支持格式:@GetSupportedFormatsText()</p></div></Upload>}
</Modal>
主题定制与样式管理
/* 自定义主题色彩 */
:root {--primary-color: #7F7FFF;--primary-hover: #9F9FFF;--primary-active: #5F5FFF;--background-light: #f9f0ff;--background-alpha: rgba(127, 127, 255, 0.1);
}/* 导入卡片样式 */
.import-card {border-radius: 8px;box-shadow: 0 2px 8px rgba(0, 0, 0, 0.1);transition: all 0.3s ease;background: linear-gradient(135deg, var(--background-light), white);
}.import-card:hover {transform: translateY(-2px);box-shadow: 0 4px 16px rgba(127, 127, 255, 0.2);
}/* 上传区域样式 */
.upload-area {border: 2px dashed var(--primary-color);border-radius: 8px;padding: 40px;text-align: center;background: var(--background-alpha);transition: all 0.3s ease;
}.upload-area:hover {border-color: var(--primary-hover);background: rgba(127, 127, 255, 0.2);
}/* 处理进度样式 */
.processing-progress {padding: 20px;text-align: center;
}.processing-step {display: flex;align-items: center;margin: 10px 0;padding: 10px;border-radius: 6px;background: var(--background-light);
}.processing-step.active {background: var(--background-alpha);border-left: 4px solid var(--primary-color);
}.processing-step.completed {background: rgba(82, 196, 26, 0.1);border-left: 4px solid #52c41a;
}
🔍 性能监控与优化策略
性能指标的监控
public class PerformanceMonitor
{private readonly ILogger<PerformanceMonitor> _logger;private readonly Dictionary<string, PerformanceCounter> _counters;public async Task<T> MonitorAsync<T>(string operationName, Func<Task<T>> operation){var stopwatch = Stopwatch.StartNew();var memoryBefore = GC.GetTotalMemory(false);try{var result = await operation();stopwatch.Stop();var memoryAfter = GC.GetTotalMemory(false);var memoryUsed = memoryAfter - memoryBefore;_logger.LogInformation("Operation {OperationName} completed in {ElapsedMs}ms, Memory used: {MemoryUsed} bytes",operationName, stopwatch.ElapsedMilliseconds, memoryUsed);return result;}catch (Exception ex){stopwatch.Stop();_logger.LogError(ex, "Operation {OperationName} failed after {ElapsedMs}ms",operationName, stopwatch.ElapsedMilliseconds);throw;}}
}
缓存策略的实现
public class DocumentProcessingCache
{private readonly IMemoryCache _memoryCache;private readonly IDistributedCache _distributedCache;public async Task<ProcessingResult> GetOrProcessAsync(string fileHash, Func<Task<ProcessingResult>> processor){// 首先检查内存缓存if (_memoryCache.TryGetValue(fileHash, out ProcessingResult cachedResult)){return cachedResult;}// 检查分布式缓存var distributedResult = await _distributedCache.GetStringAsync(fileHash);if (!string.IsNullOrEmpty(distributedResult)){var result = JsonSerializer.Deserialize<ProcessingResult>(distributedResult);// 回填内存缓存_memoryCache.Set(fileHash, result, TimeSpan.FromMinutes(30));return result;}// 执行实际处理var processedResult = await processor();// 更新缓存_memoryCache.Set(fileHash, processedResult, TimeSpan.FromMinutes(30));await _distributedCache.SetStringAsync(fileHash, JsonSerializer.Serialize(processedResult),new DistributedCacheEntryOptions{AbsoluteExpirationRelativeToNow = TimeSpan.FromHours(24)});return processedResult;}
}
批处理优化
public class BatchProcessor
{private readonly SemaphoreSlim _semaphore;private readonly int _maxConcurrency;public BatchProcessor(int maxConcurrency = 5){_maxConcurrency = maxConcurrency;_semaphore = new SemaphoreSlim(maxConcurrency, maxConcurrency);}public async Task<List<ProcessingResult>> ProcessBatchAsync<T>(IEnumerable<T> items, Func<T, Task<ProcessingResult>> processor){var tasks = items.Select(async item =>{await _semaphore.WaitAsync();try{return await processor(item);}finally{_semaphore.Release();}});return (await Task.WhenAll(tasks)).ToList();}
}
🛠️ 扩展性设计与插件架构
导入处理器的插件化设计
public interface IImportProcessor
{ImportType SupportedType { get; }Task<ProcessingResult> ProcessAsync(ImportRequest request);bool CanProcess(string fileName, string contentType);
}public class TextImportProcessor : IImportProcessor
{public ImportType SupportedType => ImportType.Text;public async Task<ProcessingResult> ProcessAsync(ImportRequest request){// 文本处理逻辑var chunks = await SplitTextAsync(request.Content, request.SplitMode);return new ProcessingResult { Chunks = chunks };}public bool CanProcess(string fileName, string contentType){return contentType.StartsWith("text/") || Path.GetExtension(fileName).ToLower() == ".txt";}
}public class AudioImportProcessor : IImportProcessor
{private readonly ISpeechToTextService _speechService;public ImportType SupportedType => ImportType.Audio;public async Task<ProcessingResult> ProcessAsync(ImportRequest request){// 音频处理逻辑var transcription = await _speechService.TranscribeAsync(request.FilePath);var chunks = await SplitTextAsync(transcription.Text, SplitMode.Semantic);return new ProcessingResult { Chunks = chunks };}public bool CanProcess(string fileName, string contentType){var audioExtensions = new[] { ".mp3", ".wav", ".m4a", ".flac", ".aac", ".ogg" };return audioExtensions.Contains(Path.GetExtension(fileName).ToLower());}
}
处理器工厂的实现
public class ImportProcessorFactory
{private readonly IEnumerable<IImportProcessor> _processors;public ImportProcessorFactory(IEnumerable<IImportProcessor> processors){_processors = processors;}public IImportProcessor GetProcessor(ImportType type){return _processors.FirstOrDefault(p => p.SupportedType == type)?? throw new NotSupportedException($"Import type {type} is not supported");}public IImportProcessor GetProcessorByFile(string fileName, string contentType){return _processors.FirstOrDefault(p => p.CanProcess(fileName, contentType))?? throw new NotSupportedException($"File type {contentType} is not supported");}
}
🔐 安全性考虑与实现
文件上传安全检查
public class FileSecurityValidator
{private readonly HashSet<string> _allowedExtensions;private readonly HashSet<string> _allowedMimeTypes;private readonly long _maxFileSize;public FileSecurityValidator(){_allowedExtensions = new HashSet<string>(StringComparer.OrdinalIgnoreCase){".txt", ".docx", ".pdf", ".md", ".xlsx", ".ppt",".jpeg", ".jpg", ".png", ".tiff", ".bmp", ".gif", ".svg", ".webp",".mp3", ".wav", ".m4a", ".flac", ".aac", ".ogg"};_maxFileSize = 100 * 1024 * 1024; // 100MB}public async Task<ValidationResult> ValidateAsync(IFormFile file){var result = new ValidationResult();// 检查文件扩展名var extension = Path.GetExtension(file.FileName);if (!_allowedExtensions.Contains(extension)){result.AddError($"File extension {extension} is not allowed");}// 检查文件大小if (file.Length > _maxFileSize){result.AddError($"File size {file.Length} exceeds maximum allowed size {_maxFileSize}");}// 检查MIME类型if (!IsAllowedMimeType(file.ContentType)){result.AddError($"MIME type {file.ContentType} is not allowed");}// 病毒扫描(如果配置了)if (_antiVirusService != null){var scanResult = await _antiVirusService.ScanAsync(file.OpenReadStream());if (!scanResult.IsClean){result.AddError("File failed virus scan");}}return result;}
}
内容安全过滤
public class ContentSecurityFilter
{private readonly List<string> _bannedKeywords;private readonly Regex _sensitiveDataPattern;public ContentSecurityFilter(){_bannedKeywords = LoadBannedKeywords();_sensitiveDataPattern = new Regex(@"\b(?:\d{4}[\s-]?\d{4}[\s-]?\d{4}[\s-]?\d{4}|\d{3}-\d{2}-\d{4})\b", RegexOptions.Compiled | RegexOptions.IgnoreCase);}public FilterResult FilterContent(string content){var result = new FilterResult { OriginalContent = content };// 检查敏感词汇foreach (var keyword in _bannedKeywords){if (content.Contains(keyword, StringComparison.OrdinalIgnoreCase)){result.AddWarning($"Content contains banned keyword: {keyword}");content = content.Replace(keyword, "[FILTERED]", StringComparison.OrdinalIgnoreCase);}}// 检查敏感数据(如信用卡号、社会安全号等)var matches = _sensitiveDataPattern.Matches(content);foreach (Match match in matches){result.AddWarning($"Potential sensitive data detected: {match.Value.Substring(0, 4)}***");content = content.Replace(match.Value, "[REDACTED]");}result.FilteredContent = content;return result;}
}
📊 数据分析与洞察
导入统计分析
public class ImportAnalytics
{private readonly ILogger<ImportAnalytics> _logger;private readonly IMetricsCollector _metricsCollector;public async Task<ImportStatistics> GetImportStatisticsAsync(DateTime startDate, DateTime endDate){var statistics = new ImportStatistics();// 按类型统计导入数量statistics.ImportsByType = await GetImportCountByTypeAsync(startDate, endDate);// 成功率统计statistics.SuccessRate = await GetSuccessRateAsync(startDate, endDate);// 处理时间统计statistics.AverageProcessingTime = await GetAverageProcessingTimeAsync(startDate, endDate);// 文件大小分布statistics.FileSizeDistribution = await GetFileSizeDistributionAsync(startDate, endDate);return statistics;}public async Task TrackImportEventAsync(ImportEvent importEvent){_metricsCollector.Counter("imports_total").WithTag("type", importEvent.ImportType.ToString()).WithTag("status", importEvent.Status.ToString()).Increment();_metricsCollector.Histogram("import_processing_duration_seconds").WithTag("type", importEvent.ImportType.ToString()).Observe(importEvent.ProcessingDuration.TotalSeconds);_metricsCollector.Histogram("import_file_size_bytes").WithTag("type", importEvent.ImportType.ToString()).Observe(importEvent.FileSizeBytes);}
}
用户行为分析
public class UserBehaviorAnalyzer
{public async Task<UserInsights> AnalyzeUserBehaviorAsync(string userId, TimeSpan period){var insights = new UserInsights();// 最常用的导入类型insights.PreferredImportTypes = await GetPreferredImportTypesAsync(userId, period);// 导入频率模式insights.ImportFrequencyPattern = await GetImportFrequencyPatternAsync(userId, period);// 文件类型偏好insights.FileTypePreferences = await GetFileTypePreferencesAsync(userId, period);// 处理模式偏好insights.ProcessingModePreferences = await GetProcessingModePreferencesAsync(userId, period);return insights;}
}
🚀 部署与运维最佳实践
容器化部署配置
# Dockerfile for AntSK Knowledge Base
FROM mcr.microsoft.com/dotnet/aspnet:8.0 AS base
WORKDIR /app
EXPOSE 80
EXPOSE 443# 安装必要的系统依赖
RUN apt-get update && apt-get install -y \libgdiplus \libc6-dev \libx11-dev \&& rm -rf /var/lib/apt/lists/*FROM mcr.microsoft.com/dotnet/sdk:8.0 AS build
WORKDIR /src
COPY ["AntSK.csproj", "."]
RUN dotnet restore "AntSK.csproj"
COPY . .
WORKDIR "/src/."
RUN dotnet build "AntSK.csproj" -c Release -o /app/buildFROM build AS publish
RUN dotnet publish "AntSK.csproj" -c Release -o /app/publishFROM base AS final
WORKDIR /app
COPY --from=publish /app/publish .# 创建上传目录
RUN mkdir -p /app/wwwroot/uploads && chmod 755 /app/wwwroot/uploads# 设置环境变量
ENV ASPNETCORE_ENVIRONMENT=Production
ENV ASPNETCORE_URLS=http://+:80ENTRYPOINT ["dotnet", "AntSK.dll"]
Kubernetes部署配置
apiVersion: apps/v1
kind: Deployment
metadata:name: antsk-knowledge-baselabels:app: antsk-kb
spec:replicas: 3selector:matchLabels:app: antsk-kbtemplate:metadata:labels:app: antsk-kbspec:containers:- name: antsk-kbimage: antsk/knowledge-base:latestports:- containerPort: 80env:- name: ConnectionStrings__DefaultConnectionvalueFrom:secretKeyRef:name: antsk-secretskey: database-connection- name: OpenAI__ApiKeyvalueFrom:secretKeyRef:name: antsk-secretskey: openai-api-keyresources:requests:memory: "512Mi"cpu: "250m"limits:memory: "2Gi"cpu: "1000m"volumeMounts:- name: upload-storagemountPath: /app/wwwroot/uploadslivenessProbe:httpGet:path: /healthport: 80initialDelaySeconds: 30periodSeconds: 10readinessProbe:httpGet:path: /health/readyport: 80initialDelaySeconds: 5periodSeconds: 5volumes:- name: upload-storagepersistentVolumeClaim:claimName: antsk-upload-pvc
监控与告警配置
# Prometheus监控配置
apiVersion: v1
kind: ConfigMap
metadata:name: prometheus-config
data:prometheus.yml: |global:scrape_interval: 15sscrape_configs:- job_name: 'antsk-knowledge-base'static_configs:- targets: ['antsk-kb-service:80']metrics_path: '/metrics'scrape_interval: 10srule_files:- "antsk_alerts.yml"alerting:alertmanagers:- static_configs:- targets: ['alertmanager:9093']antsk_alerts.yml: |groups:- name: antsk_alertsrules:- alert: HighImportFailureRateexpr: rate(imports_total{status="failed"}[5m]) / rate(imports_total[5m]) > 0.1for: 2mlabels:severity: warningannotations:summary: "High import failure rate detected"description: "Import failure rate is {{ $value | humanizePercentage }} over the last 5 minutes"- alert: LongProcessingTimeexpr: histogram_quantile(0.95, rate(import_processing_duration_seconds_bucket[5m])) > 300for: 5mlabels:severity: criticalannotations:summary: "Import processing time is too long"description: "95th percentile processing time is {{ $value }}s"
🔧 故障排查与问题解决
常见问题诊断
1. 文件上传失败
public class FileUploadDiagnostics
{public async Task<DiagnosticResult> DiagnoseUploadIssueAsync(string fileName, long fileSize, string contentType){var result = new DiagnosticResult();// 检查文件大小限制if (fileSize > _maxFileSize){result.AddIssue("File size exceeds limit", $"File size: {fileSize}, Limit: {_maxFileSize}");}// 检查磁盘空间var availableSpace = GetAvailableDiskSpace();if (availableSpace < fileSize * 2) // 需要2倍空间用于处理{result.AddIssue("Insufficient disk space", $"Available: {availableSpace}, Required: {fileSize * 2}");}// 检查文件格式支持if (!IsFormatSupported(fileName, contentType)){result.AddIssue("Unsupported file format", $"File: {fileName}, ContentType: {contentType}");}return result;}
}
2. 处理性能问题
public class PerformanceDiagnostics
{public async Task<PerformanceReport> GeneratePerformanceReportAsync(){var report = new PerformanceReport();// CPU使用率report.CpuUsage = await GetCpuUsageAsync();// 内存使用情况report.MemoryUsage = GC.GetTotalMemory(false);report.Gen0Collections = GC.CollectionCount(0);report.Gen1Collections = GC.CollectionCount(1);report.Gen2Collections = GC.CollectionCount(2);// 线程池状态ThreadPool.GetAvailableThreads(out int workerThreads, out int completionPortThreads);report.AvailableWorkerThreads = workerThreads;report.AvailableCompletionPortThreads = completionPortThreads;// 队列长度report.ImportQueueLength = await GetImportQueueLengthAsync();return report;}
}
日志分析工具
public class LogAnalyzer
{public async Task<LogAnalysisResult> AnalyzeLogsAsync(DateTime startTime, DateTime endTime){var result = new LogAnalysisResult();// 错误统计result.ErrorCounts = await CountErrorsByTypeAsync(startTime, endTime);// 性能趋势result.PerformanceTrends = await GetPerformanceTrendsAsync(startTime, endTime);// 异常模式识别result.AnomalyPatterns = await DetectAnomalyPatternsAsync(startTime, endTime);return result;}private async Task<Dictionary<string, int>> CountErrorsByTypeAsync(DateTime start, DateTime end){// 分析日志文件,统计不同类型的错误var errorCounts = new Dictionary<string, int>();// 实现日志解析逻辑// ...return errorCounts;}
}
🎯 总结与展望
通过对AntSK知识库多格式导入功能的深度技术解析,我们可以看到这个系统在设计和实现上的诸多亮点:
技术创新点
-
统一接口设计:通过ImportKMSTaskDTO实现了不同导入类型的统一处理
-
智能预处理:创新性的文档预处理和预览功能
-
多模态支持:集成OCR和多模态AI,实现图片内容的智能理解
-
异步处理架构:确保系统的高并发处理能力
-
插件化扩展:为未来功能扩展提供了良好的架构基础
用户体验优化
-
直观的界面设计:清晰的功能分类和操作流程
-
实时状态反馈:及时的处理状态和进度提示
-
错误处理机制:友好的错误提示和恢复建议
-
批量处理支持:提高大量文档处理的效率
系统架构优势
-
高可扩展性:模块化设计便于功能扩展
-
高可用性:完善的错误处理和恢复机制
-
高性能:异步处理和缓存策略的合理运用
-
高安全性:多层次的安全检查和内容过滤
未来发展方向
随着AI技术的不断发展,AntSK知识库系统在未来可能会在以下方面进行演进:
-
更智能的内容理解:集成更先进的大语言模型,提供更准确的内容解析和理解
-
实时协作功能:支持多用户实时协作编辑和管理知识库
-
知识图谱构建:自动构建知识之间的关联关系,形成知识网络
-
个性化推荐:基于用户行为和偏好,提供个性化的内容推荐
-
跨语言支持:支持多语言内容的导入和智能翻译
🎪 互动环节:让我们一起探讨
看完这篇技术深度解析,相信你对AntSK的多格式导入功能有了全新的认识。现在,让我们来一场技术讨论吧!
💭 思考题
-
架构设计:如果让你设计一个类似的多格式导入系统,你会采用什么样的架构模式?为什么?
-
性能优化:在处理大量文档导入时,你认为最关键的性能瓶颈在哪里?有什么优化建议?
-
用户体验:你觉得当前的导入流程还有哪些可以改进的地方?如何让用户操作更加便捷?
-
技术选型:对于不同类型的文档处理(如PDF解析、音频转录等),你会选择什么技术栈?
-
安全考虑:在企业环境中部署这样的系统,你认为还需要考虑哪些安全因素?
🚀 挑战任务
如果你是AntSK的开发者,现在需要添加一个新的导入类型——"视频导入",你会如何设计和实现这个功能?请考虑以下几个方面:
-
视频内容的提取策略(字幕、音频、关键帧等)
-
用户界面的设计
-
处理流程的优化
-
可能遇到的技术挑战
💬 分享你的观点
欢迎在评论区分享你的想法和经验:
-
你在项目中是如何处理多格式文档导入的?
-
遇到过哪些有趣的技术挑战?
-
对AntSK的功能有什么改进建议?
-
想要了解哪些相关的技术细节?
🎁 彩蛋
如果你仔细阅读了整篇文章,一定注意到了文中提到的一个有趣的设计细节:媒体导入最终使用的是ImportType.Text。这个设计背后的深层思考是什么?欢迎在评论区说出你的理解!
作者寄语:技术的魅力不仅在于解决问题,更在于创造可能。AntSK知识库系统展现了现代软件工程在AI时代的无限潜力。希望这篇文章能够激发你对技术的思考,也期待与你在技术探索的路上相遇。
如果这篇文章对你有帮助,请不要忘记点赞、收藏和分享。让更多的技术爱好者一起感受代码的艺术之美!
更多AIGC文章