从“Where”到“Where + What”:语义多目标跟踪(SMOT)全面解读

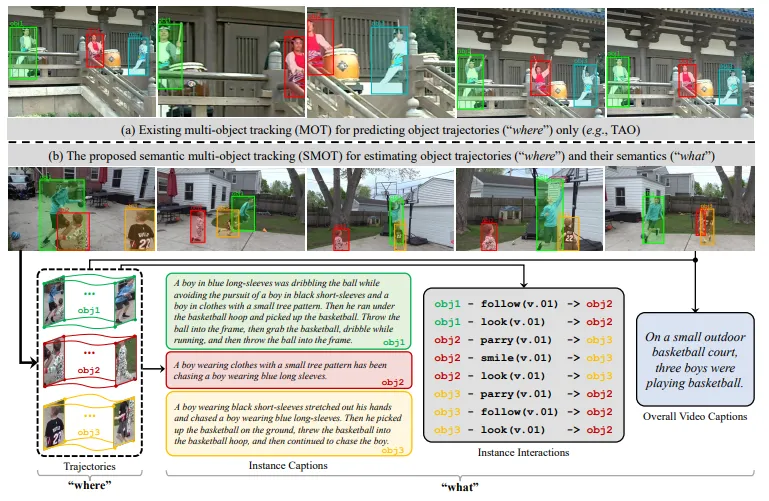
在自动驾驶、机器人、视频监控等场景中,多目标跟踪(Multi-Object Tracking,MOT)是一项基础且关键的技术。传统的MOT主要回答的是一个问题:“目标在哪里?”——也就是预测视频中多个目标的运动轨迹。
但问题来了:仅仅知道“人或物体在某个位置”远远不够。
比如监控场景中,除了要知道“人走到哪里”,我们更希望知道“他是在交谈、奔跑还是打架”。在体育分析中,仅有球员的轨迹信息也不够,我们还想知道他们的动作和相互配合。
因此,中国科学院软件所团队提出了一个新概念:语义多目标跟踪(Semantic Multi-Object Tracking,SMOT)。它不仅能跟踪“目标在哪里”,还能理解“目标在做什么”,真正把“where”和“what”结合起来。
目录
一、什么是语义多目标跟踪(SMOT)?
二、BenSMOT:首个语义多目标跟踪数据集
三、SMOTer:面向SMOT的端到端跟踪器
模型结构
四、实验结果与分析
跟踪性能
编辑
语义理解
消融实验
关键发现
五、未来展望
结语
这个问题非常关键,因为它会导致模型过拟合、预测偏差,并且对那些最重要的类别召回率极低。
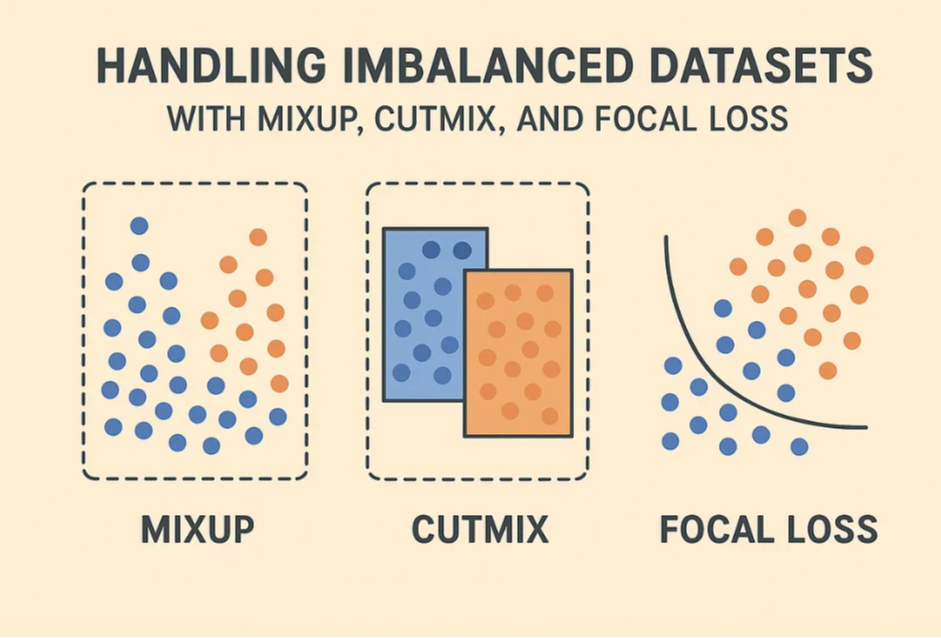
为解决这一挑战,研究者和实践者常常结合使用数据增强和损失函数优化技术。本文将重点介绍三种广泛应用的方法:MixUp、CutMix 和 Focal Loss。它们从不同角度发挥作用,共同构成了一种应对小规模和不平衡数据集的强大策略。
一、什么是语义多目标跟踪(SMOT)?
简单来说,SMOT在传统多目标跟踪的基础上,增加了三项语义理解任务:
-
实例描述(Instance Captioning):用自然语言描述每个目标的行为,比如“一个穿黑色短袖的男孩在追赶穿蓝色长袖的男孩”。
-
交互识别(Instance Interaction Recognition):理解目标之间的关系,比如“obj1跟随obj2”、“obj2传球给obj3”。
-
视频总结(Video Captioning):对整个视频进行整体性描述,比如“在篮球场上,三个男孩正在打篮球”。
这样,SMOT不再只是冷冰冰的坐标点,而是能把运动轨迹和语义信息结合,赋予视频更深层次的理解力。
二、BenSMOT:首个语义多目标跟踪数据集
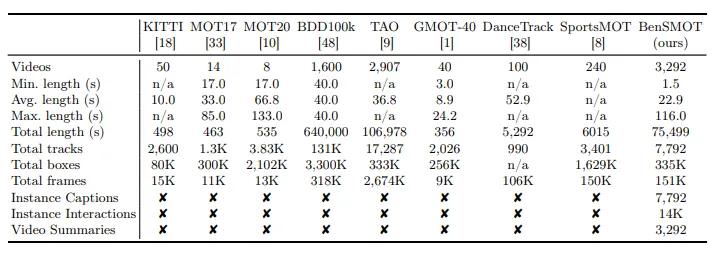
为了推动这一方向的发展,作者们构建了一个全新大规模数据集——BenSMOT。
-
规模:3,292段视频,共15.1万帧
-
场景:覆盖40多种日常生活、运动和互动场景
-
标注:7,800个实例,33.5万个边界框,7,800条实例描述,14,000条交互标注,以及3,292个视频总结
相比以往只提供轨迹的MOT数据集,BenSMOT是第一个同时提供“位置+语义”的公开数据集。
💡如果你也想快速复现类似的语义跟踪任务,Coovally平台已经内置了400+开源数据集,涵盖检测、跟踪、分割等任务,研究者无需额外下载和复杂配置,就能直接调用,节省了大量准备时间。

三、SMOTer:面向SMOT的端到端跟踪器
-
在语义多目标跟踪(SMOT)中,仅仅拼接“检测+跟踪+语义”并不能真正解决问题。传统的“多阶段流水线”往往会导致误差累积:轨迹出错 → 语义描述出错。
为此,研究团队提出了一个全新的端到端模型 —— SMOTer。它的设计逻辑是:一次性学会“跟踪+理解”,让模型在生成轨迹的同时自然学会语义信息。
-
模型结构
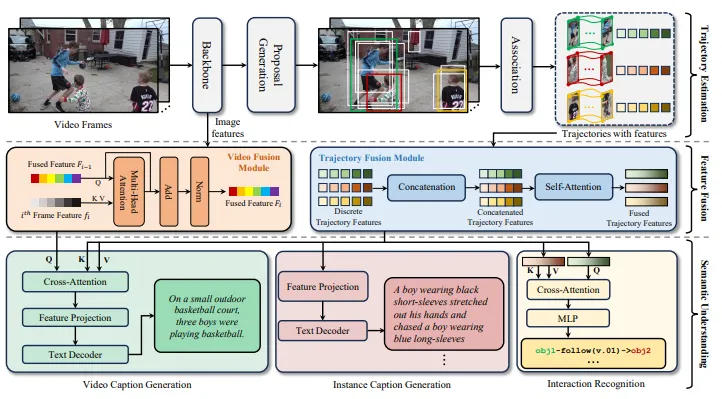
SMOTer整体可以分为三大模块:
-
轨迹估计模块
使用检测器生成候选框,再通过 BYTETrack 算法完成目标关联。
输出每个目标的连续轨迹,同时抽取目标特征。
-
特征融合模块
视频特征融合(Video Fusion Module, VFM):通过跨注意力(Cross-Attention),将帧级特征整合成视频级全局特征。
轨迹特征融合(Trajectory Fusion Module, TFM):将同一目标在不同时刻的特征拼接,再用自注意力增强,得到高质量的轨迹表示。
-
语义理解模块
实例描述:基于轨迹特征,生成自然语言描述。
交互识别:判断目标之间的交互关系,输出 <主语, 动作, 宾语>。
视频总结:结合轨迹与视频全局特征,生成场景级文字描述。
这种设计的好处是:
-
跟踪与语义任务共享特征,避免“任务割裂”;
-
端到端训练时,语义学习反过来提升跟踪精度。
在Coovally平台上,你也可以一键训练类似的端到端模型训练流程,将目标跟踪与下游行业场景(如无人机监控、体育分析、安防)结合起来,形成完整的智能化解决方案。
四、实验结果与分析
研究团队在 BenSMOT 数据集 上,对 SMOTer 和多种主流MOT方法进行了对比实验,主要从 跟踪性能 和 语义理解能力 两个方面来评估。
-
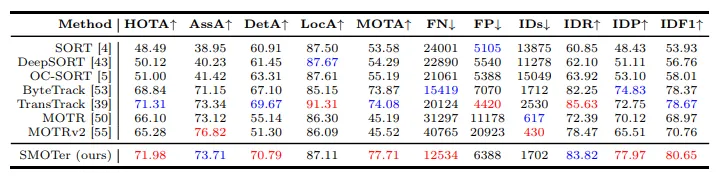
跟踪性能
在传统MOT评价指标上,SMOTer表现非常亮眼:
-
HOTA:71.98%
-
MOTA:77.71%
-
IDF1:80.65%
相比业界广泛使用的ByteTrack(HOTA 68.84%,MOTA 73.87%),SMOTer 提升明显(+3.1% HOTA,+3.7% MOTA)。
更有意思的是,虽然 SMOTer同时承担语义任务,但它的跟踪精度不仅没有下降,反而更高。这说明语义理解任务对目标区分与轨迹预测是有反向促进作用的。
-
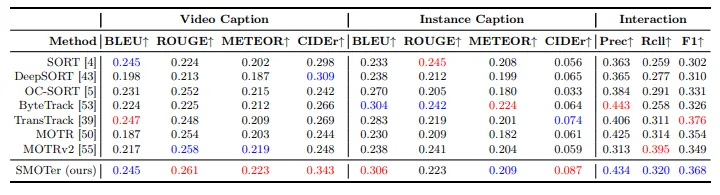
语义理解
除了跟踪,SMOTer在语义任务上也展现了强大能力:
-
视频描述(Video Captioning):CIDEr 提升 +7.7%
-
实例描述(Instance Captioning):CIDEr 提升 +2.3%
-
交互识别(Interaction Recognition):F1 提升 +4.2%
例如,在篮球场场景中,SMOTer不仅能跟踪球员轨迹,还能自动生成这样的描述:
“一个穿黑色短袖的男孩追赶一个穿蓝色长袖的男孩,并在篮筐下投篮。”
而传统MOT方法只能告诉我们:“目标1在坐标x1,y1,目标2在坐标x2,y2”。
-
消融实验
研究团队还进行了多组消融实验,探索不同设计的影响:
-
特征融合策略:
视频级任务(视频描述)中,注意力机制效果最好。
轨迹级任务(实例描述、交互识别)中,拼接(Concatenation)表现更优。
-
关联方法对比:BYTETrack 在 SMOTer 中的表现最佳,超过 SORT、DeepSORT 等经典方法。
-
阈值参数 τp:在0.3时性能最优,兼顾检测质量与跟踪稳定性。

-
关键发现
-
语义任务提升跟踪性能
SMOTer的实验表明,语义理解并非“额外负担”,反而能帮助模型更好地区分和跟踪目标。
-
复杂行为带来挑战
在 BenSMOT 中,实例描述平均超过35个词,一个目标可能涉及多个动作(如运球、投篮、防守),这对模型理解力提出了更高要求。
-
首次实现端到端语义MOT
以往方法往往分阶段训练,而SMOTer首次实现了统一建模,这为未来的研究提供了新方向。
五、未来展望
语义多目标跟踪的提出,为视频理解开辟了新的方向。未来,它可能在以下领域发挥作用:
-
智慧安防:不仅知道“有人闯入”,还能识别是“闲逛”还是“打架”;
-
体育分析:生成自动化解说词,分析运动员配合;
-
机器人交互:帮助机器人更好地理解人类行为,从而作出合理反应。
结语
从“where”走向“where + what”,让多目标跟踪更接近真实理解;提供首个大规模语义MOT数据集BenSMOT;提出端到端模型SMOTer,验证了语义信息对跟踪的反向促进作用。这无疑会推动多目标跟踪向更智能的方向发展。