Kubernetes: 解构Karpenter NodePool, 云原生时代的弹性节点管理艺术
引言
在Kubernetes集群的日常运维中,节点扩缩容是一个永恒的话题。传统的Cluster Autoscaler(集群自动伸缩器)虽然解决了“有”和“无”的问题,但它通常依赖于预定义的节点组,这意味着我们必须事先规划好实例的规格和类型。当集群中运行着多种类型的工作负载时,这种模式就显得捉襟见肘,常常导致资源浪费或调度延迟。
Karpenter项目(现为CNCF孵化项目)提供了一种全新的思路。它不再管理节点“组”,而是直接与云服务商的计算API交互,根据Pod的实际请求(如CPU、内存、架构、GPU等)动态地、秒级地创建出最合适的节点。而这一切魔法的核心,都围绕着一个名为 NodePool 的自定义资源(CRD)展开。接下来,让我们通过一个实例,深入探索 NodePool 的奥秘。
什么是NodePool?从“管理牛群”到“关心牛排”
在Karpenter的早期版本中,Provisioner CRD扮演着定义节点规则的角色。从 v1beta1 版本开始,NodePool 取代了 Provisioner,带来了更清晰、更强大的语义。
我们可以这样理解:如果说管理传统的节点组像是管理一个“牛群”(Cattle),我们关心的是整个群体的健康和数量;那么使用 NodePool 则更像是直接关心“牛排”(Pets),即每一个被应用所需要的计算资源本身。NodePool 定义了一系列规则和约束,Karpenter则基于这些规则为等待调度的Pod量身定制节点。它是一个模板,一个契约,描述了“可以创建什么样的节点”以及“如何管理这些节点”。
深入解析 NodePool 核心字段
让我们以一个aws eks 提供的 general-purpose NodePool为例,逐一分析其核心配置。
apiVersion: karpenter.sh/v1
kind: NodePool
metadata:name: general-purpose
spec:disruption:budgets:- nodes: 10%consolidateAfter: 30sconsolidationPolicy: WhenEmptyOrUnderutilizedtemplate:metadata: {}spec:expireAfter: 336hnodeClassRef:group: eks.amazonaws.comkind: NodeClassname: defaultrequirements:- key: karpenter.sh/capacity-typeoperator: Invalues:- on-demand- key: eks.amazonaws.com/instance-categoryoperator: Invalues:- c- m- r- key: eks.amazonaws.com/instance-generationoperator: Gtvalues:- "4"- key: kubernetes.io/archoperator: Invalues:- amd64- key: kubernetes.io/osoperator: Invalues:- linuxterminationGracePeriod: 24h0m0s
spec.template:定义节点的“蓝图”
这部分定义了由该 NodePool 创建的所有节点的共同特征,是节点的“基因”模板。
-
nodeClassRef: 这是一个至关重要的字段。它将NodePool的“逻辑”定义与“物理”定义解耦。NodePool负责定义调度约束(如实例类型、架构),而NodeClass(在AWS上是EC2NodeClass) 则负责定义基础设施的细节,例如AMI(镜像)、子网(Subnets)、安全组(Security Groups)、IAM实例配置文件等。这种分离使得我们可以复用基础设施配置,同时为不同应用创建拥有不同调度策略的NodePool。 -
requirements: 这是NodePool最具魔力的部分,它定义了节点选择的约束条件。Karpenter会综合Pod的调度需求和这里的约束,从云服务商成百上千种实例类型中挑选出最经济、最合适的那个。karpenter.sh/capacity-type: 指定容量类型,这里是on-demand(按需实例),也可以是spot(竞价实例)。eks.amazonaws.com/instance-category: 限制实例的家族,c、m、r分别代表计算优化、通用型和内存优化型。eks.amazonaws.com/instance-generation: 限制实例的代数,Gt: "4"表示选择第四代以上的实例,确保使用较新的硬件。kubernetes.io/arch和kubernetes.io/os: 标准的Kubernetes节点标签,用于指定架构和操作系统。
-
expireAfter: 设置节点的生命周期。336h(14天) 意味着节点将在创建14天后被自动标记为过期,并由Karpenter进行轮替。这对于强制执行安全补丁更新或避免配置漂移非常有用。
spec.disruption:优雅的节点生命周期管理
如果说 template 决定了节点的“生”,那么 disruption 就决定了节点的“老、病、死”,以及整个节点池的健康与成本效益。
-
consolidationPolicy: 定义了整合策略。WhenEmptyOrUnderutilized表示当节点为空或资源利用率过低时,Karpenter会主动发起整合。整合意味着Karpenter会尝试用更少、更便宜的节点来替换现有节点,并将Pod迁移过去,从而达到节省成本的目的。另一个可选值为WhenEmpty,即仅在节点完全没有Pod时才进行回收。 -
consolidateAfter: 设置一个“冷静期”。30s表示一个节点被创建后,至少要等待30秒才能被考虑用于整合。这可以防止新节点在Pod还未完全就绪时就被错误地回收。 -
budgets: 中断预算,这是一个非常重要的安全机制。nodes: 10%意味着在任何时间点,Karpenter因为中断操作(如整合、过期、轮转等)而同时影响的节点数量不能超过该NodePool节点总数的10%。这可以有效防止Karpenter的优化行为对集群稳定性造成冲击。
Karpenter工作流:从Pod Pending到Node Ready
为了更直观地理解 NodePool 是如何工作的,我们用一个序列图来展示Karpenter的完整工作流程。
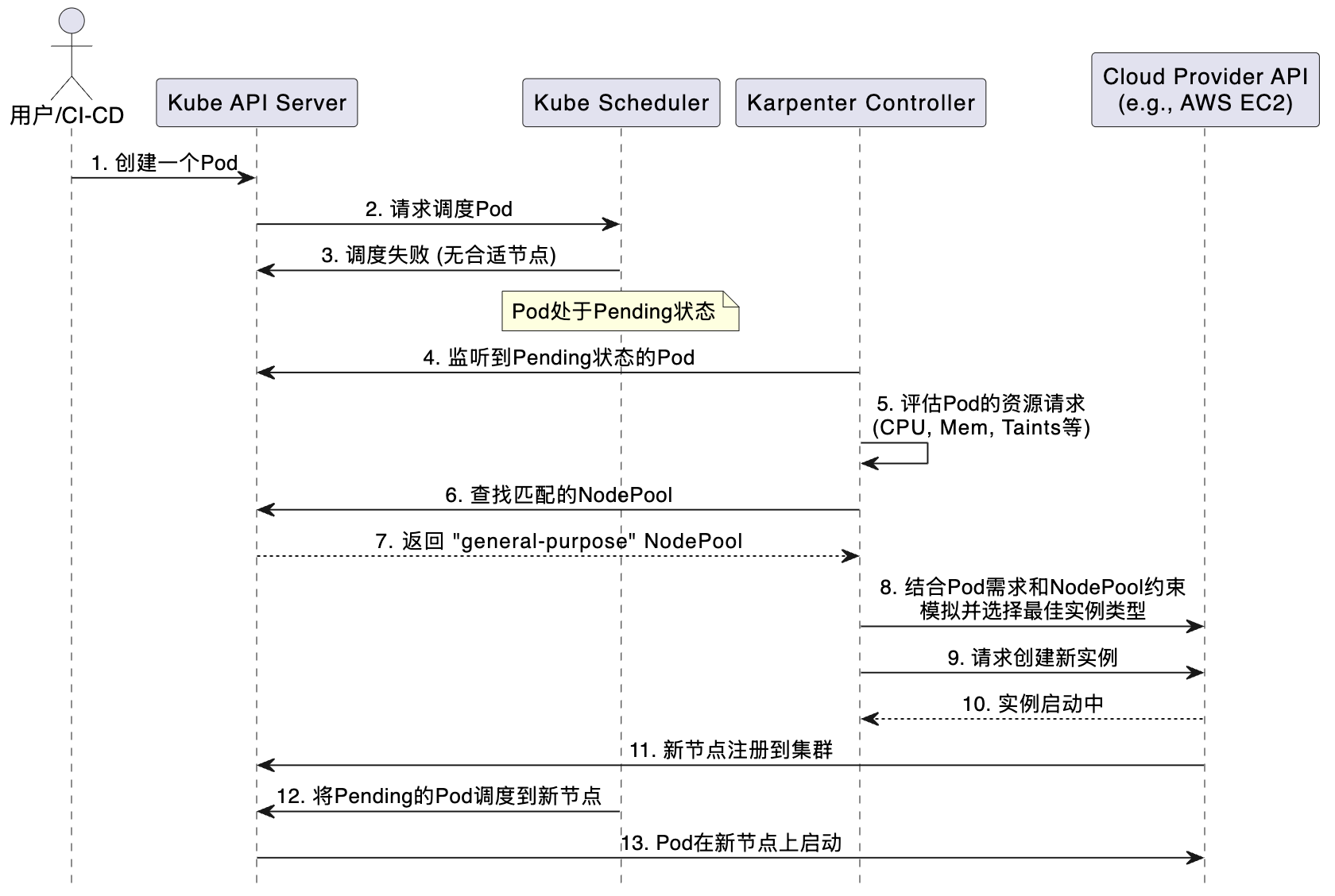
这个流程清晰地展示了Karpenter的自动化和智能化:
- 触发: 核心触发器是一个无法被调度的(Pending)Pod。
- 匹配: Karpenter监听到这个Pod,并根据Pod的标签、容忍度等信息,在集群中寻找一个能满足其
requirements的NodePool。 - 决策: 一旦找到匹配的
NodePool,Karpenter会结合Pod的资源请求(如request.cpu: 8,request.memory: 32Gi)和NodePool的约束(如实例类型、可用区等),向云服务商查询所有可能的实例类型。 - 执行: Karpenter会从中选择一个成本最低且能满足需求的实例类型,然后调用云API来创建这个实例。
- 完成: 新实例启动后,会自动安装kubelet并加入集群,成为一个Ready状态的Node。此时,Kubernetes调度器就能将等待的Pod调度到这个全新的、为其量身定制的节点上。
结论
Karpenter的 NodePool 不仅仅是一个配置项,它代表了一种云原生时代基础设施管理的哲学转变:从被动地管理静态资源池,转向主动地、按需地、精细化地供应计算资源。
通过其强大的 requirements 定义和优雅的 disruption 管理机制,NodePool 赋予了我们前所未有的灵活性和成本控制能力。它使得Kubernetes集群能够像一个真正的“云操作系统”一样,智能地调度和管理底层资源。对于任何希望在Kubernetes上构建高弹性、高性价比应用的技术团队来说,深入理解和掌握Karpenter及其 NodePool 的使用,无疑是一项极具价值的投资。