Redis面试题--介绍下Redis几种集群模式
Redis 主要有三种集群模式:主从复制、哨兵模式、Cluster 模式。它们的关系是逐步演进,解决不同问题的。
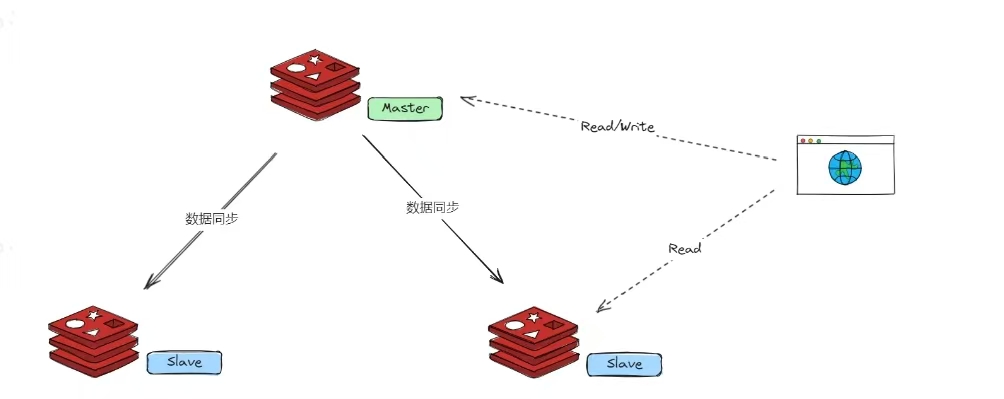
模式一:主从复制 (Master-Slave Replication)
这是最基础、最简单的模式,核心目标是:数据备份 和 读写分离。
适合读多写少的场景。
1. 是什么?
一个 Master 节点(主节点),负责处理所有写操作。
一个或多个 Slave 节点(从节点),负责复制 Master 的数据,并处理读操作。
数据流向是单向的:只能从 Master -> Slave。
2. 工作原理/核心原理
当 Slave 启动后,会向 Master 发起一个
SYNC命令。Master 会执行 BGSAVE,在后台生成一个当前数据的快照(RDB 文件),并将快照期间新的写命令缓存起来。
Master 将 RDB 文件发送给 Slave,Slave 将其加载到内存。
Master 再将缓存的写命令(replication buffer)发送给 Slave,Slave 执行这些命令,从而与 Master 保持数据同步。
之后,Master 的每一个写命令都会异步地发送给所有 Slave,实现持续同步。
3. 优缺点
优点:
读写分离:将读请求分散到多个 Slave,减轻 Master 压力,提升读性能。
数据备份:Slave 是 Master 的完整数据副本,可用于灾难恢复。
缺点:
不具备高可用性:如果 Master 宕机,无法自动切换,需要人工干预将某个 Slave 提升为新的 Master,期间服务会中断。
写操作无法扩展:所有写操作仍然集中在单个 Master 节点。
数据异步复制:Slave 的数据可能比 Master 略旧,存在数据不一致的短暂窗口。
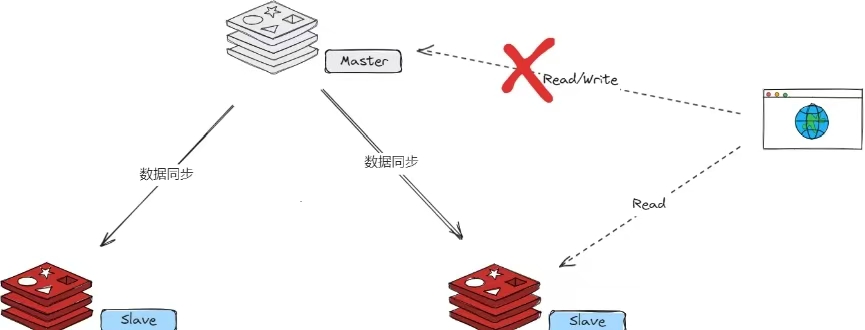
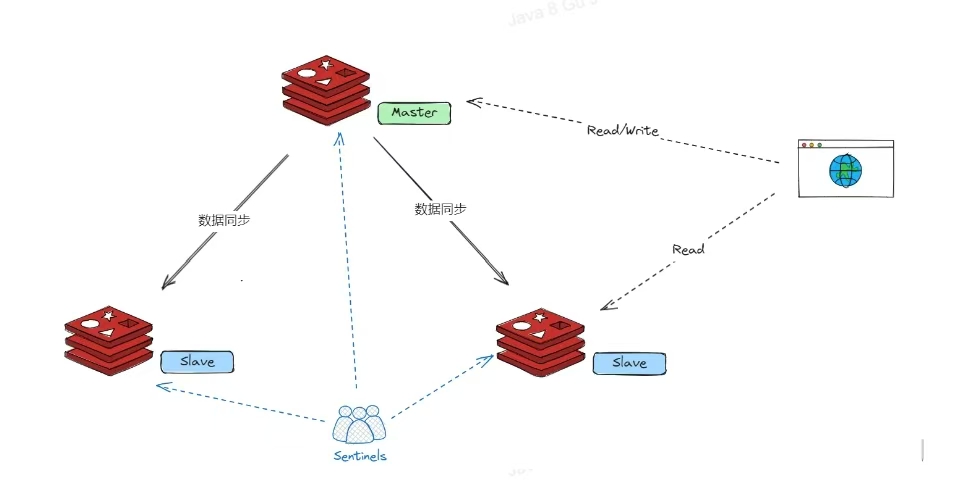
模式二:哨兵模式 (Sentinel)
在主从复制的基础上,哨兵模式解决了 高可用性(High Availability) 问题。
适合读多写少的场景
1. 是什么?
哨兵是一个独立的分布式系统,由多个哨兵实例组成。
哨兵不存储数据,它的核心任务是监控所有 Redis 节点(Master 和 Slave),并在 Master 故障时,自动完成故障转移。
2. 工作原理/核心原理
监控:每个哨兵节点会定期向所有 Redis 节点发送 PING 命令,检查它们是否“存活”。
主观下线和客观下线:
如果一个哨兵发现 Master 无响应,它会将其标记为“主观下线”。
当足够数量的哨兵(需达到 quorum 法定人数)都认为 Master 下线了,则将其标记为“客观下线”。
选举领导者哨兵:哨兵节点会通过 Raft 算法选举出一个领导者哨兵,由它来负责故障转移。
故障转移:领导者哨兵会从 Slave 节点中,根据一定的规则(如优先级、复制偏移量)选出一个最优的,并将其提升为新的 Master,然后让其他 Slave 复制新的 Master。
通知客户端:哨兵会将新的 Master 地址通知给客户端(如 Jedis 等客户端库支持监听哨兵事件)。
3. 优缺点
优点:
高可用性:实现了 Master 故障的自动切换,服务中断时间大大减少。
持续监控:持续监控所有节点健康状态。
缺点:
写操作和存储无法水平扩展:和主从模式一样,写能力和存储容量仍受限于单个 Master 节点。
配置更复杂:需要部署和管理额外的哨兵系统。
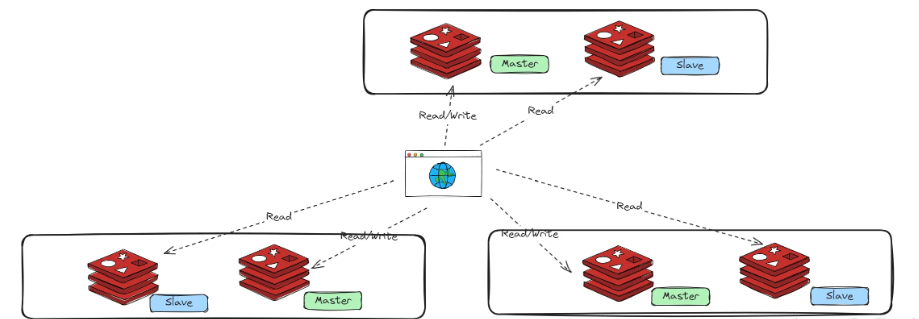
模式三:Cluster 模式 (Redis Cluster)
这是 Redis 官方提供的分布式数据库解决方案,同时解决了高可用性和大数据量、高并发的瓶颈。
1. 是什么?
采用无中心结构,每个节点都与其他节点相连。
数据分片(Sharding) 存储:整个数据集被划分为 16384 个槽(slot),每个节点负责一部分槽。
每个分片都是一个主从复制的单元,保证了每个分片的高可用。
2. 工作原理/核心原理
数据分片:
客户端对某个 key 执行操作时,会先用 CRC16 算法计算其哈希值,再对 16384 取模,得到对应的 slot 编号。
客户端根据“槽位映射表”(存储在每个节点中)找到负责该 slot 的节点,然后直接与其通信。
高可用性:
每个主节点都有至少一个从节点。
如果某个主节点宕机,其从节点会被集群自动提升为主节点,继续提供服务。
gossip 协议:
节点间通过 Gossip 协议进行通信,交换节点状态、槽位映射等信息,最终达成集群状态的一致。
4. 优缺点
优点:
高可用性:内置哨兵机制,自动故障转移。
水平扩展:可以通过增加节点来线性扩展存储容量和读写性能(特别是写性能)。
原生分布式:客户端可直接连接任意节点,节点会智能重定向。
缺点:
架构复杂:部署和维护最复杂。
客户端要求高:客户端需要支持集群协议,能处理重定向(MOVED/ASK)错误。
不支持多数据库:Cluster 模式下只能使用 db0。
事务支持受限:通常只支持同一节点上多个 key 的事务(通过 hash tag 确保 key 在同一 slot)。
总结与选择建议
| 模式 | 核心目标 | 可扩展性 | 高可用性 | 适用场景 |
|---|---|---|---|---|
| 主从复制 | 数据备份、读写分离 | 读扩展 | 无 | 读多写少,对数据丢失不敏感,容灾备份 |
| 哨兵模式 | 高可用、读写分离 | 读扩展 | 有 | 读多写少,要求服务高可用(如缓存) |
| Cluster 模式 | 高可用 + 水平扩展 | 读/写扩展 | 有 | 大数据量、高并发,既要高可用又要写性能扩展(如大型应用核心缓存/存储) |
如何选择?
如果你的数据量不大,主要是读请求,并且可以接受几分钟的故障恢复时间,用 主从 + 哨兵。
如果你需要缓存的数据量很大,或者并发写请求很高,必须采用 Cluster 模式。这是目前生产环境最主流的选择。
单纯的主从复制通常不会单独用于生产环境,而是作为其他模式的基础单元。
Raft算法
一、是什么 — 一句话概括
Raft 是一个用于管理复制日志(Replicated Log)的一致性算法。 它的核心目标是:让一个集群中的多个机器,在部分机器可能故障的情况下,也能对外部表现出像一个整体一样,安全地达成一致决策。
一个简单的比喻:
把它想象成一个民主选举的微型国家。
这个国家必须始终只有一个领导人。
所有法律修改(写操作)都必须由领导人提出,由公民(其他节点)投票通过后才能生效。
如果领导人失踪了(宕机了),公民会重新选举一位新领导人。
Raft 就是这个国家如何选举领导人和如何立法的一套完整宪法。
二、为什么需要它?— 它解决什么问题?
在分布式系统(比如 Redis Sentinel、Etcd、Consul 的集群模式)中,数据通常会在多个节点上有副本,以保证高可用性。
这就带来了一个核心问题:如何保证所有副本上的数据是一致的? 如果客户端向一个节点发送了 set name Kimi,如何确保所有节点都应用了这个操作,而不是有些是 set name Alice?
Raft 就是为了安全、高效地解决这种多副本数据一致性问题而设计的。
三、核心原理:Raft 如何工作?(How?)
Raft 将一致性问题分解为三个相对独立的子问题:
领导人选举:当没有领导人时,选出一个新的。
日志复制:领导人必须接收客户端的请求,并将其复制到集群中的其他节点。
安全性:保证任何节点上的日志状态机都不会执行错误的命令(这是最核心的约束)。
为了管理这些过程,每个 Raft 节点在任何时候都处于以下三种状态之一:
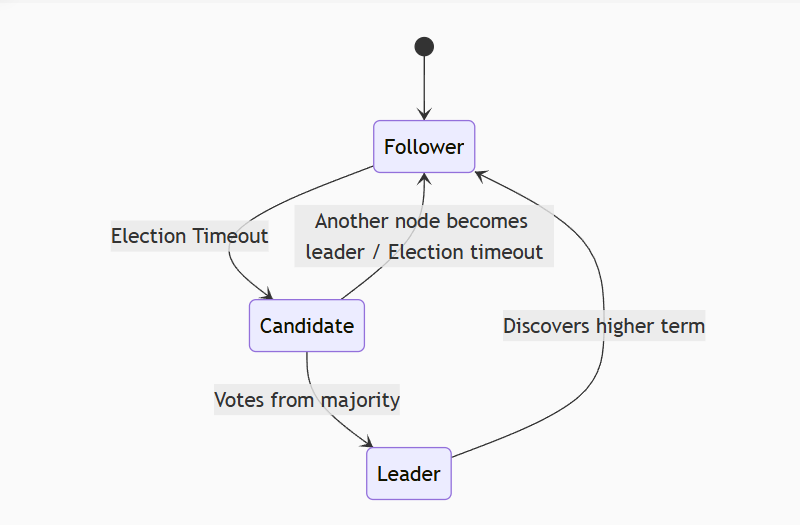
1. 领导人选举
初始状态:所有节点启动时都是 Follower。
心跳与超时:Followers 期望从 Leader 或 Candidate 节点接收心跳(一种特殊的 RPC 消息)。如果一个 Follower 在选举超时时间内没有收到心跳,它就认为Leader挂了,并将自己转变为 Candidate,开始一次新的选举。
发起投票:Candidate 会向其他所有节点发送请求投票的 RPC。
投票规则:每个节点在一个任期内只能投一票(先到先得)。Candidate 需要收到超过半数的选票才能当选为新的 Leader。
新的领导人:一旦当选,新 Leader 就会立即向所有其他节点发送心跳消息,以宣告自己的权威并阻止新的选举。
为什么需要“超过半数”?
这避免了脑裂。在一个由 N 个节点组成的集群中,最多只能有一个 Candidate 获得 N/2 + 1 张选票。这确保了同一时刻最多只有一个 Leader。
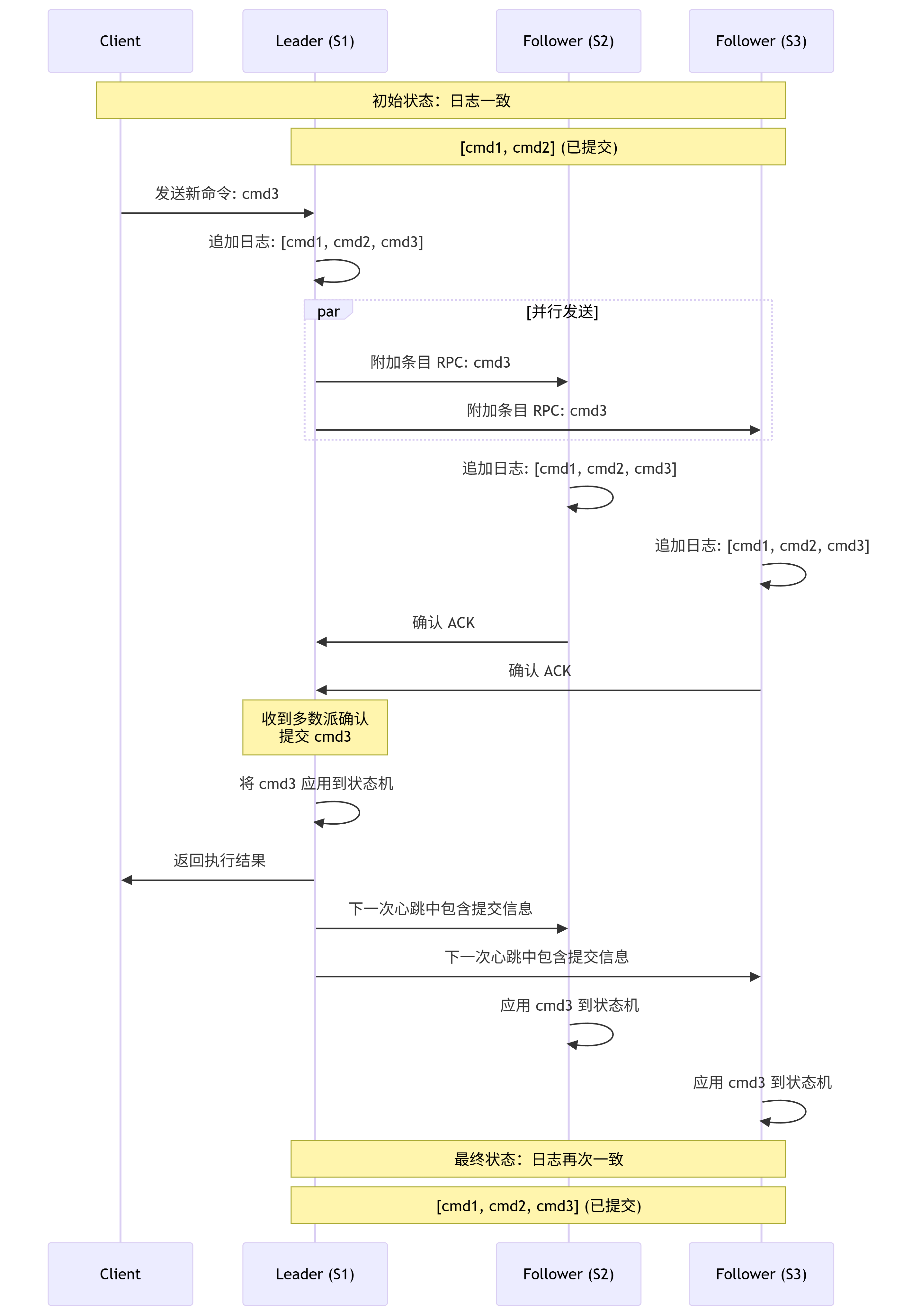
2. 日志复制
现在有了 Leader,它就可以开始处理客户端的请求了。
接收请求:Leader 接收来自客户端的命令(例如
set x 5)。追加日志:Leader 将该命令作为一条新日志条目追加到自己的日志中。
复制日志:Leader 通过 追加条目 RPC,并行地将该日志条目发送给所有其他 Follower。
确认响应:Follower 收到条目后,会将其写入自己的日志文件,然后向 Leader 返回成功确认。
提交应用:当 Leader 收到超过半数的节点的确认后,就认为该日志条目是已提交的。Leader 会应用这条日志到自己的状态机(即执行
set x 5),并将执行结果返回给客户端。通知提交:在后续的心跳中,Leader 会通知所有 Follower 该条目已提交,Follower 随后也将其应用到自己的状态机。
通过这个过程,只要大多数节点是存活的,整个集群就能对外提供一致的服务。
四、一个生动的图示:日志复制过程
假设我们有一个由 3 台服务器组成的 Raft 集群:
五、Raft 的核心特性与优点
强领导者:所有客户端请求都必须由 Leader 处理,日志流向只能是 Leader -> Follower。这简化了逻辑。
领导选举:使用随机化的选举超时来避免投票分裂,确保快速选出新Leader。
成员变更:支持通过联合共识的方式安全地增加或减少集群中的节点数量,而不会破坏集群的可用性。
易于理解:这是 Raft 设计的首要目标。它将问题分解,使得算法比传统的 Paxos 算法更容易被理解和实现。
总结
Raft 是一个“为现实世界设计的算法”。它通过明确的领导权、基于心跳的选举和多数派确认的日志复制机制,以一种相对简单的方式实现了分布式系统中最核心的一致性问题。
你现在使用的很多著名系统都在使用 Raft:
etcd (Kubernetes 的大脑)
Consul (服务发现和配置)
Redis Sentinel 的领导者选举
TiKV (TiDB 的存储引擎)