AI记忆革命:从七秒遗忘到终身学习
目录
01 为何 AI 需要记忆能力
02 记忆增强型 AI 系统的核心运作架构
03 这些记忆内容存储在何处?
04 寻找正确的记忆内容
05 反思与真正的学习
06 记忆类型
07 The Future
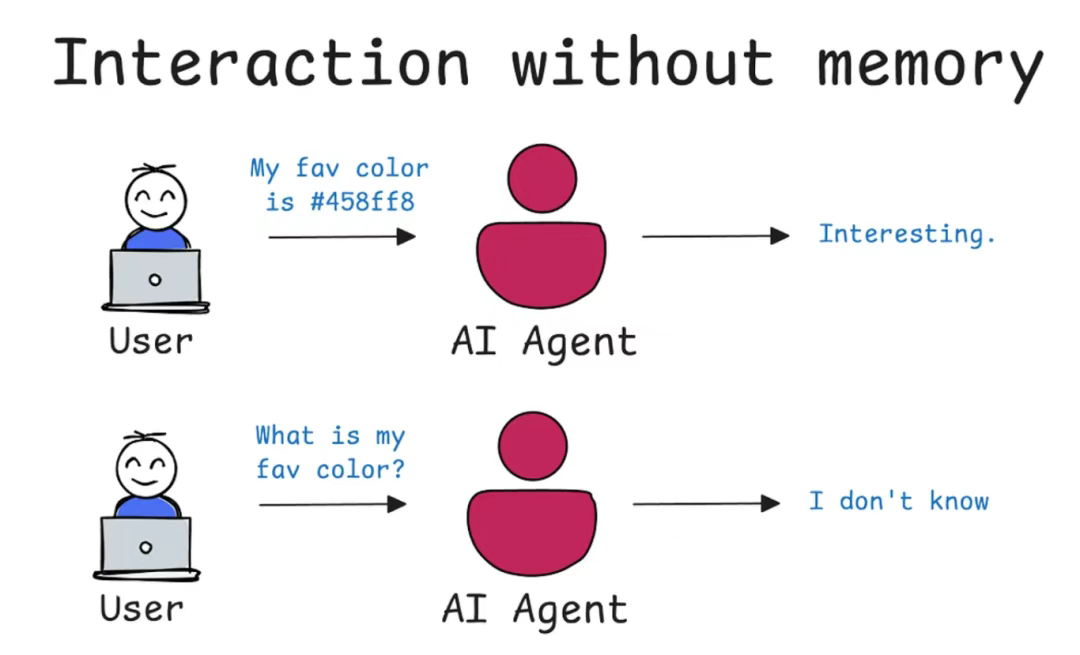
和AI助手对话时,是否总遇到同样的问题?刚说完重要信息,转眼就被遗忘。长期以来,大多数AI都面临着这个困境——它们聪明,却只有七秒记忆。

然而,这一现状正在发生转变。如今的人工智能不仅能记住我们上周的对话内容,还能准确回忆我们的个人偏好,并通过持续互动不断学习提升。这正是当前AI研究的前沿领域之一,也是本文将要深入探讨的主题:人工智能记忆机制的奥秘。接下来,让我们系统性地解析AI记忆能力的实现原理。
01 为何 AI 需要记忆能力
从本质来看,记忆就是为我们提供上下文。它是连接过往经历与当下行为的纽带。对 AI 而言,这是从工具进阶为真正智能伙伴的关键桥梁。 缺乏记忆能力的 AI 将无法实现:
个性化体验不足:无法记住你的偏好(比如喜欢简明的要点而非冗长段落,或需要系统在推荐食谱时考虑你的素食习惯) 学习能力有限:每次互动都需从头开始,难以通过持续交流提升服务质量 处理复杂任务困难:想象与这样的助手合作撰写报告——每次收到新数据都会忘记项目目标 赋予AI记忆能力,是为了让它更有用、更个性化、更接近人类思维,从而提供更有效的帮助。
02 记忆增强型 AI 系统的核心运作架构
这个系统可以被视为一个持续运转的认知闭环,使 AI 能够感知环境、采取行动并从经验中持续学习。整个过程可分解为一个强大的自我迭代循环。
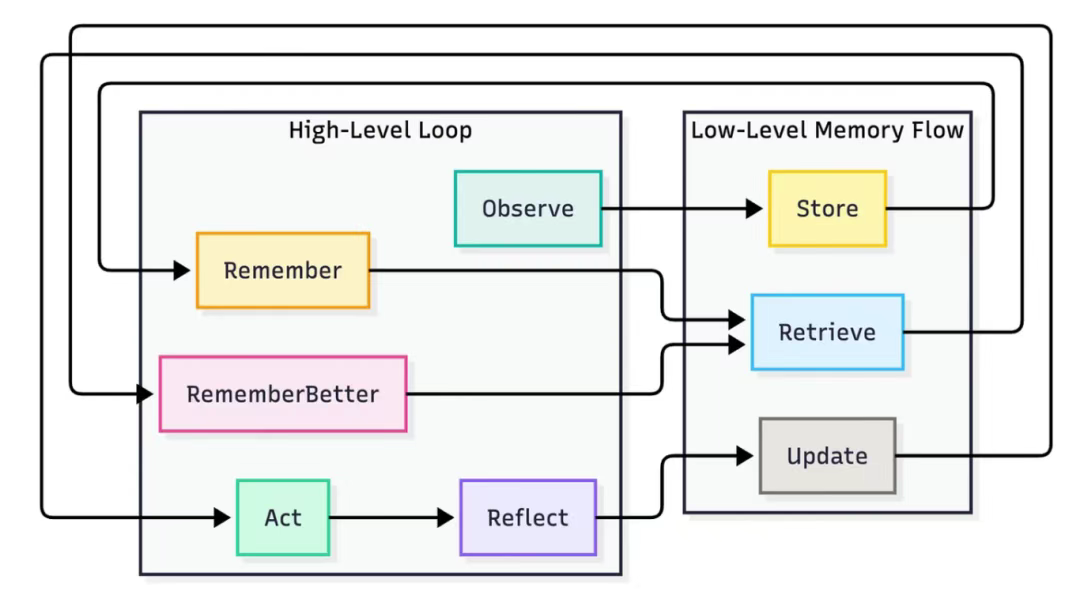
1)观察:首先,智能体感知任务或用户输入。这是其 "眼睛与耳朵" 所在,负责接收当前的上下文信息。
2)记忆:随后智能体存储即时上下文与相关对话历史。这不仅仅是记录文字,更要理解当前时刻 "发生的事情" 以及 "这些事为什么会发生"。
3)行动:基于上下文,智能体执行动作或作出决策。可能表现为编写代码、回答问题或调用特定工具。
4)反思:行动完成后进行评估。行动结果是成功还是失败?是否更接近目标?
5)更新记忆:最终(也是最关键的环节),将新学习到的认知模式与推理洞察回传至记忆库。
正是这种观察 → 记忆 → 行动 → 反思 → 更新的迭代循环,赋予智能体实时改进的能力,使其每一次交互都转化为实践课程。
03 这些记忆内容存储在何处?
那么,这些记忆信息究竟存放在何处呢?在智能体系统中,记忆被精心组织在不同的存储层级中,各司其职。其运作机制可类比为一个高度有序的工作车间。
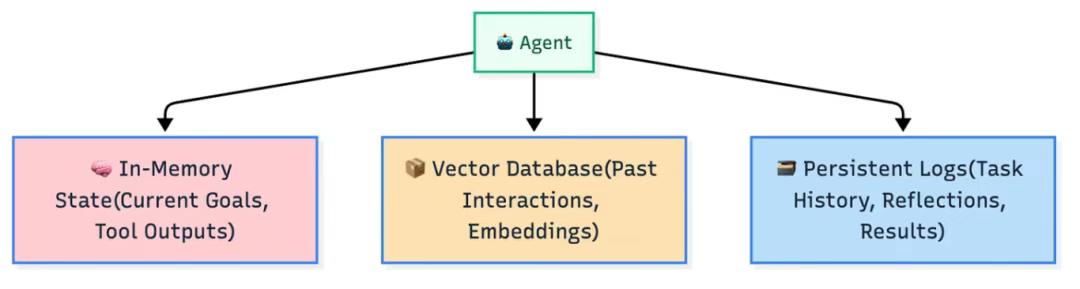
- 实时内存态(In-Memory state) :这是智能体短期使用的临时工作区。存储当前任务所需的即时信息,例如您设定的实时目标或刚调用的工具的输出结果。
- 持久化日志(Persistent logs) :智能体在此建立跨多个会话的长期事件档案,记录行为轨迹、反思结论及任务结果。就像一本详细的项目笔记本,它记录了智能体所做的事情、智能体如何完成任务以及最终结果。这可以确保在下一个任务开始之前,从之前的任务中学到的知识不会丢失。
- 向量数据库(Vector databases) :向量数据库存储历史交互数据时,并非简单记录文本,而是将其转化为蕴含丰富语义的嵌入向量 ------ 即数据的高维数值表征。嵌入向量能捕捉信息的语义精髓与内在关联,使智能体可基于上下文的相似度(而非关键词匹配)检索记忆。其机制更像触发人脑的 "寻找与此相似的情境记忆",而非在文档中进行关键词搜索。
04 寻找正确的记忆内容
当你向智能体提问时,它并不会逐字逐句地通读自己的整个过往经历。相反,它会执行一次优雅的高速检索,以找到最相关的上下文。以下是这种语义搜索背后的运作原理:
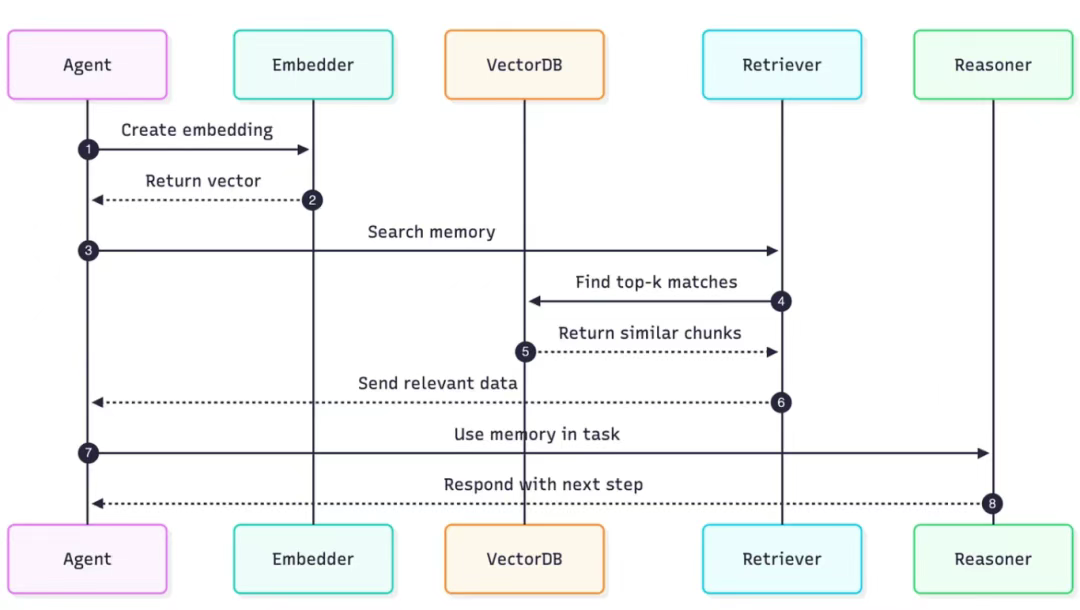
1)创建嵌入向量:智能体获取你当前的任务或问题,并指令一个嵌入模型将其转化为数字化的嵌入向量。
2)搜索记忆内容:这个新的嵌入向量随后被发送到向量数据库,附带一条简单指令:"find the memories most similar to this(找到与此最相似的记忆内容)"。
3)寻找最匹配的记忆内容:数据库将查询嵌入向量(query embedding)与存储的记忆嵌入向量(memory embeddings)进行比对,并检索出最相关的前 k 个匹配项。这些匹配项可能包括过往出现的同类错误、其他类似任务中的成功执行结果,或是用户之前提过的相关需求。
4)使用记忆内容:然后,相关数据会被送回主智能体,用以指导其下一步行动。
整个过程快速、模糊匹配、并且具备上下文感知能力。其核心运作理念在于: "智能检索有用信息"("find what's useful") 而非 "机械记忆全部数据"("remember everything")。
05 反思与真正的学习
在实际应用中,我们需要构建完整的反思闭环机制。以下是一个典型的工作流程示例:
- 任务执行阶段:
- 智能体按既定策略完成具体任务(如客户服务对话、数据分析等)
- 系统自动记录完整执行轨迹,包括决策点、外部反馈和最终结果
-
反思评估阶段(关键环节): a) 有效性分析:
- 识别高回报行动(如成功解决客户投诉的特定话术)
- 通过AB测试数据验证策略有效性(例:对比两种推荐算法的转化率)
b) 困难诊断:
- 标记执行卡点(如处理模糊需求时准确率下降35%)
- 分析外部干扰因素(服务器延迟导致响应超时等)
-
策略优化阶段:
- 建立改进方案库(针对常见问题预设3-5种应对方案)
- 实施渐进式调整(先在小流量测试环境验证新策略)
- 设置版本回滚机制(当新策略效果下降超过阈值时自动切换)
应用场景示例: 在电商客服场景中,智能体完成100次咨询后:
- 发现"主动推荐关联商品"策略使客单价提升22%
- 识别出"退换货政策解释"环节平均耗时超出标准47%
- 据此调整:保留推荐策略,新增政策问答知识库,并设置快捷回复按钮
这种机制确保系统持续进化,最终实现:
- 周级别的策略迭代速度
- 持续性能提升
- 对突发情况的适应能力(如促销期间的流量激增)
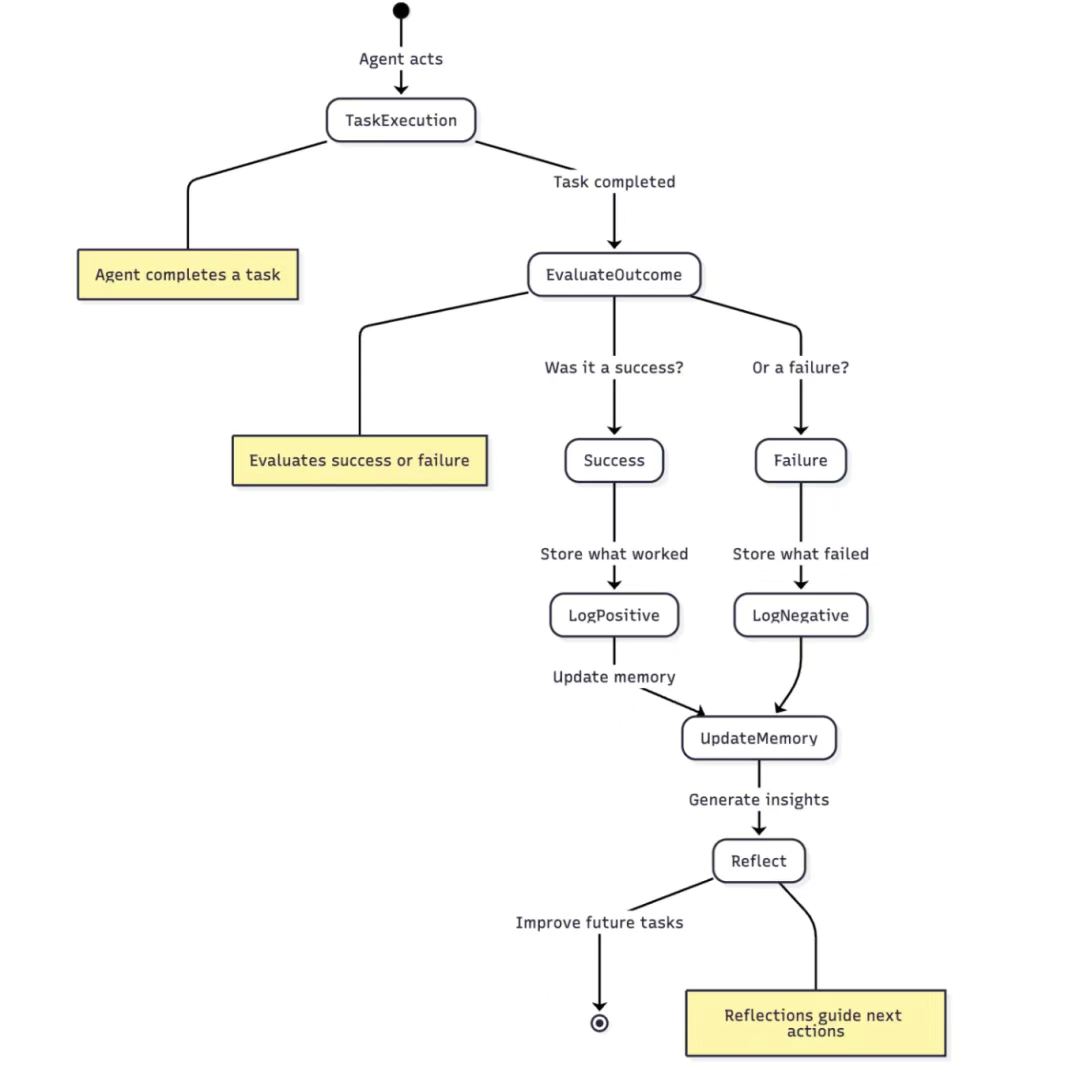
通过反思产生的洞见(无论是从成功中获得的经验,还是从失败中获得的教训)将被记录并存储至记忆库。这种反思循环机制使智能体能持续从行动中学习,确保未来所作的决策始终受历史经验指引。
06 记忆类型
为做出智能决策,智能体会综合使用多种类型的记忆 ------ 这与人类大脑的运作方式高度相似。
1)工作记忆(Working memory)
可视为智能体的思维便利贴(mental sticky notes),用于短期存储当前任务的指令、目标及执行步骤。
- 短期记忆(Short-Term memory):指 AI 为完成即时任务临时暂存信息的能力。在现代 AI(如 ChatGPT)中,这种记忆通常被称为 "上下文窗口"(context window)。
- 本质功能:预定义的对话缓存空间,存储当前会话的所有输入 / 输出内容
- 运作原理:类比 AI 的运行内存(RAM),通过快速存取保持对话的连贯性(可实时调用上下文窗口内全部信息,从而理解最新问题的上下文)
- 局限:对话长度超限时,最早期的内容将被主动遗忘(为新内容腾出空间) ------ 这就是长对话中 AI 遗忘开头内容的原因
2)情景记忆(Episodic memory)
相当于智能体的任务日记,记录历史执行过程中的关键信息,如:具体成功案例、失败教训、用户互动历史。
3)语义记忆(Semantic memory) :这是智能体的长期知识库,相当于一本内置的百科全书,它储存着这个智能体通过长期经验积累的通用知识、行为模式和应对策略。
- 长期记忆(Long-Term memory):这是最重要的部分。通过构建持久化的 "数据库",使人工智能能在不同会话、不同日期乃至间隔数月后依然记住你。
- 本质功能:为人工智能提供存储机制,更重要的是能够检索过往交互中的关键信息。
- 运作原理:当前最主流的技术是检索增强生成(RAG)。其运作流程如下:
- 存储记忆:当用户提供重要信息(如 "我的公司叫 'Innovate Next'")时,系统将其转化为称为 "向量" 的数学表征,储存在专用向量数据库中
- 调用记忆:当用户提出相关问题(如 "为我的公司提供营销建议")时,系统首先查询该数据库获取相关记忆片段
- 应用记忆:在生成回复前,将检索到的记忆("用户公司名为 Innovate Next")用来增强提示词
智能体的实时操作(工作记忆)、过往经历(情景记忆)与通用知识(语义记忆)三者融合,才能做出真正的智能决策。
07 The Future
本文所诉内容并非理论空谈,而是当前正在加速推进的现实。诸如 LangChain、LangGraph、LlamaIndex 及 CrewAI 等现代框架均已内置支持这类记忆系统 ------ 从简易的缓存(buffers)到复杂的长期检索器(long-term retrievers),相关技术正以闪电般的速度迭代演进。不妨关注一下专为智能体设计的 Mem0 等新兴架构,它们的目标是实现智能化的记忆管理 ------ 能像人类一样自主判断信息价值,动态筛选需要保留的内容并优化存储方式。
我们最终要构建的不只是处理信息的 AI,而是能与信息建立深度联结的伙伴。具备记忆、学习和进化能力的 AI,正是精巧工具与真正协作伙伴的本质区别。

这个漫画的笑点在于机器人被要求识别猫的种类,但它却表示自己更擅长识别狗,因此无法完成这个关于猫的分类任务。