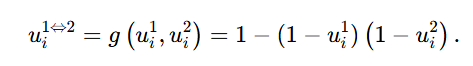Fuzzy Multimodal Learning for Trusted Cross-modal Retrieval(CVPR 2025)
研究方向:Image Captioning
1. 论文介绍
本文提出了一种名为模糊多模态学习(FUME)的新框架,基于模糊集合理论,来量化跨模态不确定性,从而实现可信的跨模态检索。
跨模态检索(CMR)的主要挑战在于计算异构样本之间的相似性,大多数现有方法通过将不同模态投影到共享的潜在空间来解决这一问题,使得语义相关的异构样本可以用相似的嵌入来表示。但它们是确定性模型,仅依赖相似性分数,同时忽略了不可靠或不可信结果的可能性,一个直观的解决方案是对检索结果相关的认知不确定性进行量化。
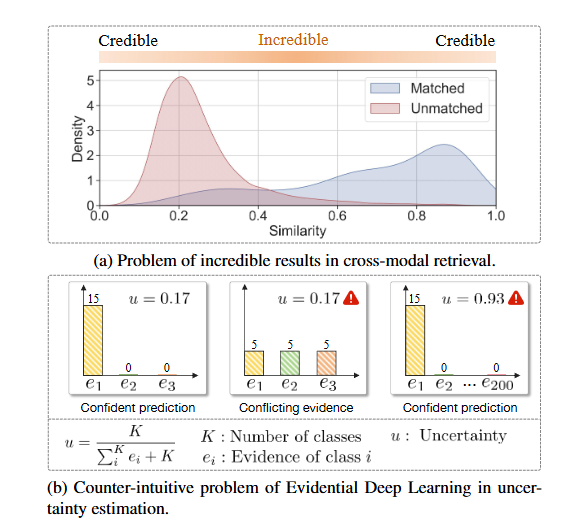
图(a):
- 横轴 Similarity:跨模态对(如一张图和一段文字)在共享空间里的相似度分数
- 纵轴 Density:对应相似度的概率密度。纵坐标高的地方表示“有更多检索对落在该相似度区间”。
- 顶部的色条(从两端的 “Credible” 到中间的 “Incredible”):用它来直观划分相似度区间——两端(很低或很高的相似度)被认为可信,中间区间被认为容易出现 “incredible results”(看起来合理但实际上错的检索)。
图(b):
EDL(Evidential deep learning,之前的方法) 的不确定性公式:
K = 类别数
= 对第 i 类的 evidence(证据量)
2.方法介绍
代表矩阵,
表示列向量。多模态数据集
![]() ,
,是模态的数量。
![]() 表示第
表示第模态的集合,N是每个模态中的样本数量,
表示来自第
模态的第
个样本,
是第
模态的维度,
![]() 是
是的语义标签向量
,是类别的数量。有
个类别时,标签是长度为
的向量,属于第
类时对应位置为 1,其它位置为 0。
跨模态检索(CMR)的目标是学习一组映射函数 (每个模态一个),把每个模态的样本从各自原始特征空间投影到同一个公共潜在空间。
![]() 投影后的向量记为
投影后的向量记为 ,维度是
。把
标准化(例如单位归一化),便于用余弦相似度比较。每个映射函数
有自己的可训练参数
。
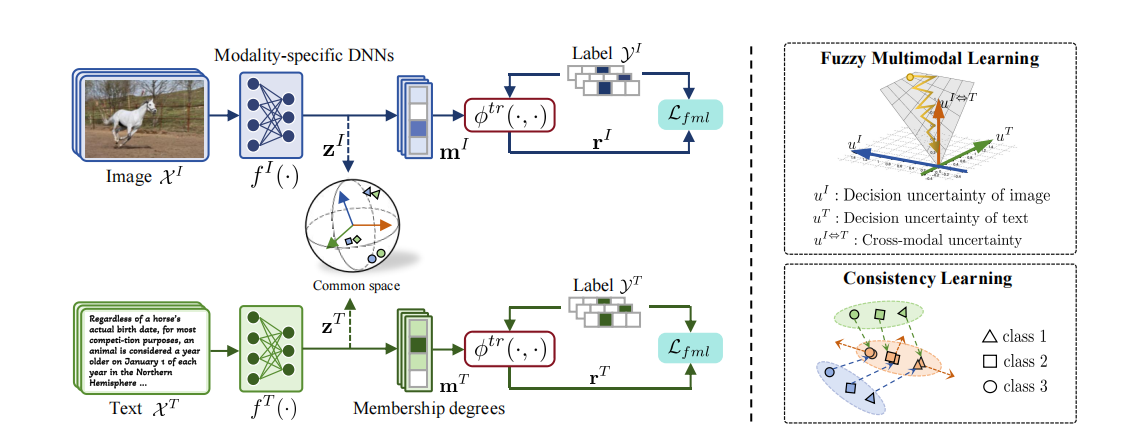
2.1 模糊多模态学习
2.1.1 可信度建模
可能性(样本属于某个类别的可能性):给定一个样本,它属于每个类别的隶属度表示为
,其中K是类别的数量。
![]()
必然性(样本不属于其它类别的确定性):![]()
把可能性和必然性合并得到类别可信度:![]()
2.1.2 可信度学习
直观上,这可以通过直接将类别可信度与相应的一热标签
对齐来实现,即最小化
,
但也有过度优化不匹配类别必要性问题。
假设 ,真实类为 1(标签
)。若目标是使
,可以通过两种方式降低
:
降低
(合乎直觉);
提高
(通过把
提高到 1),这也会使 1
下降,从而把
降低。但第二种方式会让
因此必须约束优化方向,使减少非真类可信度的手段是提高真类隶属度而不是抬高其它错误类别。
使用有标签引导的可信度 :
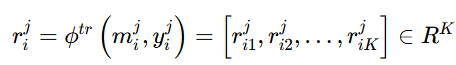
改进后的类别可信度:
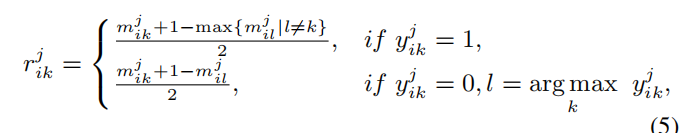
![]() (也就是标签中为 1 的那一类别的索引)
(也就是标签中为 1 的那一类别的索引)
设 ,当前隶属度向量
,真类是类 1(所以
)。
用论文的(非真类
):
若把 提高到 0.9,
不变(仍然 0.45),因为
用的是
作为参照,和
无关。于是“抬高其他错误类”不再能骗过损失,从而避免了错误优化路径。
损失函数:
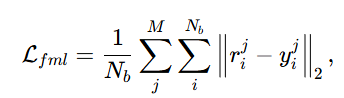
2.2 一致性学习
跨模态对比损失,把同一实例的不同模态表示拉近,把不同实例(无论哪种模态)的表示推远,缩小模态间差距,增强公共空间的语义对齐。
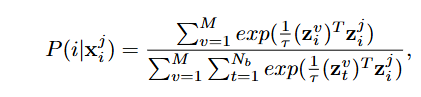
当用 作为查询时,模型把同一实例
(跨所有模态)的表示视为正例的相对概率
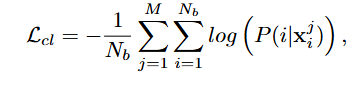
在公共空间中对齐来自同一实例的跨模态样本的损失
结合模糊多模态学习和一致性学习,最终的损失函数:
![]()
强迫每个模态学出正确的
类别可信度(从而降低单模态
决策不确定性);
保证不同模态在
空间对齐,使得两模态的
、
可比较与融合。
3. 推理阶段
在推理阶段,相似性是传统跨模态检索(CMR)方法广泛使用的度量标准,用于测量来自不同模态的两个样本是否匹配。
我们首先量化每个模态预测的决策不确定性,随后融合两种模态的决策不确定性来推断检索结果的跨模态不确定性。
单模态的决策不确定性:
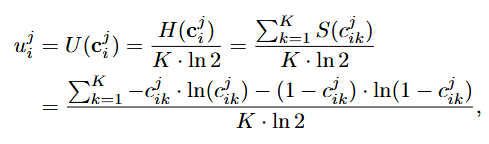
两模态的不确定性融合函数: