机器学习模型可解释库的介绍:Shapash (一)
github地址:
https://github.com/MAIF/shapash
中文文档:
https://weak.notion.site/README-8cc8e0bb36b44c7ca3251c3a27d83605
英文文档:
https://shapash.readthedocs.io/en/latest/
本文:Shapash: Making ML Models Understandable by Everyone
文章目录
- 1 背景
- 2 Shapash 关键特性
- 3 安装
- 3.1 Shapash 演示
- 3.1.1 步骤 1 — 导入
- 3.1.2 步骤 2 — 初始化 SmartExplainer 对象
- 3.1.3 步骤 3 — 编译
- 3.1.4 步骤 4 — 启动 Web 应用
- 3.1.5 Step 5 — 输出图解释
- 特征重要性
- 贡献图
- local图
- 比较图
在这篇文章中,我们将介绍 Shapash,一个开源的 Python 库,帮助数据科学家使他们的机器学习模型对所有人更加透明和可理解!
Shapash Web App 演示
Shapash 是由 MAIF 开发的 Python 工具包,旨在帮助数据科学家理解机器学习模型。它使得与非数据专家(如业务分析师、管理人员、最终用户等)共享和讨论模型可解释性变得更加容易。
具体来说,Shapash 提供易于阅读的可视化和一个 Web 应用。Shapash 用适当的措辞(预处理逆转/后处理)展示结果。Shapash 在操作环境中非常有用,因为它使数据科学家能够在从探索到生产的过程中使用可解释性:您可以轻松地在生产中部署本地可解释性,以补充每个预测/推荐的本地可解释性摘要。
在这篇文章中,我们将介绍 Shapash 的主要功能及其工作原理。我们将通过一个具体的用例来说明该库的实现。
1 背景
模型的可解释性和可理解性是热门话题。关于这一主题有许多文章、出版物和开源贡献。这些贡献并没有解决相同的问题和挑战。
大多数数据科学家使用这些技术有很多原因:更好地理解他们的模型,检查模型的一致性和无偏性,以及调试。
然而,问题不止于此:
可理解性对于教学目的至关重要。可以进行讨论的可理解机器学习模型可以与非数据专家(如业务分析师、最终用户等)进行辩论。
具体来说,在我们的数据科学项目中,有两个步骤涉及非专家:
- 探索步骤和模型拟合:
在这个阶段,数据科学家和业务分析师讨论所涉及的内容,并定义他们将集成到项目中的基本数据。这需要很好地理解主题和我们所建模问题的主要驱动因素。
为此,数据科学家研究全局可解释性、特征重要性以及模型的主要特征的作用。他们还可以局部查看某些个体,特别是异常值。此阶段的 Web 应用非常有趣,因为他们需要查看可视化和图形。与业务分析师讨论这些结果非常有趣,以挑战方法并验证模型。
- 在生产环境中部署模型
就是这样!模型经过验证,已部署,并为最终用户提供预测。本地可解释性可以为他们带来很多价值,前提是有办法为他们提供良好、有用且易于理解的摘要。这对他们有两个原因是有价值的:
- 透明性带来信任:如果他理解模型,他将信任模型。
- 人类保持控制:没有模型是 100% 可靠的。当他们能够理解算法的输出时,用户可以推翻算法的建议,如果他们认为这些建议基于错误的数据。
Shapash 的开发旨在帮助数据科学家满足这些需求。

2 Shapash 关键特性
- 易于阅读的可视化,适合所有人。
- 一个 Web 应用:要理解模型的工作原理,您必须查看多个图表、特征重要性和特征对模型的全局贡献。Web 应用是一个有用的工具。
- 多种方法展示结果,使用适当的措辞(预处理逆转、后处理)。您可以轻松添加数据字典、category-encoders 对象或 sklearn ColumnTransformer 以获得更明确的输出。
- 函数可轻松保存 Pickle 文件并将结果导出为表格。
- 可解释性摘要:该摘要可配置以适应您的需求,专注于本地可解释性的重要内容。
- 能够轻松部署到生产环境,并为每个操作应用(批处理或 API)完成每个预测/推荐的本地可解释性摘要。
- Shapash 提供多种处理方式:它可以轻松访问结果或进行更好的措辞。显示结果所需的参数非常少。但是,您越多地清理和记录数据集,最终用户的结果就会越清晰。
Shapash 适用于回归、二元分类或多类问题。它与许多模型兼容:Catboost、Xgboost、LightGBM、Sklearn Ensemble、线性模型、SVM。
Shapash 基于使用 Shap(Shapley 值)、[Lime](https://github.com/marcotcr/lime)或任何允许计算可累加本地贡献的技术计算的本地贡献。
3 安装
您可以通过 pip 安装该软件包:
$pip install shapash
3.1 Shapash 演示
让我们在一个具体的数据集上使用 Shapash。在本文的其余部分,我们将向您展示 Shapash 如何探索模型。
我们将使用来自 Kaggle 的著名“房价”数据集来拟合一个回归模型……并预测房价!让我们先加载数据集:
import pandas as pd
from shapash.data.data_loader import data_loading
house_df, house_dict = data_loading('house_prices')
y_df=house_df['SalePrice'].to_frame()
X_df=house_df[house_df.columns.difference(['SalePrice'])]
house_df.head(3)
对分类特征进行编码:
from category_encoders import OrdinalEncodercategorical_features = [col for col in X_df.columns if X_df[col].dtype == 'object']
encoder = OrdinalEncoder(cols=categorical_features).fit(X_df)
X_df=encoder.transform(X_df)
训练、测试拆分和模型拟合。
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressorXtrain, Xtest, ytrain, ytest = train_test_split(X_df, y_df, train_size=0.75)
reg = RandomForestRegressor(n_estimators=200, min_samples_leaf=2).fit(Xtrain,ytrain)
并预测测试数据……
y_pred = pd.DataFrame(reg.predict(Xtest), columns=['pred'], index=Xtest.index)
让我们发现并使用 Shapash SmartExplainer。
3.1.1 步骤 1 — 导入
from shapash.explainer.smart_explainer import SmartExplainer
3.1.2 步骤 2 — 初始化 SmartExplainer 对象
xpl = SmartExplainer(features_dict=house_dict) # 可选参数
- features_dict:指定每个列名的含义的字典。
3.1.3 步骤 3 — 编译
xpl.compile( x=Xtest, model=regressor, preprocessing=encoder,# 可选:使用 inverse_transform 方法 y_pred=y_pred # 可选
)
编译方法允许使用另一个可选参数:postprocess。它提供了应用新函数的可能性,以指定更好的措辞(正则表达式、映射字典等)。
现在,我们可以显示结果并理解回归模型的工作原理!
3.1.4 步骤 4 — 启动 Web 应用
app = xpl.run_app()
Web 应用链接会在 Jupyter 输出中出现(访问演示 这里)。
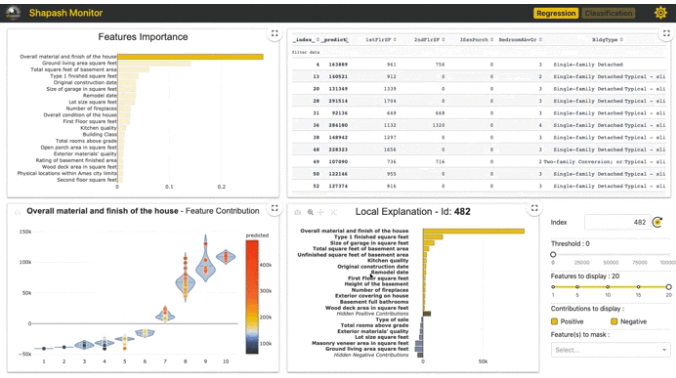
该 Web 应用包含四个部分:
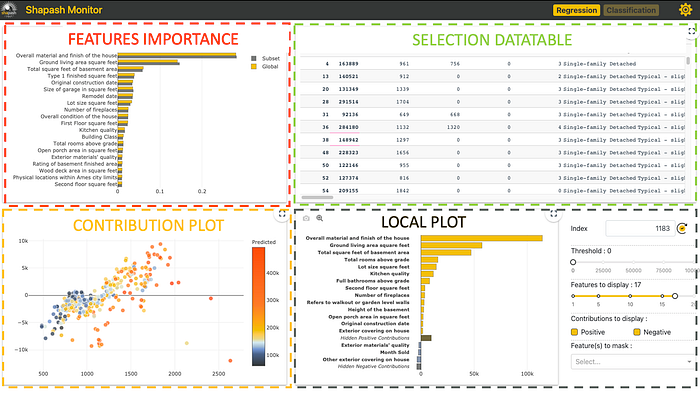
每个部分都可以相互交互,帮助轻松探索模型。
特征重要性:您可以单击每个特征以更新下面的贡献图。
贡献图:特征如何影响预测?显示每个特征的本地贡献的提琴图或散点图。
本地图:
- 本地解释:哪些特征对预测值贡献最大。
- 您可以使用多个按钮/滑块/列表来配置本地可解释性的摘要。我们将在下面描述使用 filter 方法的不同参数,以便您可以处理摘要。
- 此 Web 应用是与业务分析师讨论如何总结可解释性的最佳方式以满足操作需求的有用工具。
选择表: 允许 Web 应用用户选择:
- 一个子集以集中探索该子集
- 一行以显示相关的本地解释
如何使用数据表选择子集?在表顶部,您想要用于过滤的列名下方,指定:
- =Value, >Value, <Value
- 如果您想选择包含特定单词的每一行,只需输入该单词而不加“=”
此 Web 应用有几个选项可用(右上角按钮)。最重要的选项可能是样本大小(默认:1000)。为了避免延迟,Web 应用依赖于样本来显示结果。使用此选项修改样本大小。
要终止应用:
app.kill()
3.1.5 Step 5 — 输出图解释
所有图表都可以在 Jupyter 笔记本中使用,下面的段落描述每个图表的关键点。
特征重要性
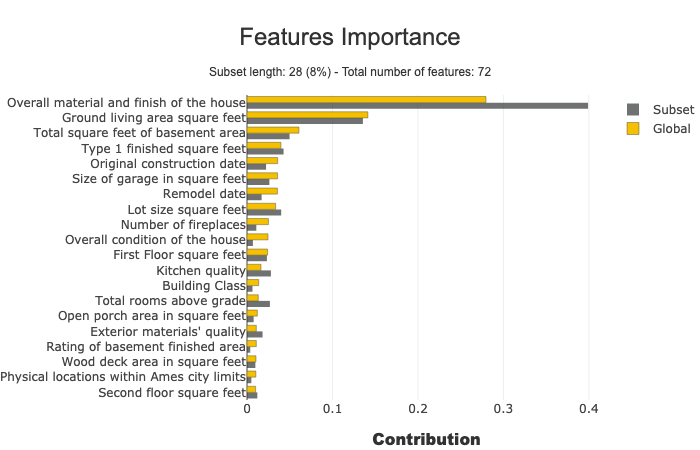
此参数允许比较子集的特征重要性。它对于检测子集中的特定行为非常有用。
subset = [168, 54, 995, 799, 310, 322, 1374, 1106, 232, 645, 1170, 1229, 703, 66, 886, 160, 191, 1183, 1037, 991, 482, 725, 410, 59, 28, 719, 337, 36]
xpl.plot.features_importance(selection=subset)
贡献图
贡献图用于回答以下问题:
特征如何影响我的预测?它是否有积极贡献?特征的贡献是逐渐增加还是减少?是否存在任何阈值效应?对于分类变量,每种模式的贡献如何?……此图表补充了特征的重要性,以便更好地理解特征对模型的影响。
此图表上有多个参数。请注意,显示的图表会根据您对分类或连续变量的兴趣(提琴图或散点图)以及您所处理的用例类型(回归、分类)而有所不同。
xpl.plot.contribution_plot("OverallQual")
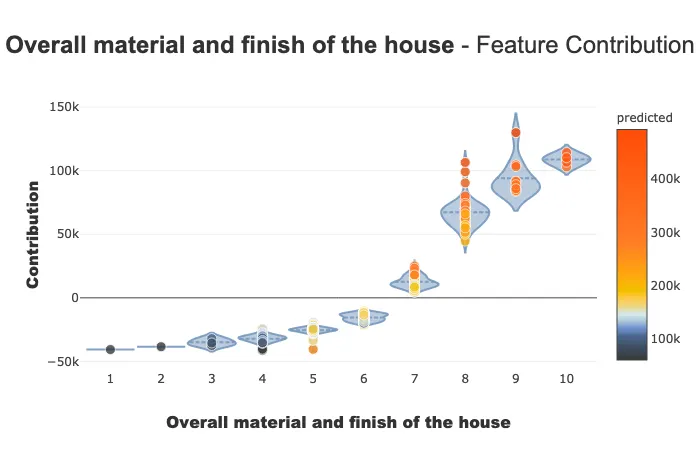
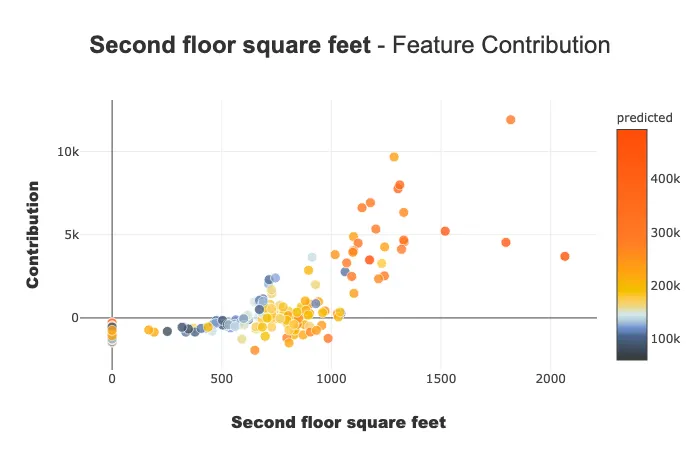
贡献图应用于连续特征。
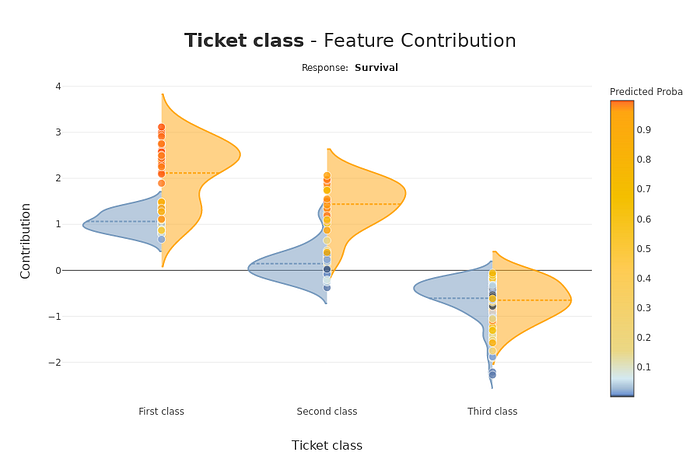
分类案例:泰坦尼克号分类器 — 贡献图应用于分类特征。
local图
您可以使用local图进行模型的本地可解释性。
filter() 和 local_plot() 方法允许您测试和选择最佳方式来总结模型所捕捉的信号。您可以在探索阶段使用它。然后,您可以将此摘要部署到生产环境中,以便最终用户在几秒钟内理解每个推荐的最有影响力的标准。
我们将发布第二篇文章,说明如何在生产中部署本地可解释性。
结合 filter 和 local_plot 方法
使用 filter 方法指定如何总结本地可解释性。您可以配置摘要的四个参数:
- max_contrib:要显示的标准的最大数量
- threshold:显示标准所需的贡献(绝对值)的最小值
- positive:仅显示积极贡献?消极的?(默认值为 None)
- features_to_hide:您不想显示的特征列表
在定义这些参数后,我们可以使用 local_plot() 方法显示结果,或使用 to_pandas() 导出它们。
xpl.filter(max_contrib=8, threshold=100)
xpl.plot.local_plot(index=560)
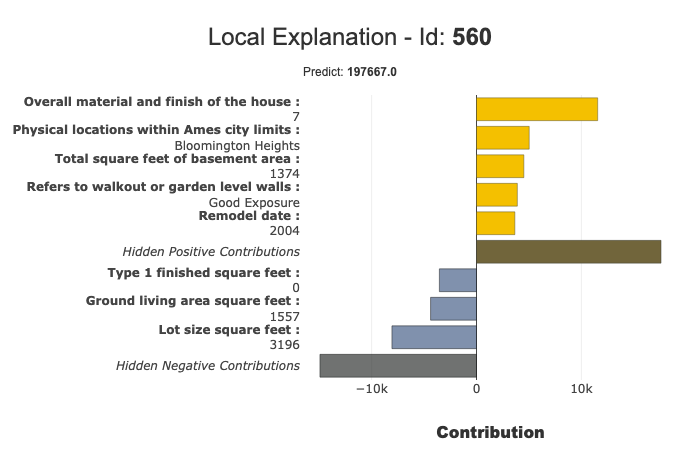
导出到 pandas DataFrame:
xpl.filter(max_contrib=3, threshold=1000)
summary_df = xpl.to_pandas()
summary_df.head()
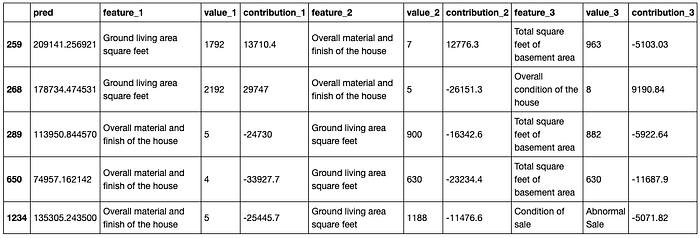
比较图
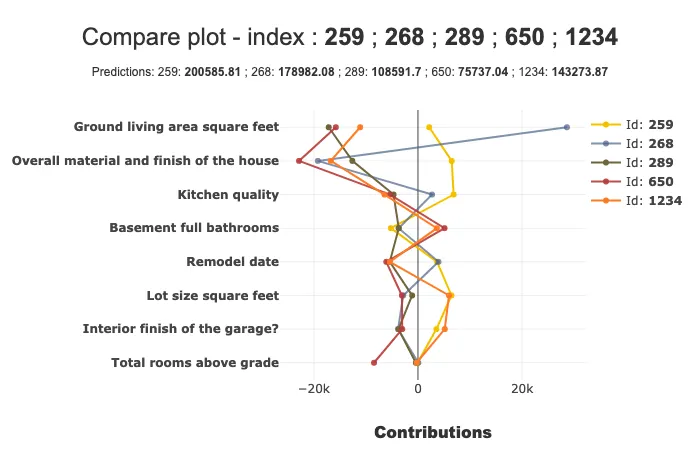
使用 compare_plot() 方法,SmartExplainer 对象可以理解为什么两个或多个个体的预测值不同。最具决定性的标准显示在图表顶部。
xpl.plot.compare_plot(row_num=[0, 1, 2, 3, 4], max_features=8)