【Jetson】基于llama.cpp部署gpt-oss-20b(推理与GUI交互)
前言
本文在jetson设备上使用llama.cpp完成gpt-oss 20b的部署,包括后端推理和GUI的可视化交互。
使用的设备为orin nx 16g(super),这个显存大小推理20b的模型完全没有问题。
使用硬件如下,支持开启super模式。(https://www.seeedstudio.com/reComputer-Super-J4012-p-6443.html)

- jetpack版本:6.2
- 系统:ubuntu 22.04
- CUDA版本:12.6
安装llama.cpp
拉取llama.cpp,maste分支下25年8月份之后支持gpt-oss:
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
进行编译,编译时间会比较长:
sudo apt update
sudo apt install -y build-essential cmake git
cmake -B build -DGGML_CUDA=ON
cmake --build build --parallel # 平行编译
如果出现cuda相关的路径错误,如下:
-- Found CUDAToolkit: /usr/local/cuda/include (found version "12.6.68")
-- CUDA Toolkit found
-- Using CUDA architectures: 50;61;70;75;80
CMake Error at /usr/share/cmake-3.22/Modules/CMakeDetermineCompilerId.cmake:726 (message):Compiling the CUDA compiler identification source file"CMakeCUDACompilerId.cu" failed.Compiler: CMAKE_CUDA_COMPILER-NOTFOUNDBuild flags:Id flags: -vThe output was:No such file or directoryCall Stack (most recent call first):/usr/share/cmake-3.22/Modules/CMakeDetermineCompilerId.cmake:6 (CMAKE_DETERMINE_COMPILER_ID_BUILD)/usr/share/cmake-3.22/Modules/CMakeDetermineCompilerId.cmake:48 (__determine_compiler_id_test)/usr/share/cmake-3.22/Modules/CMakeDetermineCUDACompiler.cmake:298 (CMAKE_DETERMINE_COMPILER_ID)ggml/src/ggml-cuda/CMakeLists.txt:25 (enable_language)-- Configuring incomplete, errors occurred!
说明编译器环境路径不对,参考下面指令修复,cuda-12.6换为你使用的cuda版本:
export PATH=/usr/local/cuda-12.6/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda-12.6/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
编译完成后,在llama.cpp目录下安装后续转换模型需要用的依赖:
pip install -e .
后续调用该目录下的脚本与执行文件即可。
下载gpt-oss模型
option A : 使用 huggingface-cli 下載
该方法下载模型需要翻墙,如果网络环境不好请看option B。
安装HuggingFace-cli,并下载模型:
pip install -U "huggingface_hub[cli]"
huggingface-cli download openai/gpt-oss-20b --local-dir gpt-oss-20b/
option B: 手动下载
国内使用使用huggingface-cli下载模型经常链接不上服务器,这种情况可以选择手动下载。
进入Hugging Face中gpt-oss的主页,如下:
https://huggingface.co/openai/gpt-oss-20b/tree/main
图中的几个就是模型文件以及相关的参数文件,点击下载后,放到同一个目录下:
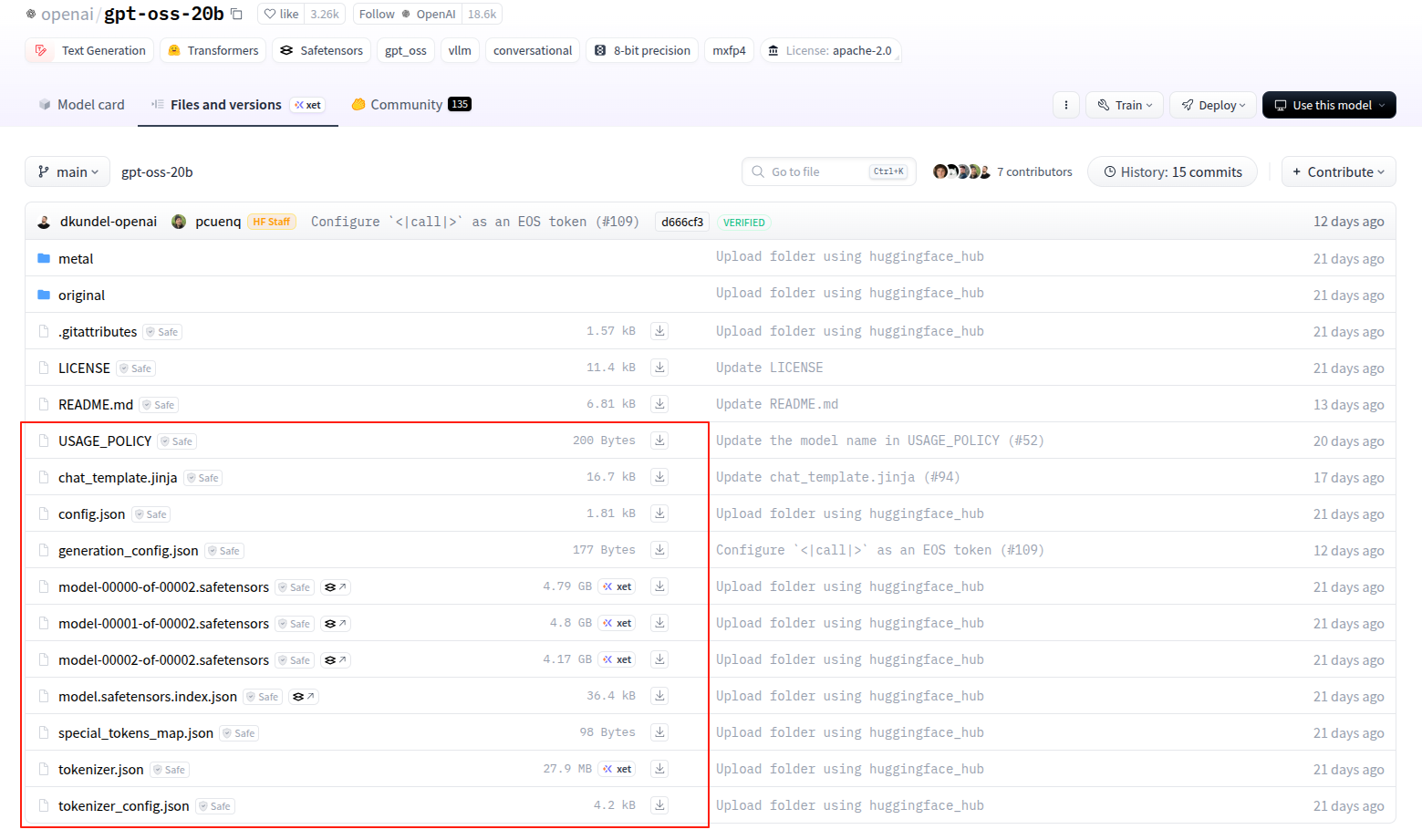
转换模型与量化
把模型从HuggingFace格式转为gguf格式:
python convert_hf_to_gguf.py --outfile /home/seeed/Downloads/gpt-oss /home/seeed/Documents/gpt-oss-gguf/
# python convert_hf_to_gguf.py --outfile <输入模型的路径> <输出模型的路径>
对模型进行量化:
./build/bin/llama-quantize /home/seeed/Documents/gpt-oss-gguf/Gpt-Oss-32x2.4B-F16.gguf /home/seeed/Documents/gpt-oss-gguf-Q4/Gpt-Oss-32x2.4B-Q4.gguf Q4_K
# ./build/bin/llama-quantize <f16_gguf_模型的路径> <输出模型的路径> <量化方法>
你也可以在HuggingFace找到别人量化好的各种精度的gguf格式模型,直接下载可以跳过上面的转换/量化步骤:
https://huggingface.co/unsloth/gpt-oss-20b-GGUF/tree/main
gpt-oss原生的模型中一些算子本来就才用了压缩的精度(例如mxfp4精度)
所以量化后模型没有明显的变小。
模型推理与benchmark
在llama.cpp目录下,启动cli进行推理测试,-ngl 40表示模型的前40层在GPU上运行,所以当模型较小时,这个参数设置到某个阈值就不会再提升推理速度:
./build/bin/llama-cli -m /home/seeed/Documents/gpt-oss-gguf/Gpt-Oss-32x2.4B-F16.gguf -ngl 40
启动后可以在终端中向gpt提问
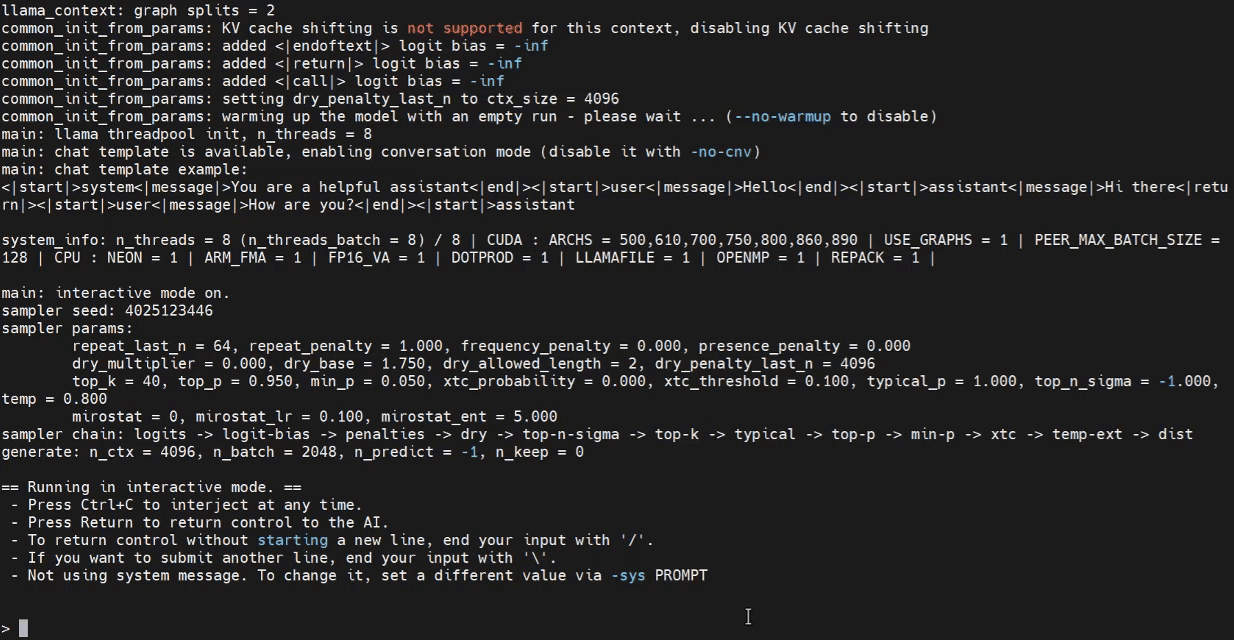
使用llama.cpp做benchmark,测试推理速度,batch-size提高也会提升测速结果:
./build/bin/llama-bench -m /home/seeed/Documents/gpt-oss-gguf/Gpt-Oss-32x2.4B-F16.gguf -ngl 40 --batch-size 2048
GUI交互
启动llam-server,提供后端推理服务,记得把之前的llama-cli关掉:
./build/bin/llama-server -m /home/seeed/Documents/gpt-oss-gguf/Gpt-Oss-32x2.4B-F16.gguf -ngl 40
如果希望通过 UI 界面访问模型,可以在 Jetson 上安装 OpenWebUI 来实现。
打开一个新的终端并输入以下命令,安装并启动OpenWebUI:
pip install open-webui
open-webui serve
然后,打开您的浏览器并导航到 http://<jetson的ip地址>:8080 来启动 Open WebUI。如果使用本地回环就设置为127.0.0.1这个地址。
转到 ⚙️ Admin Settings → Connections → OpenAI Connections,将 url 设置为:http://127.0.0.1:8081。保存后,Open WebUI将开始使用本地的Llama.cpp服务器作为后端
总结
gpt-oss,需要使用8月份之后release的llama.cpp才能推理,目前该模型量化的压缩效果不明显。