模型微调训练中超长文本训练存在的问题
字典内容问题
预训练模型(如bert)有字典长度限制,大多数情况下这个长度能被满足,某些特定情况下可能不被满足,字符超出了字典长度。
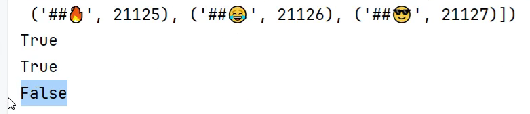
如下图所示,阳光中间有个空格,字典识别不到阳光在vocab里面。
token = BerTokenizer.from_pretrained(r"../../c30xxxxxxx")vocab = token.vocab
print(vocab)
print("阳" in vocab)
print("光" in vocab)
print("阳光" in vocab)

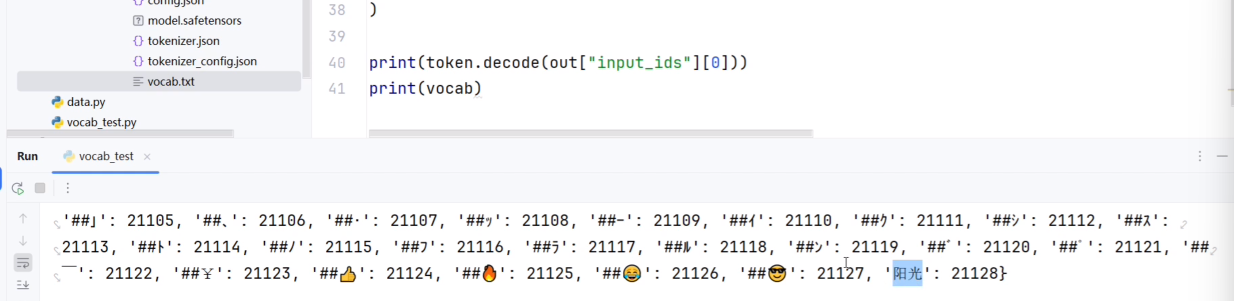
自定义内容加到字典中
#自定义内容添加到vocab中
token.add_tokens(new_tokens=["阳光"])
vocab = token.get_vocab()
print(len(token.vocab))
print("阳光" in vocab)现在重新编码,发现阳光就能被编码到一起了。

除了添加一般的内容,我们也可以添加特殊的词,但一般不需要加。
token.add_special_tokens(special_token_dict={"cls_token"="<CLS>"})
添加普通文本或特殊词后,就会跟config.json配置文件冲突,导致没法用。
编码长度问题
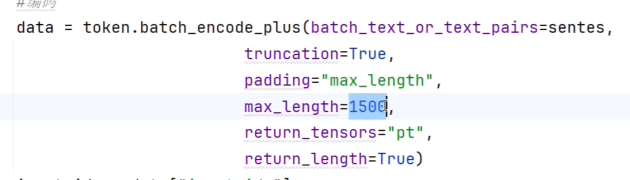
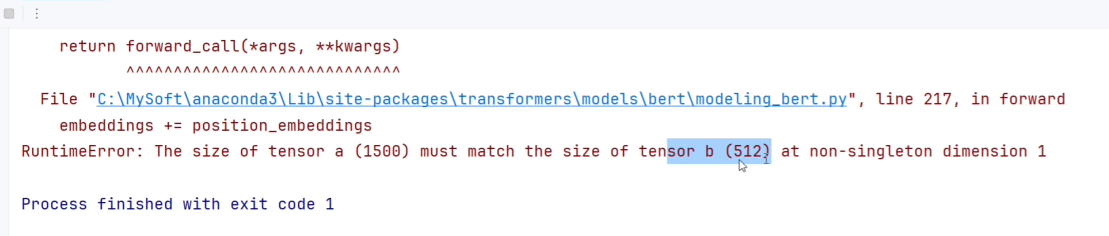
编码字符过长导致超出max_position_embeddings报错。
在max_length中,我填入了1500,超出了max_position_embeddings,导致报错。
解决方法
修改我们需要通过配置文件修改。
观察预训练模型,修改时尽量不要动维度等参数。
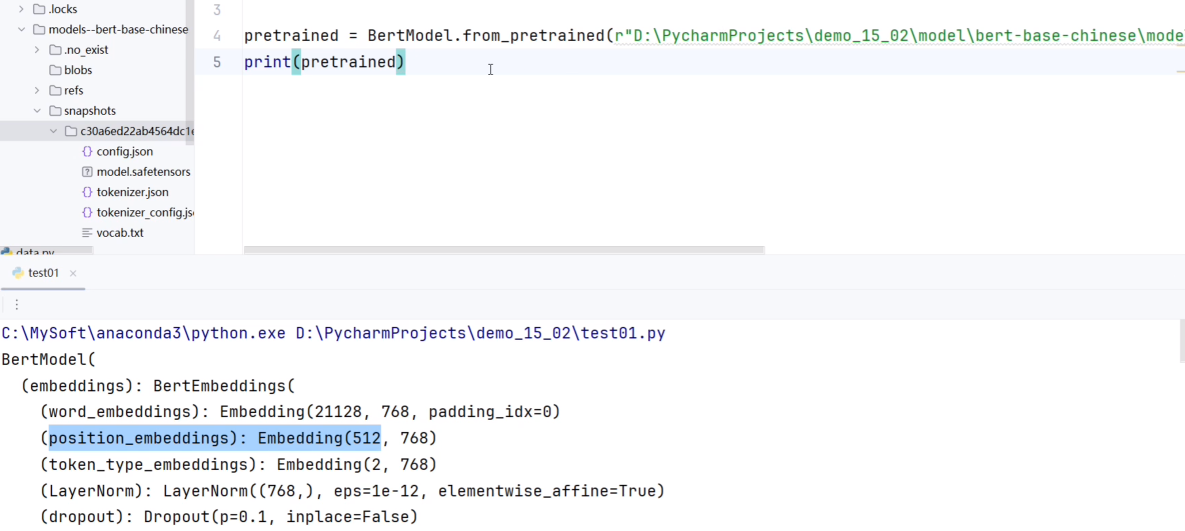
修改字典长度和编码长度
pretrained.embeddings.word_embeddings = torch.nn.Embedding(21130, 768, padding_idx=0)
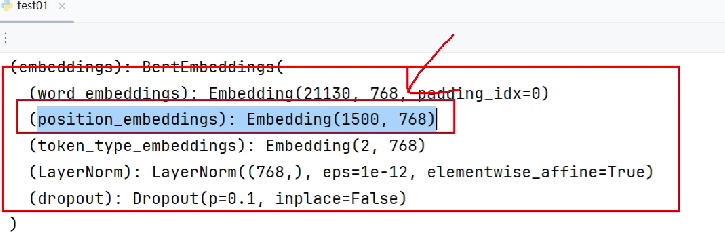
pretrained.embeddings.position_embeddings = torch.nn.Embedding(1500, 768)修改模型后打印,发现修改成功。但这种方法只更新了参数,没有更新配置文件。
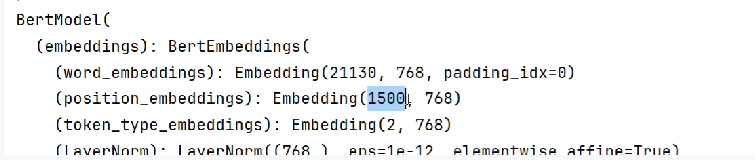
注意我们编码问题还需要修改分词工具,使它达到需要的长度,不然还是会报错,上个方式修改没有修改max_position_embeddings。

正确修改方式:
from transformers import BertConfigconfig = BertConfig.from_pretrained(r"../../c30xxxxxxx")
config.max_position_embeddings = 1500print(config)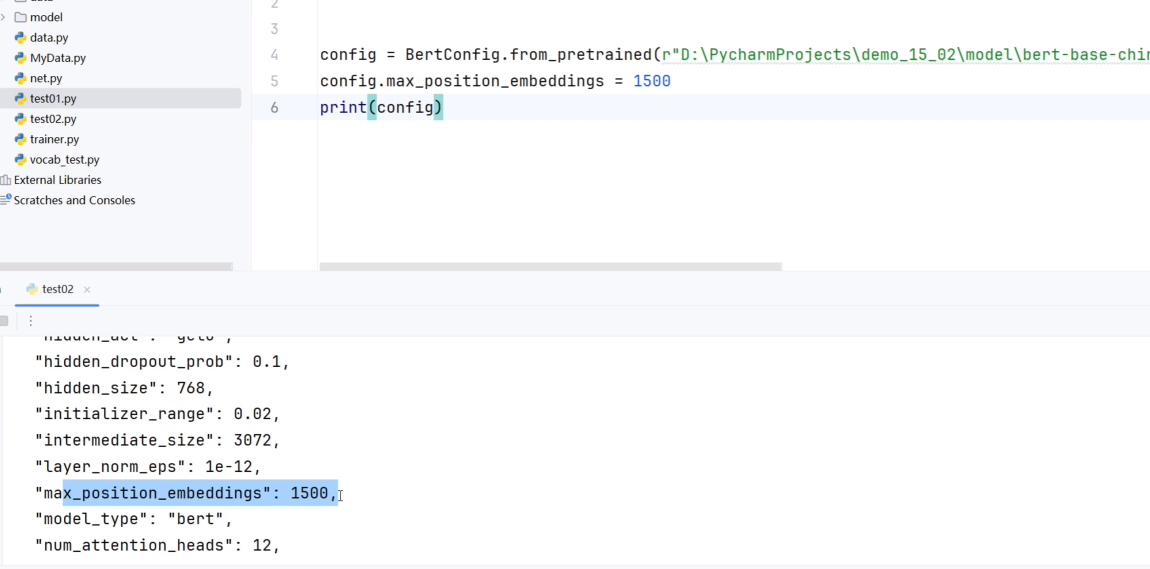
把配置信息合并到模型里面。
import torchDEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 初始化模型
model = BertModel(config).to(DEVICE)
print(model.embeddings.position_embeddings)
embeddings层变大了,不需要重新训练这一层吗?
这一行给了1500是给了1500个位置,没有值,值是随机初始化的。
config.max_position_embeddings = 1500这会导致这个位置的编码不可靠,最终结果不理想、不稳定。所以我们要让修改后的ebeddings部分重新参与模型的训练过程中。
原先代码如下:
class Model(torch.nn.Module):def __init__(self):super().__init__()self.fc = torch.nn.Linear(768,2)def forward(self,input_ids,attention_mask,token_type_ids):#冻结主干网络权重with torch.no_grad():out = pretrained(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids)out = self.fc(out.last_hidden_state[:,0])out = out.softmax(dim=1)return out修改代码如下:
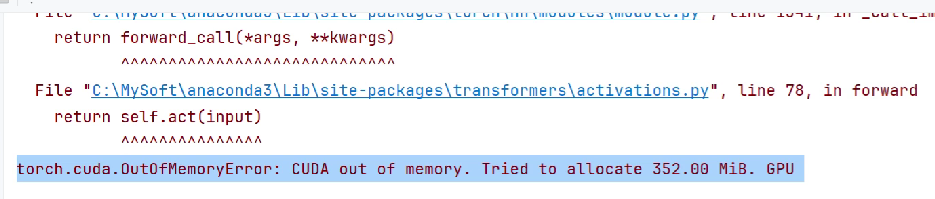
第一种,整个bert参与训练,这需要设备够大。
class Model(torch.nn.Module):def __init__(self):super().__init__()self.fc = torch.nn.Linear(768,2)def forward(self,input_ids,attention_mask,token_type_ids):# 调整模型的前向计算,让embeddings部分参与到模型的训练过程# out = pretrained(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids)out = self.fc(out.last_hidden_state[:,0])out = out.softmax(dim=1)return out不然可能会报错
第二种,只训练embeddings部分(性价比最高)。
class Model(torch.nn.Module):def __init__(self):super().__init__()self.fc = torch.nn.Linear(768,2)def forward(self,input_ids,attention_mask,token_type_ids):# 训练embeddings部分embeddings_output = pretrained.embeddings(input_ids=input_ids, token_type_ids=token_type_ids)# 防止出错(0、1类似的可能会被认为是int),都转换为float类型attention_mask = attention_mask.to(torch.float)# [N,1,1,sequence_length] 要求的形状attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)attention_mask = attention_mask.to(embeddings_output.dtype)# 冻结剩余部分不参与训练with torch.no_grad():encoder_output = pretrained(embeddings_output,attention_mask=attention_mask)out = self.fc(encoder_output.last_hidden_state[:,0])out = out.softmax(dim=1)return out