推荐系统学习笔记(十四)-粗排三塔模型
粗排 vs 精排
粗排是在精排之前进行快速初步筛选的操作,所以粗排和精排有存在一些区别:
| 粗排 | 精排 |
|---|---|
| 给几千篇笔记打分 | 给几百篇笔记打分 |
| 单次推理代价必须小 | 单次推理代价很大 |
| 预估的准确性不高 | 预估的准确性更高 |
精排模型 vs 双塔模型
回顾前面介绍的召回和排序中主要使用的两个模型:
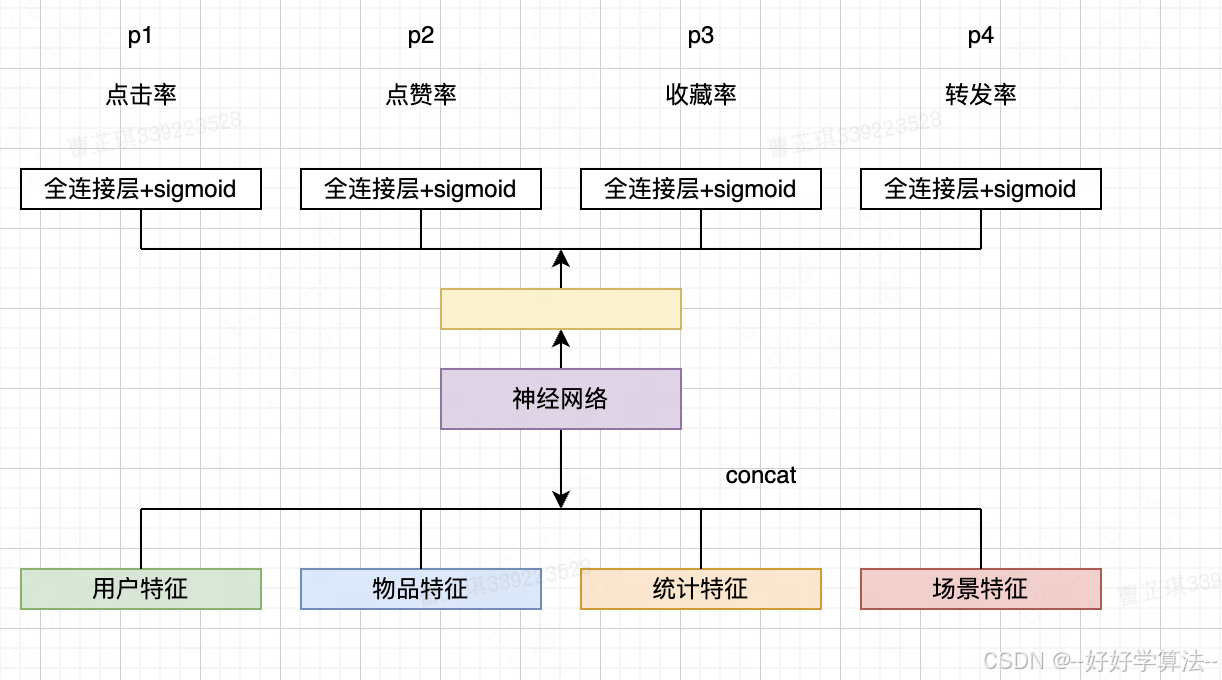
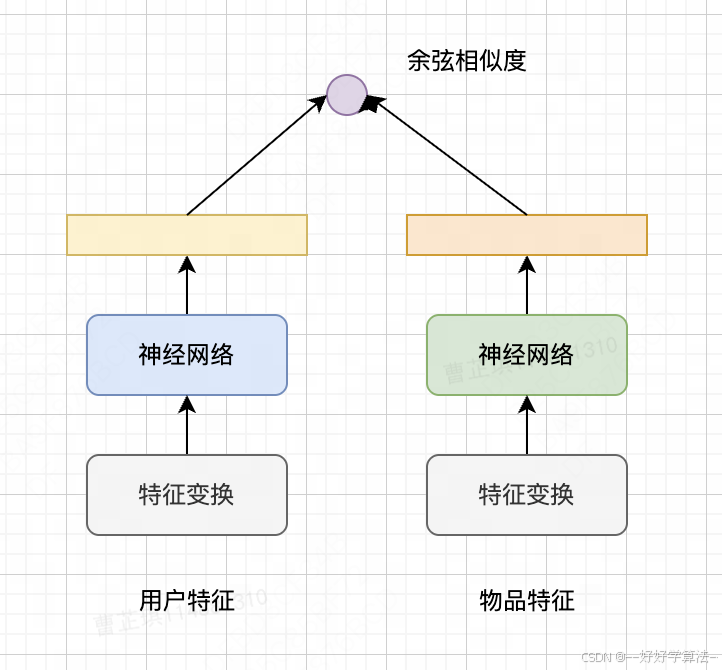
它们的区别在于:
| 精排模型 | 双塔模型 |
|---|---|
| 前期融合:先对所有特征做concatenation,再输入神经网络。 | 后期融合:把用户、物品特征分别输入不同的神经网络,不对用户、物品特征做融合。 |
| 线上推理代价大:如果有n篇候选笔记,整个大模型要做n次推理。 | 线上计算量小:用户塔只需要做一次线上推理,而物品表征通过线下计算事先存储在数据库中,物品塔在线上不做推理。 |
显然,双塔模型的预估准确性不如精排模型,后期融合适合快速做召回,前期融合更适合精准排序。
粗排的三塔模型
参考文献:
Zhe Wang et al. COLD: Towards the Next Generation of Pre-Ranking System. In DLP -
KDD , 2020。https://arxiv.org/pdf/2007.16122
工作中有一种常用的粗排模型,是三塔模型,效果介于精排和双塔模型之间,模型架构如下图所示:
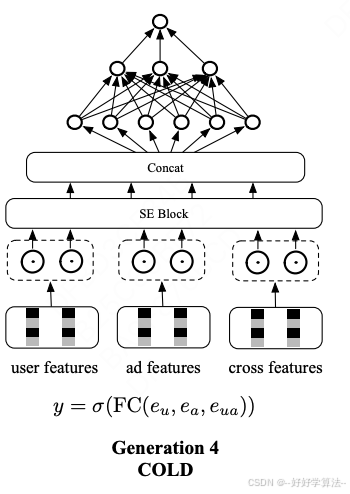
如图可见,实际上粗排模型的输出、训练与精排完全一致,主要区别在于下面的三个塔,该模型介于前期融合和后期融合之间。这个模型的特点在于:
1. 只有一个用户,用户塔只用做一次推理。因此即使用户塔很大,总计算量也不大。
2. 有 n 个物品,理论上物品塔需要做 n 次推理。所以需要缓存物品塔的输出向量,避免绝大部分推理。
3. 交叉塔的输入(统计特征等)动态变化,缓存不可行。而有 n 个物品,交叉塔必须要做 n 次推理,所以交叉塔必须要小。
而在模型的上层,有 n 个物品必须要做 n 次推理。上层推理的计算量要高于交叉塔,也是粗排的大部分计算量所在。因此,三塔模型的推理:
1. 从多个数据源取特征:
(1)1 个用户的画像、统计特征;
(2)n 个物品的画像、统计特征。
2. 用户塔:只做一次推理。
3. 物品塔:未命中缓存时需要做推理。
4. 交叉塔:必须做 n 次推理。
5.上层网络做 n 次推理,给 n 个物品打分。