深度学习----由手写数字识别案例来认识PyTorch框架
一、深度学习常用的框架
常用的有:Caffe,TensorFlow,Keras,PyTorc
- Caffe:配置文件搭模型方便, 但安装麻烦、缺新模型且更新停滞。
- TensorFlow:Google 开发,1.x 版本代码冗余难上手,2.x 版本因收购 Keras 不兼容 1.x 。
- Keras:基于 TensorFlow 封装,能简化代码难度 。
- PyTorch:Facebook(现 Meta )开发,上手易,可直接套用模板 。
二、pytorch及cuda的配置
注意:自己需要下载的版本,还有要注意是cpu还是gpu
pytorch安装及配置-CSDN博客
CUDA安装教程(包括cuDNN的教程)一个博客带你了解所有问题-CSDN博客
三、PyTorch框架认识
现在主流的框架是PyTorch框架,所以这里详细介绍一下
PyTorch 是由 Meta(原 Facebook)开发并维护的开源深度学习框架,以易用性和灵活性著称,在深度学习领域应用广泛,尤其受研究人员和开发者青睐,以下是对它的详细介绍:
核心特性
- 动态计算图:PyTorch 采用动态计算图机制,计算图在运行时根据前向传播的实际需求即时构建 ,允许用户随时修改计算图结构。例如在处理循环神经网络中不同序列长度的数据时,能灵活调整模型。相比之下,传统框架(如早期版本的 TensorFlow )使用静态计算图,需预先定义完整模型结构,调试难度较大。
- 自动微分:通过 torch.autograd 模块实现,自动跟踪张量运算,自动计算梯度,无需开发者手动推导复杂导数公式,这使得反向传播算法的实现更为高效,让开发者更专注于模型设计本身。
- Pythonic 设计:语法与 NumPy 高度兼容,熟悉 NumPy 的用户能快速上手。并且天然支持 Python 生态工具,比如可以使用 Pandas 加载数据再转为 PyTorch 张量进行处理,利用 Matplotlib 可视化训练过程等,降低了学习门槛。
- 灵活性和扩展性:支持用户轻松自定义模型、损失函数和优化器,比如开发者可以使用 Python 强大的功能实现自定义层、自定义数据加载器等复杂逻辑。同时,它支持 GPU 和多 GPU 训练,通过简单 API 调用就能将计算任务分配到 GPU 上,大幅提升训练速度 。
主要模块
- torch:PyTorch 的核心模块,提供张量运算、随机数生成等基本功能,是其他模块的基础。张量是 PyTorch 中数据的基本结构,类似于 NumPy 数组,但支持 GPU 计算。
- torch.autograd:自动微分模块,用于自动计算梯度,在神经网络反向传播中发挥关键作用。
- torch.nn:神经网络模块,将神经网络抽象为可堆叠的组件,提供各种神经网络层(如全连接层 nn.Linear、卷积层 nn.Conv2d、循环层 nn.LSTM )、激活函数、损失函数等,方便开发者构建神经网络模型。
- torch.optim:优化模块,提供多种优化算法,如随机梯度下降(SGD)、Adam 等,用于神经网络训练过程中对模型参数进行优化更新。
- torch.utils.data:数据处理模块,包含 Dataset 和 DataLoader 等类,用于处理数据集并进行批量加载,方便数据的读取和预处理。
- torch.cuda:GPU 支持模块,提供与 GPU 相关的操作,能将张量移动到 GPU 上以加速计算。
- torchvision:图像处理扩展库,专为计算机视觉任务提供数据集(如 MNIST、CIFAR - 10 等)、预训练模型(如 ResNet、VGG 等)和图像预处理工具。
- torchtext:自然语言处理扩展库,提供文本数据集、词向量和常见的文本处理工具,助力自然语言处理任务的开发。
- torchaudio:音频处理扩展库,用于音频数据的加载、转换和特征提取。
- torch.jit:模型序列化与部署模块,有助于将 PyTorch 模型部署到不同环境中。
三、优化器的介绍
优化器用于调整深度学习模型参数,以最小化损失函数,以下是常见优化器分类及特点:
一、基础梯度下降类
1. 批量梯度下降法(Batch Gradient Descent, BGD)
- 计算方式:用全样本数据计算梯度,如
batch_size=64时,基于 64 个样本算梯度。 - 优点:收敛次数少,模型训练相对稳定,易趋近全局最优。
- 缺点:每次迭代需加载所有数据,内存占用大、计算耗时,不适大数据集。
2. 随机梯度下降法(Stochastic Gradient Descent, SGD)
- 计算方式:从样本(如 64 个)中随机选一组训练,依此梯度更新参数。
- 优点:训练速度快,无需加载全量数据,适合在线学习场景。
- 缺点:梯度更新波动大,可能陷入局部最优,收敛路径不稳定。
3. 小批量梯度下降法(Mini-batch Gradient Descent)
- 计算方式:将训练集分成小批量(如每次选 32/64 个样本 ),用小批量数据算误差、更新参数。
- 特点:结合 BGD 和 SGD 优势,平衡计算效率与收敛稳定性,是深度学习常用策略。
二、改进优化算法
1. 自适应矩估计(Adaptive Moment Estimation, Adam)
- 特点:自适应调整每个参数的学习率,结合一阶动量(梯度均值)和二阶动量(梯度平方均值 ),收敛快、鲁棒性好,适多种场景,尤其非凸优化任务。
2. 动量梯度下降(Momentum Gradient Descent)
- 特点:引入 “动量” 概念,累加历史梯度方向,加速梯度下降。像物理中物体惯性,能冲过局部极小值,加快收敛,适合处理含噪声、平坦区域的损失函数。
3. AdaGrad
- 特点:为不同参数自适应调整学习率,频繁更新参数的学习率衰减快,适合稀疏数据场景(如文本分类 ),但易因学习率过早衰减导致训练停滞。
4. RMSprop
- 特点:改进 AdaGrad,只累加近期梯度平方,避免学习率过快下降,更适合非凸优化,在深度学习中常作自适应学习率优化器基础。
5. AdamW
- 特点:对 Adam 增加权重衰减正则化,优化模型泛化能力,在大模型训练(如 Transformer )中,能有效缓解过拟合。
6. Adadelta
- 特点:无需手动设置初始学习率,基于梯度的二阶矩动态调整,鲁棒性强,减少对学习率敏感问题,适合不同规模数据集训练。
四、激活函数
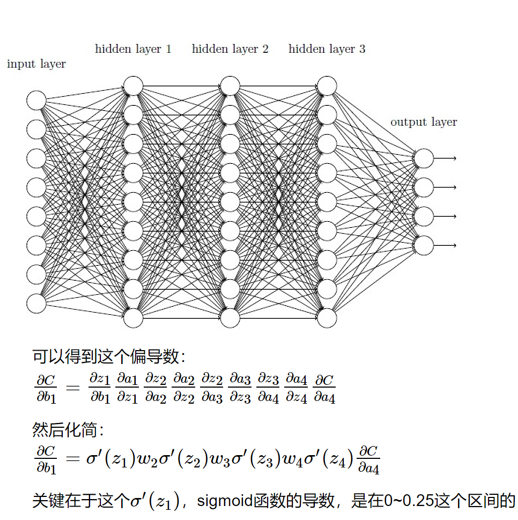
一、核心问题:梯度消失 & 梯度爆炸
深度神经网络训练时,反向传播需计算梯度(参数更新的依据),但会因激活函数导数连乘产生问题:
- 梯度消失:若激活函数导数大多
<1(如 sigmoid 导数在0~0.25),连乘后梯度→0,导致深层网络参数几乎不更新,模型难以训练。 - 梯度爆炸:若激活函数导数大多
>1,连乘后梯度→无穷大,导致参数更新幅度过大,模型训练不稳定。
二、根源:激活函数的「导数特性」
以 sigmoid 激活函数为例,其导数 σ’(z) 最大值仅 0.25(区间 0~0.25)。深层网络反向传播时,梯度需通过 σ’(z₁)×w₂×σ’(z₂)×w₃×… 连乘传递,一旦层数多,梯度极易因连乘「指数级衰减 / 膨胀」,引发消失或爆炸。
三、解决方案:换用更优激活函数
为缓解梯度问题,避免用 sigmoid,改用导数更稳定的激活函数,常见替代方案:
- ReLU:导数为
1(正区间),无梯度消失风险,计算高效,是深度学习标配。 - tanh:导数比 sigmoid 更接近
1(但仍<1),效果优于 sigmoid 但不如 ReLU。 - P-ReLU、R-ReLU:ReLU 变种,解决 ReLU 「死亡神经元」问题,导数更灵活。
- Maxout:动态选最优激活值,导数稳定,但计算成本略高。

五、深度学习的手写数字识别
1、导入相关库以及获取数据集
import torch
from torch import nn#导入神经网络模块
from torch.utils.data import DataLoader#数据包管理工具,打包数据
from torchvision import datasets#封装了很多与图像相关的模型,和数据集
from torchvision.transforms import ToTensor#将其他数据类型转化为张量train_data=datasets.MNIST(root='data',train=True,#是否读取下载后数据中的训练集download=True,#如果之前下载过则不用下载transform=ToTensor()
)
test_data=datasets.MNIST(root='data',train=False,download=True,transform=ToTensor()
)2、数据打包与加载
Data_loader用于将数据集分批次打包,需要注意的是数据实际加载发生在for循环遍历Data_loader时(每次循环从硬盘加载指定数量(如64张图片)的数据),而非初始化阶段
train_loader=DataLoader(train_data,batch_size=64)
test_loader=DataLoader(test_data,batch_size=64)3、判断使用的设备
判断是不是使用cuda进行训练
device='cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu'
print(f'Using {device} device')4、神经网络构建(通过类的继承)
必须继承 nn.Module 类,并实现 __init__(初始化网络层)和 forward(定义数据流向)方法即前向传播。
nn.Flatten()创建一个展开对象,将输入图片展开为一维数据(如28*28=784)
通过nn.Linear()创建网络层,第一个参数是有多少信息传进来,第二个参数是当前本层神经元个数或有多少信息传出去
这里我们创建了两个隐藏层和一个输出层
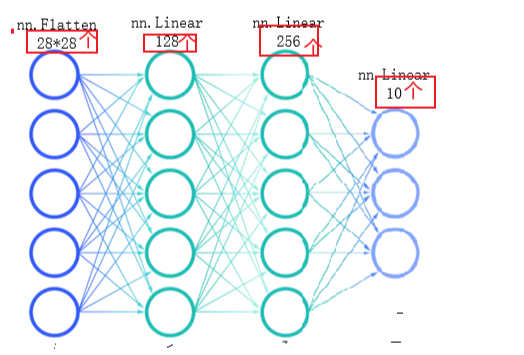
class NeuralNetwork(nn.Module):def __init__(self):super().__init__()self.flatten=nn.Flatten()#创建一个展开对象self.hidden1=nn.Linear(28*28,128)#第一个参数是有多少信息传进来,第二个参数是当前本层神经元个数或有多少信息传出去self.hidden2=nn.Linear(128,256)self.out=nn.Linear(256,10)def forward(self,x):#前向传播x=self.flatten(x)x=self.hidden1(x)x = torch.sigmoid(x)x=self.hidden2(x)x = torch.sigmoid(x)x=self.out(x)return x
model=NeuralNetwork().to(device)#把刚刚创建的模型传入device中
print(model)forward()方法不可改名,我们要明确数据的流动顺序(如 Flatten → Linear → 激活 → Linear → 输出)。最后一层通常不设激活函数,直接输出原始值
最后通过model=NeuralNetwork().to(device)把刚刚创建的模型传入device(gpu/cpu)中
注意:
self.flatten等为类属性,存储网络层对象(如nn.Flatten、nn.Linear的实例)。- 调用
forward时,数据依次通过各层对象执行计算。 - 网络结构可调整,但需确保参数一致性(如神经元凸起数量匹配即前后输入输出个数要匹配)。
5、损失函数和优化器
我们使用交叉熵损失函数来计算多分类问题的损失
使用SGD随机梯度下降来作为我们的优化器,传入模型参数和步长即学习率
loss_fn=nn.CrossEntropyLoss()
optimizer=torch.optim.SGD(model.parameters(),lr=0.01)#lr是学习率即步长,第一个参数是我们要训练的参数6、数据的加载与训练
自已定义一个train()方法
首先我们在训练前使用model.train()方法告诉模型我们要准备开始训练,赋予模型修改参数w的权限(测试时则需调用model.eval(),固定模型参数(ω)仅允许读取不允许修改,防止意外修改)
遍历data_loader循环读取数据,每次取出64张图片,由于数据与模型需要在同一个设备(CPU/GPU)上,所以我们通过X.to(device),y.to(device)实现数据迁移(如GPU训练时需将数据移至GPU)。
调用model的forward()方法完成前向传播,再将前向传播的结果和Y标签传入损失函数得到损失值
损失值为tensor类型
最后进行反向传播更新w值
-
优化器梯度清零(
zero_grad)。 -
反向更新计算出更新后的w值(
loss.backward)。 -
更新模型参数(
optimizer.step)。
通过item()方法将损失值转化为可读的float类型,我们每一百个批次打印一次损失值
def train(dataloader,model,loss_fn,optimizer):model.train()#告诉模型,准备开始训练batch_size_num=1for X,y in dataloader:X,y=X.to(device),y.to(device)#把训练数据和标签也传入cpu或gpu中pred=model.forward(X)loss=loss_fn(pred,y)optimizer.zero_grad()loss.backward()optimizer.step()loss_value=loss.item()if batch_size_num%100==0:print(f'loss:{loss_value:>7f} [number:{batch_size_num}]')batch_size_num+=1补充:
- 模型传入64张图片,每张图片维度为28x28(单通道)。训练时采用逐张图片处理,但计算机通过并行计算实现高效运行。
- 数据以矩阵形式处理,64张图片对应64个并行网络实例,GPU同时运行64个相同模型进行前向传播。
- Batch size的优势在于并行化计算,64个模型的输出结果通过累加平均计算损失值,并统一更新模型参数。
7、模型测试
自己定义一个test()方法
首先调用model.eval()方法告诉模型我们要开始测试了,停止对w的更新
通过len(dataloader.dataset)获取数据集的长度便于后面计算准确率
使用torch.no_grad()禁用梯度更新,减少内存占用
X,y还是需要传入到模型的设备中,继续前向传播得到结果和损失值,将损失值累加到一起最后计算平均损失
通过pred.argma(1)找出64组训练结果中每一组的结果(最大概率的)然后通过==y判断与测试集的标签是否相同,相同返回True,不同返回False,共返回64个,
再通过.type(torch.float)将结果转化为0,1,True则转化为1然后sum()计算总合,将每个correct累加起来这样我们就能知道我们总共对了多少,通过item()转化为可读的浮点类型
最后通过累加后的correct计算正确率
def test(dataloader,model,loss_fn):model.eval()#开始测试,停止更新wlen_data=len(dataloader.dataset)correct,num_batch=0,0loss_sum=0with torch.no_grad():for X,y in dataloader:X,y=X.to(device),y.to(device)pred=model.forward(X)loss_sum+=loss_fn(pred,y)correct+=(pred.argmax(1)==y).type(torch.float).sum().item()num_batch+=1correct/=len_dataloss_avg=loss_sum/num_batchprint(f'Accuracy:{100*correct}%\nLoss Avg:{loss_avg}')8、结果
调用train()和test()方法查看结果
train(train_loader, model, loss_fn, optimizer)
test(test_loader,model,loss_fn)
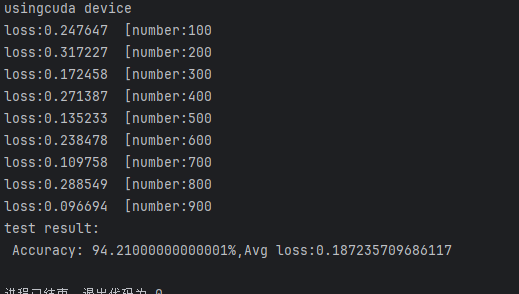
准确率太低,需要优化
9、模型优化
1.设置训练的次数epoch
如果我们不设置训练次数,那我们就相当于只将训练集的内容只训练了一次明显不够
可以通过for循环实现多次训练
for i in range(epochs):print(f'==========第{i+1}轮训练==============')train(train_loader, model, loss_fn, optimizer)print(f'第{i+1}轮训练结束')2.优化器改进
有以下的优化器
- 原使用随机梯度下降(SGD),建议改用自适应优化器(如Adam)。
- Adam优化器优势:
- 更快收敛(首轮损失值从2.0降至0.2)。
- 训练10轮后正确率从19%提升至96.81%。
- 学习率调整:
- 初始学习率0.01导致后期损失值震荡,改为0.005后正确率微升至97.5%。
- 学习率过大会阻碍模型到达极小值点。
optimizer=torch.optim.Adam(model.parameters(),lr=0.005)3.激活函数改进
- Sigmoid函数缺陷:
- 偏导数范围(0~0.25)导致深层网络梯度消失(连乘趋近于0)。
- 影响参数更新,造成训练停滞或震荡。
替代方案:ReLU(Rectified Linear Unit)函数。
- 优势:
- 计算简单(偏导数为0或1,避免梯度消失)。
- 非线性映射能力(小于零输出0,大于零线性输出)。
- 当前实验效果:
- 对浅层网络(如2层)影响有限,正确率未显著提升。
- 深层网络中推荐替换Sigmoid以避免梯度问题。
def forward(self,x):#前向传播x=self.flatten(x)x=self.hidden1(x)x=torch.relu(x)x=self.hidden2(x)x=torch.relu(x)x=self.out(x)return x10、优化后的代码
import torch
print(torch.__version__)import torch
from torch import nn#导入神经网络模块
from torch.utils.data import DataLoader#数据包管理工具,打包数据
from torchvision import datasets#封装了很多与图像相关的模型,和数据集
from torchvision.transforms import ToTensor#将其他数据类型转化为张量train_data=datasets.MNIST(root='data',train=True,#是否读取下载后数据中的训练集download=True,#如果之前下载过则不用下载transform=ToTensor()
)
test_data=datasets.MNIST(root='data',train=False,download=True,transform=ToTensor()
)train_loader=DataLoader(train_data,batch_size=64)
test_loader=DataLoader(test_data,batch_size=64)device='cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu'
print(f'Using {device} device')
#定义神经网络,通过类的继承
class NeuralNetwork(nn.Module):def __init__(self):super().__init__()self.flatten=nn.Flatten()#创建一个展开对象self.hidden1=nn.Linear(28*28,128)#第一个参数是有多少信息传进来,第二个参数是当前本层神经元个数或有多少信息传出去self.hidden2=nn.Linear(128,256)self.out=nn.Linear(256,10)def forward(self,x):#前向传播x=self.flatten(x)x=self.hidden1(x)# x=torch.sigmoid(x)#激活函数x=torch.relu(x)x=self.hidden2(x)x=torch.relu(x)x=self.out(x)return x
model=NeuralNetwork().to(device)#把刚刚创建的模型传入device中
print(model)def train(dataloader,model,loss_fn,optimizer):model.train()#告诉模型,准备开始训练batch_size_num=1for X,y in dataloader:X,y=X.to(device),y.to(device)#把训练数据和标签也传入cpu或gpu中pred=model.forward(X)loss=loss_fn(pred,y)optimizer.zero_grad()loss.backward()optimizer.step()loss_value=loss.item()if batch_size_num%100==0:print(f'loss:{loss_value:>7f} [number:{batch_size_num}]')batch_size_num+=1def test(dataloader,model,loss_fn):model.eval()#开始测试,停止更新wlen_data=len(dataloader.dataset)correct,num_batch=0,0loss_sum=0with torch.no_grad():for X,y in dataloader:X,y=X.to(device),y.to(device)pred=model.forward(X)loss_sum+=loss_fn(pred,y)correct+=(pred.argmax(1)==y).type(torch.float).sum().item()num_batch+=1correct/=len_dataloss_avg=loss_sum/num_batchprint(f'Accuracy:{100*correct}%\nLoss Avg:{loss_avg}')
loss_fn=nn.CrossEntropyLoss()
# optimizer=torch.optim.SGD(model.parameters(),lr=0.01)#lr是学习率即步长,第一个参数是我们要训练的参数
optimizer=torch.optim.Adam(model.parameters(),lr=0.005)epochs=10
for i in range(epochs):print(f'==========第{i+1}轮训练==============')train(train_loader, model, loss_fn, optimizer)print(f'第{i+1}轮训练结束')
test(test_loader,model,loss_fn)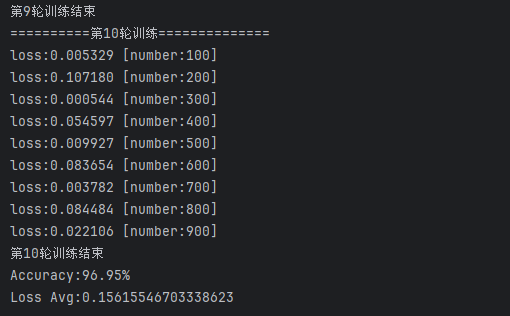
六、x=self.hidden1(x)对象后直接传参说明
在上面代码中有一些代码如
x=self.flatten(x)
x=self.hidden1(x)
x=self.hidden2(x)
x=self.out(x)
loss=loss_fn(pred,y)
中都是直接对象后直接加参数这是因为继承自 nn.Module 的类可以省略 forward,直接通过对象调用(如 model(x) 等价于 model.forward(x))。
nn.Flatten、nn.Linear等层均继承自nn.Module,因此它们的forward方法可省略调用。- 交叉熵损失函数(
nn.CrossEntropyLoss)同样继承自nn.Module,支持直接调用(如loss(pred, target))。