构建AI智能体:十四、从“计算”到“洞察”:AI大模型如何让时间序列数据“开口说话”
一、我需要学习“时间序列”吗
今天主题是“时间序列模型”,在开始之前我们先讨论一下学习大模型需要了解时间序列吗,首先要看我们的目标,学习大模型也必须也要有自己的目标。
应用型工程师:
如果想成为一名应用大模型的专业工程师,比如构建一个智能聊天客服机器人、开发一个文档总结工具、创建一个代码生成助手,那么,不需要深入研究时间序列模型,此时你的核心技能应该是:
强化提示词工程:如何设计问题才能从大模型得到最佳答案;
数据处理:如何准备和清洗用于微调的文本数据;
但了解后会更强大,理解时间序列能让你看到一个更广阔的世界,如果你的项目正好需要分析和预测时间数据(比如分析用户活跃度的趋势、预测产品未来销量),或者给大模型喂数据时,经常需要构造具有时间上下文的信息,如果你有时间序列的思维,你会更清楚如何构建这些数据。基于此,对于应用者,时间序列不是入门门槛,但它是一个能让你从“会用”到“用好”、“用精”的关键进阶技能。
核心算法研究者:
如果你的目标是深入大模型的原理,甚至参与训练和创造新的大模型,那么时间序列的知识就变得至关重要。
大模型处理的就是“序列”:大模型的根本任务是处理序列信息,无论是文本序列、代码序列,还是图像切块后的序列。理解ARIMA、RNN、LSTM如何捕捉序列中的依赖关系,会让你更深刻地理解Transformer为什么这么设计。
多模态趋势:大模型不仅仅是语言模型,而是多模态模型。这意味着它们要统一处理文本、图像、音频、视频等各种数据。音频和视频本质上是时间序列!音频是声波随时间的变化,视频是图像帧随时间的变化。要让大模型真正理解和生成流畅的语音和视频,就必须拥有强大的时间序列建模能力。
前沿探索:一个非常前沿的方向就是让大模型直接处理数值时间序列数据(比如股票价格、传感器数据)。研究人员正在尝试将时间序列数据像文本一样进行“分词”,然后训练大模型来理解和预测它们。如果你不懂时间序列,根本无法进入这个领域。
二、什么是时间序列
时间序列数据是按时间顺序索引的一系列数据点。它最大的特点是数据点之间存在依赖关系,即“时间上下文”至关重要。这与传统的独立同分布数据截然不同。从每日的股票收盘价、每小时的气温变化,到每分钟的网站点击流,时间序列无处不在。分析它的目的主要有两个:描述历史规律(如季节性波动)和预测未来值(如预测明日销售额)。
用一句话概括:时间序列模型,就是一个“看过去、猜未来”的数学工具。它的核心工作就是:从历史数据中找出规律,然后用这个规律来预测未来会发生什么。
一个简单的例子:卖冰淇淋的小店,想象一下,你开了一家冰淇淋店。
你的“历史数据”是:过去几年,每天卖了多少冰淇淋。
数据里的“规律”是:
趋势:生意越来越好,每年都比前一年多卖一些。(长期向上)
季节性:每年夏天卖的都比冬天多得多;每个周末卖的都比周一到周五多。(周期性波动)
突发噪音:突然有一天卖得特别差,因为那天下暴雨了。(无法预测的偶然事件)
你现在遇到的“问题”是:下个月我该进多少货?进多了会化掉,进少了又没钱赚。
这时,时间序列模型就可以登场了!它会做两件事:
分析历史:模型会像一位精明的老师傅,仔细研究你过去几年的销售记录,把上面提到的“趋势”和“季节性”(夏天/周末)这些稳定规律都总结出来。
预测未来:老师傅根据总结出的规律,再看看下个月的日历(有多少个周末?天气是不是夏天?),然后告诉你:“老板,根据以往经验,下个月大概能卖5000盒冰淇淋,你就按这个量进货吧!”
当然,它没法预测“下暴雨”这种偶然事件,但它能帮你做出一个基于历史数据的最优猜测,这远比你自己凭感觉瞎猜要准确得多!
三、时间序列的核心概念与预处理
组成成分:
趋势:数据长期变化的总体方向(上升、下降或平稳)。
季节性:在固定周期(如一天、一年)内重复出现的规律波动。
周期性:非固定频率的波动(如经济周期)。
残差:去除趋势、季节性和周期后剩下的随机“噪音”。
平稳性:一个平稳的时间序列其统计特性(如均值、方差)不随时间变化。这是ARIMA等许多模型的基本要求。Augmented Dickey-Fuller (ADF) 检验是一种常用的统计检验方法,其原假设是“序列非平稳”。如果p值小于显著性水平(如0.05),则拒绝原假设,认为序列平稳。
预处理:差分(用当前值减去前一时刻的值)是消除趋势和季节性的最强有力工具,常用于将非平稳序列转换为平稳序列。
四、时间序列模型家族
1. 平滑法
平滑法适合做短期预测,概念简单。Holt-Winters 模型通过三种成分(水平、趋势、季节)的平滑方程,能有效地处理具有趋势和季节性的数据。
示例:使用Holt-Winters模型进行季节性分解与预测
目标:分析一段具有明显趋势和季节性的模拟月度销售数据,并进行预测。
# 导入必要的库
import pandas as pd # 用于数据处理和操作
import numpy as np # 用于数值计算和数组操作
import matplotlib.pyplot as plt # 用于数据可视化
from statsmodels.tsa.holtwinters import ExponentialSmoothing # 导入Holt-Winters模型
from statsmodels.tsa.seasonal import seasonal_decompose # 导入季节性分解工具
# 1. 创建模拟数据(包含趋势 + 季节性 + 随机噪声)
# 生成100个月度日期范围,从2018-01-01开始
dates = pd.date_range(start='2018-01-01', periods=100, freq='M')
# 创建线性趋势成分:从50逐渐增加到150
trend = np.linspace(50, 150, 100)
# 创建季节性成分:使用正弦函数模拟周期性变化(4个完整周期)
seasonality = 10 * np.sin(np.linspace(0, 4*np.pi, 100))
# 创建随机噪声成分:均值为0,标准差为5的正态分布随机数
noise = np.random.normal(0, 5, 100)
# 将三个成分相加形成最终的时间序列
sales = trend + seasonality + noise
# 将数据转换为Pandas Series对象,并指定日期索引
ts = pd.Series(sales, index=dates)
# 2. 可视化 & 季节性分解
# 使用加法模型对时间序列进行分解,得到趋势、季节性和残差成分
result = seasonal_decompose(ts, model='additive')
# 绘制分解后的各个成分图表
result.plot()
# 显示图形
plt.show()
# 3. 拟合Holt-Winters模型(使用加法趋势和加法季节性)
# 创建指数平滑模型,指定趋势和季节性类型为加法模型,季节性周期为12个月
model = ExponentialSmoothing(ts, trend='add', # 加法趋势seasonal='add', # 加法季节性seasonal_periods=12) # 一年12个月为一个季节性周期
# 使用数据拟合模型
model_fit = model.fit()
# 4. 进行未来12步(一年)预测
# 使用拟合好的模型预测未来12个时间点的值
forecast = model_fit.forecast(12)
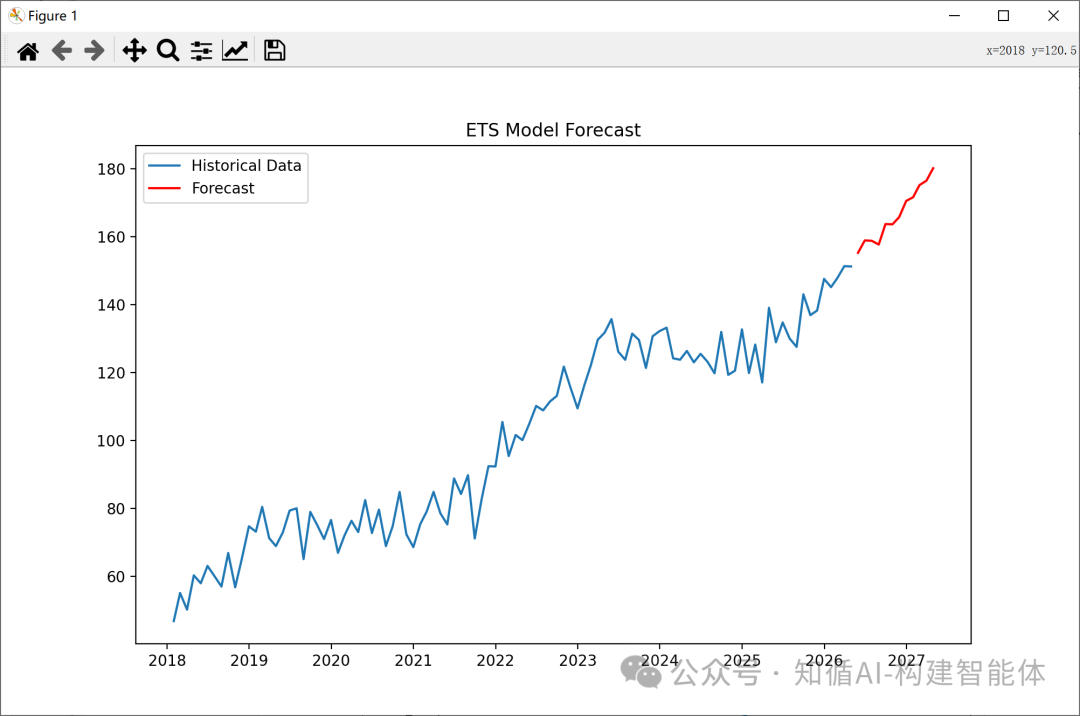
# 5. 绘图展示历史数据和预测结果
# 创建一个新的图形,设置图形大小
plt.figure(figsize=(10, 6))
# 绘制历史数据曲线,添加标签
plt.plot(ts, label='Historical Data')
# 绘制预测数据曲线,使用红色并添加标签
plt.plot(forecast, label='Forecast', color='red')
# 添加图例
plt.legend()
# 添加标题
plt.title('ETS Model Forecast')
# 显示图形
plt.show()代码分解:
数据生成部分:
trend:线性趋势,模拟数据的长期变化方向
seasonality: 季节性成分,使用正弦函数模拟周期性波动
noise:随机噪声,模拟现实世界中的不可预测因素
我们创建了一个包含三种成分的模拟时间序列:
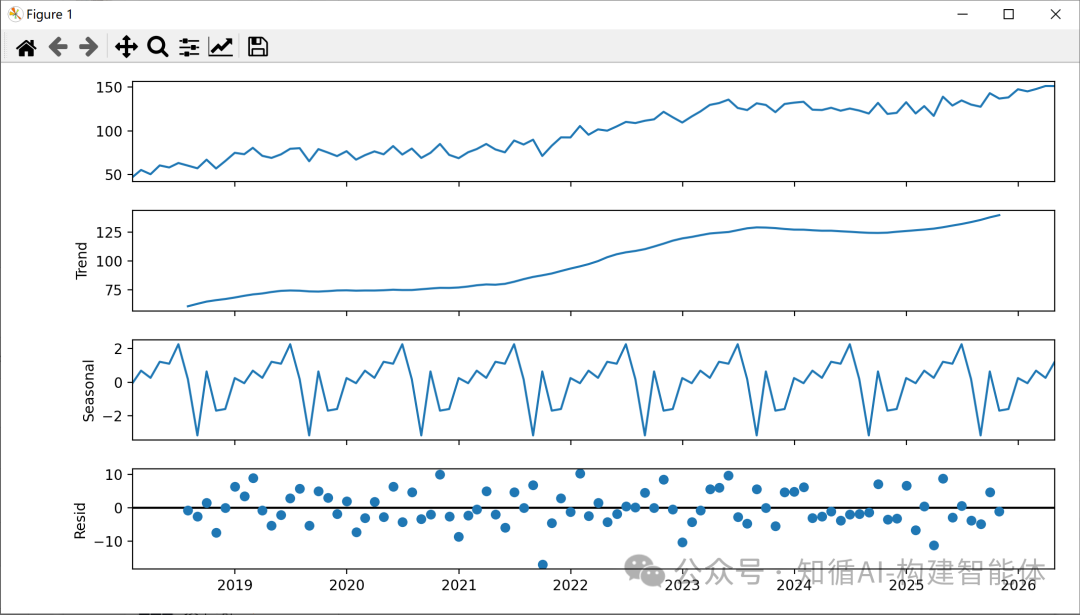
季节性分解:
趋势(Trend):数据的长期方向
季节性(Seasonal):固定周期的重复模式
残差(Residual):去除趋势和季节性后的随机波动
seasonal_decompose 函数将时间序列分解为三个组成部分:
Holt-Winters模型:
使用指数平滑方法,特别适合具有趋势和季节性的时间序列
trend='add' 和 seasonal='add' 指定使用加法模型(而不是乘法模型)
seasonal_periods=12 指定季节性周期为12个月(一年)
预测与可视化:
使用拟合好的模型预测未来12个月的值
将历史数据和预测结果绘制在同一图表中,便于比较
这段代码完整展示了如何使用Holt-Winters模型进行时间序列分析和预测,从数据生成到模型拟合再到结果可视化的全过程。
根据销量数据进行预测:
那么,Holt-Winters模型中的Trend、Seasonal、Resid该怎么理解呢?
通过直观的分析冰淇淋销量的示例来了解,假设你有一家冰淇淋店,过去三年的每日销量就是你的时间序列数据。Holt-Winters模型就像一个精明的老师傅,他会把销量分解成三个部分来看:
1. Trend - 趋势:代表“大方向”的“战略家”
它是数据在较长时期内表现出来的总体运动方向。它忽略了短期的波动,只看大局。
在冰淇淋例子中:
上升趋势:因为你的店口碑很好,附近小区入住的人也越来越多了,所以整体上,生意一年比一年好。今年的平均销量比去年高,明年的平均销量预计又会比今年高。这个“逐年变好”的大方向,就是上升趋势。
下降趋势:如果对面新开了一家更大的竞争对手,导致你的顾客流失,销量可能呈现下降趋势。
平稳趋势:如果市场稳定,销量每年都差不多,那就是平稳趋势(没有明显趋势)。
一句话理解Trend: “我们的生意从长期来看,是在变好、变差,还是维持原样?”
2. Seasonal - 季节性:代表“周期性规律”的“节律大师”
它是在固定周期内重复出现的、规律性的波动。这个周期是已知且固定的。
在冰淇淋例子中:
年度季节性:毫无疑问,每年夏天的销量都会达到顶峰,而每年冬天的销量都会跌入谷底。这个规律年年如此,非常稳定。
每周季节性:即使在夏天,每周的周末销量也会比工作日更高。
季节性成分就是把这些固定的、可预测的周期性规律量化出来。 模型会学习到:“哦,在7月份,销量通常会比年平均水平高出200%;而在1月份,销量通常会比年平均水平低60%。”
一句话理解Seasonal: “在一年四季、一周七天里,我们的销量有哪些雷打不动的规律?”
3. Resid - 残差:代表“随机噪音”的“意外事件”
它是在你剥离了趋势和季节性这两个主要规律后,剩下的、无法被解释的部分。它完全是随机的、不可预测的“噪音”。
在冰淇淋例子中:
本来模型预测今天能卖100个冰淇淋(基于“上升趋势”和“夏天”这个季节性)。
但是,今天突然下了一场暴雨,导致实际只卖了30个。
又或者,今天突然有个公司跑来团建,一口气买了200个,导致销量远超预测。
这场暴雨和这个团建订单,就是残差。模型无法提前预测这种突发性的单一事件。
一句话理解Resid: “在剔除了所有长期规律和周期规律后,剩下的纯粹运气和意外成分。” 一个理想的模型,其残差应该是完全随机的,没有任何模式可言。如果残差还有模式,说明有规律没被模型捕捉到。
总结与联想
成分 | 角色 | 冰淇淋例子 | 关键特点 |
Trend (趋势) | 战略家 | 生意逐年变好 | 看长期大方向 |
Seasonal (季节性) | 节律大师 | 夏天旺,冬天淡;周末好,周中差 | 固定的周期规律 |
Resid (残差) | 意外事件 | 某天突然下暴雨或来了个大订单 | 完全随机,无法预测 |
所以,Holt-Winters模型就是在做一件事:
从历史数据中,把这“三重人格”——趋势、季节性、残差——一一剥离出来。然后,它把“趋势”和“季节性”这两个有规律的成分投射到未来,从而得到对未来的预测。 而“残差”部分,因为无法预测,就被丢弃了。
2. ARIMA模型
ARIMA模型这是经典方法中的核心和难点。
AR (AutoRegressive - 自回归): “我认为,未来的数据和过去的数据有关系。” 比如,过去几天卖得好,明天可能也会卖得好。他会用一个公式来描述“过去7天”对“明天”的影响有多大。
I (Integrated - 积分): 这是个“稳定器”。他发现如果数据一直上升(有趋势),就很难预测。所以他先把数据做差分处理。
差分:今天销量 - 昨天销量 = 一个增长值。这样就把“上升趋势”转换成了“在零附近波动”的稳定数据,就好预测多了。
MA (Moving Average - 移动平均): “我觉得,未来的数据和过去的预测误差也有关系。” 比如,我昨天预测卖了100个,结果只卖了90个,差了10个。这个“误差”信息对修正明天的预测也有帮助。
所以,ARIMA就是一个既考虑过去的数据,又考虑过去的误差,还先把数据变稳定的综合型侦探。他的升级版叫SARIMA,额外擅长处理季节性问题(比如冰淇淋夏天的销量规律)。
ARIMA模型就是三者的结合,记为 ARIMA(p, d, q)。SARIMA 在此基础上增加了对季节性的建模参数 (P, D, Q, S),其中S是季节周期。
示例:通过ARIMA模型对时间序列进行建模和预测
# 使用ARMA模型进行时间序列预测
import pandas as pd # 数据处理库
import matplotlib.pyplot as plt # 绘图库
import statsmodels.api as sm # 统计模型库
# 使用新的ARIMA模块替代已弃用的ARMA(ARIMA(p,0,q)等价于ARMA(p,q))
from statsmodels.tsa.arima.model import ARIMA # ARIMA模型
from statsmodels.graphics.api import qqplot # Q-Q图绘制工具
# 创建时间序列数据(这里是一组示例数据)
data = [3821, 4236, 3758, 6783, 4664, 2589, 2538, 3542, 4626, 5886, 6233, 4199, 3561, 2335, 5636, 3524,
4327, 6064, 3912, 1356, 4305, 4379, 4592, 4233, 4281, 1613, 1233, 4514, 3431, 2159, 2322, 4239, 4733,
2268, 5397, 5821, 6115, 6631, 6474, 4134, 2728, 5753, 7130, 7860, 6991, 7499, 5301, 2808, 6755, 6658,
6944, 6372, 8380, 7366, 6352, 8333, 8281, 11548, 10823, 13642, 9973, 6723, 13416, 12205, 13942, 9590,
11693, 9276, 6519, 6863, 8237, 10122, 8646, 9749, 5346, 4836, 9806, 7502, 9387, 11078, 9832, 6886, 4285,
8351, 9725, 11844, 12387, 10666, 7072, 6429]
# 将数据转换为Pandas Series对象,便于时间序列分析
data = pd.Series(data)
# 为数据创建时间索引(从1901年到1990年,共90个年份)
data_index = sm.tsa.datetools.dates_from_range('1901','1990')
#print(data_index) # 可以打印查看生成的时间索引
# 将时间索引分配给数据
data.index = pd.Index(data_index)
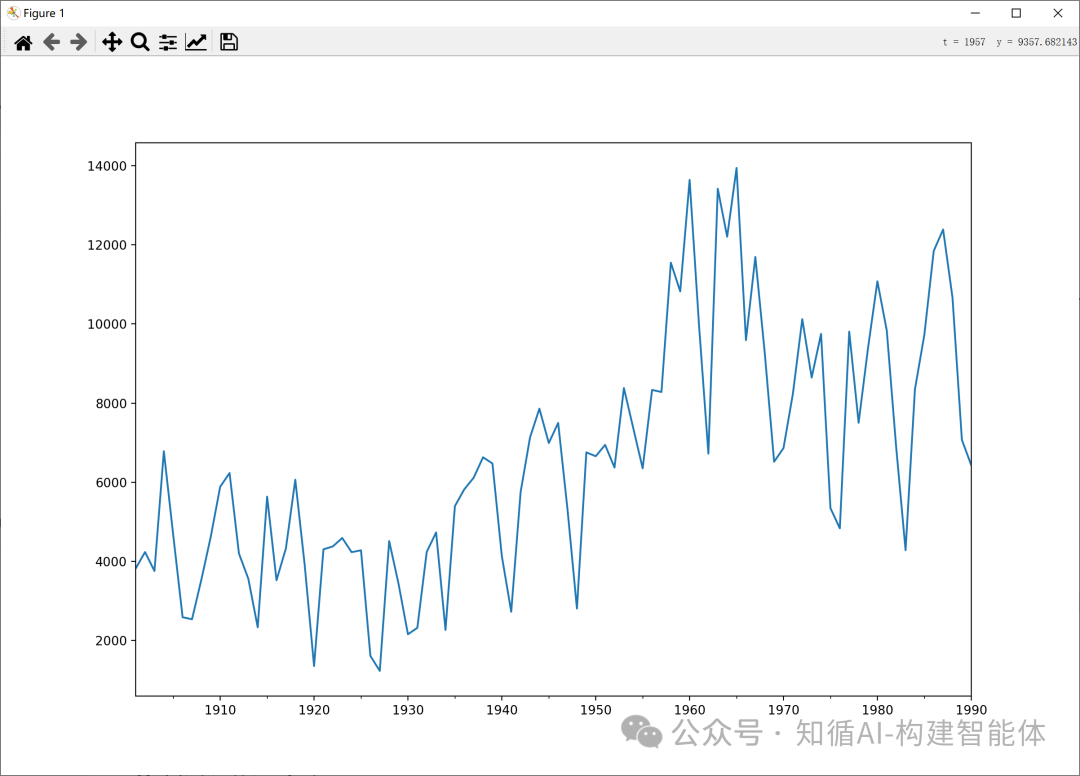
# 绘制原始数据图,设置图形大小
data.plot(figsize=(12,8))
plt.title('Original Time Series Data (1901-1990)') # 添加标题
plt.ylabel('Value') # 添加y轴标签
plt.xlabel('Year') # 添加x轴标签
plt.show() # 显示图形
# 创建ARIMA模型,使用order=(7,0,0)表示ARMA(7,0)模型
# 参数说明:p=7(自回归阶数), d=0(差分阶数), q=0(移动平均阶数)
arma = ARIMA(data, order=(7,0,0)).fit() # 拟合模型
# 打印模型的AIC值(赤池信息准则,用于模型选择,越小越好)
print('AIC: %0.4lf' %arma.aic)
# 使用拟合好的模型进行预测
# 预测时间范围:从1990年到2000年(共11个时间点)
predict_y = arma.predict(start='1990', end='2000')
# 绘制预测结果
fig, ax = plt.subplots(figsize=(12, 8)) # 创建图形和坐标轴
ax = data.loc['1901':].plot(ax=ax) # 绘制1901年至今的原始数据
predict_y.plot(ax=ax) # 在同一坐标轴上绘制预测值
plt.title('ARMA(7,0) Model Forecast') # 添加标题
plt.ylabel('Value') # 添加y轴标签
plt.xlabel('Year') # 添加x轴标签
plt.legend(['Actual Data', 'Forecast']) # 添加图例
plt.show() # 显示图形代码说明:
ARMA模型简介:
ARMA(自回归移动平均)模型是时间序列分析中的经典模型,由AR(自回归)和MA(移动平均)两部分组成
ARIMA(p,0,q)等价于ARMA(p,q),其中d=0表示不需要进行差分处理
模型参数选择:
代码中使用order=(7,0,0)表示AR(7)模型(只有自回归部分,没有移动平均部分)
在实际应用中,通常需要通过ACF和PACF图或信息准则(如AIC)来确定最佳的p和q值
模型评估:
AIC(Akaike Information Criterion)用于模型选择,值越小表示模型拟合越好
在实际分析中,还应检查残差是否符合白噪声假设(可以使用QQ图或Ljung-Box检验)
预测可视化:
代码将原始数据与预测结果绘制在同一图表中,便于直观比较
预测区间从1990年到2000年,展示了模型对未来值的预测能力
这段代码展示了如何使用ARMA模型进行时间序列分析和预测的基本流程,包括数据准备、模型拟合、评估和预测可视化。
模型训练:
结果展示:
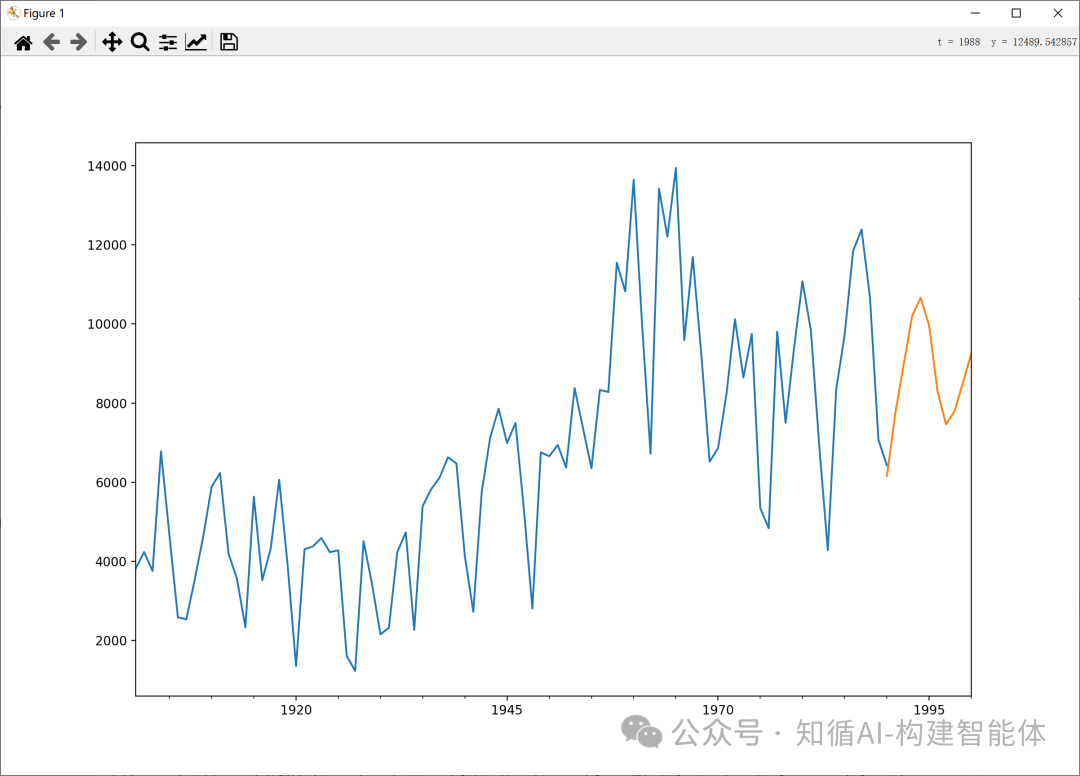
AIC: 1616.0337 注意:声明使用ARIMA模型(其中I(0)表示不使用差分,因此实际上是ARMA模型)对时间序列进行建模和预测;
重点:
示例中的模型的参数order=(7,0,0)是怎么定义的,为什么是(7,0,0),而不是其他呢,这里的AIC值就起到了关键的作用,我们把参数值调整为(7,0,7) 试试,首先看看预测结果产生了明显的偏差,同时AIC值也明显变大;AIC相对更小,误差则会更小;
AIC: 1633.3992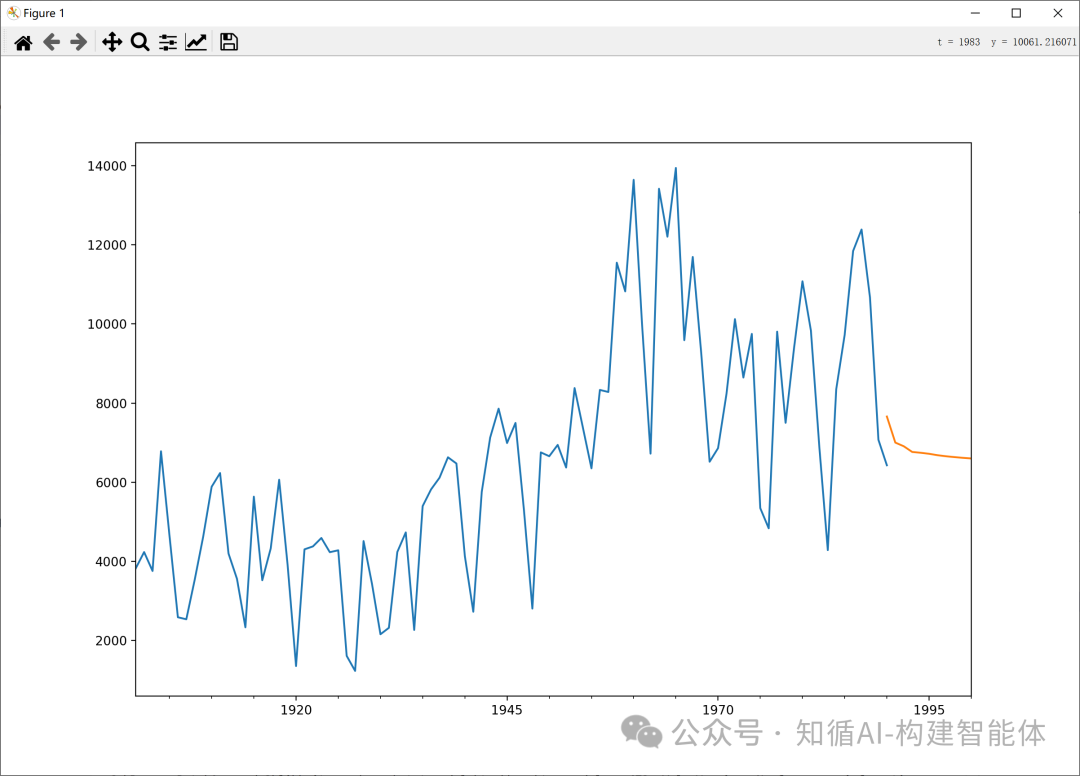
示例:沪市指数预测(最优参数训练)
使用ARMA工具对沪市指数进行预测:
•第一步,数据加载&探索
按照不同的时间尺度(天,月,季度,年)可以将数据压缩,得到不同尺度的数据,然后做可视化呈现。
df_month = df.resample('M').mean()
•第二步,模型选择&训练,在给定范围内,选择最优的超参数
创建ARMA时间序列模型。我们并不知道p和q取什么值时,可以给它们设置一个区间范围,比如都是range(0,5),然后计算不同模型的AIC数值,选择最小的AIC数值对应的那个ARMA模型
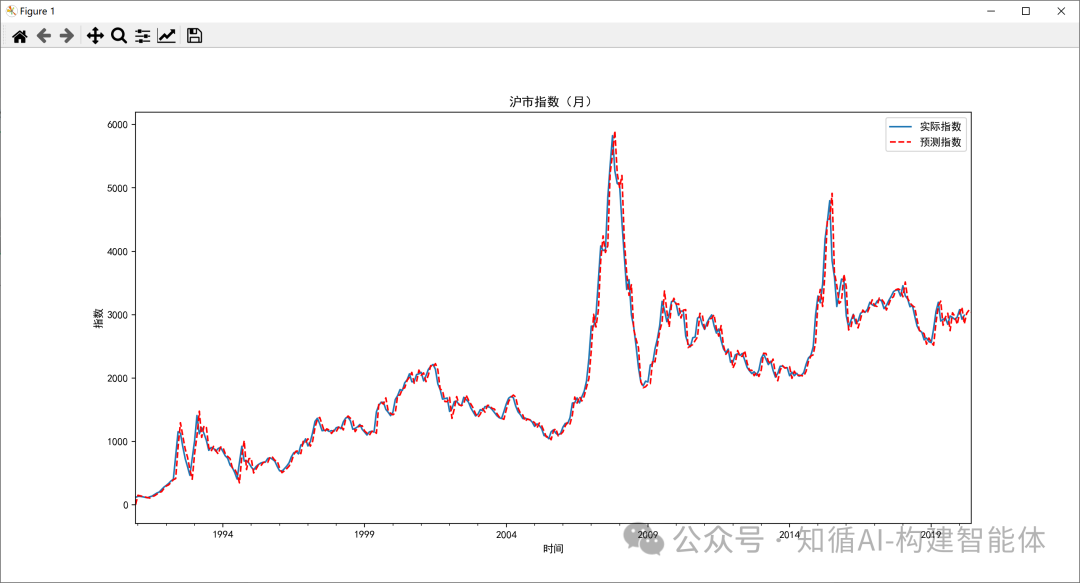
•第三步,模型预测,可视化呈现
用这个最优的ARMA模型预测未来3个月的沪市指数走势,并将结果做可视化呈现。
# 沪市指数走势预测,使用时间序列ARMA模型
import numpy as np # 数值计算库
import pandas as pd # 数据处理库
import matplotlib.pyplot as plt # 绘图库
from statsmodels.tsa.arima_model import ARIMA # ARIMA模型(传统接口)
import statsmodels.api as sm # 统计模型库
import warnings # 警告处理
from itertools import product # 用于生成参数组合
from datetime import datetime, timedelta # 日期时间处理
import calendar # 日历功能
# 忽略警告信息
warnings.filterwarnings('ignore')
# 设置matplotlib中文字体显示
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 数据加载
df = pd.read_csv('./shanghai_index_1990_12_19_to_2020_03_12.csv')
# 只保留时间戳和价格两列
df = df[['Timestamp', 'Price']]
# 将时间列转换为datetime类型,并设置为索引
df.Timestamp = pd.to_datetime(df.Timestamp)
df.index = df.Timestamp
# 数据探索
# print(df.head())
# 按照不同时间粒度重新采样:月、季度、年
df_month = df.resample('M').mean() # 按月重采样并取均值
df_Q = df.resample('Q-DEC').mean() # 按季度重采样并取均值(季度末为12月)
df_year = df.resample('A-DEC').mean() # 按年重采样并取均值(年末为12月)
# print(df_month)
# 设置ARIMA模型参数范围
ps = range(0, 5) # 自回归阶数(p)的取值范围
qs = range(0, 5) # 移动平均阶数(q)的取值范围
ds = range(1, 2) # 差分阶数(d)的取值范围,这里固定为1阶差分
# 生成所有可能的参数组合
parameters = product(ps, ds, qs)
parameters_list = list(parameters)
print('parameters_list:', parameters_list)
# 寻找最优ARIMA模型参数,即AIC值最小的模型
results = [] # 存储所有参数组合及其对应的AIC值
best_aic = float("inf") # 初始化最佳AIC为正无穷
# 遍历所有参数组合
for param in parameters_list:try:# 使用SARIMAX模型(包含季节因素的ARIMA扩展)model = sm.tsa.statespace.SARIMAX(df_month.Price, # 时间序列数据order=(param[0], param[1], param[2]), # (p, d, q)参数# seasonal_order=(4, 1, 2, 12), # 季节性参数(P, D, Q, S),此处被注释掉enforce_stationarity=False, # 不强制要求平稳性enforce_invertibility=False # 不强制要求可逆性).fit()except ValueError:print('参数错误:', param)continueaic = model.aic # 获取模型的AIC值# 如果当前模型的AIC更小,则更新最佳模型if aic < best_aic:best_model = modelbest_aic = aicbest_param = paramresults.append([param, model.aic]) # 保存当前参数和AIC
# 输出最优模型摘要信息
print('最优模型: ')
print(best_model.summary())
# 准备预测未来数据
df_month2 = df_month[['Price']] # 只保留价格列
future_month = 3 # 预测未来3个月
# 获取最后一个月的时间
last_month = pd.to_datetime(df_month2.index[len(df_month2)-1])
date_list = [] # 存储预测的日期
# 生成未来3个月的日期
for i in range(future_month):# 计算下个月有多少天year = last_month.yearmonth = last_month.monthif month == 12: # 如果是12月,则下个月是明年1月month = 1year = year + 1else:month = month + 1# 获取下个月的天数next_month_days = calendar.monthrange(year, month)[1]# 计算下个月的日期last_month = last_month + timedelta(days=next_month_days)date_list.append(last_month)
# print('date_list=', date_list)
# 创建未来3个月的空DataFrame,用于存储预测结果
future = pd.DataFrame(index=date_list, columns=df_month.columns)
# 将未来日期合并到原始数据中
df_month2 = pd.concat([df_month2, future])
# 使用最优模型进行预测
# get_prediction方法返回预测区间,我们使用predicted_mean获取点预测值
df_month2['forecast'] = best_model.get_prediction(start=0, # 从第一个数据点开始end=len(df_month2) # 到最后一个数据点(包括未来预测点)
).predicted_mean
# 绘制沪市指数预测结果
plt.figure(figsize=(30, 7)) # 设置图形大小
# 绘制实际指数曲线
df_month2.Price.plot(label='实际指数')
# 绘制预测指数曲线(红色虚线)
df_month2.forecast.plot(color='r', ls='--', label='预测指数')
plt.legend() # 显示图例
plt.title('沪市指数(月)') # 设置标题
plt.xlabel('时间') # 设置x轴标签
plt.ylabel('指数') # 设置y轴标签
plt.show() # 显示图形经过训练后的参数预测出的结果展示:
先看看预定参数:

先给定AIC一个基础值,然后循环每组参数,每次循环得出的AIC和初始AIC比较,将小的AIC值更新并记录,到下次循环时继续比较,得出最低的AIC值为止,即可得出最优参数值;
最优模型: SARIMAX Results
==============================================================================
Dep. Variable: Price No. Observations: 352
Model: SARIMAX(1, 1, 4) Log Likelihood -2249.762
Date: Tue, 26 Aug 2025 AIC 4511.524
Time: 20:25:53 BIC 4534.603
Sample: 12-31-1990 HQIC 4520.714- 03-31-2020
Covariance Type: opg
==============================================================================coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ar.L1 0.5618 0.163 3.454 0.001 0.243 0.881
ma.L1 -0.2268 0.164 -1.381 0.167 -0.549 0.095
ma.L2 -0.0453 0.058 -0.783 0.434 -0.159 0.068
ma.L3 -0.1573 0.044 -3.539 0.000 -0.244 -0.070
ma.L4 0.2199 0.031 7.150 0.000 0.160 0.280
sigma2 2.6e+04 941.086 27.632 0.000 2.42e+04 2.78e+04
===================================================================================
Ljung-Box (L1) (Q): 0.01 Jarque-Bera (JB): 1129.88
Prob(Q): 0.94 Prob(JB): 0.00
Heteroskedasticity (H): 2.27 Skew: -0.85
Prob(H) (two-sided): 0.00 Kurtosis: 11.69
===================================================================================五、总结
时间序列的主要三大用途:
预测未来,预测明天股票的涨跌,预测下个月产品的销量,预测下一小时电力的需求。
发现规律,理解数据背后的故事,分析过去十年的气温数据,看全球变暖的趋势到底有多严重;分析用户访问APP的数据,发现每周五晚上是流量高峰。
检测异常,实时监控工厂机器的振动数据,一旦发现异常波动,就在它坏掉之前报警;监控你的信用卡消费记录,一旦出现一笔在国外的异常大额消费(不符合你平时的消费习惯和地点),立刻冻结卡片防止盗刷。
总而言之,时间序列模型就是一个强大的“数据分析师”,它专门处理这种与时间紧密相关的数据,帮助我们从过去中学习,从而更科学地应对未来。 它的目标就是让我们的决策从“凭感觉”变成“凭数据”。