Redis之Keys命令和Scan命令
序言
网上看到的面试题:Redis有1亿个key,其中10w个key是以某个固定的前缀开头,如何将它们全部找出来?一般有两种命令可以实现:
- Keys命令
- Scan命令
下面具体分析一下两种命令
Keys命令
Keys pattern
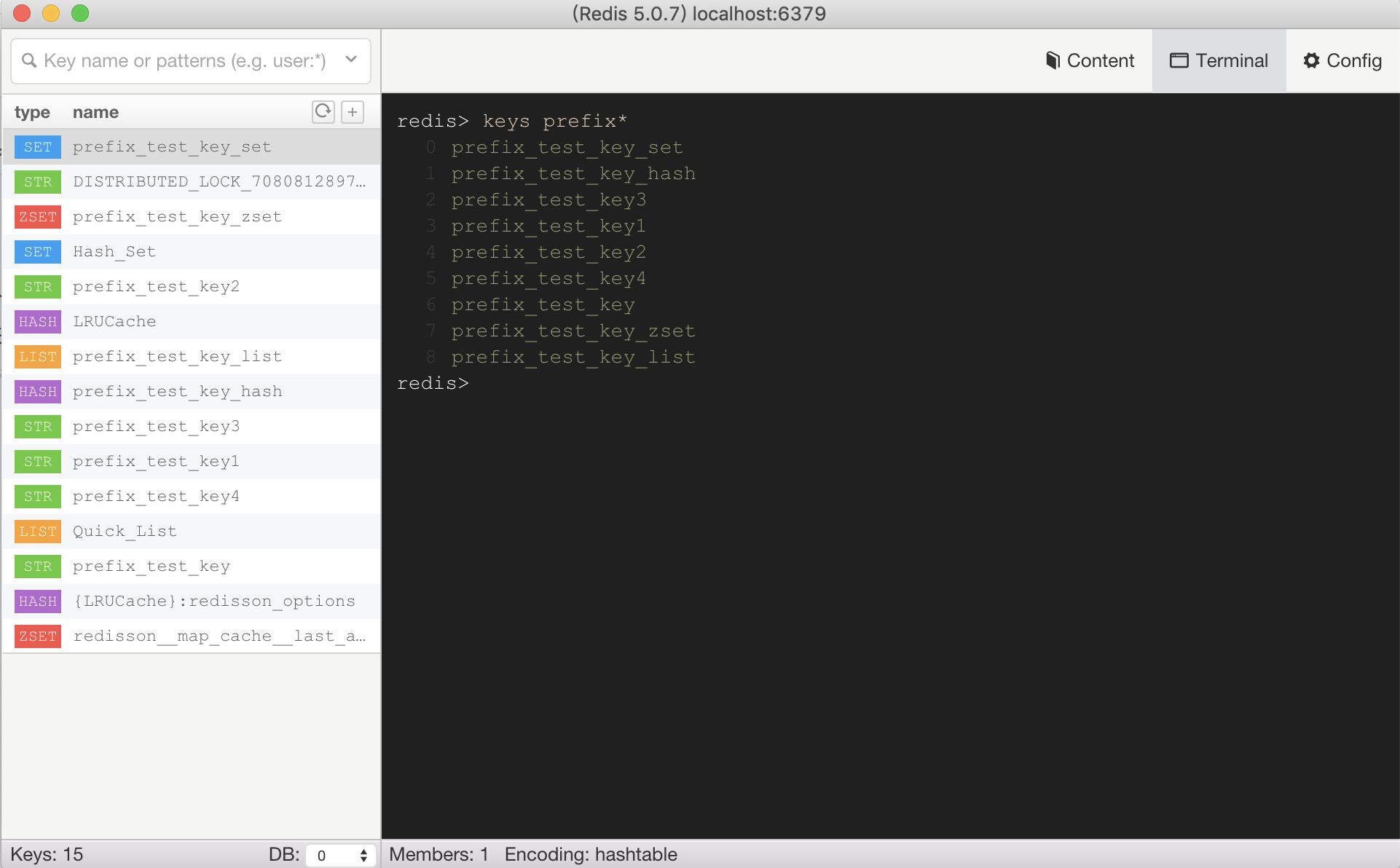
如下图所示,建了一些不同数据结构(String、Hash、List、Set、ZSet)的Key,使用命令找出前缀为prefix的Key(key区分大小写),
- 时间复杂度O(n);
- 笔记本电脑40毫秒内可以查100w个键值对;
- 生产环境慎用,大型数据库上执行会影响性能;
那么在大型数据库场景下为什么不能使用该命令呢?
Keys命令是一个阻塞式操作。
- 单线程模型:Redis的命令处理是基于单线程的。一个命令在执行时,其他所有客户端的请求都必须等待;
- 全量遍历:Keys为了找出所有匹配的key,会遍历数据库(NoSQL)中所有的key,遍历完成之前,Redis无法处理任何其他命令。
- 生产环境灾难:如果正在有1亿个key的实例上执行
Keys命令,会导致Redis服务卡顿数十秒甚至数分钟,所有依赖Redis的业务都会出现超时和雪崩,会导致严重的生产事故。
Scan命令
SCAN cursor [MATCH pattern] [COUNT count] [TYPE type]
- 单次调用时间复杂度O(1),完整迭代时间复杂度O(n);所以单次调用不会长时间阻塞线上服务;
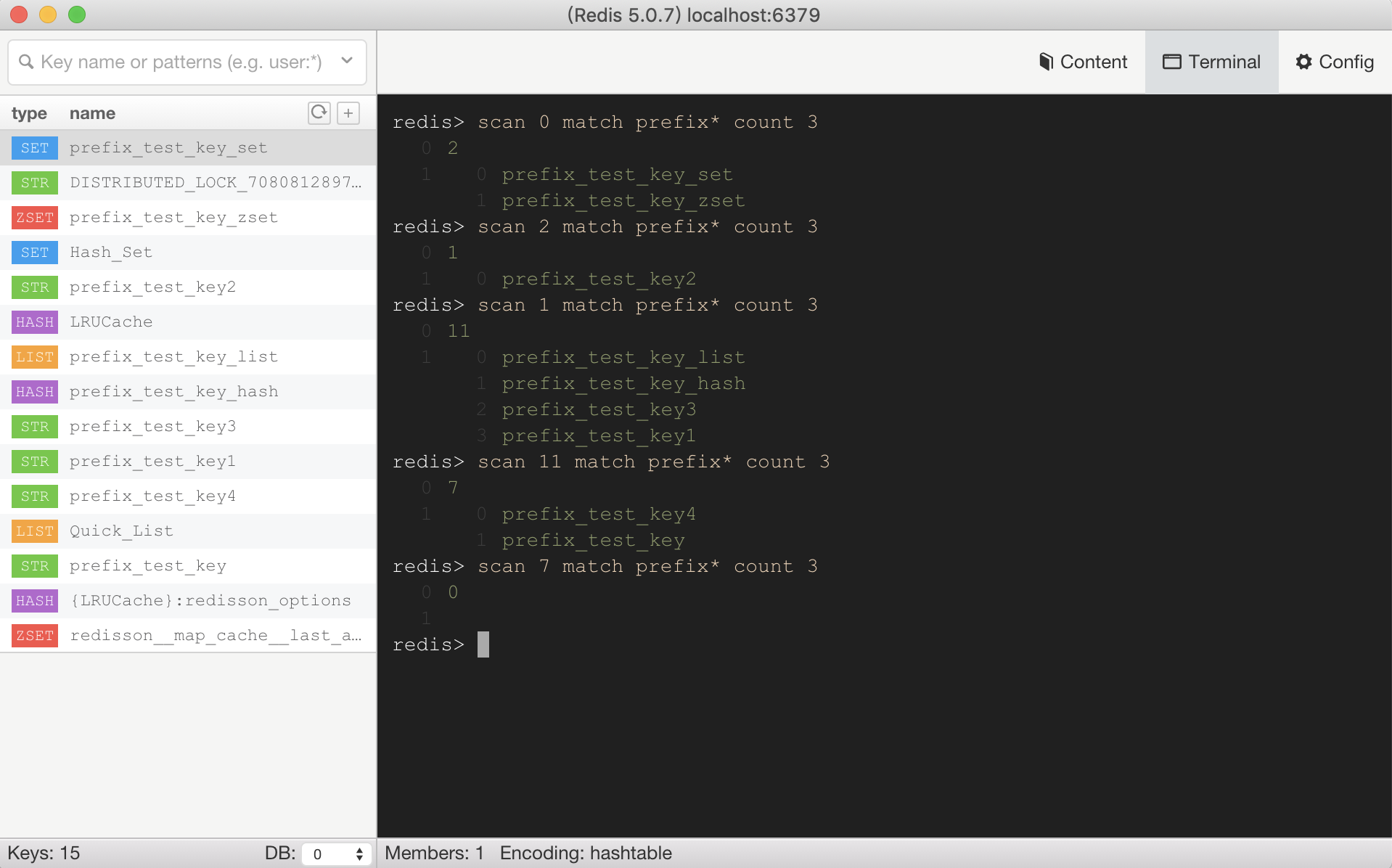
- 非阻塞式(渐进式)迭代:该命令允许增量迭代,每次调用返回少量数据,然后返回一个游标(cursor),下次传入这个游标,Redis就会接着上次结束的地方继续扫描,如上图
scan xxx match prefix* count 3每次返回的游标不一定按照顺序; - COUNT参数:
COUNT是一个建议值,告诉Redis希望每次迭代返回大约多少个key。但不是精确的,有时多有时少,但是可以控制单次扫描的粒度。如上图scan xxx match prefix* count 3每次返回的数据量不一定都是3;
参看官网,相关的还有其他的一些扫描指令:
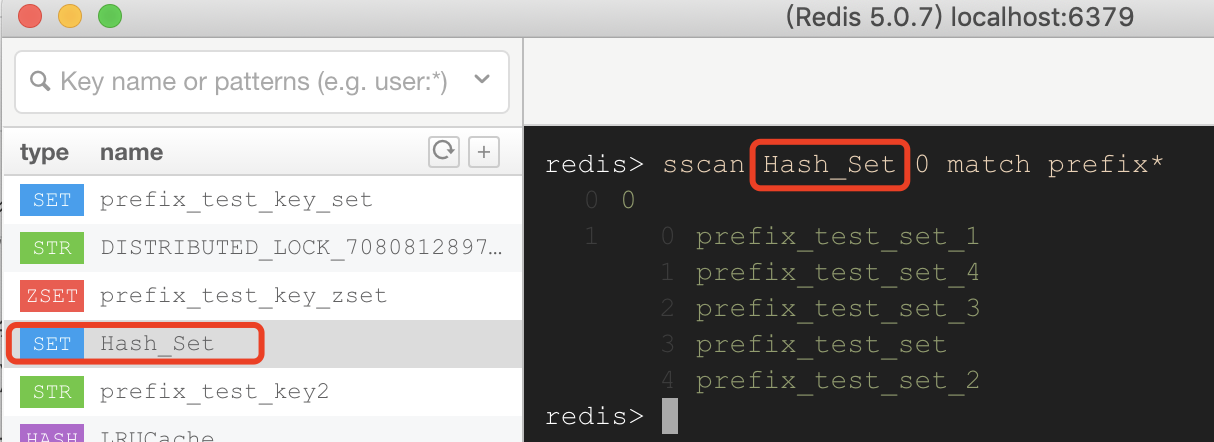
- SSCAN:iterates elements of Sets types.(针对Set数据结构)
- HSCAN:iterates fields of Hash types and their associated values.(针对Hash数据结构)
- ZSCAN:iterates elements of Sorted Set types and their associated scores.(针对ZSet数据结构)
实际操作
实际项目中可能会通过python脚本或者LUA脚本去执行查找,下面是使用python代码去执行的示例代码,
import redisr = redis.Redis(host='localhost', port=6379)
cursor = 0
prefix = 'your_prefix:*'
found_keys = []while True:cursor, keys = r.scan(cursor, match=prefix, count=10000)found_keys.extend(keys)if cursor == 0:break
可以使用Lua脚本在Redis服务器端直接处理,减少网络往返:
local keys = redis.call('SCAN', ARGV[1], 'MATCH', ARGV[2], 'COUNT', ARGV[3])
return keys
其他思路
空间换时间
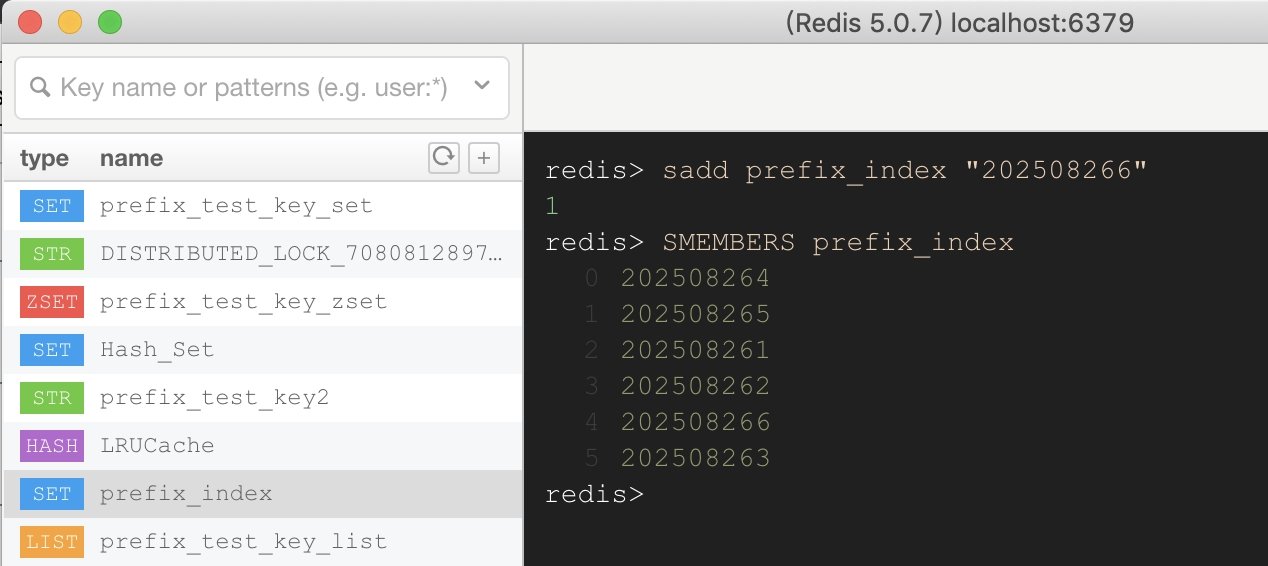
另外维护一个“索引”:
- 创建Key时,将key添加到前缀索引的Set集合中;
- 查找Key时,直接读取索引Set的所有成员,这样时间复杂度即使是O(n),遍历的也是10w数据,而非NoSQL数据库中的1亿条数据;
- 删除时,除了删除原始key,还需要从索引Set中移除对应的成员;
从节点(Replica)执行
假设这是一个低频且用于离线分析的需求,并且不想修改现有的数据结构,可以考虑在Redis集群(主从、哨兵、集群模式)的从节点去执行SCAN命令操作(甚至Keys命令),避免长时间耗时影响主节点(Master)的正常读写。