Pytorch框架的训练测试以及优化
目录
一.导入相关库以及获取数据集
二.数据打包与加载
三.判断使用的设备
四.神经网络构建(通过类的继承)
注意:
五.损失函数和优化器
六.数据的加载与训练
补充:
七.模型测试
八.结果
九.模型优化
1.设置训练的次数epoch
2.优化器改进
3.激活函数改进
十.优化后的代码
一.导入相关库以及获取数据集
import torch
from torch import nn#导入神经网络模块
from torch.utils.data import DataLoader#数据包管理工具,打包数据
from torchvision import datasets#封装了很多与图像相关的模型,和数据集
from torchvision.transforms import ToTensor#将其他数据类型转化为张量train_data=datasets.MNIST(root='data',train=True,#是否读取下载后数据中的训练集download=True,#如果之前下载过则不用下载transform=ToTensor()
)
test_data=datasets.MNIST(root='data',train=False,download=True,transform=ToTensor()
)二.数据打包与加载
Data_loader用于将数据集分批次打包,需要注意的是数据实际加载发生在for循环遍历Data_loader时(每次循环从硬盘加载指定数量(如64张图片)的数据),而非初始化阶段
train_loader=DataLoader(train_data,batch_size=64)
test_loader=DataLoader(test_data,batch_size=64)三.判断使用的设备
判断是不是使用cuda进行训练
device='cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu'
print(f'Using {device} device')四.神经网络构建(通过类的继承)
必须继承 nn.Module 类,并实现 __init__(初始化网络层)和 forward(定义数据流向)方法即前向传播。
nn.Flatten()创建一个展开对象,将输入图片展开为一维数据(如28*28=784)
通过nn.Linear()创建网络层,第一个参数是有多少信息传进来,第二个参数是当前本层神经元个数或有多少信息传出去
这里我们创建了两个隐藏层和一个输出层
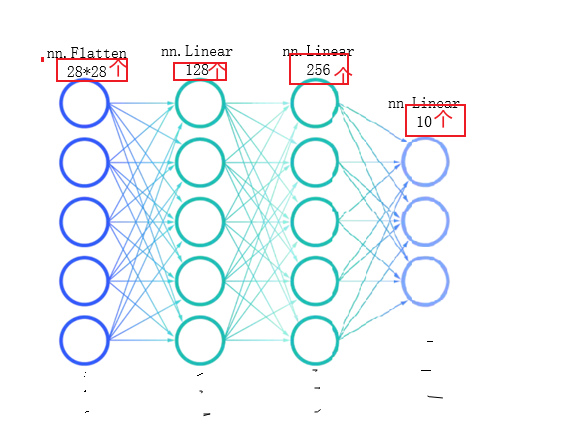
class NeuralNetwork(nn.Module):def __init__(self):super().__init__()self.flatten=nn.Flatten()#创建一个展开对象self.hidden1=nn.Linear(28*28,128)#第一个参数是有多少信息传进来,第二个参数是当前本层神经元个数或有多少信息传出去self.hidden2=nn.Linear(128,256)self.out=nn.Linear(256,10)def forward(self,x):#前向传播x=self.flatten(x)x=self.hidden1(x)x = torch.sigmoid(x)x=self.hidden2(x)x = torch.sigmoid(x)x=self.out(x)return x
model=NeuralNetwork().to(device)#把刚刚创建的模型传入device中
print(model)forward()方法不可改名,我们要明确数据的流动顺序(如 Flatten → Linear → 激活 → Linear → 输出)。最后一层通常不设激活函数,直接输出原始值
最后通过model=NeuralNetwork().to(device)把刚刚创建的模型传入device(gpu/cpu)中
注意:
self.flatten等为类属性,存储网络层对象(如nn.Flatten、nn.Linear的实例)。- 调用
forward时,数据依次通过各层对象执行计算。 - 网络结构可调整,但需确保参数一致性(如神经元凸起数量匹配即前后输入输出个数要匹配)。
五.损失函数和优化器
我们使用交叉熵损失函数来计算多分类问题的损失
使用SGD随机梯度下降来作为我们的优化器,传入模型参数和步长即学习率
loss_fn=nn.CrossEntropyLoss()
optimizer=torch.optim.SGD(model.parameters(),lr=0.01)#lr是学习率即步长,第一个参数是我们要训练的参数六.数据的加载与训练
自已定义一个train()方法
首先我们在训练前使用model.train()方法告诉模型我们要准备开始训练,赋予模型修改参数w的权限(测试时则需调用model.eval(),固定模型参数(ω)仅允许读取不允许修改,防止意外修改)
遍历data_loader循环读取数据,每次取出64张图片,由于数据与模型需要在同一个设备(CPU/GPU)上,所以我们通过X.to(device),y.to(device)实现数据迁移(如GPU训练时需将数据移至GPU)。
调用model的forward()方法完成前向传播,再将前向传播的结果和Y标签传入损失函数得到损失值
损失值为tensor类型
最后进行反向传播更新w值
- 优化器梯度清零(
zero_grad)。 - 反向更新计算出更新后的w值(
loss.backward)。 - 更新模型参数(
optimizer.step)。
通过item()方法将损失值转化为可读的float类型,我们每一百个批次打印一次损失值
def train(dataloader,model,loss_fn,optimizer):model.train()#告诉模型,准备开始训练batch_size_num=1for X,y in dataloader:X,y=X.to(device),y.to(device)#把训练数据和标签也传入cpu或gpu中pred=model.forward(X)loss=loss_fn(pred,y)optimizer.zero_grad()loss.backward()optimizer.step()loss_value=loss.item()if batch_size_num%100==0:print(f'loss:{loss_value:>7f} [number:{batch_size_num}]')batch_size_num+=1补充:
- 模型传入64张图片,每张图片维度为28x28(单通道)。训练时采用逐张图片处理,但计算机通过并行计算实现高效运行。
- 数据以矩阵形式处理,64张图片对应64个并行网络实例,GPU同时运行64个相同模型进行前向传播。
- Batch size的优势在于并行化计算,64个模型的输出结果通过累加平均计算损失值,并统一更新模型参数。
七.模型测试
自己定义一个test()方法
首先调用model.eval()方法告诉模型我们要开始测试了,停止对w的更新
通过len(dataloader.dataset)获取数据集的长度便于后面计算准确率
使用torch.no_grad()禁用梯度更新,减少内存占用
X,y还是需要传入到模型的设备中,继续前向传播得到结果和损失值,将损失值累加到一起最后计算平均损失
通过pred.argma(1)找出64组训练结果中每一组的结果(最大概率的)然后通过==y判断与测试集的标签是否相同,相同返回True,不同返回False,共返回64个,
再通过.type(torch.float)将结果转化为0,1,True则转化为1然后sum()计算总合,将每个correct累加起来这样我们就能知道我们总共对了多少,通过item()转化为可读的浮点类型
最后通过累加后的correct计算正确率
def test(dataloader,model,loss_fn):model.eval()#开始测试,停止更新wlen_data=len(dataloader.dataset)correct,num_batch=0,0loss_sum=0with torch.no_grad():for X,y in dataloader:X,y=X.to(device),y.to(device)pred=model.forward(X)loss_sum+=loss_fn(pred,y)correct+=(pred.argmax(1)==y).type(torch.float).sum().item()num_batch+=1correct/=len_dataloss_avg=loss_sum/num_batchprint(f'Accuracy:{100*correct}%\nLoss Avg:{loss_avg}')八.结果
调用train()和test()方法查看结果
train(train_loader, model, loss_fn, optimizer)
test(test_loader,model,loss_fn)loss:2.295726 [number:100]
loss:2.270109 [number:200]
loss:2.264768 [number:300]
loss:2.254235 [number:400]
loss:2.229844 [number:500]
loss:2.212975 [number:600]
loss:2.185972 [number:700]
loss:2.124710 [number:800]
loss:2.048472 [number:900]
Accuracy:56.52%
Loss Avg:2.030444383621216准确率太低,需要优化
九.模型优化
1.设置训练的次数epoch
如果我们不设置训练次数,那我们就相当于只将训练集的内容只训练了一次明显不够
可以通过for循环实现多次训练
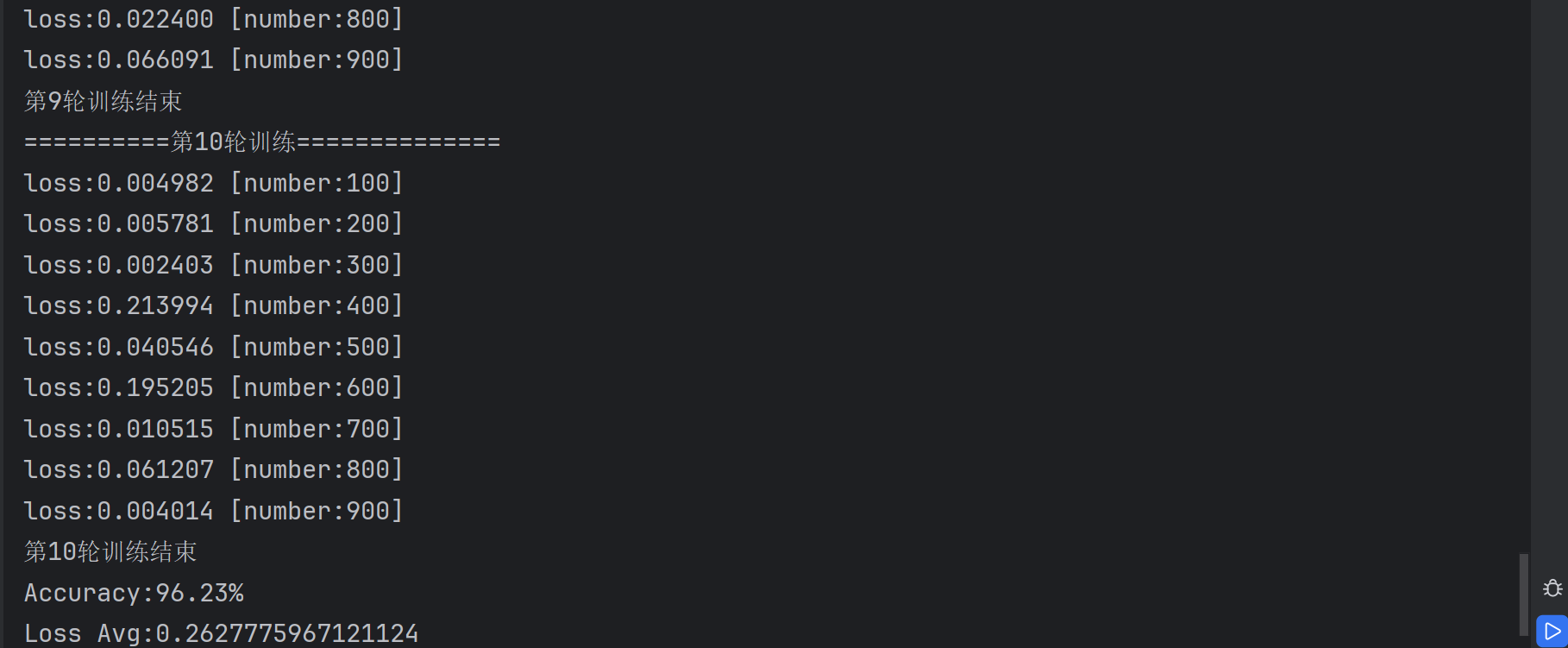
for i in range(epochs):print(f'==========第{i+1}轮训练==============')train(train_loader, model, loss_fn, optimizer)print(f'第{i+1}轮训练结束')2.优化器改进
有以下的优化器
- 原使用随机梯度下降(SGD),建议改用自适应优化器(如Adam)。
- Adam优化器优势:
- 更快收敛(首轮损失值从2.0降至0.2)。
- 训练10轮后正确率从19%提升至96.81%。
- 学习率调整:
- 初始学习率0.01导致后期损失值震荡,改为0.005后正确率微升至97.5%。
- 学习率过大会阻碍模型到达极小值点。
optimizer=torch.optim.Adam(model.parameters(),lr=0.005)
3.激活函数改进
- Sigmoid函数缺陷:
- 偏导数范围(0~0.25)导致深层网络梯度消失(连乘趋近于0)。
- 影响参数更新,造成训练停滞或震荡。
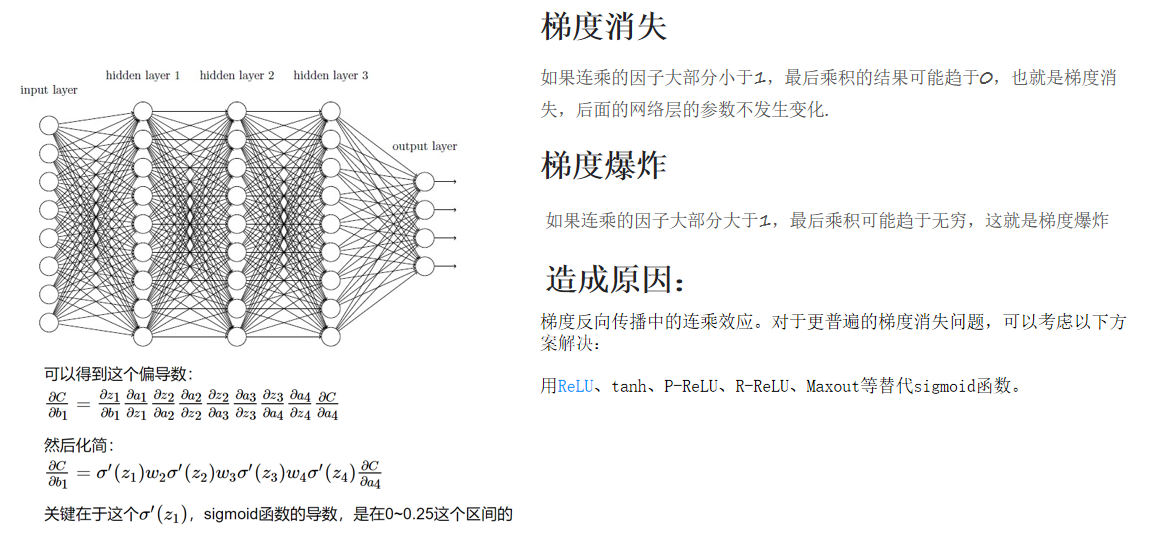
- 替代方案:ReLU(Rectified Linear Unit)函数。
- 优势:
- 计算简单(偏导数为0或1,避免梯度消失)。
- 非线性映射能力(小于零输出0,大于零线性输出)。

- 当前实验效果:
- 对浅层网络(如2层)影响有限,正确率未显著提升。
- 深层网络中推荐替换Sigmoid以避免梯度问题。
- 优势:
def forward(self,x):#前向传播x=self.flatten(x)x=self.hidden1(x)x=torch.relu(x)x=self.hidden2(x)x=torch.relu(x)x=self.out(x)return x十.优化后的代码
import torch
print(torch.__version__)import torch
from torch import nn#导入神经网络模块
from torch.utils.data import DataLoader#数据包管理工具,打包数据
from torchvision import datasets#封装了很多与图像相关的模型,和数据集
from torchvision.transforms import ToTensor#将其他数据类型转化为张量train_data=datasets.MNIST(root='data',train=True,#是否读取下载后数据中的训练集download=True,#如果之前下载过则不用下载transform=ToTensor()
)
test_data=datasets.MNIST(root='data',train=False,download=True,transform=ToTensor()
)train_loader=DataLoader(train_data,batch_size=64)
test_loader=DataLoader(test_data,batch_size=64)device='cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_available() else 'cpu'
print(f'Using {device} device')
#定义神经网络,通过类的继承
class NeuralNetwork(nn.Module):def __init__(self):super().__init__()self.flatten=nn.Flatten()#创建一个展开对象self.hidden1=nn.Linear(28*28,128)#第一个参数是有多少信息传进来,第二个参数是当前本层神经元个数或有多少信息传出去self.hidden2=nn.Linear(128,256)self.out=nn.Linear(256,10)def forward(self,x):#前向传播x=self.flatten(x)x=self.hidden1(x)# x=torch.sigmoid(x)#激活函数x=torch.relu(x)x=self.hidden2(x)x=torch.relu(x)x=self.out(x)return x
model=NeuralNetwork().to(device)#把刚刚创建的模型传入device中
print(model)def train(dataloader,model,loss_fn,optimizer):model.train()#告诉模型,准备开始训练batch_size_num=1for X,y in dataloader:X,y=X.to(device),y.to(device)#把训练数据和标签也传入cpu或gpu中pred=model.forward(X)loss=loss_fn(pred,y)optimizer.zero_grad()loss.backward()optimizer.step()loss_value=loss.item()if batch_size_num%100==0:print(f'loss:{loss_value:>7f} [number:{batch_size_num}]')batch_size_num+=1def test(dataloader,model,loss_fn):model.eval()#开始测试,停止更新wlen_data=len(dataloader.dataset)correct,num_batch=0,0loss_sum=0with torch.no_grad():for X,y in dataloader:X,y=X.to(device),y.to(device)pred=model.forward(X)loss_sum+=loss_fn(pred,y)correct+=(pred.argmax(1)==y).type(torch.float).sum().item()num_batch+=1correct/=len_dataloss_avg=loss_sum/num_batchprint(f'Accuracy:{100*correct}%\nLoss Avg:{loss_avg}')
loss_fn=nn.CrossEntropyLoss()
# optimizer=torch.optim.SGD(model.parameters(),lr=0.01)#lr是学习率即步长,第一个参数是我们要训练的参数
optimizer=torch.optim.Adam(model.parameters(),lr=0.005)epochs=10
for i in range(epochs):print(f'==========第{i+1}轮训练==============')train(train_loader, model, loss_fn, optimizer)print(f'第{i+1}轮训练结束')
test(test_loader,model,loss_fn)