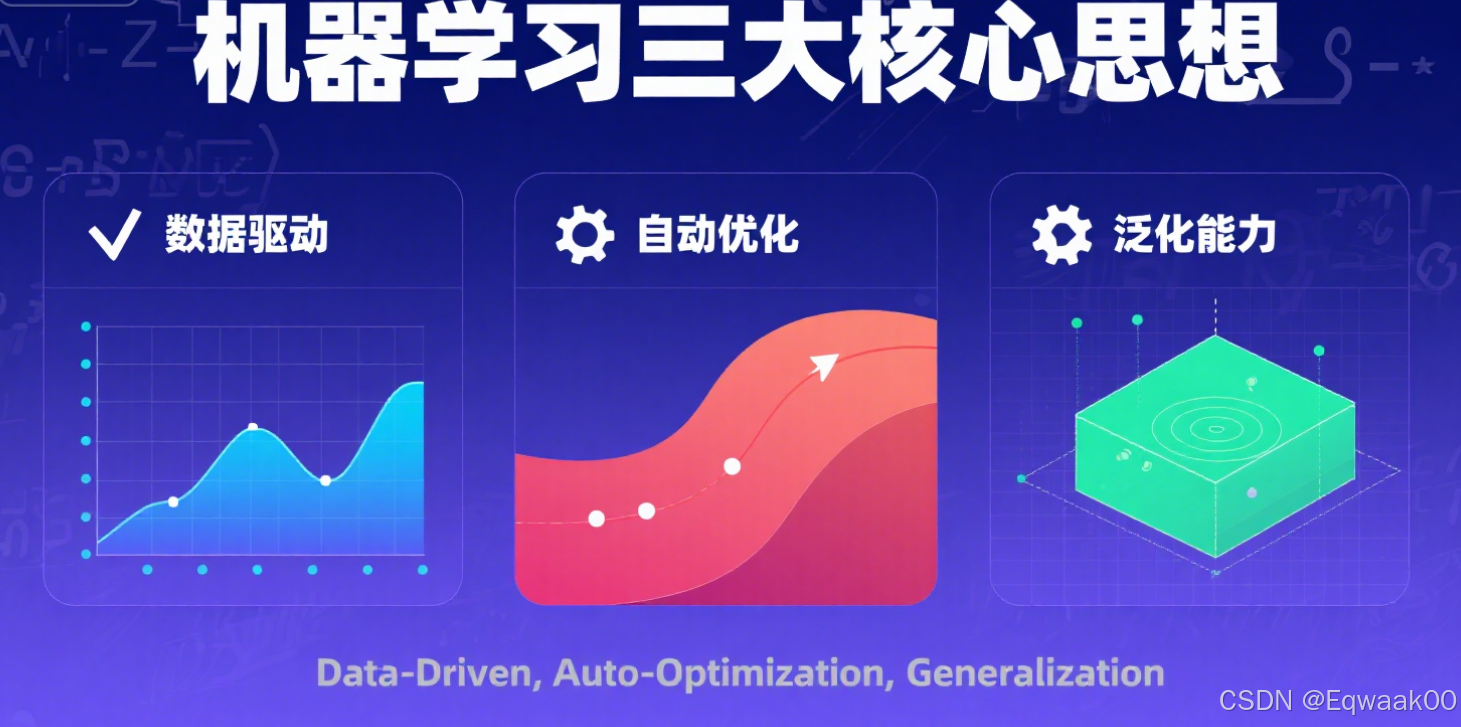
机器学习三大核心思想:数据驱动、自动优化与泛化能力
一、数据驱动:机器学习的基石
1.1 传统编程 vs 机器学习
传统编程:
# 硬编码规则
def classify_email(text):if "免费" in text and "点击" in text:return "垃圾邮件"else:return "正常邮件"机器学习:
# 数据驱动模型
model.fit(X_train, y_train) # X: 邮件文本特征,y: 标签1.2 数据驱动的本质
- 特征提取:从原始数据中提取有意义的特征(如文本的TF-IDF、图像的像素值)
- 模式发现:模型通过数据分布自动学习潜在规律
- 案例:
1.3 数据质量决定模型上限
# 数据预处理示例
from sklearn.preprocessing import StandardScalerscaler = StandardScaler()
X_scaled = scaler.fit_transform(X_raw) # 标准化处理二、自动优化:模型自我迭代的引擎
2.1 损失函数:优化的指南针
# 线性回归损失函数
def loss(y_pred, y_true):return np.mean((y_pred - y_true)**2)2.2 梯度下降:参数调整的核心算法
# 梯度下降实现
learning_rate = 0.01
for epoch in range(1000):y_pred = X * w + berror = y_pred - ygradient = X.T @ error / len(y)w -= learning_rate * gradient # 参数更新2.3 优化困境:过拟合与欠拟合
| 现象 | 原因 | 解决方案 |
|---|---|---|
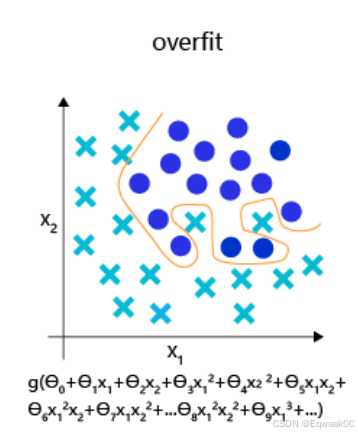 | 模型复杂度过高 | 正则化、Dropout |
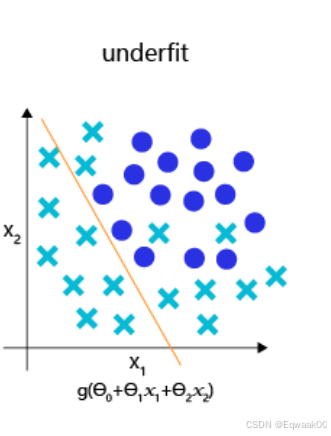 | 模型复杂度过低 | 增加特征、深度网络 |
三、泛化能力:模型的生命力
3.1 泛化误差的构成
泛化误差 = 偏差² + 方差 + 噪声- 偏差:模型预测与真实值的差距(欠拟合)
- 方差:模型对训练数据波动的敏感度(过拟合)
- 噪声:数据本身的不可约误差
3.2 提升泛化的关键技术
# 交叉验证示例
from sklearn.model_selection import cross_val_scorescores = cross_val_score(model, X, y, cv=5) # 5折交叉验证
print("CV Accuracy:", np.mean(scores))3.3 实际应用案例
房价预测任务:
# 使用正则化提升泛化
from sklearn.linear_model import Ridgemodel = Ridge(alpha=1.0) # L2正则化
model.fit(X_train, y_train)
print("Test R²:", model.score(X_test, y_test))四、三大思想的协同作用
4.1 完整学习流程
graph TDA[原始数据] --> B(特征工程)B --> C[模型训练]C --> D{验证集评估}D -->|泛化不足| E[调整模型复杂度]D -->|优化不足| F[改进优化算法]E --> CF --> C4.2 典型应用场景
| 场景 | 数据驱动 | 自动优化 | 泛化要求 |
|---|---|---|---|
| 图像识别 | 百万级图片 | CNN梯度下降 | 测试集准确率>95% |
| 金融风控 | 交易记录 | 逻辑回归优化 | 避免过拟合 |
| 自然语言处理 | 文本语料 | 注意力机制 | 跨领域迁移 |
五、未来发展方向
数据驱动:
- 主动学习(Active Learning)
- 半监督学习(Semi-supervised Learning)
自动优化:
- 自适应学习率(Adam优化器)
- 神经架构搜索(NAS)
泛化能力:
- 迁移学习(Transfer Learning)
- 元学习(Meta Learning)
实践建议:
- 始终从数据探索开始(使用Pandas/Seaborn)
- 监控训练/验证损失曲线
- 使用交叉验证评估泛化性能
- 尝试不同正则化方法(L1/L2/Dropout)