联邦雪框架FedML自学---第四篇---案例一
准备
环境搭建可以看前几篇文章,十分简单
还需要准备一个wandb账号,其实使用github登录wandb也可以
登录wandb网址,获取好自己的API KEY
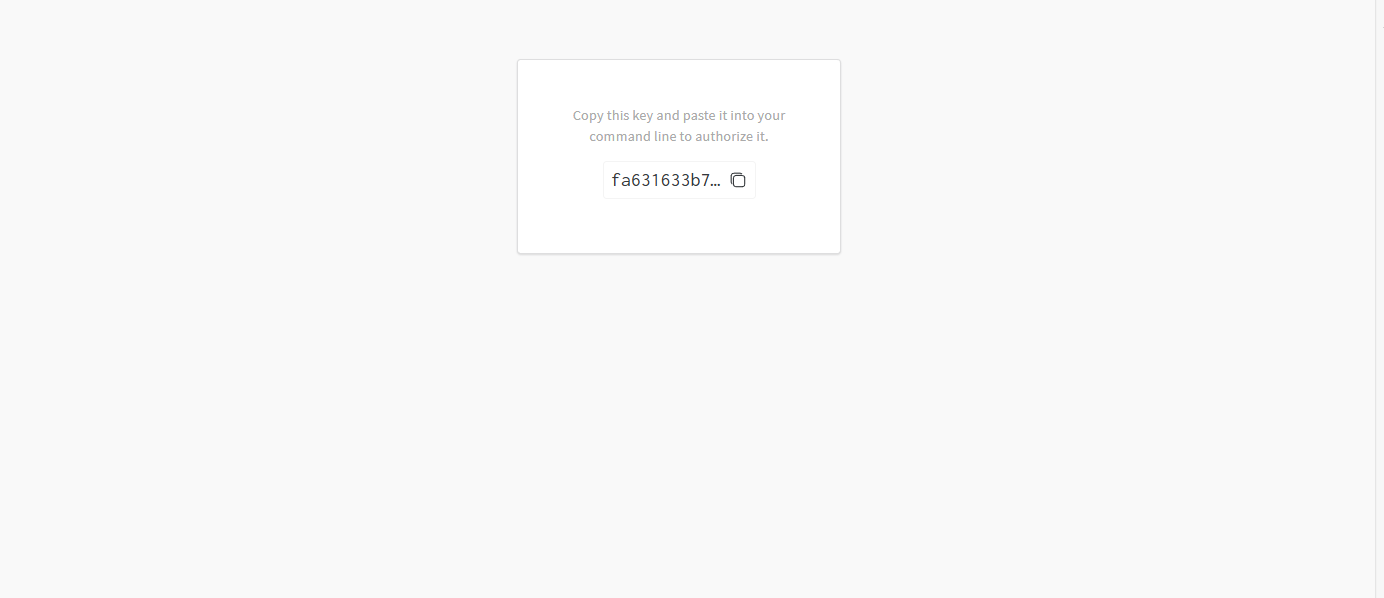
可能还会需要你设置,一个团队名称(对应着entity)
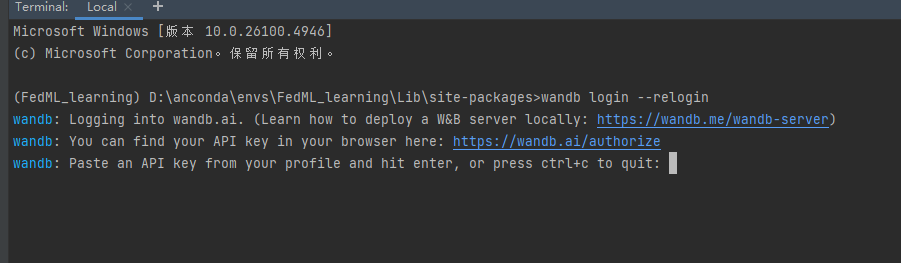
然后在终端 输入 wandb login --reloging 会让你粘贴你的api key
案例目录
这次有两个客户端,一个服务端,fedml_config.yaml是配置文件,grpc_ipconfig.csv填写客户端,服务端ip地址,wandb是在启动wandb训练跟踪后自动创建的
代码
train.py
这一次和上一篇的入门案例稍微有点不同,很显然,我们开始自定义读取数据,自定义模型了。
第一点,虽然我们是使用FedML提供的方法进行简单的自定义读取处理数据,但是返回的数据格式还是有一定格式。到后面,处理文本数据的时候,我们再简单看看源码,是如何制作成这样的,以及为什么要这样,现在就是知道,自定义数据读取方式返回的结果也需要符合FedML所规定的,而模型的自定义没有什么要求,就是普通的使用torch进行定义。
# coding: UTF-8
import torchimport fedml
from fedml import FedMLRunner
from fedml.data.MNIST.data_loader import download_mnist, load_partition_data_mnistdef load_data(args):"""按格式读取Mnist数据集"""download_mnist(args.data_cache_dir)#如果没有下载,就数据集下载到指定的文件夹中fedml.logging.info("load_data. dataset_name = %s" % args.dataset)"""| client_number | 客户端总数。 || train_data_num | 训练样本总数。 || test_data_num | 测试样本总数。 || train_data_global | 划分好批次的每批训练样本 [ ( tensor(10,784), tensor(10,) ), () ] || test_data_global | 划分好批次的每批训练样本 [ ( tensor(10,784), tensor(10,) ), () ] || train_data_local_num_dict | 每个用户 持有多少训练数据 {0:17,1:72,.........} || train_data_local_dict | {0:[(tensor(),tensor()),()],1:[(),(),()]} 每个用户所持有的划分好批次的训练数据 || test_data_local_dict | {0:[(tensor(),tensor()),()],1:[(),(),()]} 每个用户所持有的划分好批次的测试数据 || class_num | 类的数量,通常用于确定分类任务的输出层的维度。 |"""(client_num,train_data_num,test_data_num,train_data_global,test_data_global,train_data_local_num_dict,train_data_local_dict,test_data_local_dict,class_num,) = load_partition_data_mnist(#读取,并处理数据args,args.batch_size,train_path=args.data_cache_dir + "/MNIST/train",test_path=args.data_cache_dir + "/MNIST/test",)args.client_num_in_total = client_numdataset = [train_data_num,test_data_num,train_data_global,test_data_global,train_data_local_num_dict,train_data_local_dict,test_data_local_dict,class_num,]return dataset, class_num#返回数据集,类别数据量class LogisticRegression(torch.nn.Module):"""自定义线性回归模型"""def __init__(self, input_dim, output_dim):super(LogisticRegression, self).__init__()self.linear = torch.nn.Linear(input_dim, output_dim)def forward(self, x):outputs = torch.sigmoid(self.linear(x))return outputsif __name__ == "__main__":#读取参数import argparseimport osparser = argparse.ArgumentParser()parser.add_argument('--cf', type=str) #配置文件路径parser.add_argument('--role', type=str, choices=['server', 'client']) #服务端还是客户端parser.add_argument('--port', type=int) #代理端口号parser.add_argument('--rank', type=int) #编号parser.add_argument('--run_id', type=str) #启动密码 argument = parser.parse_args()os.environ["HTTP_PROXY"] = f"http://127.0.0.1:{argument.port}"os.environ["HTTPS_PROXY"] = f"http://127.0.0.1:{argument.port}""""在0.8.3版本中,使用差分隐私,隐私数据从CPU中产生,而模型更新参数我们是规定在GPU中训练,源码中直接将两者相加cpu中的数据无法直接和GPU中的数据相加,报错,我们不修改源码,直接替换源码中有问题的代码"""from fedml.core.dp.mechanisms import dp_mechanismdef _compute_new_grad_patched(self, grad):noise = self.dp.compute_noise(grad.shape).to(grad.device)return noise + graddp_mechanism.DPMechanism._compute_new_grad = _compute_new_grad_patched#初始化所有配置,环境等args = fedml.init()#获取训练设备,GPU cuda:0device = fedml.device.get_device(args)#加载数据,output_dim 就是类别数dataset, output_dim = load_data(args)#图片大小28 x 28model = LogisticRegression(28 * 28, output_dim)#开始训练fedml_runner = FedMLRunner(args, device, dataset, model)fedml_runner.run()
server_run.py,这次我们不使用pycharm中的配置方式来启动train.py
# coding: UTF-8import subprocess
import ostrain_path = os.path.join(os.path.dirname(os.path.abspath(__file__)),'train.py')
config_path = os.path.join(os.path.dirname(os.path.abspath(__file__)),'fedml_config.yaml')
role = 'server'
rank = 0
run_id = 'fedml'
port = 7897
cmd = ["python",train_path,"--cf", config_path,"--role", role,'--rank',str(rank),"--run_id",run_id,'--port',str(7897)]# 执行命令
subprocess.run(cmd)client1_run.py
# coding: UTF-8
import subprocess
import ostrain_path = os.path.join(os.path.dirname(os.path.abspath(__file__)),'train.py')
config_path = os.path.join(os.path.dirname(os.path.abspath(__file__)),'fedml_config.yaml')
role = 'client'
rank = 1
run_id = 'fedml'
port = 7897cmd = ["python",train_path,"--cf", config_path,"--role", role,'--rank',str(rank),"--run_id",run_id,'--port',str(port)]# 执行命令
subprocess.run(cmd)client2_run.py
# coding: UTF-8
import subprocess
import ostrain_path = os.path.join(os.path.dirname(os.path.abspath(__file__)),'train.py')
config_path = os.path.join(os.path.dirname(os.path.abspath(__file__)),'fedml_config.yaml')
role = 'client'
rank = 2
run_id = 'fedml'
port = 7897
cmd = ["python",train_path,"--cf", config_path,"--role", role,'--rank',str(rank),"--run_id",run_id,'--port',str(port)]# 执行命令
subprocess.run(cmd)配置
fedml_config.yaml文件,整体配置和上一篇案例的配置没什么区别,现在我们不用太过关注参数为什么那么多,有哪些参数,需要填哪些参数,每个参数的含义具体是什么,这个参数的值可以填哪些等这些问题
common_args:training_type: "cross_silo"random_seed: 0config_version: "release"using_mlops: falsedata_args:dataset: "mnist"data_cache_dir: D:\\anconda\\envs\\FedML_learning\\FedML_examples\\quick_start_octopus\\MNISTpartition_method: "hetero"partition_alpha: 0.5model_args:model: "lr"train_args:federated_optimizer: "FedAvg"client_id_list: "[]"client_num_in_total: 2client_num_per_round: 2comm_round: 3epochs: 2batch_size: 10client_optimizer: sgdlearning_rate: 0.03weight_decay: 0.001validation_args:frequency_of_the_test: 1device_args:using_gpu: truegpu_id: 0comm_args:backend: "MQTT_S3"mqtt_config_path:s3_config_path:grpc_ipconfig_path: D:\\anconda\\envs\\FedML_learning\\FedML_examples\\example1\\grpc_ipconfig.csvtracking_args:enable_tracking: trueenable_wandb: truewandb_key: xxxxxxxxxxx填入自己的wandb_entity: xxxxxxxxxxx填入自己的wandb_project: example1run_name: fedml_torch_fedavg_mnist_lrdp_args:using_gpu: trueenable_dp: truestop_training_at_epsilon: falsedp_solution_type: cdp # cdp or ldpepsilon: 0.5delta: 0.1sensitivity: 1mechanism_type: gaussiannoise_multiplier: 10.0clipping_norm: 0.04 # float('inf') or None to deactivate
其中大部分参数配置和上一篇案例的参数配置差不多,变化的有两个:
第一个就是wandb_args,其中需要你将你的api key和entity(团队名称),本次训练名称等填入
第二个就是dp_args,dp是 differential private 差分隐私,可以简单理解为对服务端和客服端之间通信的数据进行加密,其中像epsilon,delta,mechanism_type都是差分隐私数学公式中的某几个重要参数,我会在后面自学差分隐私并写一篇文章,现在只需要模仿着写即可
不过,需要提一嘴的是,这次训练我们使用的cuda,如果你的本地电脑中没有GPU,那就改成using_gpu:false 即可。如果想尝试使用cuda进行联邦学习,那需要先在本地电脑安装cuda,cudnn这些安装很简单,也有很多教程。然后在你的虚拟环境中安装cudatoolkit=11.8,torch和torchvision记得换成cuda版本的就行。
此外,如果你的本地电脑就一个GPU,那么 gpu_id:0 就可以,它会直接使用那个唯一的GPU,名为cuda:0
如果你的本地有很多GPU,或者你连接着服务器,那就可以设置一个专门的文件gpu_mapping.yaml,这个就是来指定你的多GPU工作的。当然,至于本地多进程并行的模拟联邦学习(MPI,最好使用linux系统),以及如何设置这种多GPU,后面会有文章介绍
# You can define a cluster containing multiple GPUs within multiple machines by defining `gpu_mapping.yaml` as follows:# config_cluster0:
# host_name_node0: [num_of_processes_on_GPU0, num_of_processes_on_GPU1, num_of_processes_on_GPU2, num_of_processes_on_GPU3, ..., num_of_processes_on_GPU_n]
# host_name_node1: [num_of_processes_on_GPU0, num_of_processes_on_GPU1, num_of_processes_on_GPU2, num_of_processes_on_GPU3, ..., num_of_processes_on_GPU_n]
# host_name_node_m: [num_of_processes_on_GPU0, num_of_processes_on_GPU1, num_of_processes_on_GPU2, num_of_processes_on_GPU3, ..., num_of_processes_on_GPU_n]# this is used for 10 clients and 1 server training within a single machine which has 4 GPUs
mapping_default:ChaoyangHe-GPU-RTX2080Tix4: [3, 3, 3, 2]# this is used for 4 clients and 1 server training within a single machine which has 4 GPUs
mapping_config1_5:host1: [2, 1, 1, 1]# this is used for 10 clients and 1 server training within a single machine which has 4 GPUs
mapping_config2_11:host1: [3, 3, 3, 2]# this is used for 10 clients and 1 server training within a single machine which has 8 GPUs
mapping_config3_11:host1: [2, 2, 2, 1, 1, 1, 1, 1]# this is used for 4 clients and 1 server training within a single machine which has 8 GPUs, but you hope to skip the GPU device ID.
mapping_config4_5:host1: [1, 0, 0, 1, 1, 0, 1, 1]# this is used for 4 clients and 1 server training using 6 machines, each machine has 2 GPUs inside, but you hope to use the second GPU.
mapping_config5_6:host1: [0, 1]host2: [0, 1]host3: [0, 1]host4: [0, 1]host5: [0, 1]
# this is used for 4 clients and 1 server training using 2 machines, each machine has 2 GPUs inside, but you hope to use the second GPU.
mapping_config5_2:gpu-worker2: [1,1]gpu-worker1: [2,1]# this is used for 10 clients and 1 server training using 4 machines, each machine has 2 GPUs inside, but you hope to use the second GPU.
mapping_config5_4:gpu-worker2: [1,1]gpu-worker1: [2,1]gpu-worker3: [3,1]gpu-worker4: [1,1]# for grpc GPU mapping
mapping_FedML_gRPC:hostname_node_server: [1]hostname_node_1: [1, 0, 0, 0]hostname_node_2: [1, 0, 0, 0]# for torch RPC GPU mapping
mapping_FedML_tRPC:lambda-server1: [0, 0, 0, 0, 2, 2, 1, 1]lambda-server2: [2, 1, 1, 1, 0, 0, 0, 0]#mapping_FedML_tRPC:
# lambda-server1: [0, 0, 0, 0, 3, 3, 3, 2]结果
这里就表示你的wandb登录成功
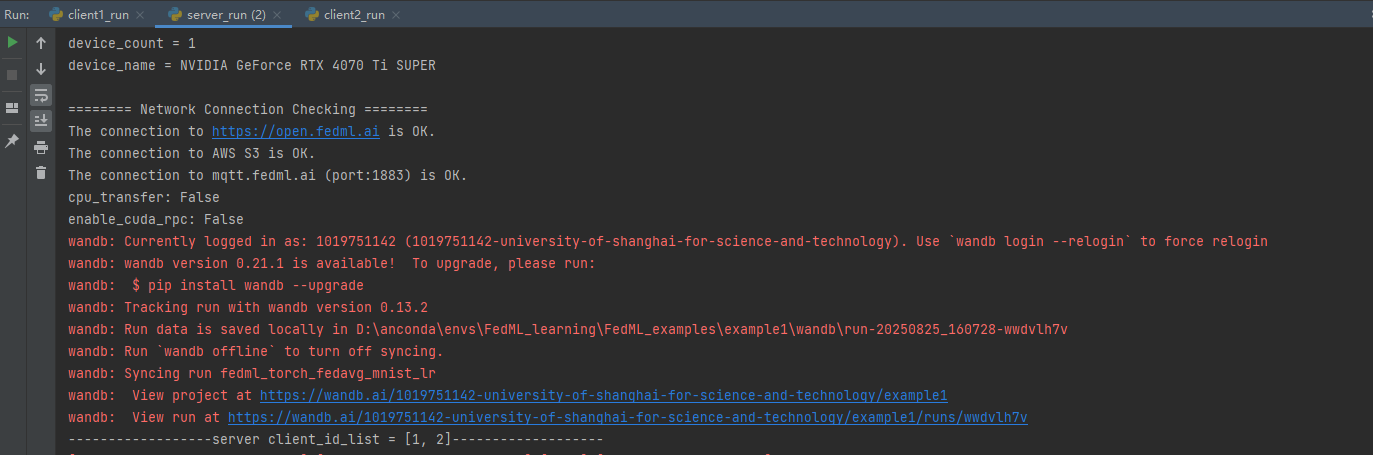
客户端的部分训练输出

正常结束
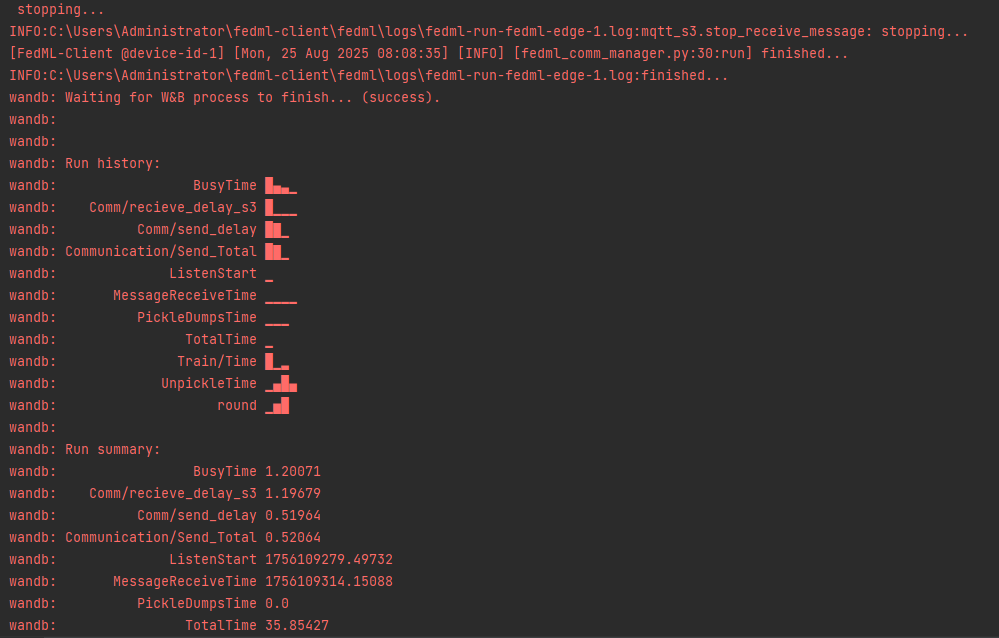
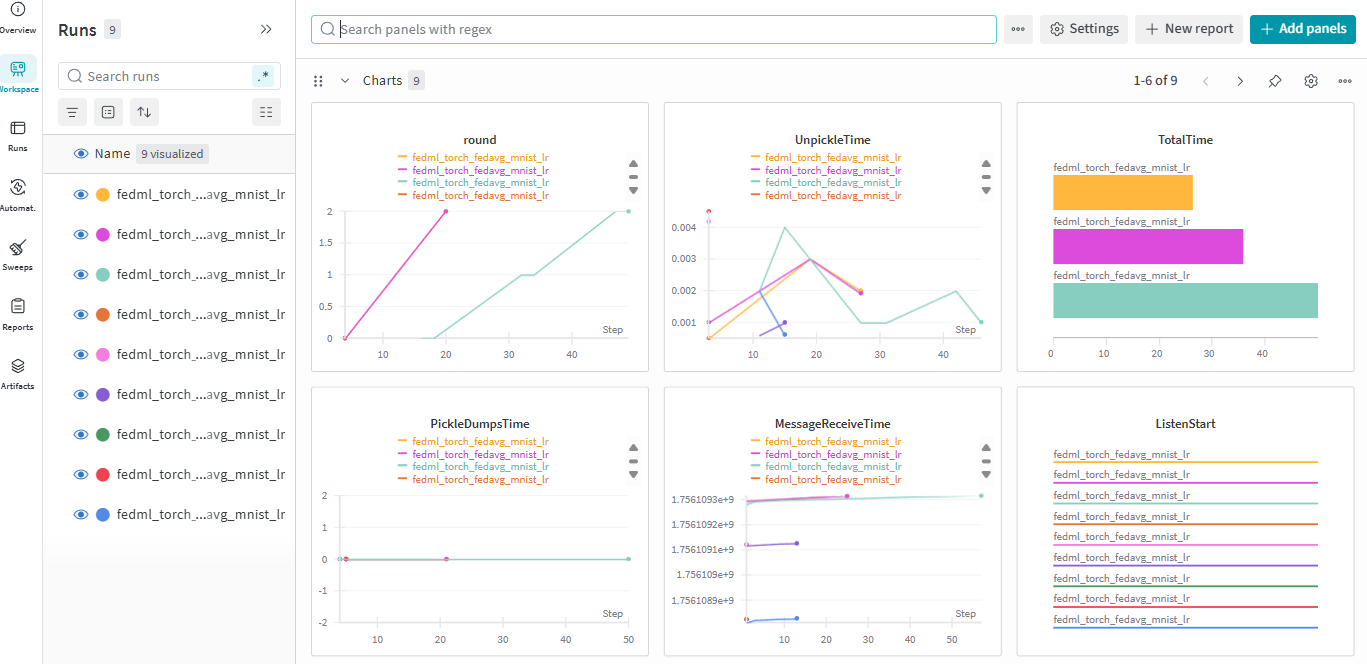
wandb显示