基于长短期记忆网络的多变量时间序列预测 LSTM
一、作品详细简介
1.1附件文件夹程序代码截图

全部完整源代码,请在个人首页置顶文章查看:
学行库小秘_CSDN博客![]() https://blog.csdn.net/weixin_47760707?spm=1000.2115.3001.5343
https://blog.csdn.net/weixin_47760707?spm=1000.2115.3001.5343
1.2各文件夹说明
1.2.1 main.m主函数文件
这段代码实现了基于 LSTM 神经网络的多变量时间序列预测模型。以下是对该MATLAB代码的详细分步解释,涵盖了从数据导入到模型评估的全过程:
总体概述
该代码从一个包含特征和目标的 Excel 数据集开始,通过构建一个以过去 kim 个时间步的特征作为输入、预测未来 zim 个时间步的目标值的监督学习数据集。随后,它划分训练集和测试集,对数据进行归一化处理,并将其重构为 LSTM 网络所需的序列输入格式。接着,代码定义、训练了一个 LSTM 网络,并用它进行预测。最后,它对预测结果进行反归一化,并计算了多种评估指标(RMSE, R², MAE, MBE, MSE, MAPE)并绘制图表来评估模型性能。
步骤 1:数据导入与初步分析
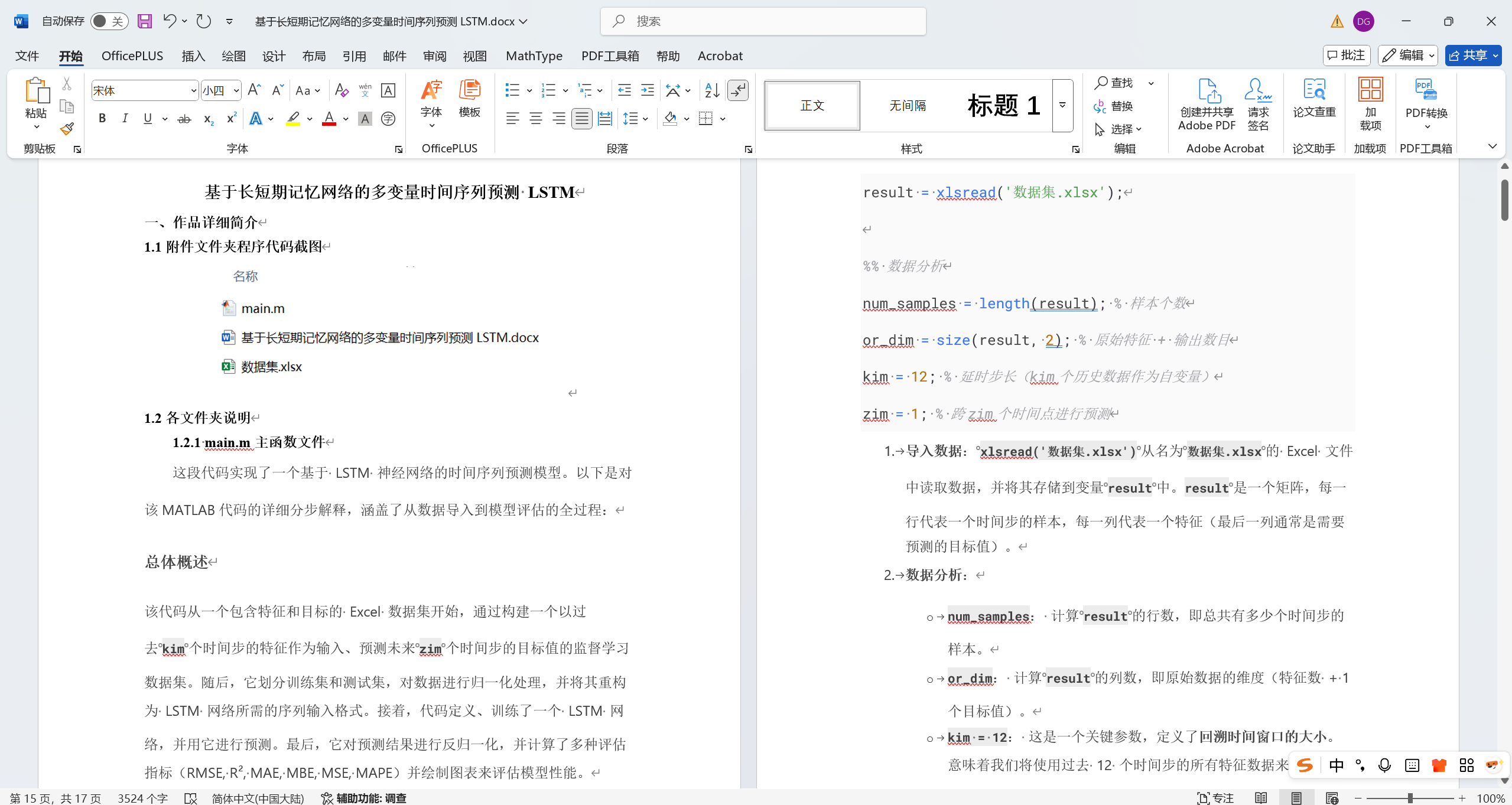
- 导入数据: xlsread('数据集.xlsx') 从名为 数据集.xlsx 的 Excel 文件中读取数据,并将其存储到变量 result 中。result 是一个矩阵,每一行代表一个时间步的样本,每一列代表一个特征(最后一列通常是需要预测的目标值)。
- 数据分析:
- num_samples: 计算 result 的行数,即总共有多少个时间步的样本。
- or_dim: 计算 result 的列数,即原始数据的维度(特征数 + 1个目标值)。
- kim = 12: 这是一个关键参数,定义了回溯时间窗口的大小。意味着我们将使用过去 12 个时间步的所有特征数据来预测未来。
- zim = 1: 定义了预测时间步的偏移。zim = 1 表示预测下一个时间步(t+1)的目标值。如果 zim = 3,则表示预测未来第 3 个时间步(t+3)的值。
步骤 2:构建监督学习数据集(滑动窗口)
这是一个滑动窗口操作,将时间序列数据转换为适合监督学习的表格数据。
- 循环:从第一个样本开始,循环到 num_samples - kim - zim + 1。这样可以确保在取 i + kim + zim - 1 的行时不会超出数据范围。
- 构造输入(特征):
- result(i: i + kim - 1, :): 取出从当前时刻 i 开始,连续 kim(12)个时间步的所有列(特征)。
- reshape(..., 1, kim * or_dim): 将上面得到的 12 x or_dim 的矩阵平铺成一个 1 x (12 * or_dim) 的行向量。这就是一个样本的所有输入特征。
- 构造输出(目标):
- result(i + kim + zim - 1, end): 取第 i + kim + zim - 1 行(即未来第 zim 个时间点)的最后一列(end)的值作为目标值。
- 组合:将平铺后的特征行向量和目标值组合成一个更长的行向量,并存入新矩阵 res 的一行中。
- 最终 res 的结构: res 有 N 行,(kim * or_dim + 1) 列。前 kim * or_dim 列是特征(X),最后一列是目标值(y)。
举例:假设 kim=2, or_dim=2(1个特征+1个目标),原始数据为 [1, 10; 2, 20; 3, 30; 4, 40]。
- i=1: 特征=[1,10; 2,20] -> 平铺为 [1,10,2,20], 目标=result(1+2+1-1, end)=result(3,2)=30 -> res(1,:)=[1,10,2,20,30]
- i=2: 特征=[2,20; 3,30] -> 平铺为 [2,20,3,30], 目标=result(4,2)=40 -> res(2,:)=[2,20,3,30,40]
步骤 3:划分训练集和测试集
- 创建索引:temp 是一个从 1 到 1488 的序列,代表所有有效样本的索引。
- 划分:
- 训练集:前 1000 个样本。
- P_train: 训练集特征,取 res 第1到1000行的前 end-1 列,并进行转置(')。转置后,每一列是一个样本。M=1000 是训练样本数。
- T_train: 训练集目标,取 res 第1到1000行的最后 end 列,并转置。
- 测试集:从第1001个样本到最后一个样本。
- P_test, T_test: 同理,N 是测试样本数(1488-1000=488)。
- 训练集:前 1000 个样本。
步骤 4:数据归一化
- 目的:将数据缩放到一个特定的区间(这里是[0, 1]),以消除量纲差异,加速模型训练收敛,提高精度。
- 输入特征归一化:
- mapminmax(P_train, 0, 1): 计算训练集 P_train 的归一化参数(最大值、最小值等),并将 P_train 归一化到 [0, 1]。ps_input 存储了这些参数。
- mapminmax('apply', P_test, ps_input): 关键! 使用训练集计算出的参数 ps_input 来归一化测试集 P_test。绝不能使用测试集自身的最大最小值来归一化,否则会引入数据泄露。
- 输出目标归一化:同理,对 T_train 和 T_test 进行归一化,参数保存在 ps_output 中,用于后续的反归一化。
步骤 5:数据重塑为序列格式
- 重塑维度 (reshape):
- reshape(P_train, 5, 12, 1, M): 这是为了将数据转换为 LSTM 层期望的序列输入格式。
- P_train 的原始形状: (特征总数, 样本数) = (kim * or_dim, M) = (12*5, 1000)?这里假设 or_dim=5(4个特征+1个目标)。
- 重塑后的形状: (特征数, 时间步长, 通道数, 样本数) = (5, 12, 1, 1000)。
- 含义: 1000 个样本,每个样本是一个 12x5 的序列(12个时间步,每个时间步有5个特征)。1 可以看作是“通道”,类似于图像中的颜色通道,这里为1。
- double() 确保数据是双精度浮点数。
- reshape(P_train, 5, 12, 1, M): 这是为了将数据转换为 LSTM 层期望的序列输入格式。
- 转换元胞数组 (cell array):
- LSTM 网络的 trainNetwork 和 predict 函数要求输入数据是元胞数组,其中每个元胞包含一个样本的序列数据。
- 循环将每个样本(P_train(:, :, 1, i),即一个 5x12 的矩阵)放入元胞数组 p_train 和 p_test 中。
- 同时,将目标数据转置回列向量以匹配元胞数组的格式。
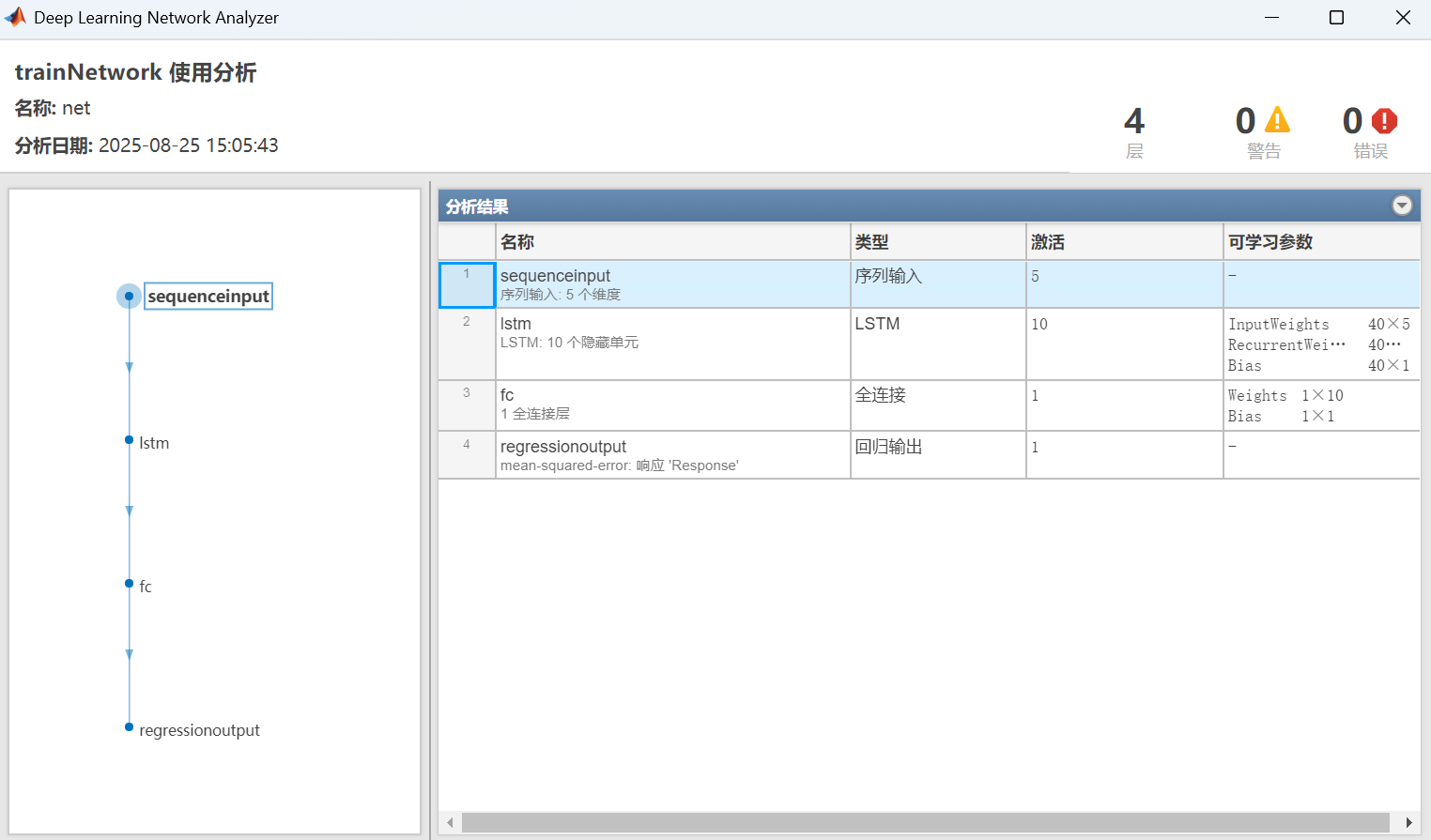
步骤 6:构建与训练 LSTM 模型
- 网络结构 (layers):
- sequenceInputLayer(5): 定义输入层,接受一个特征维度为5的序列。
- lstmLayer(10, ‘OutputMode’, ‘last’):
- 10: LSTM 层有 10 个隐藏单元(神经元)。
- ‘OutputMode’, ‘last’: 只输出最后一个时间步的隐藏状态,这对于序列到单值的预测非常有效。
- fullyConnectedLayer(1): 全连接层,将 LSTM 输出的 10 维向量映射到最终的 1 维预测值。
- regressionLayer: 定义回归任务的损失函数为均方误差(MSE)。
- 训练选项 (options):
- ‘adam’: 使用 Adam 优化器。
- ‘MaxEpochs’: 整个数据集最多被遍历 500 次。
- ‘MiniBatchSize’: 每次参数更新使用 128 个样本。
- ‘LearnRateSchedule’: 学习率按计划衰减,‘piecewise’ 表示分段恒定衰减。
- ‘LearnRateDropPeriod’ 和 ‘LearnRateDropFactor’: 每 400 个 Epoch,学习率乘以 0.1。
- ‘Shuffle’: 每个 Epoch 都打乱训练数据的顺序,防止模型过拟合。
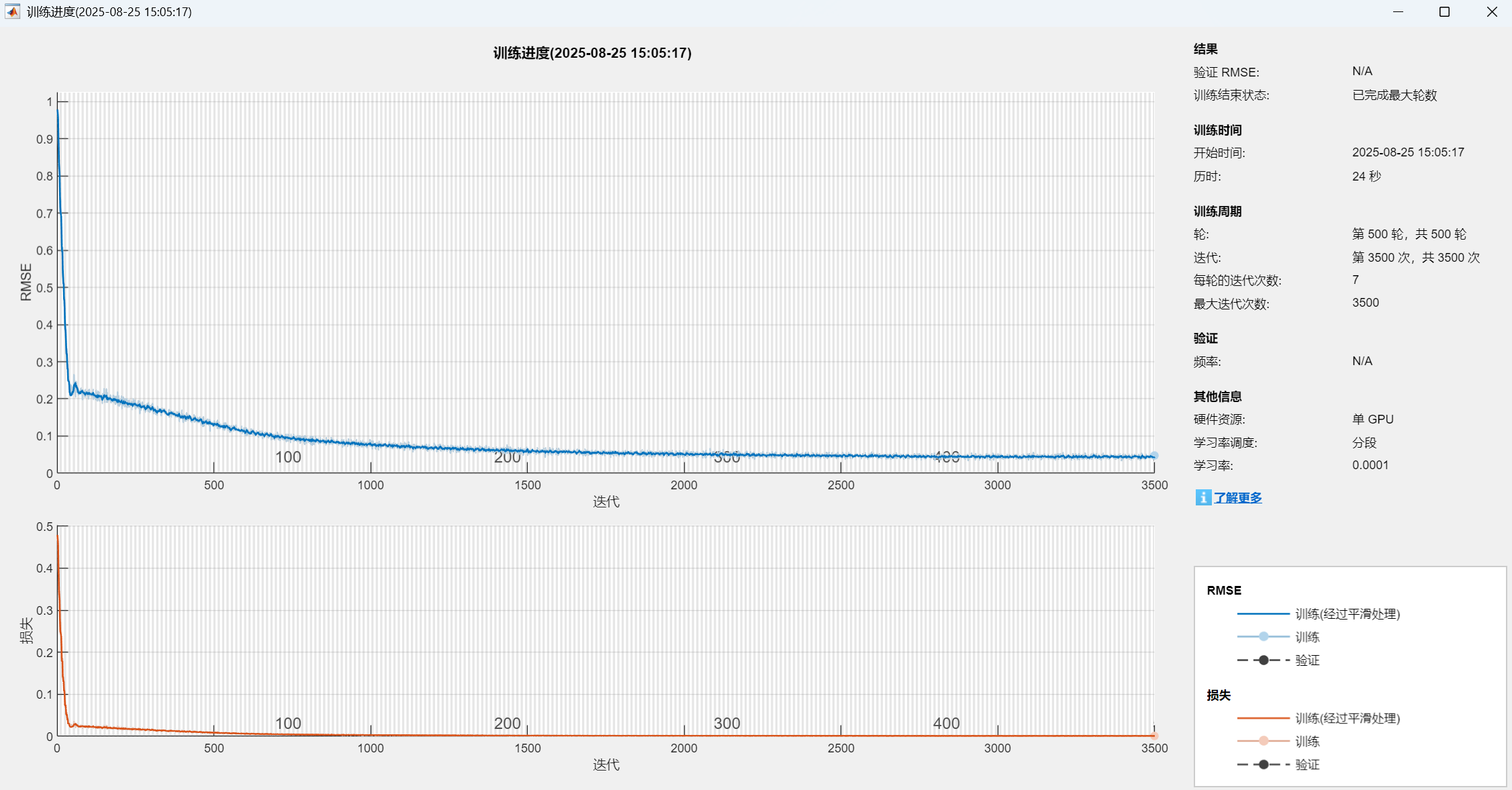
- ‘Plots’: 绘制训练过程中的损失变化图。
- 训练: trainNetwork 函数使用指定的网络结构、数据和选项开始训练,返回训练好的网络 net。
步骤 7:预测与反归一化
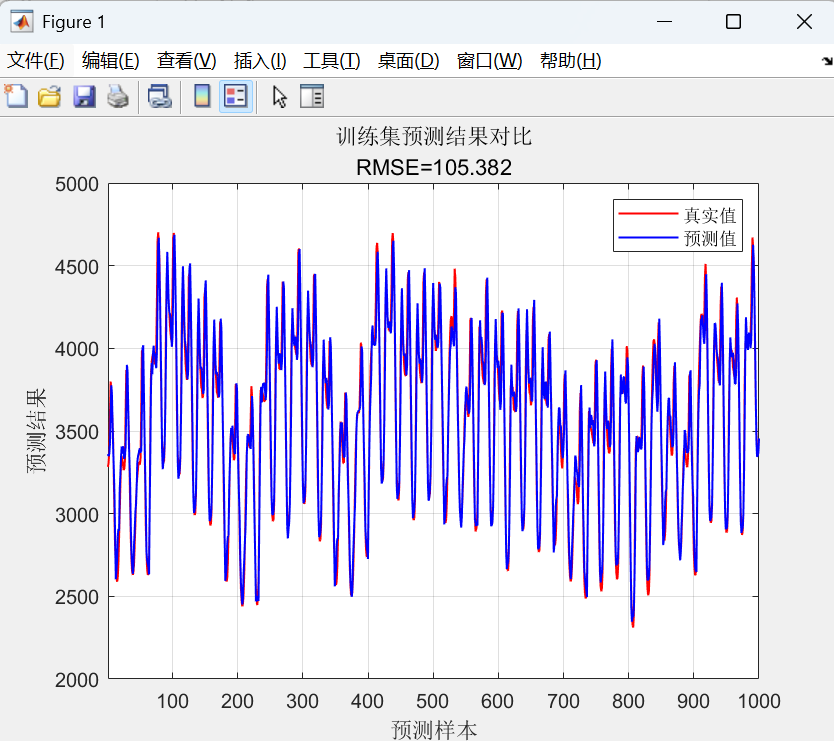
- 计算评估指标:
- RMSE: 均方根误差,衡量预测值与真实值之间的偏差,越小越好。
- R²: 决定系数,衡量模型对目标变量变化的解释程度,越接近1越好。
- MAE: 平均绝对误差,直观的误差衡量。
- MBE: 平均偏差误差,衡量预测的平均偏差(正负)。
- MSE: 均方误差。
- MAPE: 平均绝对百分比误差。
- 绘制图表:
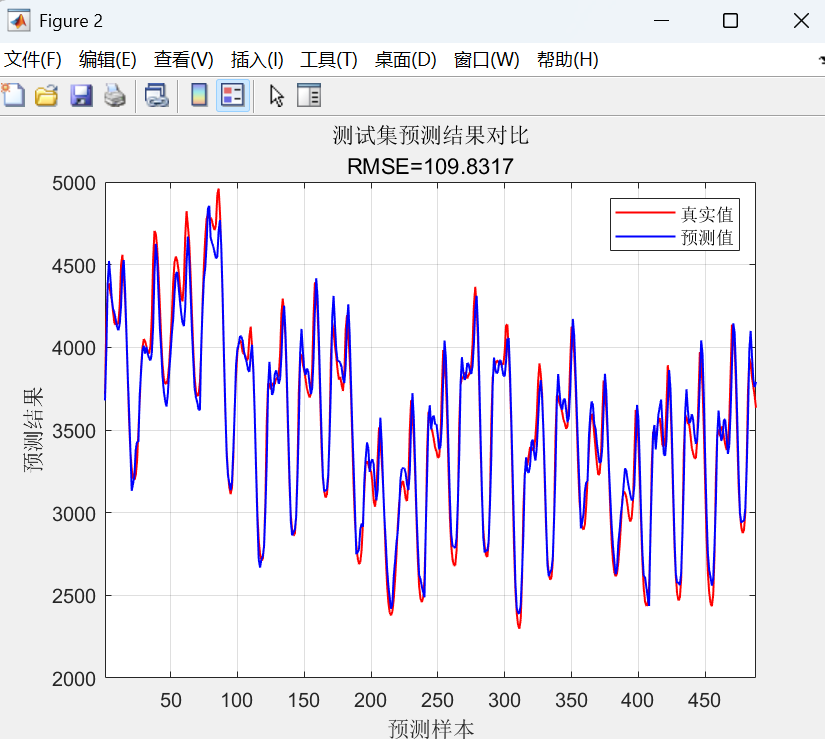
- 预测对比曲线图: 将真实值和预测值在同一张图上用曲线画出,直观地看出预测的趋势和准确性。
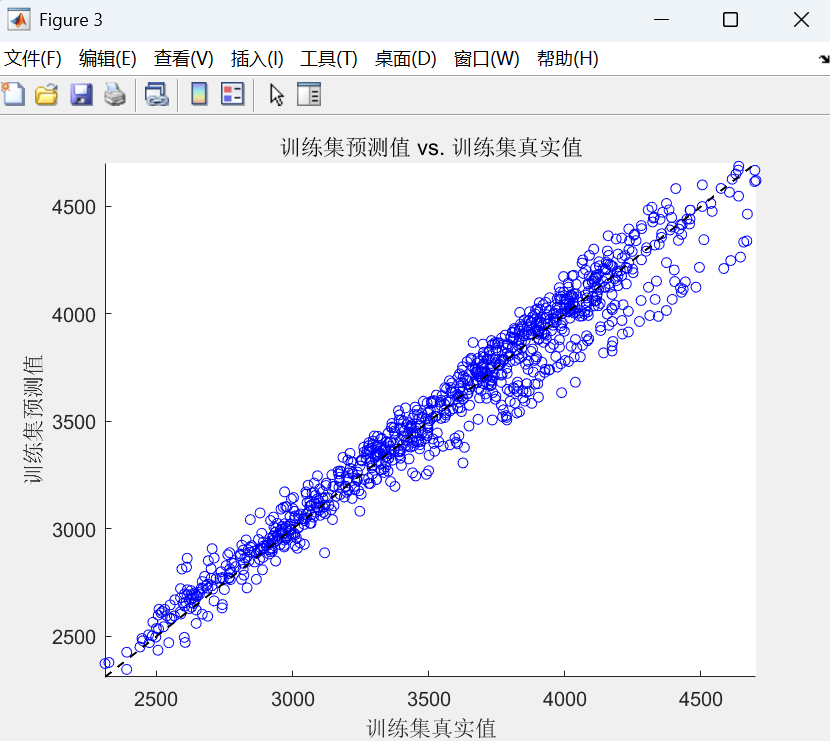
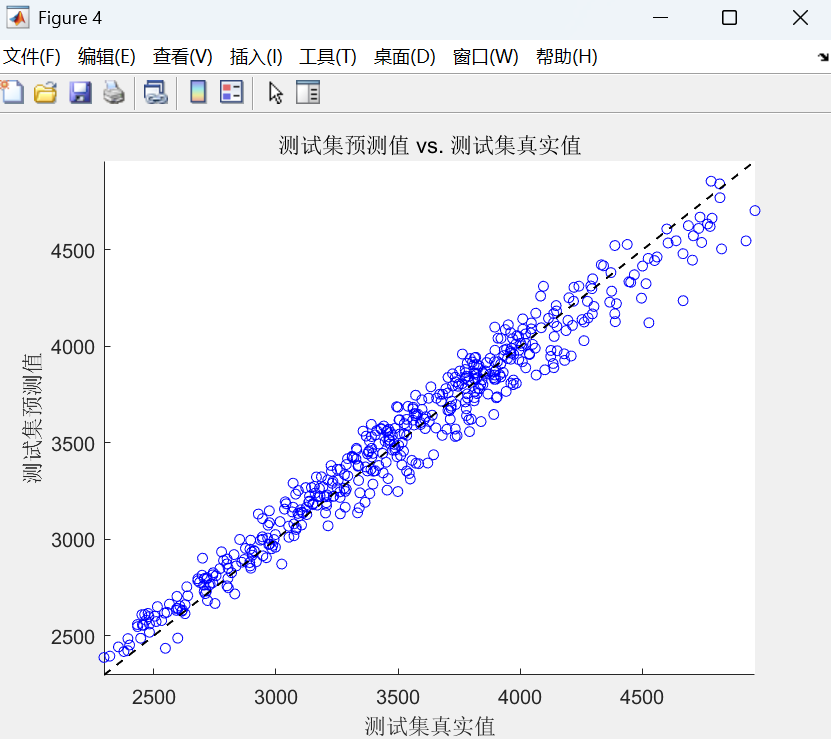
- 散点图: 将真实值作为 x 轴,预测值作为 y 轴画散点图。如果预测完美,所有点应落在一条 45° 的直线上。这可以很好地展示预测值的分布情况。
总结
这段代码完整地演示了一个时间序列预测项目的机器学习工作流程:
- 数据准备与预处理: 导入、构造滑动窗口数据集、划分训练测试集、归一化。
- 模型构建: 设计 LSTM 网络结构。
- 模型训练: 配置超参数并训练模型。
- 模型评估: 进行预测,反归一化,并用多种指标和图表全面评估模型在训练集和测试集上的性能,检查是否存在过拟合或欠拟合。

图2 main.m主函数文件部分代码
1.2.2 数据集文件
数据集为Excel数据csv格式文件,可以方便地直接替换为自己的数据运行程序。原始数据文件包含4列特征数据,1列输出(目标时间序列数据),一共包含1500个样本数据,具体如图所示。
二、代码运行结果展示
该代码实现了一个基于LSTM神经网络的时间序列预测模型。
首先,它将原始数据通过滑动窗口处理为特征-目标对的监督学习格式,并进行了归一化处理;
其次,构建并训练了一个包含LSTM层和全连接层的神经网络结构;
最后,使用训练好的模型进行预测,并通过反归一化得到最终结果,同时计算了RMSE、R²等多种评估指标并绘制图表以分析预测性能。
三、注意事项:
1.程序运行软件推荐Matlab 2018B版本及以上;
2.所有程序都经过验证,保证程序可以运行。此外程序包含简要注释,便于理解。
3.如果不会运行,可以帮忙远程运行原始程序以及讲解和其它售后,该服务需另行付费。
4. 代码包含详细的文件说明,以及对每个程序文件的功能注释,说明详细清楚。
5.Excel数据,可直接修改数据,替换数据后直接运行即可。