VLLM的加速原理
VLLM (Versatile Large Language Model)是⼀个专⻔为⼤规模语⾔模型 (LLM) 推理设计的开源加速框架,通过创新的内存管理和并⾏化技术,显著提⾼了推理速度和吞吐量。
其中,PagedAttention是 VLLM 的核⼼技术,专⻔⽤于解决 LLM 推理中的内存瓶颈问题,尤其是⾃回归⽣成任务中的键值 (KV) 缓存管理
1、PagedAttention 机制
PagedAttention 的主要⽬标是⾼效管理注意⼒机制中的 KV Cache,从⽽减少内存碎⽚和重复存储带来的显存浪费。
在传统的⾃回归解码过程中,模型需要将所有输⼊ token 的键和值张量(KV 缓存)存储在 GPU 内存中,以⽣成下⼀个 token。这种⽅法占⽤了⼤量显存,尤其当处理⻓序列时,GPU 内存成为推理过程中的瓶颈。
PagedAttention 通过引⼊类似于 虚拟内存管理 的思想,将 KV 缓存进⾏物理分块管理。即使模型在逻辑上需要连续的输⼊序列,实际的物理内存块可以是⾮连续的。这样做的好处是极⼤减少了 KV 缓存中 的内存浪费,并提⾼了推理过程中的内存利⽤率。
PagedAttention 的具体⼯作原理
物理分块 :PagedAttention 将 KV 缓存进⾏物理分块,每块显存包含固定⻓度的 tokens。在进⾏注意⼒计算时,VLLM 会根据需要从这些分块中读取键值缓存。尽管模型在逻辑上处理的是⼀个连续的序列,但这些序列在内存中的实际位置是分散的。
减少重复缓存 :在处理多个输出时,VLLM 可以将不同的逻辑块映射到同⼀个物理块,避免了重复存储同样的数据。这种⽅法显著减少了显存的占⽤,同时提⾼了吞吐量。
通过这种分块管理⽅式,VLLM 可以在保持推理速度的同时,极⼤降低内存占⽤,尤其是应对⻓序列推理时的内存瓶颈。
2、Continuous Batching机制
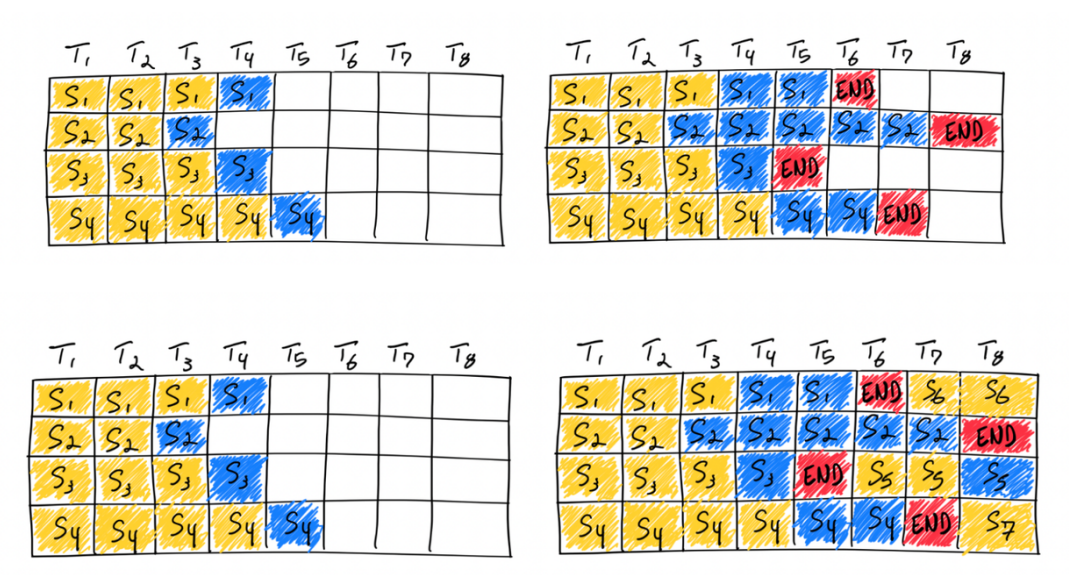
传统的批处 理⽅法(static batching)要求所有输⼊序列的⻓度对⻬,这意味着较短的句⼦需要等待较⻓句⼦⽣ 成完毕,导致 GPU 计算资源被浪费。

VLLM 采⽤ Continuous Batching,即每当某个句⼦的推理完成时,GPU 会⽴即填充下⼀个句⼦的 token,⽽不需要等待整个批次的推理完成。这种动态的批次管理⽅式充分利⽤了 GPU 的计算能⼒, 减少了等待时间,极⼤提⾼了吞吐量。

3、PagedAttention 与 Continuous Batching 的协同作用
PagedAttention 和 Continuous Batching 共同作⽤,优化了 VLLM 的推理性能。PagedAttention 通过精细管理 KV 缓存,减少了推理过程中的内存开销,特别是在处理⻓序列或多个输出时的内存浪费。
而 Continuous Batching 则确保 GPU 计算资源得到最⼤化利⽤,使得在推理过程中几乎没有等待时间。