从手术室到街头摄像头:多模态融合如何让AI“看得懂”万物?
来gongzhonghao【图灵学术计算机论文辅导】,快速拿捏更多计算机SCI/CCF发文资讯~
多模态特征融合依然是当下高性价比、高回报的研究方向,在近期的顶会顶刊中也可以推测,其持续成为发文热点。
手术视频把视觉-语言对齐推上 90% 精度,医学影像在噪声与偏移并存时一次性完成配准+复原+融合,行人属性识别用图文提示让细节不再被全局 token 淹没——这些案例都在证明:跨模态互补信息已成算法跃迁的“加速器”。
多模态特征融合不仅把模型感知力推向新高度,也因其通用性在医疗诊断、智能监控、机器人交互等场景无缝落地,创新空间巨大、落地周期短,2025 仍将是发文与转化的双热点!本文速拆三篇最新标杆,帮你一眼锁定下一波落地风口:
Surgical video workflow analysis via visual-language learning
方法:这篇文章首次将视觉-语言深度融合引入手术视频,通过“三重态语义增强器(TSE)”对 <器械-动作-目标> 进行细粒度识别,同时提出 Intra-TSE 在视觉分支内部利用跨分支交叉注意力和坐标时空模块挖掘三元组内时空关系,并设计 Inter-TSE 在文本分支用文本-视觉双图卷积网络刻画三元组间的因果与时序关系,最终把四个子任务的预测结果通过联合校准损失统一优化,实现端到端的手术工作流精准解析。
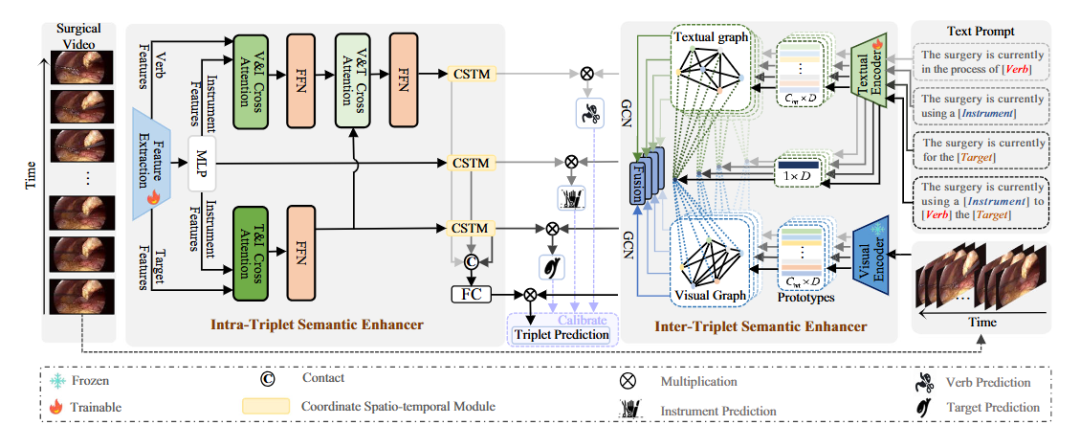
创新点:
提出 Intra-TSE 模块,利用交叉注意力与坐标时空模块联合建模三元组内部器械-动作-目标的细粒度时空交互语义。
设计 Inter-TSE 模块,首次构建文本提示-视觉原型双图卷积网络,显式捕获三元组之间的因果、时序等逻辑关系。
引入联合预测校准机制,将器械、动作、目标及三元组分支的独立预测通过乘积融合进行置信度再校准,显著提升稀有类别与整体准确率。
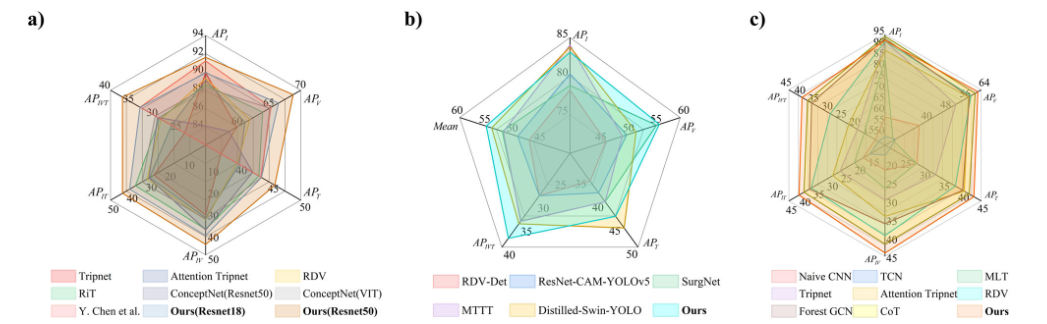
总结:作者以视觉-语言大模型为基础,将手术视频每一帧抽象为 <器械,动作,目标> 三元组,通过 Intra-TSE 在视觉流中挖掘三元组内空间-时间一致性,通过 Inter-TSE 在文本流中利用文本提示与视觉原型双图推理三元组间的高层语义关系,并以联合损失对四个子任务输出进行相互校准,从而在三个公开数据集上显著超越现有方法,为实时手术决策与术后复盘提供了新的细粒度解析框架。
UniFuse: A Unified All-in-One Framework for Multi-Modal Medical Image Fusion Under Diverse Degradations and Misalignments
方法:这篇文章首次把“配准-复原-融合”三阶段流程压缩进单一网络,提出 UniFuse 框架,用退化感知提示同时指挥跨模态对齐与复原,再用 Spatial-Mamba 统一特征空间,最后用自适应 LoRA 协同网络在一条 U-Net 内完成任意退化与偏移下的多模态医学图像融合。
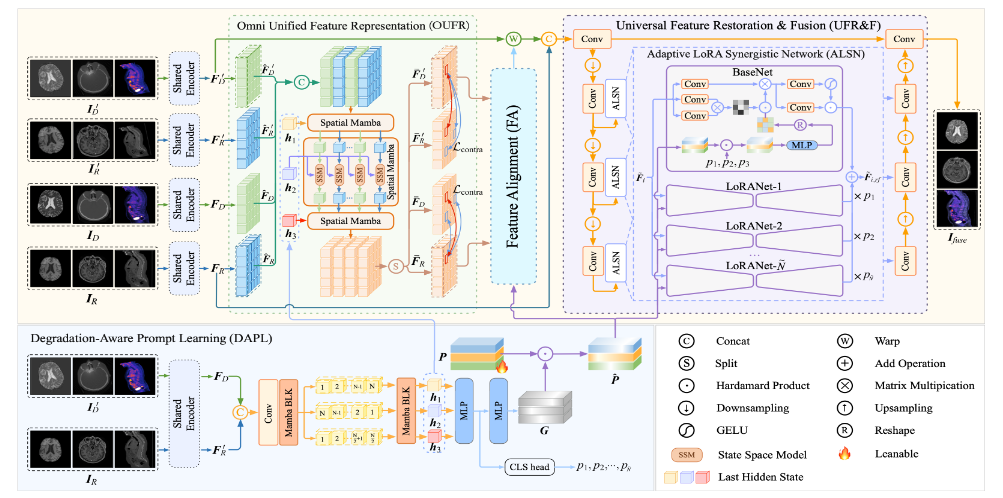
创新点:
设计退化感知提示学习(DAPL)模块,把退化类型编码成共享提示,实现配准与复原的联合优化。
提出 Omni 统一特征表示(OUFR),用 Spatial-Mamba 在多方向上消除模态差异,显著提升对齐精度。
构建自适应 LoRA 协同网络(ALSN),在保持极低参数量的同时为不同退化类型动态分配复原与融合权重。
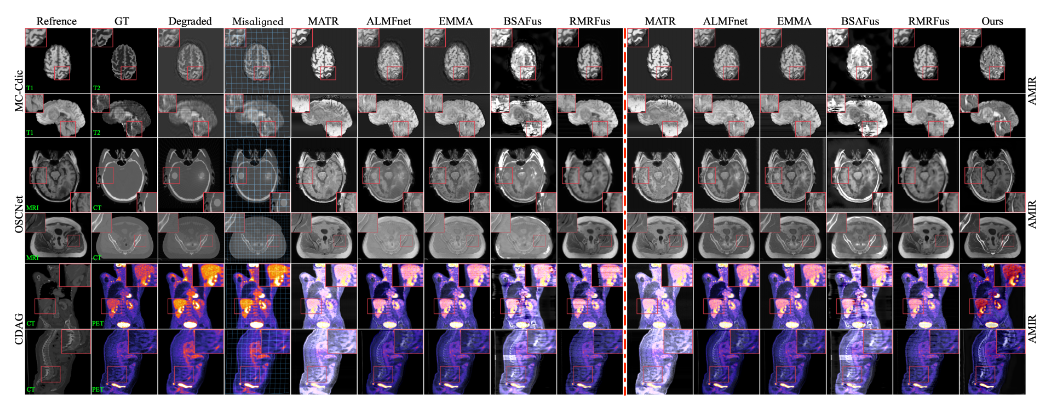
总结:UniFuse 先用共享编码器提取退化图像与参考图像的多方向特征,再用 DAPL 生成退化提示;该提示驱动 OUFR 中的 Spatial-Mamba 将两种模态映射到一致特征空间,随后 FA 模块在多尺度 RegBLK 中预测形变场完成精确对齐;最后 UFR&F 把对齐后的特征送入嵌有 ALSN 的 U-Net,在单阶段内并行完成复原和融合,并以联合损失端到端训练,在三个数据集上显著优于分阶段方法。
纠结选题?导师放养?投稿被拒?对论文有任何问题的同学,欢迎来gongzhonghao【图灵学术计算机论文辅导】,获取顶会顶刊前沿资讯~
VITA-PAR: VISUAL AND TEXTUAL ATTRIBUTE ALIGNMENT WITH ATTRIBUTE PROMPTING FOR PEDESTRIAN ATTRIBUTE RECOGNITION
方法:这篇文章直击行人属性识别中“全局粗粒度与局部细粒度难兼顾、属性位置飘忽不定、图文模态对不齐”三大痛点,提出 ViTA-PAR,用可学习的视觉-文本属性提示与跨模态对齐,一举刷新四项公开数据集指标。
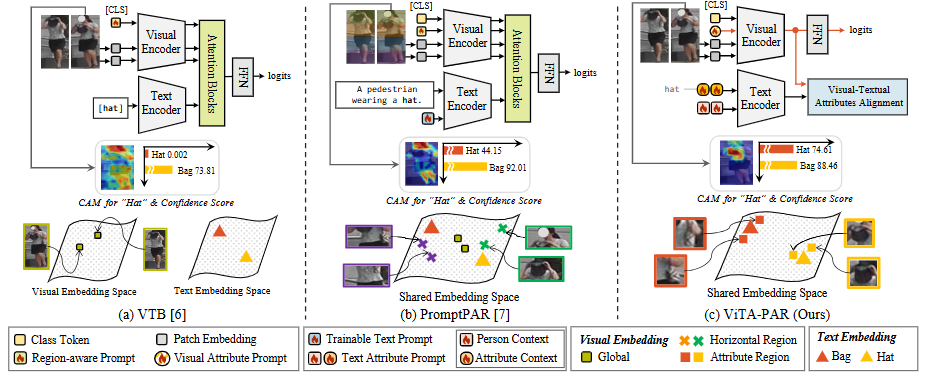
创新点:
提出视觉属性提示,突破固定区域限制,自适应捕获全局到局部的属性语义。
设计“人物+属性”双层可学习文本提示模板,丰富细粒度描述并提升文本表征能力。
构建无需额外注意力的图文特征对齐机制,仅用余弦相似度即可实现高效融合,推断阶段完全抛掉文本、速度倍增。
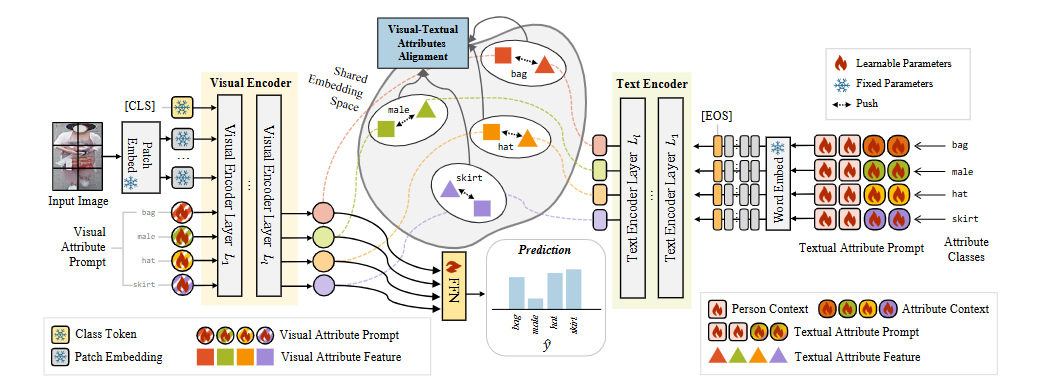
总结:ViTA-PAR 以 CLIP 为骨干,在视觉分支引入与类别数量对应的可学习视觉提示取代传统 CLS token;在文本分支通过共享的人物上下文和独立的属性上下文共同构成可训练提示,经 CLIP 文本编码器得到属性描述;训练时计算视觉-文本特征余弦相似度并用对齐损失拉近两者,推断时仅用视觉特征即可快速精准地完成多标签属性识别。
关注gongzhonghao【图灵学术计算机论文辅导】,快速拿捏更多计算机SCI/CCF发文资讯